- The paper introduces UserBench, a detailed Gym environment that tests LLM agents on realistic, multi-turn user interactions.
- It employs a multi-stage pipeline with data gathering, tool augmentation, and controlled simulation to examine preference elicitation and dialogue accuracy.
- Empirical findings reveal that heightened user preference complexity degrades model performance, underscoring a critical gap in user alignment.
UserBench: A Gym Environment for Evaluating User-Centric Agents
The development of LLM-based agents has advanced tool-augmented reasoning and autonomous task execution, but the field lacks rigorous evaluation of agents' ability to align with real user intent—especially when user goals are underspecified, incremental, or indirect. Existing agentic benchmarks focus on tool use and task completion, neglecting the complexities of human-agent collaboration where intent is co-constructed and often ambiguous. UserBench addresses this gap by introducing a gym environment that simulates realistic, multi-turn, preference-driven user interactions, requiring agents to proactively clarify, interpret, and adapt to evolving user needs.
UserBench Design and Construction
UserBench is implemented atop the Gymnasium framework, focusing on travel planning as a representative domain. The environment is constructed through a multi-stage pipeline:
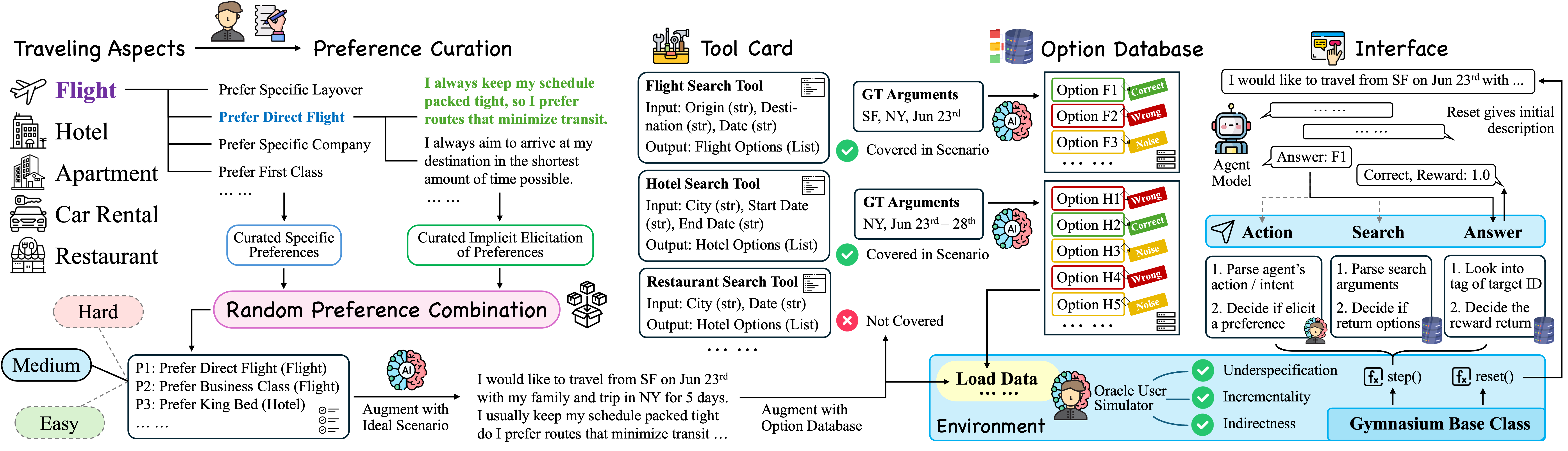
Figure 1: The pipeline of UserBench, including data gathering, preference curation, tool augmentation, environment setup, and interface design.
- Data Gathering: Five travel aspects (flight, hotel, apartment, car rental, restaurant) are identified. For each, a diverse set of real-world preferences is curated, each paired with multiple implicit, naturalistic expressions. Preferences are combined randomly to generate scenarios of varying complexity, stratified into three difficulty tiers.
- Tool Augmentation: Each aspect is associated with a tool simulating a database search, returning a mix of correct, wrong, and noise options. This ensures controlled, reproducible outputs and isolates user-centric reasoning from the confounds of real-time data retrieval.
