MolmoWeb: Open Visual Web Agent and Open Data for the Open Web
Abstract: Web agents--autonomous systems that navigate and execute tasks on the web on behalf of users--have the potential to transform how people interact with the digital world. However, the most capable web agents today rely on proprietary models with undisclosed training data and recipes, limiting scientific understanding, reproducibility, and community-driven progress. We believe agents for the open web should be built in the open. To this end, we introduce (1) MolmoWebMix, a large and diverse mixture of browser task demonstrations and web-GUI perception data and (2) MolmoWeb, a family of fully open multimodal web agents. Specifically, MolmoWebMix combines over 100K synthetic task trajectories from multiple complementary generation pipelines with 30K+ human demonstrations, atomic web-skill trajectories, and GUI perception data, including referring expression grounding and screenshot question answering. MolmoWeb agents operate as instruction-conditioned visual-language action policies: given a task instruction and a webpage screenshot, they predict the next browser action, requiring no access to HTML, accessibility trees, or specialized APIs. Available in 4B and 8B size, on browser-use benchmarks like WebVoyager, Online-Mind2Web, and DeepShop, MolmoWeb agents achieve state-of-the-art results outperforming similar scale open-weight-only models such as Fara-7B, UI-Tars-1.5-7B, and Holo1-7B. MolmoWeb-8B also surpasses set-of-marks (SoM) agents built on much larger closed frontier models like GPT-4o. We further demonstrate consistent gains through test-time scaling via parallel rollouts with best-of-N selection, achieving 94.7% and 60.5% pass@4 (compared to 78.2% and 35.3% pass@1) on WebVoyager and Online-Mind2Web respectively. We will release model checkpoints, training data, code, and a unified evaluation harness to enable reproducibility and accelerate open research on web agents.
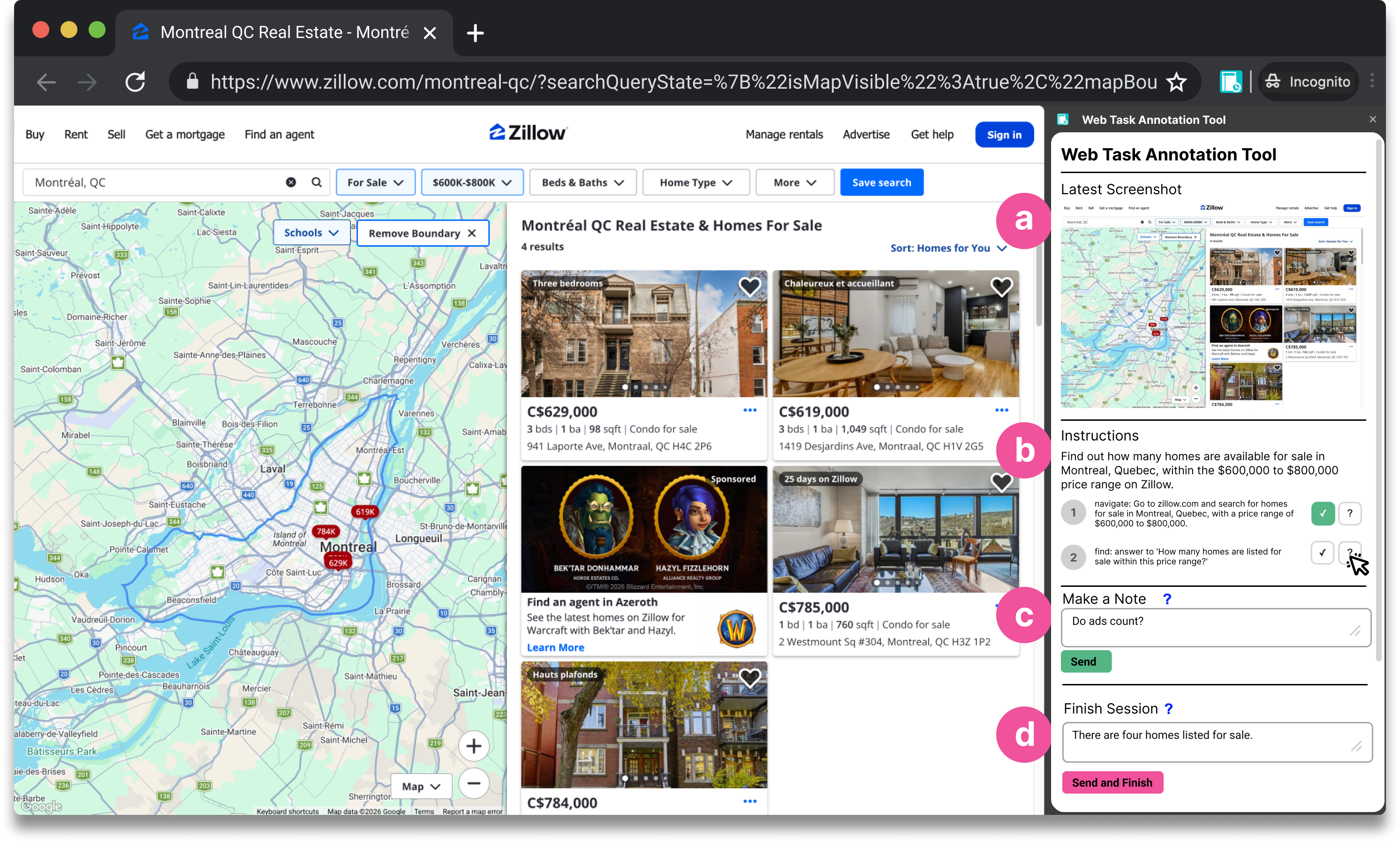
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MolmoWeb: A simple guide for teens
What is this paper about?
This paper is about building a smart computer helper (called a “web agent”) that can use websites for you. Think of it like a careful, well-trained assistant that can read the screen, click buttons, type into forms, scroll, and find information—just like you would—with no secret access to the website’s code.
The authors built:
- MolmoWeb: open, small-but-strong AI models that can operate websites using only screenshots.
- MolmoWebMix: a big, openly available training dataset that teaches these models how to understand screens and complete tasks on the web.
Their goal is to make web agents powerful, reliable, and—most importantly—fully open so that anyone can study, improve, and trust them.
What questions were they trying to answer?
They focused on a few simple questions:
- Can we train a web agent that works well by seeing only what humans see (screenshots), without peeking behind the scenes of a webpage?
- Can a smaller, open model (4–8 billion parameters) compete with or beat bigger, closed models from large companies?
- What kind of data best teaches a web agent to click the right things, type correctly, and complete multi-step tasks?
- Does trying multiple times in parallel help the agent perform better?
How did they do it?
They took a two-part approach: build great training data, then train a simple, practical model on it.
