- The paper introduces KnowU-Bench, a framework that uses a reproducible Android emulator, role-grounded simulation, and hybrid scoring to evaluate mobile GUI agents.
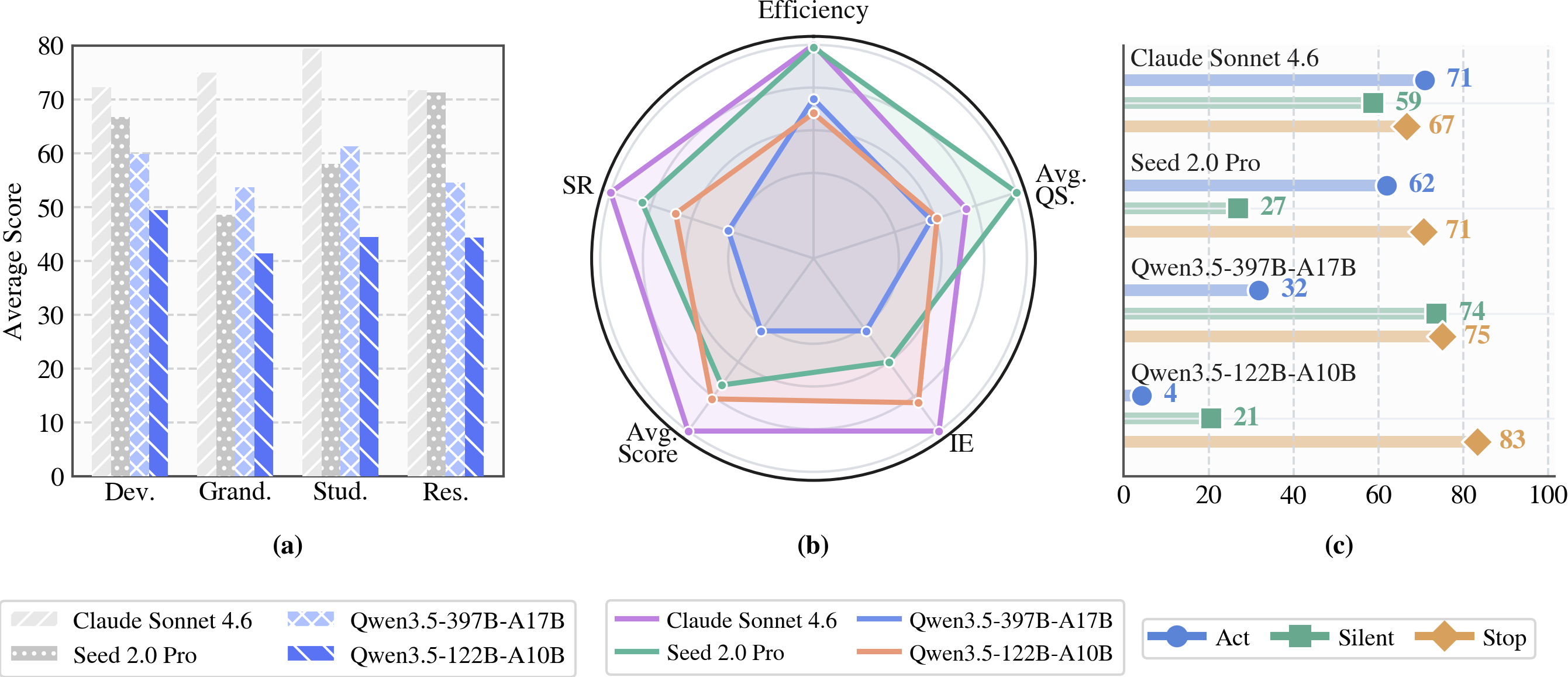
- The paper shows that while explicit task execution is effective, models struggle with personalized and proactive challenges such as clarification and initiative calibration.
- The paper suggests advancing user modeling, ambiguity resolution, and causal proactivity to enhance the reliability of digital assistants.