- Environment Simulation: The environment simulates an oracle user who reveals preferences only in response to targeted agent queries or after a fixed number of off-topic turns. All preferences are expressed implicitly, requiring agents to interpret indirect cues.
- Agent Interface: Agents interact via three actions:
search (querying the database), action (asking the user clarifying questions), and answer (submitting recommendations). The environment enforces strict turn and action constraints, and supports both single-choice and multi-choice evaluation settings.
Evaluation Protocol and Metrics
UserBench evaluates both open- and closed-source LLM agents (e.g., GPT-4o, Gemini-2.5-Pro, Claude-4-Sonnet, Deepseek-V3, Qwen3, Llama3) under deterministic decoding (temperature 0.0). The main metric is a normalized score reflecting the quality of selected options per aspect: 1.0 for the best, 0.8 for correct-but-not-best, and 0.0 otherwise. Auxiliary metrics include:
- Best Exist Rate: Fraction of aspects where the best option is selected.
- Correct Exist Rate: Fraction of aspects with any correct option.
- Valid Search/Action Attempt: Proportion of syntactically valid and preference-relevant queries.
- Preference Elicited: Percentage of ground-truth preferences revealed, split into active (elicited by agent queries) and passive (proactively revealed by the environment).
Empirical Findings
Difficulty Stratification and Model Robustness
UserBench's difficulty tiers (Easy, Medium, Hard) are defined by the number and distribution of user preferences. Model performance degrades as scenario complexity increases, confirming the environment's ability to stress-test user-centric reasoning.
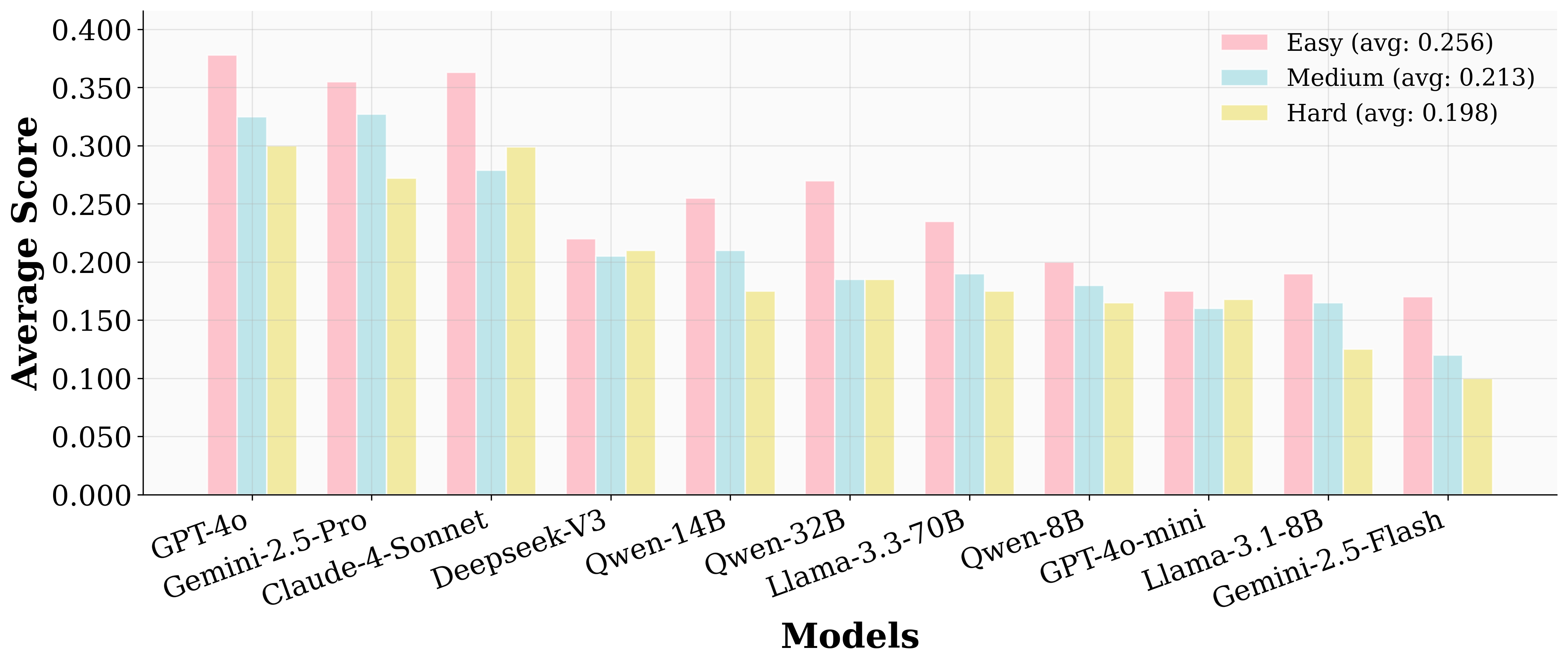
Figure 2: The score distribution of tested models across three difficulty tiers.