1) The data: MolmoWebMix
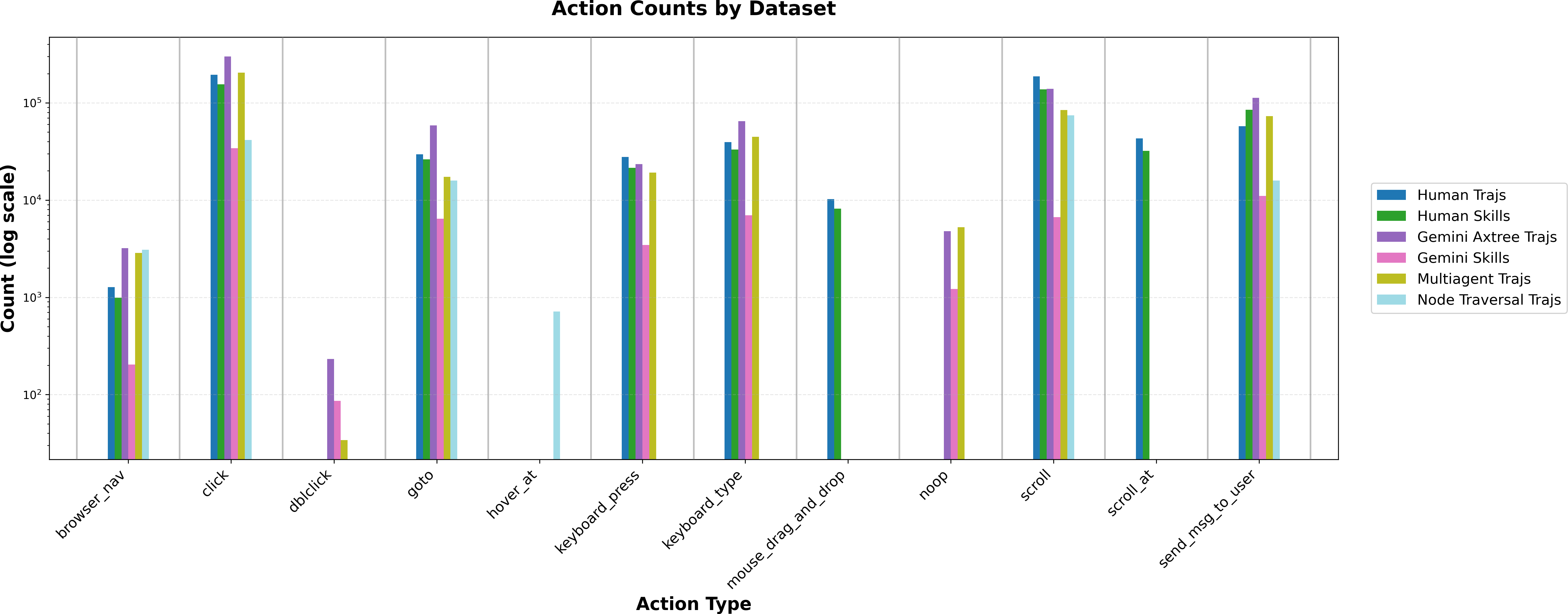
To train a web agent, you need lots of examples of “what to do on the web.” The team created a large, open dataset made of:
- Task “replays” (called trajectories): step-by-step recordings of how a task is done on a website—where to click, what to type, when to scroll, etc.
- Atomic skills: short clips that teach basic moves like “type in a search box,” “apply a filter,” “find and click a link,” or “add to cart.”
- GUI perception data: training for “seeing and understanding the screen,” including:
- Grounding: when told “click the Checkout button,” point to the exact place to click.
- Screenshot Q&A: answer questions like “What’s the price?” or “Where can I see the latest news?” by reading the screen.
Where did the task replays come from?
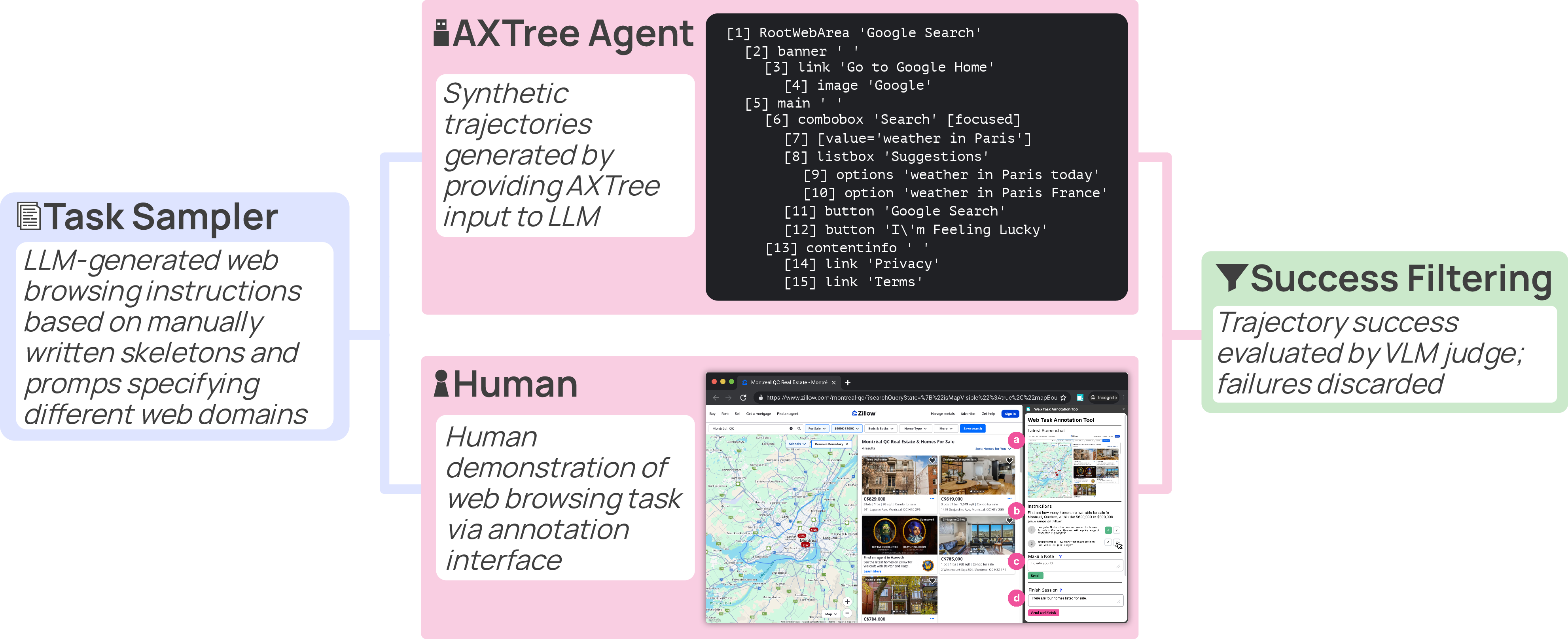
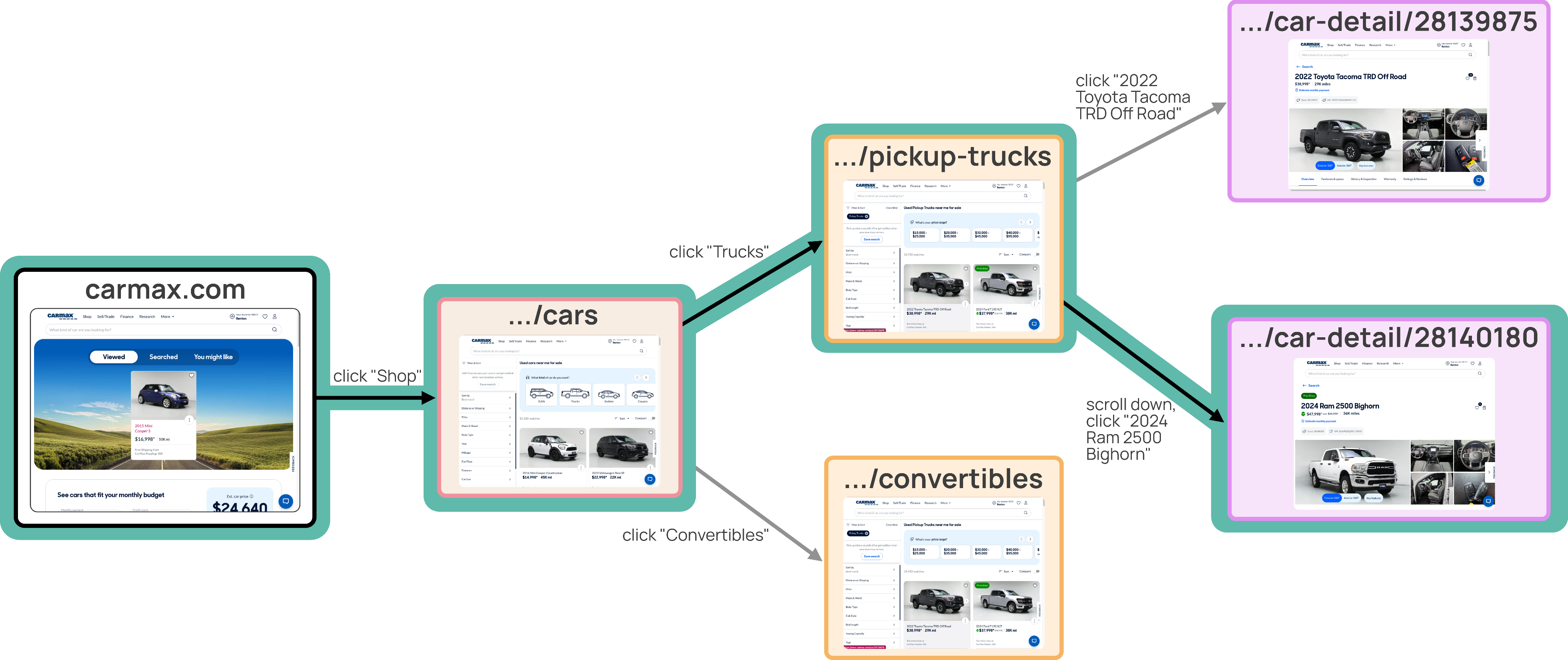
- Synthetic agents: AI systems that navigate using a website’s behind-the-scenes “map” (called an accessibility tree or AxTree). Their actions were recorded and paired with screenshots so the new model could learn visually.
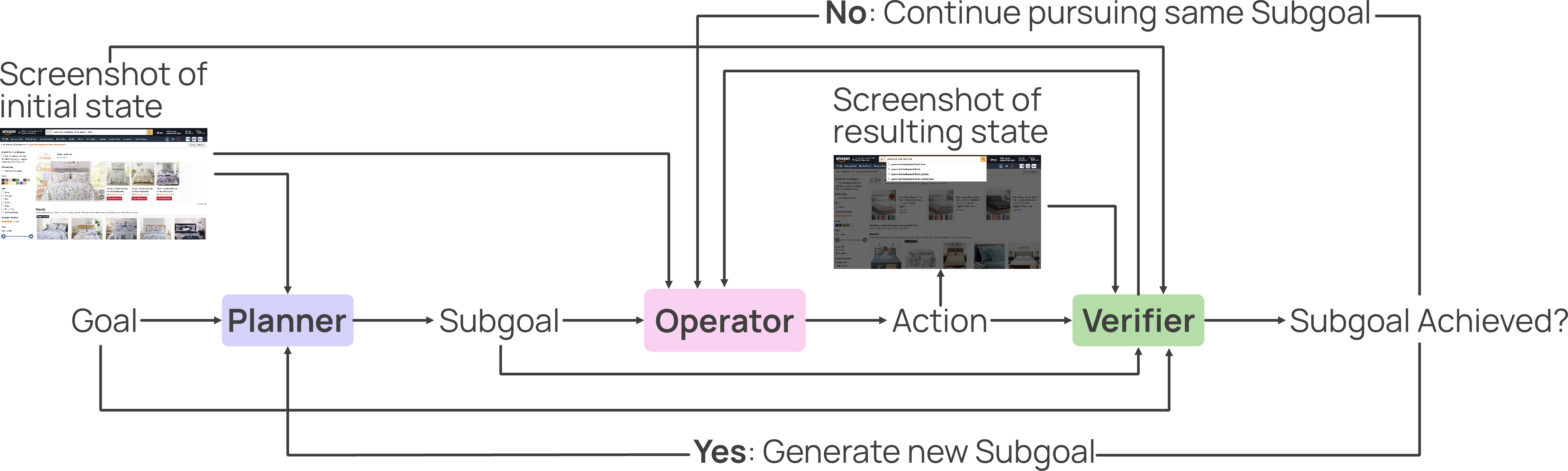
- A multi-agent setup: three roles—Planner (decides subgoals), Operator (clicks/types), Verifier (checks progress)—working together to produce higher-quality examples.
- Humans: real people completing tasks, recorded with a browser extension.
- Node traversal: a deterministic method that clicks through a site’s pages (like following a pre-drawn map), which creates reliable training examples.
Why screenshots?
- It mirrors how humans use the web.
- It avoids messy, ever-changing website code.
- It’s cheaper and simpler than feeding giant chunks of webpage structure into the model.
2) The model: MolmoWeb (4B and 8B)
MolmoWeb is a vision-LLM (it reads text and images together). At each step it gets:
- The task instruction (e.g., “Find and add the cheapest blue backpack to the cart”),
- The current screenshot,
- A short history of past actions.
It outputs:
- A short “thought” (a simple reason for its next step),
- A concrete action: click, type, scroll, go back, open tab, etc. (with coordinates for clicks).
Training was straightforward supervised learning: show the model many examples and have it imitate the correct next action.
What did they find?
Here are the main results, in plain language:
- Strong performance for small, open models:
- The 8B model beats or matches other open models of similar or larger size on popular tests like WebVoyager, Online-Mind2Web, and DeepShop.
- It even outperforms some bigger, closed systems that get extra information about the page.
- Vision-only can be enough:
- Even without reading the website’s hidden structure, the screenshot-only agent completes tasks very well. This suggests good data and targeted training can rival, or even beat, brute force model size or extra inputs.