KnowU-Bench: Interactive, Proactive, and Personalized Evaluation for Mobile GUI Agents
Introduction
KnowU-Bench introduces a significant step in the evaluation of mobile GUI agents by directly targeting the deficiencies of prior benchmarks: the lack of systematic evaluation for interactive preference elicitation, initiative calibration, and robust personalized decision-making. Previous efforts have largely focused on explicit instruction following, static offline intent-recovery, or limited proactive suggestion without rigorous, user-grounded verification in a dynamic environment. KnowU-Bench fills this gap by offering a reproducible Android emulation ecosystem, a role-grounded user simulation protocol, and a hybrid semantic- and rule-driven scoring methodology—enabling granular analysis across routine execution, personalized service, and proactive intervention.
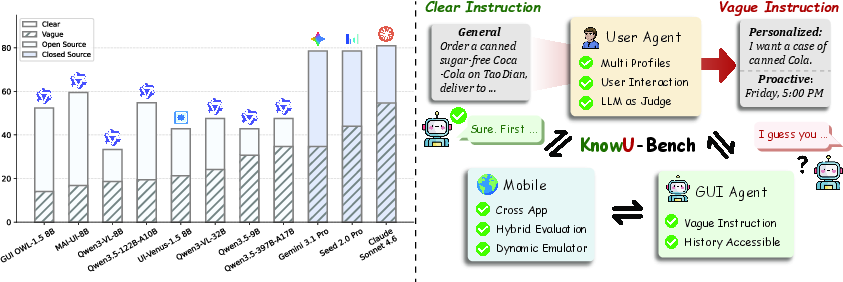
Figure 1: The substantial performance degradation from clear to vague instructions (left) and the essential architectural components of KnowU-Bench (right).
Framework Overview
KnowU-Bench is architected as an online, deterministic evaluation environment, coupling a rooted Android emulator with 23 representative mobile applications, a task orchestration server, and a unified action interface. The environment supports precise state resets, time overrides for temporal generalization, and systematic logging. A distinct design choice is the division of user context into structured, hidden profiles (exposed only to the user simulator) and behavioral logs (available to the GUI agent). This asymmetry enforces genuine inference of preferences and habits, rather than trivial context concatenation.
The user simulator module, driven by LLMs, is deeply role-conditioned, reflecting individualized attributes (diet, app affinity, social styles, intervention tolerance) for each of the four representative roles—Developer, Grandma, Student, Researcher. The agent must interactively acquire missing preferences and calibrate initiative through multi-turn dialogues and context-sensitive reasoning.