Preference Complexity as the Core Challenge
Performance is more sensitive to the number of preferences per aspect than to the number of aspects. When the aspect count is fixed, increasing preferences per aspect leads to a monotonic decline in scores.
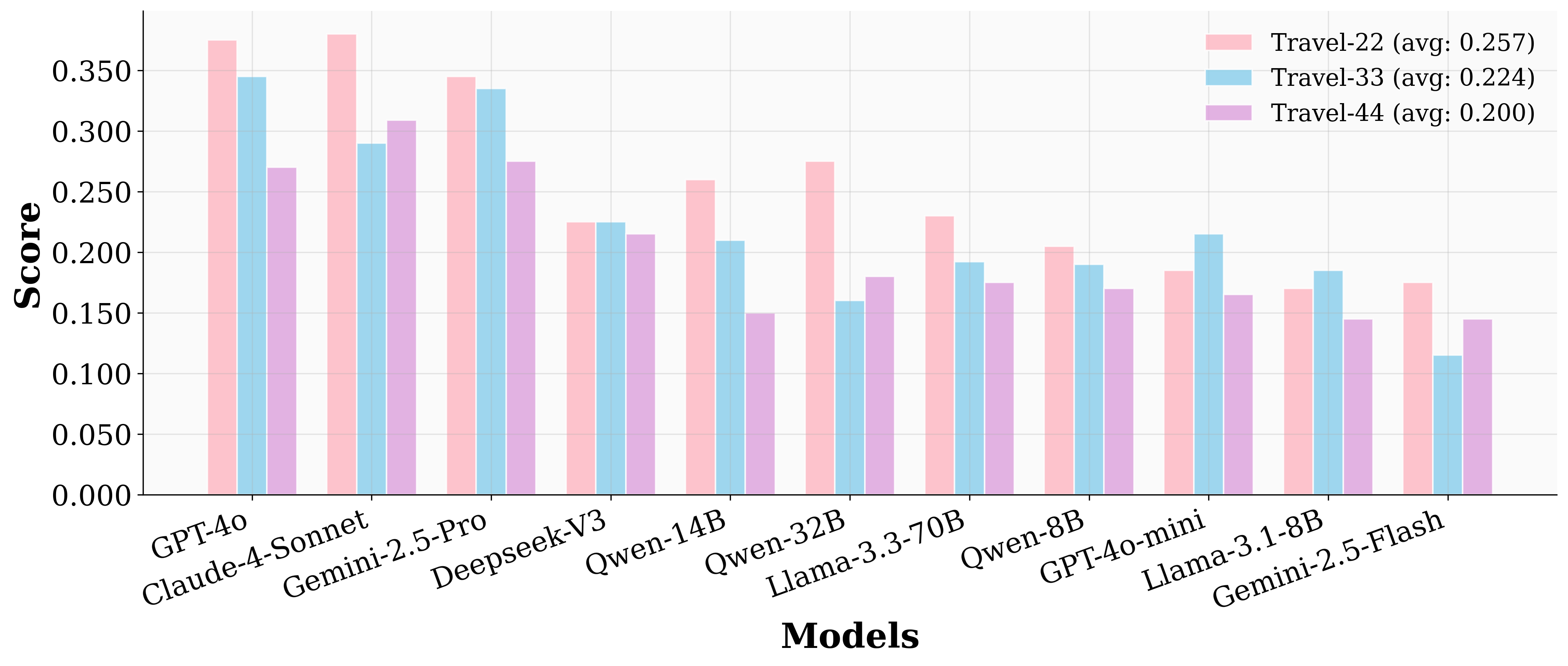