- Trying multiple times boosts success:
- If the agent runs several attempts in parallel and you pick the best one using an automatic judge, success rates jump a lot.
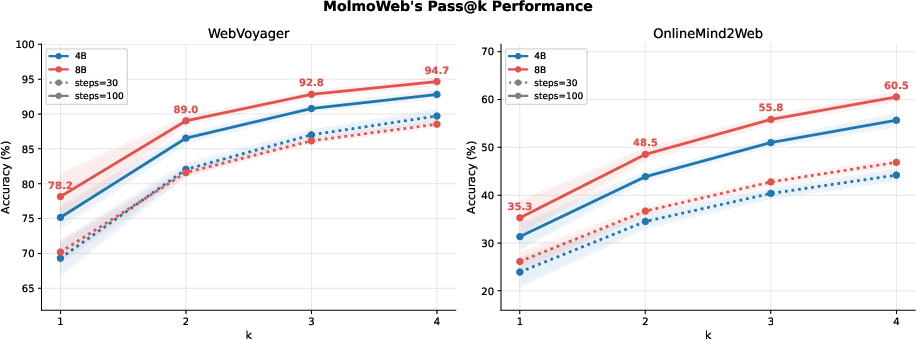
- Example: on WebVoyager, the 8B model went from about 78% (one try) to about 95% when picking the best of four tries.
- More data helps—but quality matters:
- Performance grows with more training data.
- Carefully made synthetic examples (produced by the AxTree agents) often taught the model better than human demonstrations. Human demos can be longer, messier, and more exploratory, which is natural for people but harder for the model to imitate.
- Decoding strategy matters:
- Letting the model be a bit “creative” (not purely greedy, but sampling from top choices) helps it avoid getting stuck and improves task completion.
Why is this important?
- It shows you can build a useful, web-using AI that’s open, runs on smaller models, and learns from visual information alone.
- It reduces reliance on secret data and closed systems.
What could this mean for the future?
- More trustworthy and testable web agents: Because the models, code, and data are open, researchers and developers can check how the agent learned, reproduce results, and improve them.
- Better accessibility: Agents that see screens like humans can help people complete online tasks that are otherwise confusing or time-consuming—especially for users with disabilities or lower digital literacy.
- Faster progress for everyone: Open tools lower the barrier for students, startups, and labs to build real, useful web assistants.
- Practical upgrades on the horizon: The big gains from parallel tries suggest simple ways to make agents much more reliable in everyday use. The data and approach can also support future training methods like self-improvement and reinforcement learning.
In short: the team shows that a well-trained, open, screenshot-only web agent can compete with or beat larger closed systems. They release the models, data, and evaluation tools so the whole community can build on their work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future research could address:
- Vision-only constraint: How do screenshot-only agents compare to AxTree/DOM-augmented agents under controlled ablations (same model/compute) across robustness, efficiency, and accuracy, especially for small targets, offscreen elements, hidden widgets, and dynamic content?
- OCR robustness: The model implicitly performs OCR; its accuracy on small fonts, low contrast text, non-Latin scripts (CJK/RTL), rotated text, and dense tables is unreported—what are the failure modes and how to mitigate them?
- Multilingual and localization: Coverage and performance on non-English webpages, mixed-language UIs, locale-specific formats (date, currency, phone numbers) and right-to-left layouts remain unquantified.
- Accessibility semantics at inference: Without AxTree at runtime, the agent cannot leverage ARIA roles, labels, or landmarks—can hybrid visual+semantic inputs improve reliability and accessibility alignment?
- Action space completeness: The action set lacks file upload/download, clipboard copy/paste, right-click menus, system dialogs, OS file pickers, calendar pickers, sliders, and complex drag gestures—what additions most improve real-world task coverage?
- Coordinate discretization: Click coordinates are normalized to two decimals; how often does this miss tiny targets (e.g., small checkboxes) and would subpixel or learned hit-testing reduce miss clicks?
- Element-level vs pixel-level pointing: Can adding a learned element selector (point+segment or box) reduce spatial error and improve generalization across responsive layouts?
- Popups and overlays: No explicit handling for cookie banners, consent dialogs, modals, or interstitials was evaluated—what detection and policy adaptations are needed to robustly clear such blockers?
- Authentication/multi-factor flows: The agent’s capability on login, 2FA, email/SMS code entry, and session timeouts is not assessed—how to safely and privately handle credentials and persistent sessions?
- Personalization and paywalls: Behavior under personalized feeds, paywalled content, and region-locked sites is untested; how to generalize across user states and content gates?
- Multi-tab/task context: Although new_tab and tab_focus exist, tasks requiring coordination across multiple tabs or windows were not isolated—what strategies reliably track and switch context?
- Temporal robustness: Performance drift over time with site redesigns, A/B tests, and ad variations is unmeasured—how stable are agents across months and what continual adaptation is needed?
- Viewport and device diversity: Only desktop screenshot settings appear studied; generalization to different resolutions, zoom levels, HiDPI, mobile/responsive layouts, and dark mode is unknown.
- Non-HTML canvases: Interactions with PDFs, canvas-rendered UIs, maps, graphics, and embedded media (audio/video players) were not analyzed—what specialized perception modules are required?
- Safety and risk controls: No explicit safeguards against harmful or irreversible actions (e.g., purchases, money transfers, data deletion) were evaluated—what policy constraints or approval checkpoints reduce risk?
- Prompt/UX injection: Webpages can inject misleading instructions; there is no evaluation of robustness to prompt-injection-style attacks—what defenses (content filtering, instruction isolation) are effective?
- Privacy and data handling: Screenshots may contain PII; how are collection, storage, redaction, and release governed, and can on-device processing or selective redaction mitigate risk?
- Evaluation judge reliability: Success is judged by frontier LLMs with known variability; inter-judge agreement, bias, and reproducibility of pass/fail labels are not quantified—can open judges or human audits calibrate evaluations?
- Judge-driven selection bias: Best-of-N selection uses the same (or similar) judge; does this induce overfitting to judge preferences, and how to validate with judge diversity or blinded human evaluation?
- Train–test leakage risk: Synthetic trajectories include benchmark sites; explicit decontamination between training and evaluation (site/task/session overlap) is not described—what audited splits prevent leakage?
- Live-web reproducibility: Live sites change; the paper permits retries and step caps—how sensitive are results to environment variability, and should standardized snapshots or seeded web sandboxes be used for stable comparisons?
- Cost–quality tradeoffs: Best-of-N rollouts yield large gains but increase compute; what are the Pareto curves of success rate vs. cost, and can self-distillation compress BoN gains into single-run policies?
- Learning from human trajectories: Human data gave limited gains; what methods (noise-robust imitation, latent policy mixtures, sequence filtering/denoising, curriculum) best reconcile human and synthetic policies?
- Planning vs reactive policies: The agent outputs a “thought” but no explicit hierarchical planning/tracking—do explicit subgoal planners, memory modules, or plan-verification loops improve long-horizon success?