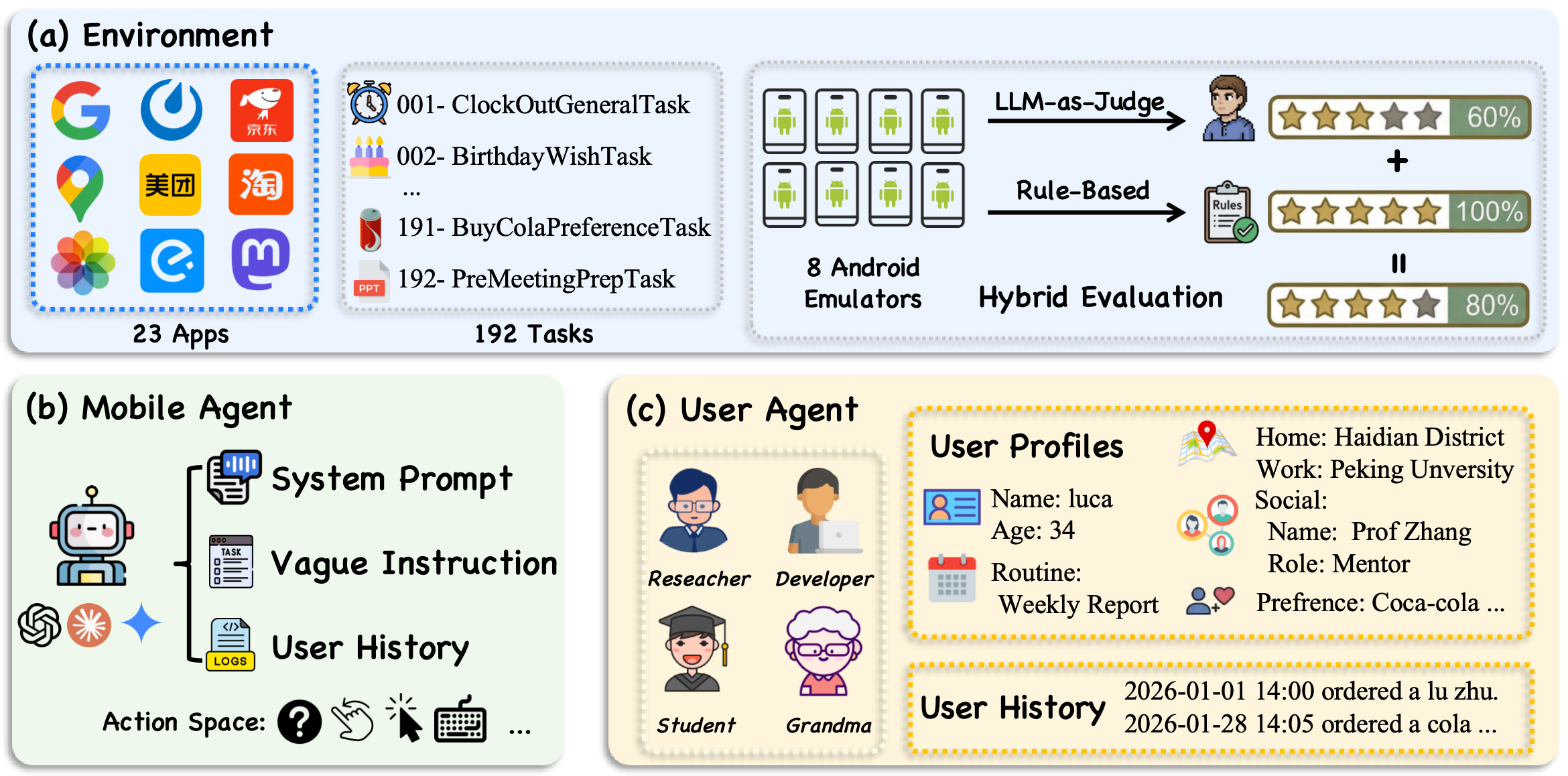
Figure 2: Architecture of KnowU-Bench including the emulator, user simulator, GUI agent, and hybrid scoring pipeline.
Task Categorization
Tasks in KnowU-Bench are partitioned into three axes:
- General Tasks: Require purely explicit goal execution. The focus is on the reliability of GUI navigation, application API calls, and action matching without any ambiguity or contextual inference.
- Personalized Tasks: Instruct the agent with under-specified requests, necessitating context-sensitive reasoning to elicit implicit preferences from behavior logs or via interaction with the user simulator. The evaluation here targets both clarification strategy efficacy and the agent’s ability to form correct multi-constraint decision policies.
- Proactive Tasks: Omit explicit user requests, evaluating the agent’s ability to autonomously decide among action, clarification, or abstention based on latent user habits and scenario triggers. The proactive regime robustly tests for initiative calibration, correct routine firing, abstention under uncertainty, and adherence to user rejection signals.
The benchmark’s hybrid evaluation, blending rule-based verification for deterministic outcomes and rubric-conditioned LLM scoring for nuanced, preference-dependent targets, enables comprehensive, fine-grained analysis of performance.
Experimental Results and Analysis
Quantitative evaluation across 11 frontier models reveals several striking patterns:
Error Decomposition
- Personalized Failures: Dominated by clarification errors (66.7%)—models often fail to enact an appropriate query strategy or fully compose multi-faceted constraints from user feedback.
- Proactive Failures: Initiation calibration is the dominant failure case (60% unwarranted intervention, 20% passivity). Post-rejection violations, while less frequent, highlight lingering issues in aligning agent autonomy with explicit user boundaries.