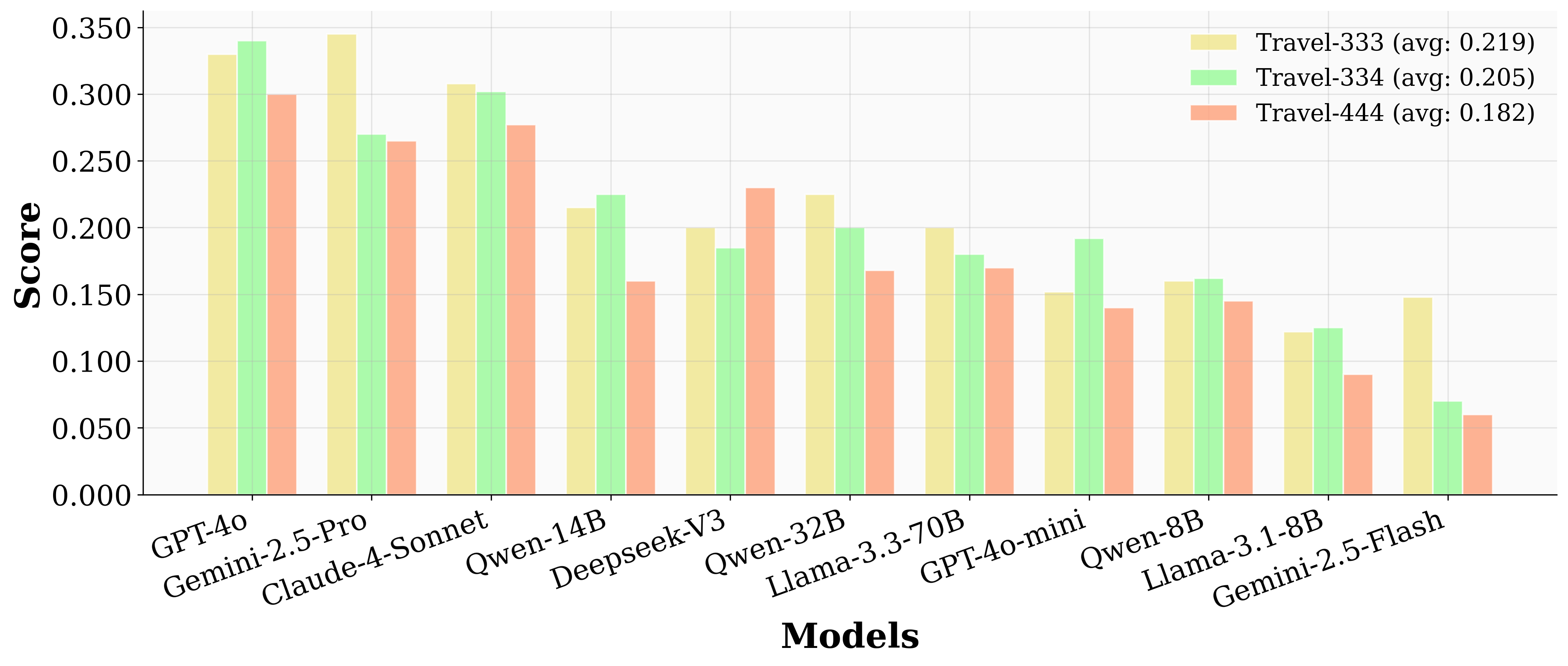
Figure 3: When aspect number is settled, more user preferences generally lead to less scores.
Conversely, distributing the same number of preferences across more aspects improves performance, indicating that concentrated preference complexity is a primary bottleneck.