- Credit assignment over long horizons: Tasks capped at 100 steps may still fail due to compounding errors; can search, lookahead, or model-predictive control reduce error accumulation without large compute?
- RL and feedback: Only SFT is used; do offline RL, DPO, or preference learning from judge/human feedback yield robust gains beyond BoN?
- Sampling strategy generality: Top-p=0.8, T=0.7 worked on WebVoyager; are optimal decoding parameters benchmark- and state-dependent, and can adaptive decoding policies prevent local traps?
- Grounding data provenance: Grounding labels derived from AxTree boxes and templated/GPT-generated descriptions may induce biases; how to reduce label noise and improve linguistic variety and spatial realism?
- GUI QA generation risks: Screenshot QA questions were produced using AxTree references (later filtered); residual leakage and coverage of higher-order reasoning remain unclear—can human-written QA or adversarial QA improve robustness?
- Error taxonomy: A systematic breakdown of failure modes (mis-grounding, wrong form fields, pagination errors, navigation loops, dead-ends) is missing—what targeted data or policy changes most reduce top errors?
- Domain coverage and diversity: Although 2.6K domains are claimed, the distribution across categories (government, finance, healthcare, travel, education) and geographies is unclear—where are the blind spots?
- Security evaluation: No red-teaming against malicious sites (phishing, drive-by downloads, deceptive UI) or adversarial GUIs—what security benchmarks and mitigations are necessary for safe deployment?
- Legal and licensing: The release of screenshots from live sites raises copyright/ToS concerns; what licensing, consent, and takedown processes govern dataset use and redistribution?
- Resource efficiency: Inference latency, GPU memory needs, and throughput for 4B/8B models (and under BoN) are not reported—what optimizations (quantization, caching, vision-only pruning) preserve quality at lower cost?
- Generalization to non-web GUIs: Transfer to desktop/mobile apps is not evaluated—what adaptations of perception and action spaces are required for OS-native UI automation?
- Calendar/time-sensitive tasks: The paper edits time fields to keep tasks valid; can agents autonomously repair stale goals (date roll-forward, alternative options) to stay task-relevant?
- User-in-the-loop interactions: The action send_msg_to_user exists but interactive clarification (asking for missing info, ambiguity resolution) was not evaluated—when and how should agents query users?
- Mixture optimization: Data mixing ratios were tuned manually; can automated mixture-of-datasets optimization or curriculum learning improve multi-benchmark performance more systematically?
- Thought usefulness: The impact of generating “thought” text on policy quality, grounding, or BoN selection is not ablated—does rationale generation help, and can it be distilled away to save tokens?
Practical Applications
Overview
Based on the paper “MolmoWeb: Open Visual Web Agent and Open Data for the Open Web,” below are concrete, real-world applications enabled by its open web agent (MolmoWeb-4B/8B), dataset (MolmoWebMix), and evaluation harness. The applications are grouped by deployment horizon and mapped to sectors, with notes on tools/workflows and feasibility assumptions.
Immediate Applications
The following can be deployed today with the released checkpoints, data, and code, or with minimal integration engineering.
Industry
- Vision-first RPA for web workflows (Software, Enterprise IT)
- What: Automate repetitive browser tasks—click, type, scroll, form-fill—across heterogeneous websites without DOM/AxTree dependency (e.g., invoice downloading, claims submissions, vendor onboarding).
- Tools/workflows: Wrap MolmoWeb into a headless-browser runner; expose a JSON action API; optionally use best-of-N parallel rollouts with an LLM-judge for reliability.
- Assumptions/dependencies: Stable headless browser (e.g., Chrome/Browserbase); adherence to site TOS; anti-bot/captcha mitigation; secure secrets handling for logins.
- E-commerce operations automation (Retail)
- What: Product comparison, price checks, stock status, cart and checkout flows; returns initiation and warranty claims on vendor portals.
- Tools/workflows: Task templates (“check top 5 competitors and log prices”), scheduled runs; audit trails via MolmoWeb’s action/“thought” logs.
- Assumptions/dependencies: Login support, MFA handling via user-in-the-loop; anti-bot systems may limit frequency.
- Customer support portal navigation (BPO/Support)
- What: Automate ticket creation, form submissions, SLA lookups, refund and RMA processes on partner/customer portals that lack robust APIs.
- Tools/workflows: Integrate MolmoWeb as a support agent copilot; use best-of-N selection for higher first-pass success.
- Assumptions/dependencies: Role-based access controls; privacy controls for PII; reliability monitored by human oversight.
- QA and regression testing for web UIs (Software testing)
- What: Vision-based end-to-end test flows robust to HTML/CSS refactors; detect behavior regressions and broken flows despite DOM changes.
- Tools/workflows: Test suite defined as natural-language tasks; screenshot traces and pass/fail judged by LLM-as-a-judge or curated heuristics.
- Assumptions/dependencies: Stable test environments; standardized judge prompts; ability to snapshot build states.
- Web data capture from visual content (Finance, Operations)
- What: Extract visible values (totals, balances, confirmations) and export them (e.g., reconcile bills, download statements).
- Tools/workflows: Use Screenshot QA + actions; optional OCR backup; log extraction as structured data.
- Assumptions/dependencies: Respect terms of service; content must be visibly rendered; anti-automation protections may block access.
- Procurement and vendor management (Enterprise operations)
- What: Automate routine procurement tasks across vendor sites (catalog browse, quote requests, order placement).
- Tools/workflows: Templates per vendor flow; human-in-the-loop review for purchase approvals.
- Assumptions/dependencies: Compliance and financial controls; periodic vendor website changes require monitoring.
Academia and Open-Source
- Reproducible web-agent research and benchmarking
- What: Use MolmoWebMix, open weights, and unified eval harness to study model/data scaling, sampling, training mixtures, and GUI perception.
- Tools/workflows: Run ablations; compare pass@k and sampling strategies; try self-distillation using best-of-N rollouts.
- Assumptions/dependencies: Compute for evaluation (parallel rollouts); judge quality affects measured performance.
- Curriculum learning on atomic GUI skills
- What: Train and test on isolated skills (search, form filling, filtering) to study compositionality and data efficiency.
- Tools/workflows: Start with MolmoWebMix’s atomic skill segments; analyze transfer to multi-step tasks.
- Assumptions/dependencies: Proper mixing ratios; careful evaluation to avoid overfitting to specific sites.
- GUI grounding and OCR benchmarking
- What: Evaluate and build stronger screen-grounding or OCR models using the grounding and screenshot QA data.
- Tools/workflows: Fine-tune grounding-specialist heads; port to new screen resolutions or UIs.
- Assumptions/dependencies: Visual variance across sites; OCR performance depends on text rendering quality.
Policy and Governance
- Transparent evaluation protocols for web agents
- What: Leverage the open evaluation harness and LLM-as-a-judge prompts to prototype standardized test procedures for auditing web agents.
- Tools/workflows: Publish judge prompts and scoring guidelines; compare judges to assess bias/variance.
- Assumptions/dependencies: Judge choice (closed vs. open) affects outcomes; legal considerations for testing on live sites.