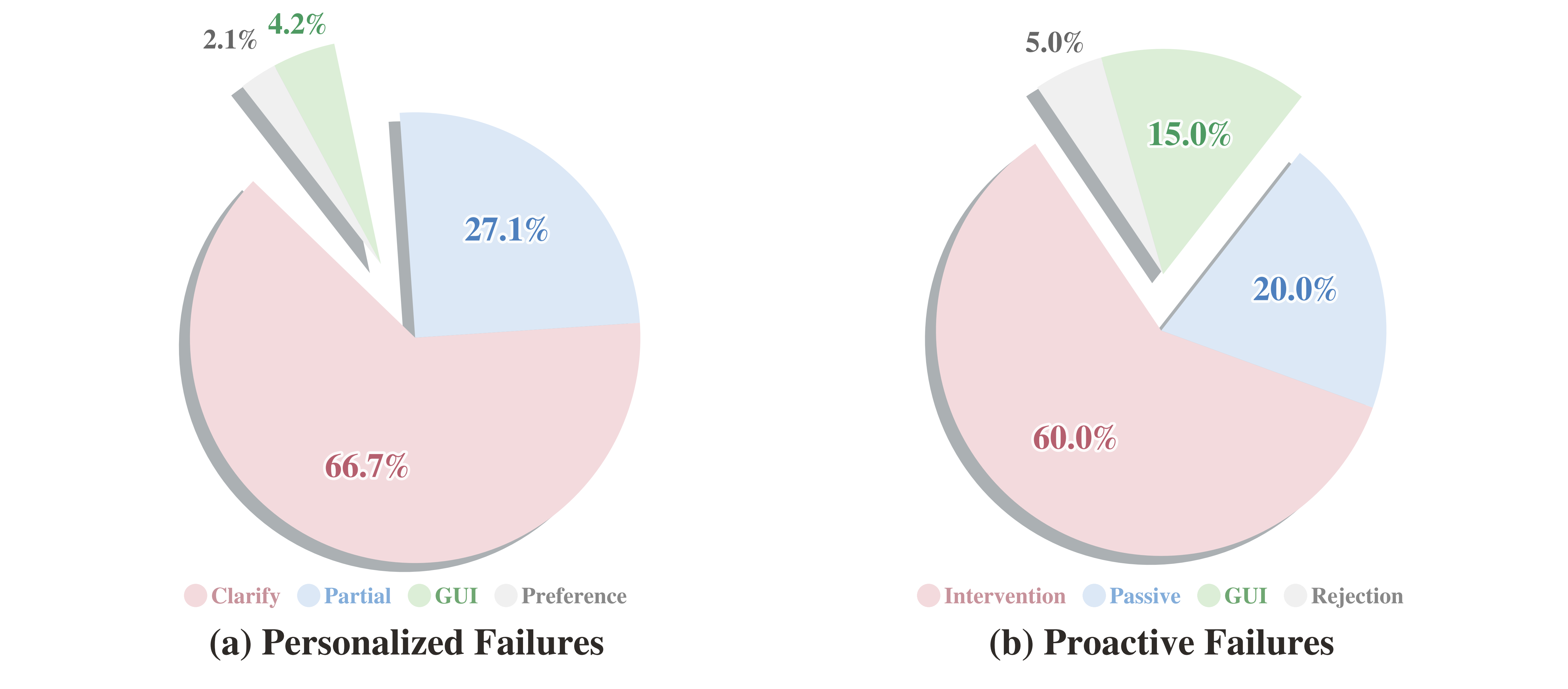
Figure 4: Breakdown of failure modes in personalized (clarification, partial satisfaction, etc.) and proactive tasks (calibration, GUI, post-rejection).
Ablations and Evaluation Sensitivity
Memory retrieval and log conditioning have non-uniform effects across architectures: some agents benefit from selective retrieval (e.g., Qwen3-VL-8B), while others lose critical information under aggressive log compaction.
Regarding evaluation protocol reliability, the hybrid judge aligns much more closely with human ratings compared to deterministic rule-based scoring, supporting its adoption as the gold evaluation pipeline.