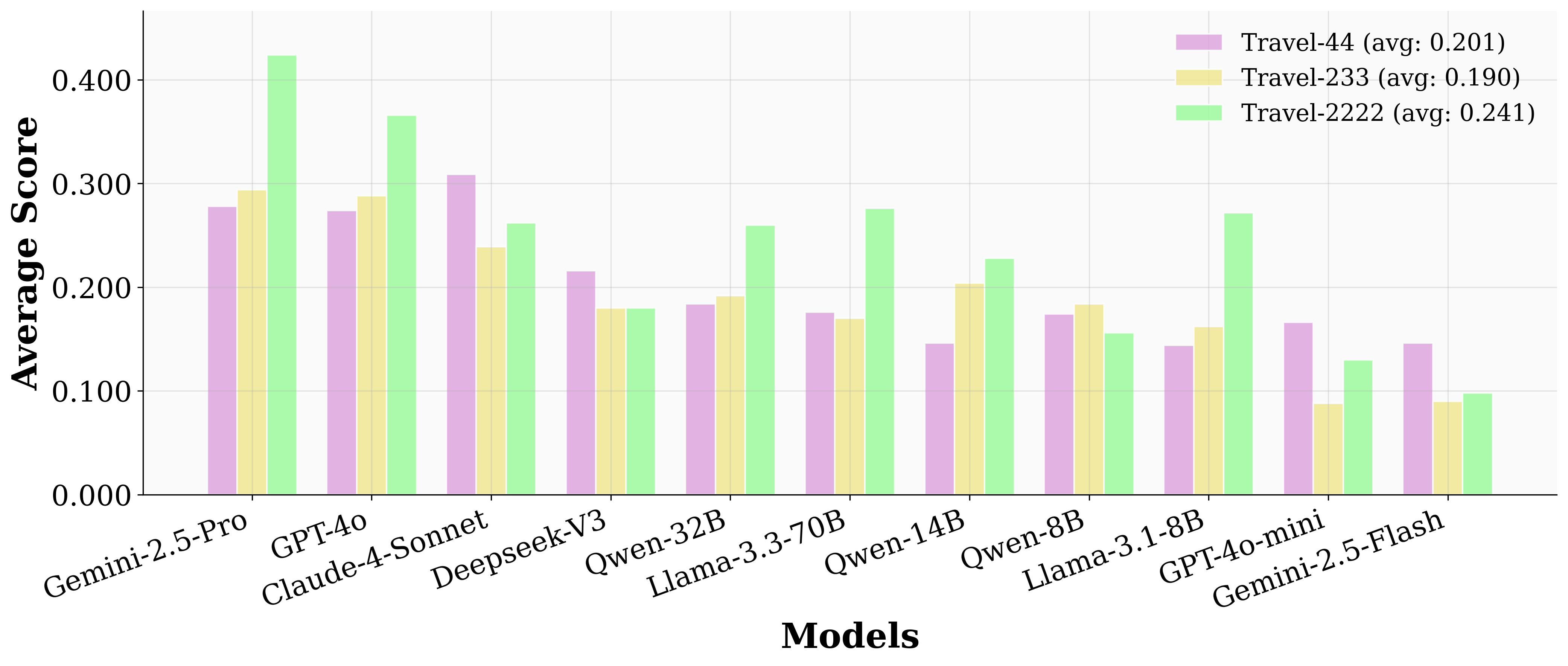
Figure 4: When total user preferences are settled, less preferences per aspect generally lead to higher scores.
Interaction Efficiency and Preference Elicitation
Despite high valid search rates (>80% for top models), valid action rates and preference elicitation remain low. Even the best models elicit less than 30% of user preferences through active querying, and only 20% of answers fully align with all user intents in the single-choice setting. This demonstrates a significant gap between tool-use proficiency and user alignment.
Turn and Sampling Analysis
Allowing more interaction turns does not consistently improve performance; in some cases, it leads to degradation due to repetitive or off-topic dialogue.