- Accessibility research and pilot evaluations
- What: Evaluate whether vision-only agents improve access to services (e.g., government portals) for users with disabilities.
- Tools/workflows: User studies where MolmoWeb executes tasks on voice instructions; log errors for remediation.
- Assumptions/dependencies: Ethical oversight; privacy and consent; limited guarantees for high-stakes tasks.
Daily Life
- Personal browsing automations
- What: Book appointments (DMV, healthcare), track packages, fill applications, cancel subscriptions, or register for events.
- Tools/workflows: Browser extension wrapper for MolmoWeb; “task macros” with confirmation steps.
- Assumptions/dependencies: MFA/login steps may require user input; sites may rate-limit or use anti-bot protections.
- Assistive browsing for users with disabilities or limited digital skills
- What: Speech-driven commands to accomplish multi-step web tasks; agent describes actions before execution.
- Tools/workflows: Voice interface + MolmoWeb action runner; transparent “thought” logs aid trust.
- Assumptions/dependencies: Robust speech-to-text and TTS; privacy controls; task complexity should match reliability.
Long-Term Applications
These require further research, scaling, productization, and/or policy frameworks.
Industry
- General-purpose enterprise web assistant with reliability guarantees
- What: An agent that robustly executes multi-step workflows across any website at near-human reliability, with auditability and rollback.
- Tools/workflows: Self-distillation from best-of-N rollouts, reinforcement learning on success signals, and human-in-the-loop verification policies.
- Assumptions/dependencies: Higher-capacity open models or specialized finetunes; better judges; robust anti-bot handling; SLAs for failure recovery.
- Unified “computer-use” across web, desktop, and mobile apps
- What: Extend screenshot-only action policies from web to full desktops/mobile; orchestrate multi-app workflows (e.g., export from ERP, upload to portal).
- Tools/workflows: Cross-platform screen capture and input drivers; action abstractions per OS/app.
- Assumptions/dependencies: OS-level permissioning; latency constraints; input focus handling and window management.
- Compliance-aware automation with policy constraints
- What: Agents that understand and enforce policy rules (e.g., SOC2, HIPAA) during automation, with fine-grained action-level auditing.
- Tools/workflows: Policy engines integrated into the action policy; immutable logs; red-team testing harness.
- Assumptions/dependencies: Formal policy encoding; secure storage and data minimization; verifiable judge oracles.
Academia and Open-Source
- Learning from interactive feedback and self-improvement
- What: Use pass@k and best-of-N trajectories to self-distill better single-run policies; incorporate online RL with success/failure signals.
- Tools/workflows: Iterative data collection loops; judge- or human-verified labels; off-policy corrections.
- Assumptions/dependencies: Reliable judges; careful mitigation of reward hacking and bias.
- Robustness to adversarial or dynamic web environments
- What: Improve generalization to UI/layout changes, anti-automation countermeasures, and non-English interfaces.
- Tools/workflows: Domain randomization; multilingual data augmentation; adversarial training.
- Assumptions/dependencies: Access to diverse sites; controlled adversarial testbeds; stronger vision encoders.
- Interpretable agent reasoning and debuggability
- What: Operationalize the “thought + action” outputs for traceability, error analysis, and safety reviews.
- Tools/workflows: Alignment datasets for faithful rationales; tools to compare rationales vs. actions vs. outcomes.
- Assumptions/dependencies: Avoiding deceptive rationales; mechanism for secure storage and review.
Policy and Governance
- Standards for judging web-agent correctness and safety
- What: Develop open benchmarks and judge protocols for high-stakes domains (finance, healthcare, government services).
- Tools/workflows: Public judge prompt repositories; calibration studies comparing different judges and human panels.
- Assumptions/dependencies: Agreement on success criteria; availability of consented test sites; governance for judge updates.
- Regulatory guidance for automated web interaction
- What: Clarify acceptable automation practices, data handling, and user consent in automated browsing agents.
- Tools/workflows: Collaborations among standards bodies, agencies, and industry; compliance test suites based on MolmoWeb harness.
- Assumptions/dependencies: Jurisdictional variation; evolving website terms and anti-bot policies.
Daily Life
- Proactive personal digital assistant
- What: An agent that monitors deadlines, renewals, and opportunities (e.g., passport renewal slots) and takes pre-approved actions.
- Tools/workflows: Schedules + triggers; user-defined guardrails; notifications and human confirmation.
- Assumptions/dependencies: Trust and privacy controls; identity verification; failure handling and user recourse.
- Multimodal accessibility copilot
- What: Context-aware assistance that adapts to user preferences (e.g., low-vision users) and navigates complex sites with descriptive guidance.
- Tools/workflows: Personalized prompting; adapted UI overlays; interaction summaries.
- Assumptions/dependencies: Personalization data and consent; accessibility guidelines alignment (e.g., WCAG).
- Cross-lingual and cross-cultural web assistance
- What: Seamless automation across non-English websites and culturally variant UI conventions.
- Tools/workflows: Multilingual finetuning; locale-specific skills; scripts for holidays/formatting differences.
- Assumptions/dependencies: Diverse multilingual datasets; OCR for multiple scripts; evaluation across locales.
Notes on Feasibility, Dependencies, and Risks
- Anti-automation and CAPTCHA: Many sites deploy bot detection—expect to need human-in-the-loop steps or compliant automation agreements.
- Authentication and security: Handling credentials, MFA, and PII requires strong privacy safeguards and secure key management.
- Judge dependence: Best-of-N and pass@k rely on an LLM judge; different judges can shift outcomes. Open, audited judges are preferable for governance.
- Screenshot-only limits: Hidden elements, off-screen content, or heavy dynamic content may require scrolling strategies or fallback cues.
- Legal and ethical constraints: Respect site terms of service and regional regulations; avoid scraping uses that violate policies; ensure user consent.
- Compute and latency: Parallel rollouts improve reliability but increase cost/latency; engineering trade-offs are needed per use case.
These applications build on MolmoWeb’s core strengths—vision-only robustness to DOM changes, open data and code for reproducibility, competitive performance at 4B/8B scales, and strong gains via test-time scaling—positioning it as a practical foundation for open, trustworthy web automation.
Glossary
- Accessibility tree (AxTree): A structured, accessibility-focused representation of a webpage’s UI elements used for programmatic interaction and analysis. "Crucially, MolmoWeb agents operate on any website using only the visual interface that human users see, without requiring specialized APIs or access to the underlying HTML or accessibility tree (AxTree)."