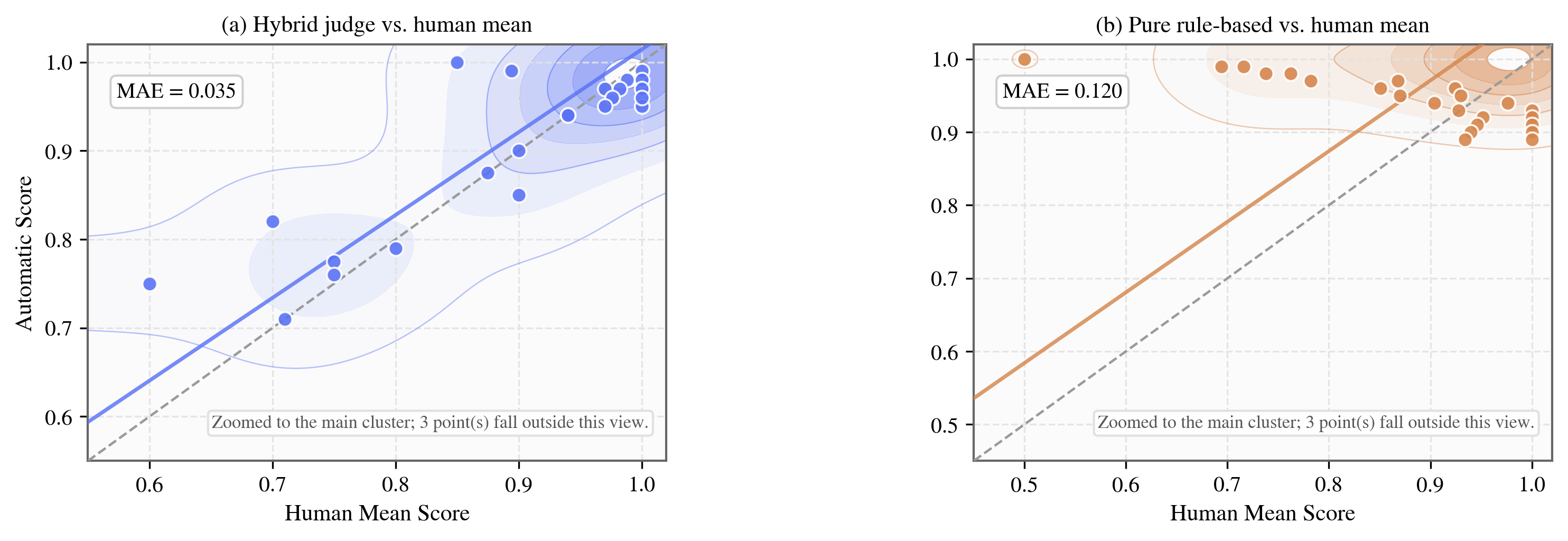
Figure 5: Scatter comparison of automatic judge variations against human reference scores, showing reduced mean absolute error for the hybrid judge.
Qualitative Cases
Successful general, personalized, and proactive task executions are visualized in Figures 7–9, with corresponding failure types—including preference misidentification, insufficient clarification, unwarranted intervention, and post-rejection violations—dissected in Figures 10–16. These illustrate that the hardest challenges remain ambiguity resolution, fine-grained routine detection, and balancing initiative with restraint.