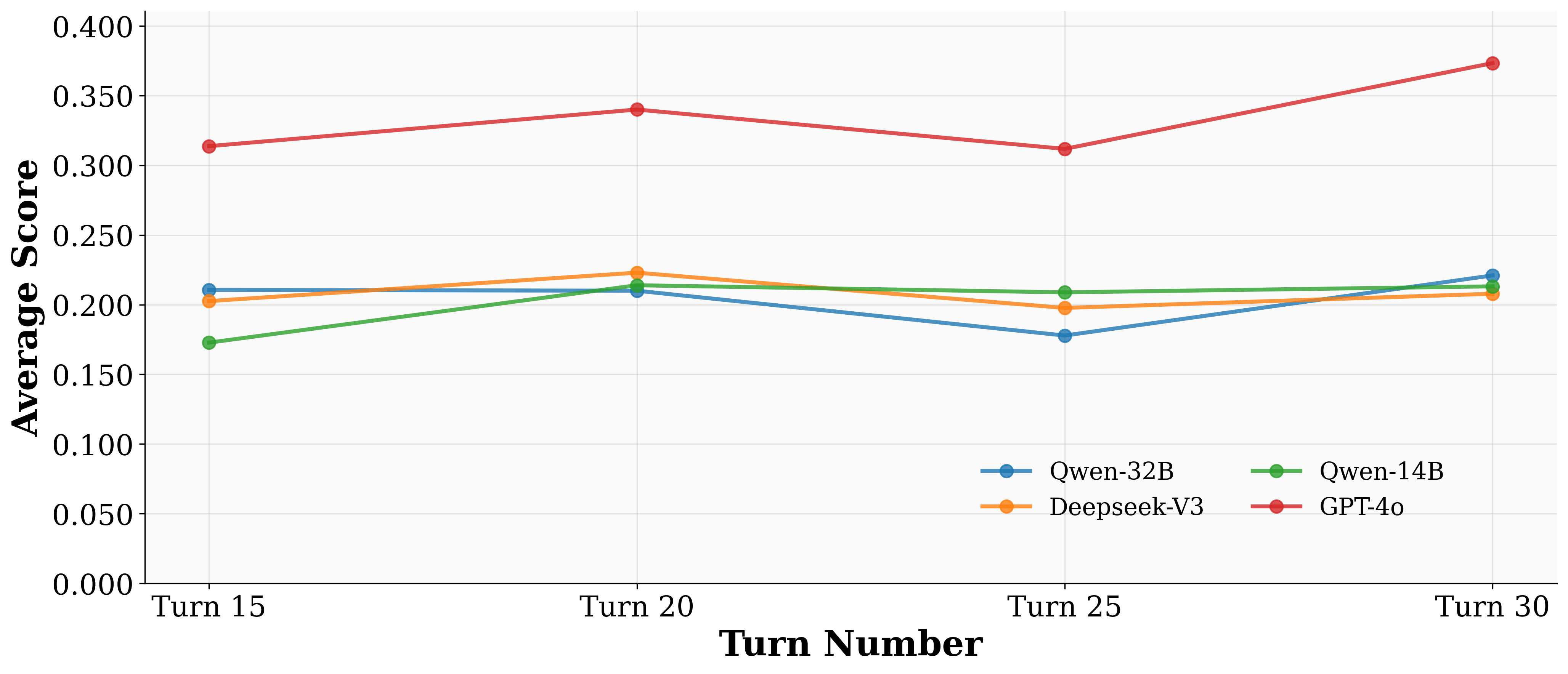
Figure 5: Increasing the number of turns allowed in interaction does not necessarily lead to better performance across models.
Increasing the number of sampled responses (pass-k) raises the maximum achievable score but does not improve the average, highlighting instability and reliance on sampling luck rather than robust reasoning.