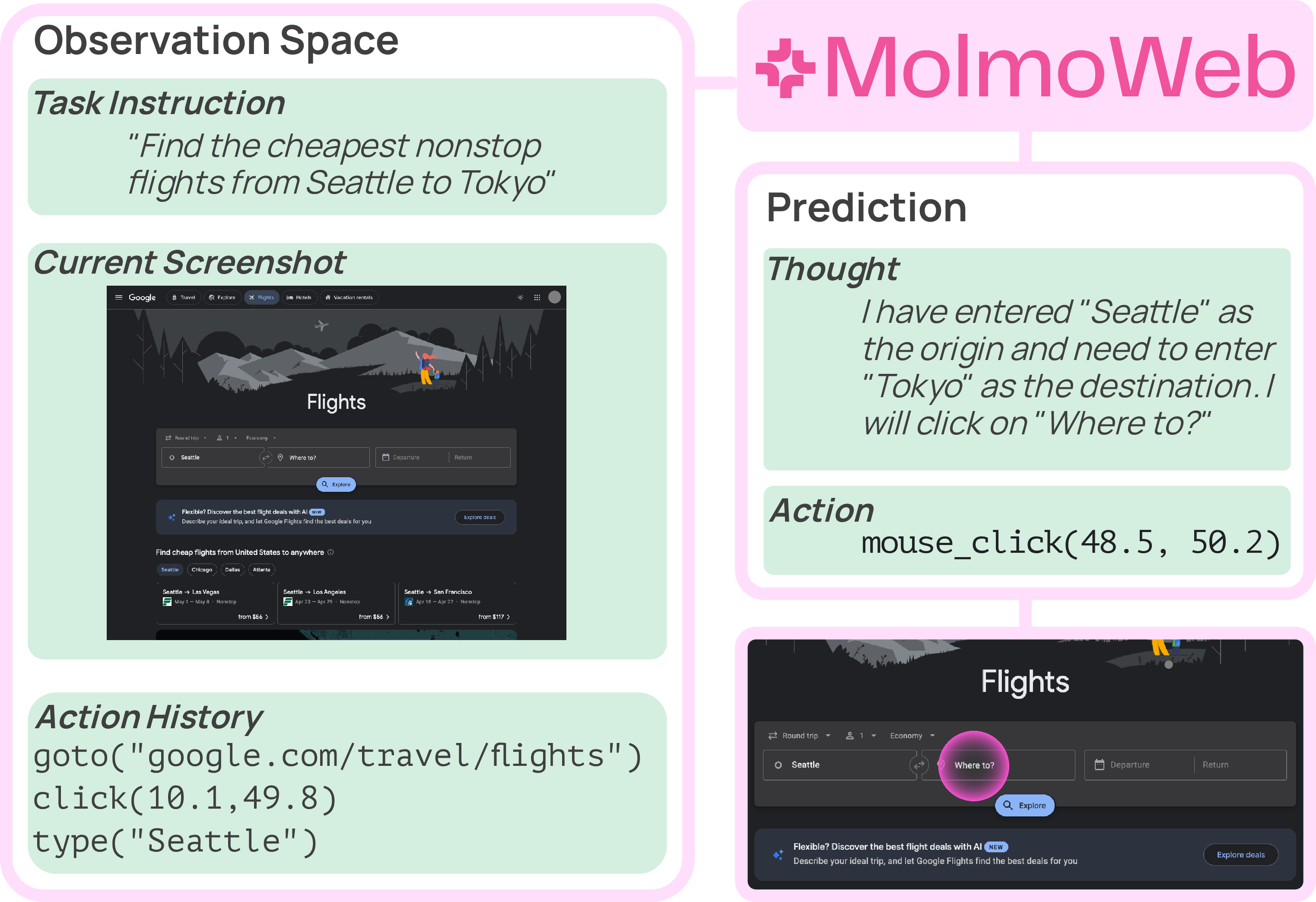
- Action policy: A mapping from observations (e.g., screenshots, instructions) to actions that an agent should execute, conditioned on the task. "MolmoWeb agents operate as instruction-conditioned visual-language action policies: given a task instruction and a webpage screenshot, they predict the next browser action, requiring no access to HTML, accessibility trees, or specialized APIs."
- Action space: The set of all actions available to an agent (e.g., click, type, scroll) with their parameters. "The full action space is described in \cref{tab:actions}."
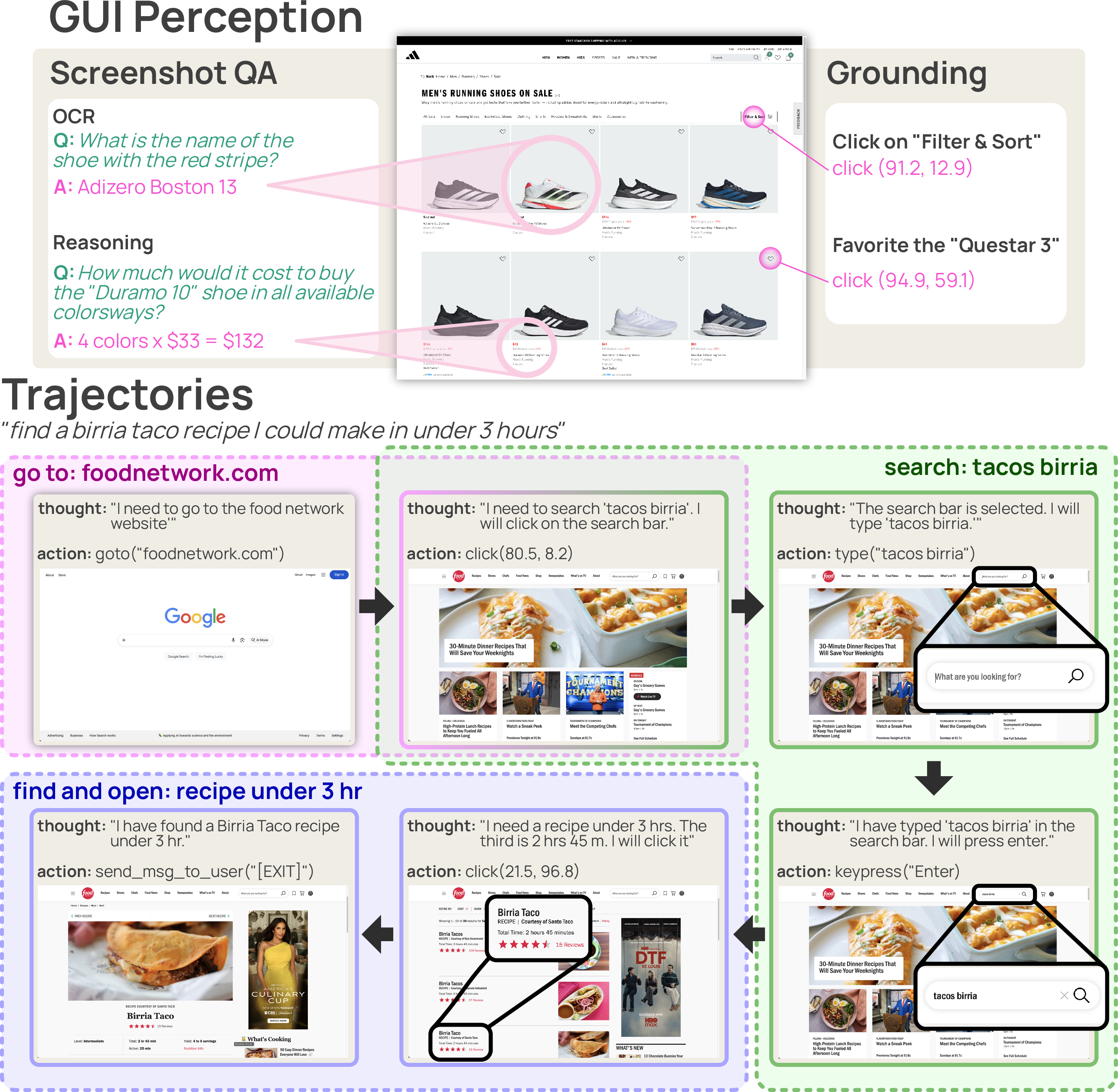
- Affordance queries: Questions focusing on what actions are possible or available in a user interface. "Questions cover three categories: OCR queries about text and values present on the page (e.g., prices, counts, text content), affordance queries about actions available on the page (e.g., 'Where would I find financial news on this page?'), and summarization queries about the overall content or purpose of a page element."