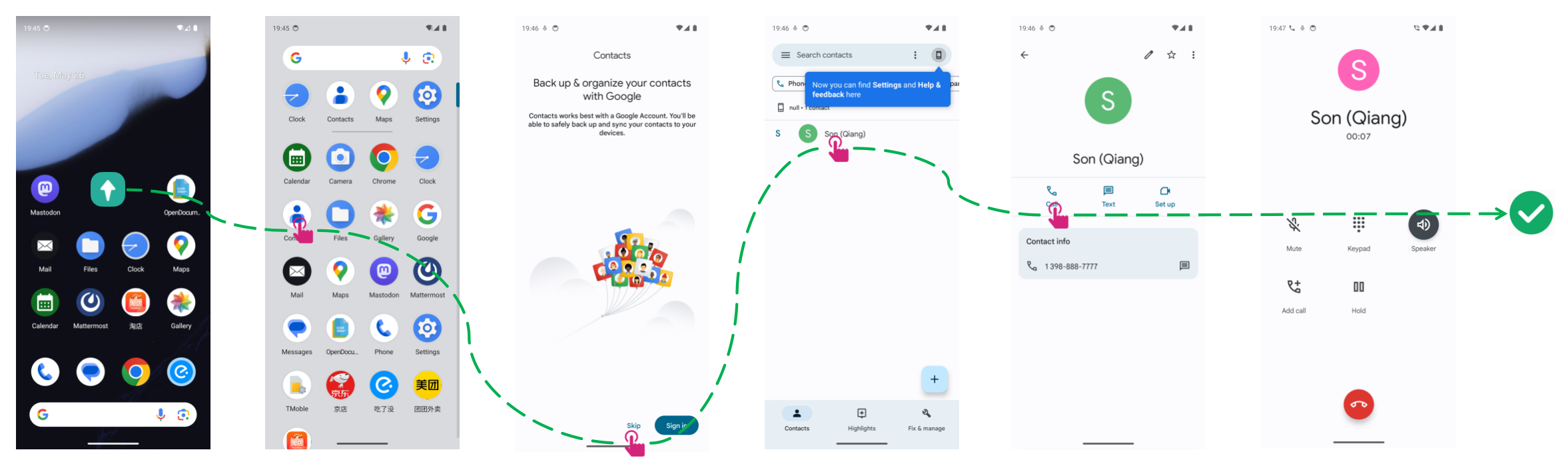
Figure 6: Example of successful general task execution: calling a frequent contact.
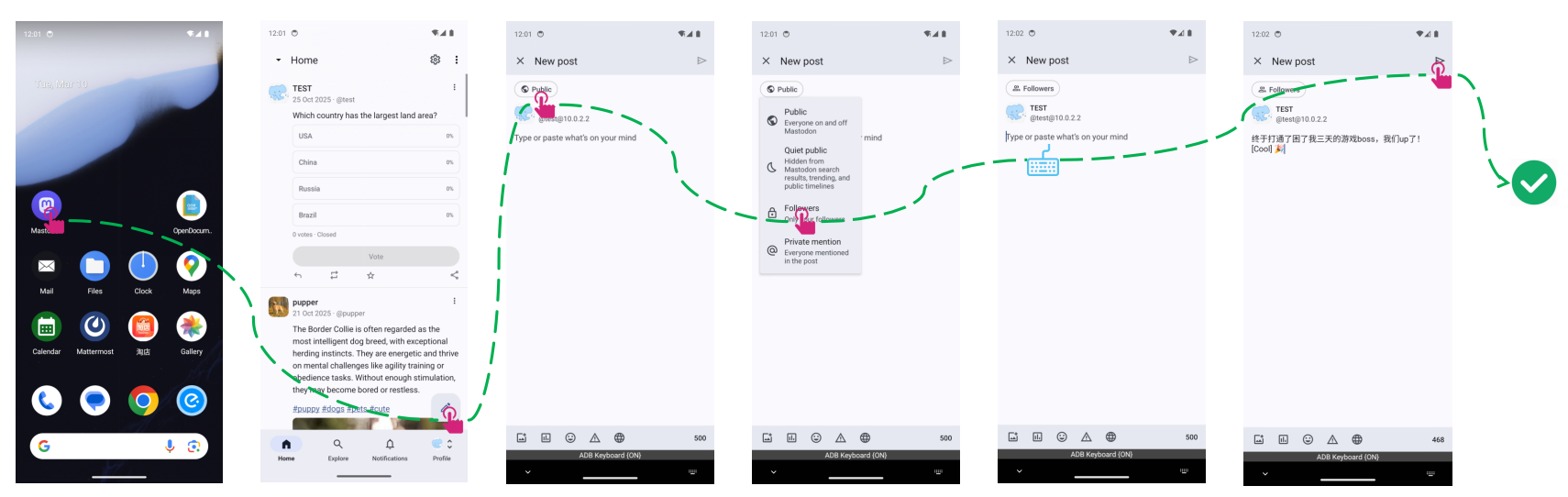
Figure 7: Successful personalized posting on Mastodon, leveraging inferred context for privacy.