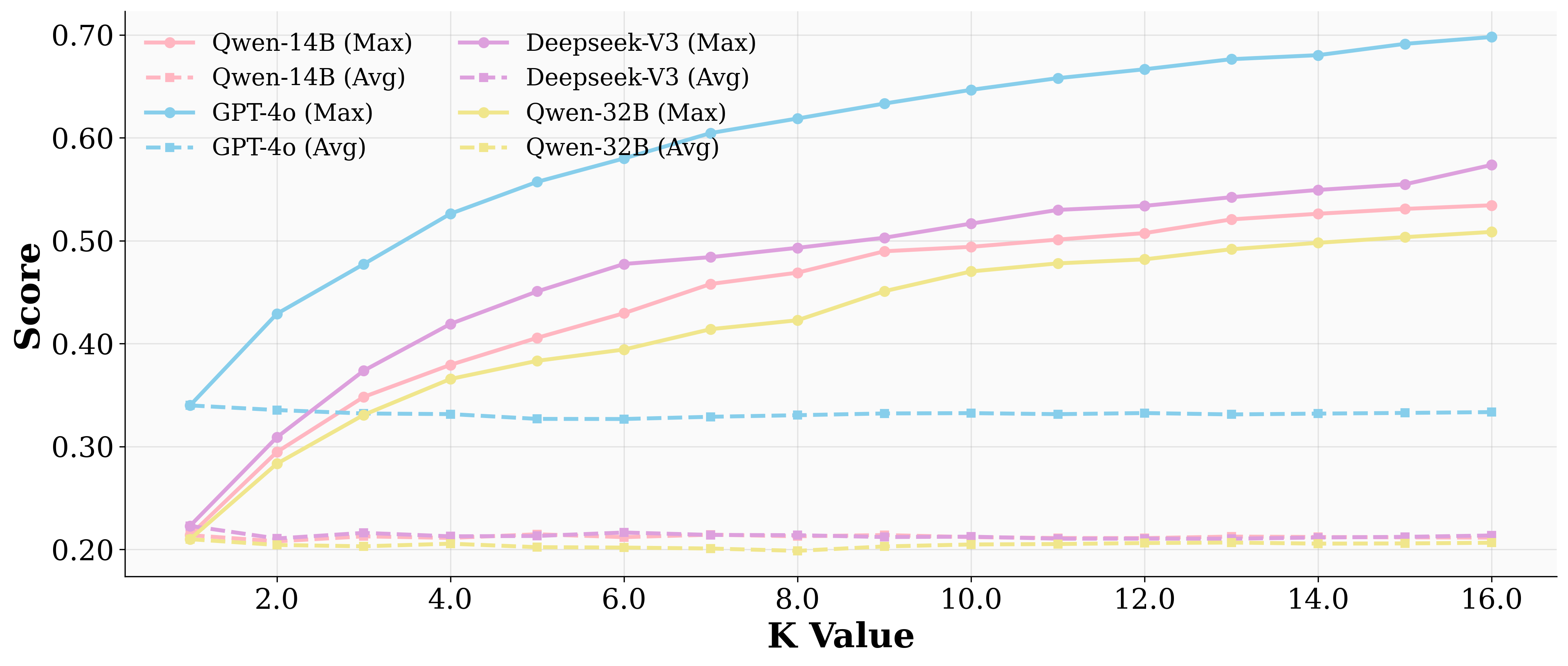
Figure 6: Increasing the number of sampling time raises the maximum score but average score shows little change or even slightly drops.
Choice Ablation
Reducing the number of distractor (wrong/noise) options yields only modest gains for strong models, and can even harm smaller models. This suggests that the core challenge is not distractor interference but the need for genuine preference understanding and integration.
Qualitative Case Studies
Positive cases (e.g., Qwen3-32B, Claude-4-Sonnet) demonstrate the ability to recover from vague queries, elicit implicit preferences through targeted follow-ups, and integrate user feedback into optimal recommendations. Negative cases (e.g., Deepseek-V3) reveal failure modes such as shallow user modeling, redundant queries, and premature or repeated suboptimal selections.
Implications and Future Directions
UserBench exposes a critical limitation of current LLM agents: proficiency in tool use does not translate to user-centric collaboration. The low rates of preference elicitation and alignment, even for state-of-the-art models, indicate that instruction tuning and tool-augmented training are insufficient for robust user modeling. The environment's modularity and compatibility with RL frameworks make it suitable for developing and evaluating agents trained with reward functions that explicitly balance efficiency (timely responses) and effectiveness (comprehensive preference elicitation).
UserBench's design supports both evaluation and training, enabling fine-grained behavioral analysis and reinforcement learning with turn-wise rewards. This aligns with emerging trends in RL for agentic LLMs, where reward shaping can penalize late preference discovery and reward proactive, user-aligned interaction.
Conclusion
UserBench provides a rigorous, scalable, and extensible environment for evaluating and training user-centric agents. By simulating realistic, multi-turn, preference-driven interactions with underspecified, incremental, and indirect user goals, it reveals a substantial gap between current LLM agent capabilities and the requirements of true collaborative intelligence. The findings motivate future research on agent architectures, training objectives, and evaluation protocols that prioritize user alignment, adaptive clarification, and communicative intelligence. UserBench is positioned as a foundational resource for advancing the development of agents that are not only capable task executors but also effective, adaptive collaborators.