- AxTree agent: An agent that perceives and acts using the accessibility tree representation rather than raw visuals. "We use Gemini-2.5-Flash for the Planner, GPT4-o as the Verifier, and Gemini AxTree agent as the Operator."
- Best-of-N selection: A strategy that runs multiple independent attempts and selects the best outcome according to a judge. "We further demonstrate consistent gains through test-time scaling via parallel rollouts with best-of-N selection, achieving 94.7% and 60.5% pass@4 (compared to 78.2% and 35.3% pass@1)on WebVoyager and Online-Mind2Web respectively."
- Breadth-first exploration: A graph traversal method that explores neighbors level by level to construct a website map. "We first build a directed graph over 500 popular websites via breadth-first exploration: starting from the homepage, we extract the accessibility tree at each page and prompt an LLM to select a diverse set of navigational links (e.g., category pages, search features, content sections), continuing to a depth of four."
- Compositional browser-use skills: Modular UI skills (e.g., find, fill, filter) that can be combined to solve complex tasks. "atomic web skill trajectories providing targeted supervision for compositional browser-use skills,"
- Denormalized coordinates: Converting normalized coordinates back to absolute pixel values for execution. "Mouse actions are parameterized by spatial coordinates normalized to [0, 100], with 2 decimal points, which are denormalized to viewport pixel coordinates at execution time."
- Directed graph: A graph with edges that have direction, used here to model website navigation paths. "We first build a directed graph over 500 popular websites via breadth-first exploration"
- Distillation: Training a model to imitate or transfer knowledge from a stronger model. "Without distilling from other visual web agents, MolmoWeb agents are competitive with or outperform open-weights agents of comparable size, including Fara-7B"
- Document Object Model (DOM): The structured tree representation of a webpage’s elements used by browsers and scripts. "it avoids the brittleness of Document Object Model (DOM) based representations, which vary significantly across websites, frameworks, and even minor page updates"
- Frontier models: The most advanced, large-scale models typically offered as closed APIs. "set-of-marks (SoM) prompting based web agents built on much larger closed frontier models like GPT-4o"
- Greedy sampling: A decoding strategy that selects the highest-probability token at each step without randomness. "Greedy sampling performs significantly worse than random sampling strategies."
- GUI perception: Learning to understand and locate interactive elements and content from graphical user interface screenshots. "GUI perception data teaches the model to identify interactive elements on the page (e.g., buttons, links, input fields, and other controls), understand their function and affordances, and extract information from the page in response to natural language queries."
- LLM judge: A LLM used to automatically evaluate whether a trajectory/task was successful. "We use an LLM judge to evaluate success for each rollout, and we set m=5 to balance accuracy with computational cost."
- Multimodal: Involving multiple data modalities, such as images and text, jointly processed by a model. "a family of fully open and efficient multimodal web agents"
- Node traversal: Generating trajectories by following precomputed paths through a website’s link-graph. "Trajectories from node traversal."
- Node-graph: A graph whose nodes represent webpages (URLs) and edges represent links, used to plan navigation. "Together the instruction-trajectory pair generated via a walk on the node-graph now resembles a goal-directed browser demonstration."
- Normalized coordinates: Scaling coordinates to a fixed numeric range for model prediction. "Spatial coordinates are normalized to [0, 100] during training and denormalized to viewport pixels for browser execution."
- Nucleus sampling (top-p): A decoding strategy that samples from the smallest set of tokens whose cumulative probability exceeds p. "\Cref{tab:sampling_strategies} compares greedy, top-k, and top-p (nucleus) sampling on WebV."
- OCR: Optical Character Recognition; extracting text content from images or screenshots. "Questions cover three categories: OCR queries about text and values present on the page (e.g., prices, counts, text content)"
- Observation space: The information provided to the agent at inference time (e.g., screenshot, instruction, history). "Besides the observation space, other factors contributing to this gap include: (i) differences in model sizes"
- Parallel rollouts: Running multiple independent agent executions concurrently for the same task. "We explore two ways of utilizing more compute at inference time: (i) performing parallel rollouts with a best-of-N selection with an LLM-judge;"
- pass@k: The probability that at least one out of k independent attempts succeeds. "We plot MolmoWeb-4B and MolmoWeb-8B's pass@k performance on the WebVoyager benchmark with max steps of 30 and k=1,...,4"
- Pixel-space coordinates: Coordinates expressed in absolute pixels of the image or screen. "Actions predicted in bid-space are post-processed into pixel-space coordinates (clicks, typing, scrolling)."
- Referring expression grounding: Locating a specific UI element in an image given a natural language description. "GUI perception data consisting of referring expression grounding and screenshot question-answering examples."
- Reinforcement learning (RL): A learning paradigm where agents learn to act by maximizing rewards through interaction. "These massive gains from parallel rollouts suggest (or, perhaps explain to the unsurprised why) self-distillation from best-of-N rollouts and RL might be effective strategies for further improving single rollout performance."
- Set-of-marks (SoM): A prompting/interface strategy where annotated visual marks guide models to specific regions or elements. "set-of-marks (SoM) prompting based web agents built on much larger closed frontier models like GPT-4o"
- Supervised fine-tuning (SFT): Training a model on labeled examples to refine its behavior for a specific task. "We train MolmoWeb end-to-end via supervised fine-tuning (SFT) on all training data described in \cref{sec:data}."
- Test-time scaling: Improving performance by allocating more compute during inference (e.g., more steps, multiple rollouts). "We further demonstrate consistent gains through test-time scaling via parallel rollouts with best-of-N selection"
- Top-k sampling: A decoding strategy that samples from the k most probable tokens. "\Cref{tab:sampling_strategies} compares greedy, top-k, and top-p (nucleus) sampling on WebV."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs for tasks like reasoning and action. "MolmoWeb agents are vision-LLMs (VLMs) trained to serve as instruction-conditioned multimodal action policies for the web."
- Viewport: The visible portion of a webpage within the browser window that is captured in screenshots. "At each step t, the model receives a screenshot of the current browser viewport along with the task instruction."
Collections
Sign up for free to add this paper to one or more collections.