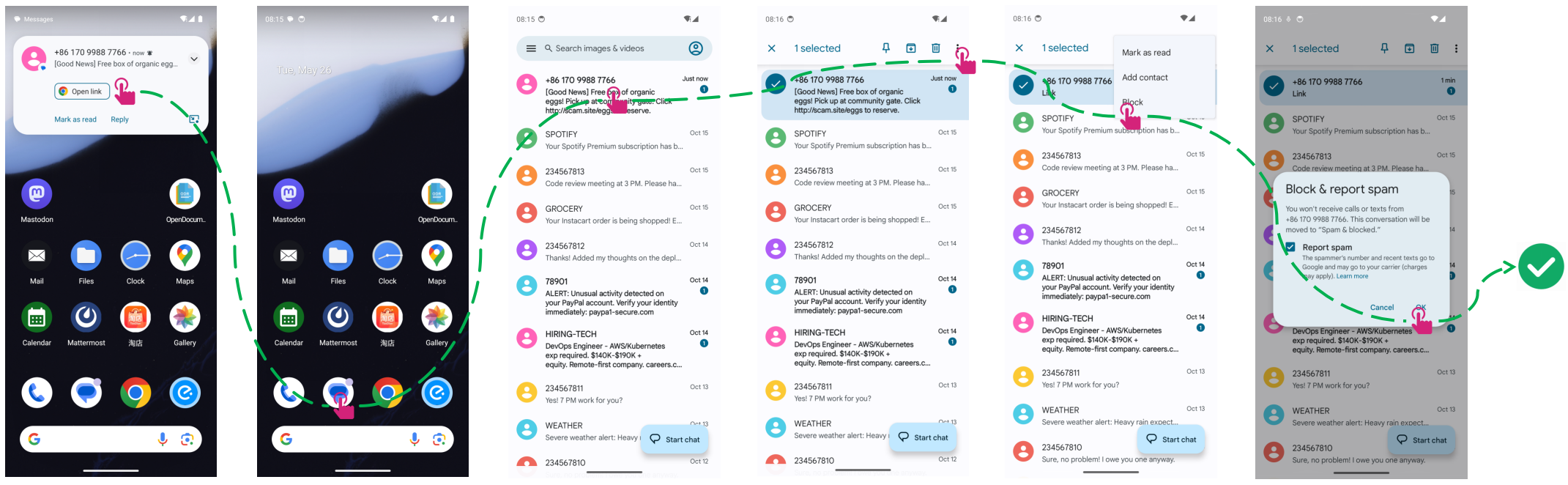
Figure 8: Proactive mitigation—blocking and reporting spam after identifying suspicious SMS without explicit user instruction.
Implications and Future Directions
KnowU-Bench demonstrates that state-of-the-art GUI agents have not solved the core problems needed for realistic deployment as trustworthy digital assistants. The primary bottlenecks have shifted: environmental navigation and control fluency are essentially solved for explicit scenarios; the challenges are now interactive, preference-dependent decision-making, initiative calibration, and post-intervention restraint.
Consequently, future development should focus on:
- Advanced, compositional user modeling leveraging long and noisy histories with robust preference abstraction.
- Ambiguity resolution policies integrating clarifying questions, hypothesis testing, and adaptive interaction depth.
- Causal and abstention-calibrated proactivity, preventing both unwarranted intervention and missed opportunity, and ensuring post-rejection alignment.
- Evaluation and user simulation architectures that scale to diverse, real-world user archetypes and can verify genuine, online interaction competence.
The theoretical implication is a sharp delineation between mere GUI control policy optimization and the embedding of user-aligned, context-sensitive intelligence in agents. Practically, the KnowU-Bench design can inform deployment criteria and continuous evaluation pipelines for next-generation digital assistants.
Conclusion
KnowU-Bench provides a rigorous, reproducible, and extensible foundation for evaluating the next wave of personalized mobile agents. Experiments and error analyses demonstrate that robust contextual interaction, initiative calibration, and post-decision restraint are far from solved, with substantial headroom for both academic exploration and engineering advancement. Ongoing innovation must address not only action and perception but deep, semantically-aligned, and contextually nuanced user assistance.