ColorAgent: Building A Robust, Personalized, and Interactive OS Agent
Abstract: With the advancements in hardware, software, and LLM technologies, the interaction between humans and operating systems has evolved from the command-line interface to the rapidly emerging AI agent interactions. Building an operating system (OS) agent capable of executing user instructions and faithfully following user desires is becoming a reality. In this technical report, we present ColorAgent, an OS agent designed to engage in long-horizon, robust interactions with the environment while also enabling personalized and proactive user interaction. To enable long-horizon interactions with the environment, we enhance the model's capabilities through step-wise reinforcement learning and self-evolving training, while also developing a tailored multi-agent framework that ensures generality, consistency, and robustness. In terms of user interaction, we explore personalized user intent recognition and proactive engagement, positioning the OS agent not merely as an automation tool but as a warm, collaborative partner. We evaluate ColorAgent on the AndroidWorld and AndroidLab benchmarks, achieving success rates of 77.2% and 50.7%, respectively, establishing a new state of the art. Nonetheless, we note that current benchmarks are insufficient for a comprehensive evaluation of OS agents and propose further exploring directions in future work, particularly in the areas of evaluation paradigms, agent collaboration, and security. Our code is available at https://github.com/MadeAgents/mobile-use.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ColorAgent, a smart helper for phones that can understand what you want, tap and swipe on apps like a human, handle long and complicated tasks, and even chat with you to figure out unclear requests. It’s built to be robust (works reliably), personalized (adapts to you), and interactive (asks questions when needed).
What questions are the researchers asking?
They focus on three main goals:
- How can we train a phone agent to carefully plan and execute many steps in a row, without getting lost or stuck?
- How can we make the agent more than a “task robot” so it understands your preferences and talks with you when your request is vague?
- Which design choices (training methods and agent architecture) make the agent more accurate, stable, and better at handling real-world apps?
How did they build and train the agent?
The team used both new training methods and a “team-of-agents” design so the system can deal with complex situations like a person would.
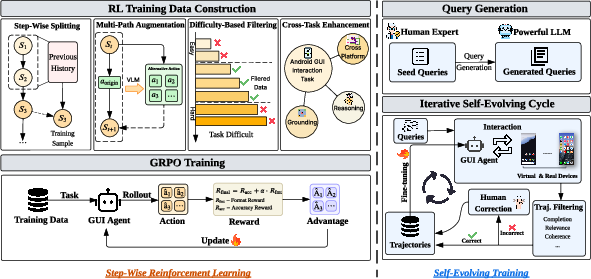
Teaching the agent step by step (Step-wise Reinforcement Learning)
- Reinforcement Learning (RL) is like learning by trial and error: try an action, see if it helps, and learn from feedback.
- “Step-wise” RL teaches the agent one move at a time (like practicing each turn in a maze), not just the final goal. This helps it get good at the small decisions that build into a full task.
- They score the agent’s responses using simple rules:
- Format: did the agent produce a clear plan, a short explanation, and a machine-friendly action?
- Accuracy: did it choose the right action (like the correct button) and the right details (like the right text or swipe direction)?
- They use a training trick called GRPO (Group Relative Policy Optimization), which compares a batch of different answers to the same problem, then nudges the model toward the better ones. Think of it like grading several attempts and boosting the best approach.
Letting the agent create its own practice (Self-evolving Training)
- After the step-wise learning, the agent starts generating its own practice tasks and solutions (like making its own worksheets).
- It rolls out (tries) multiple ways to solve a request across both virtual phones and real devices.
- A set of “quality checkers” filters out bad or messy attempts. Mistakes get fixed and added back into training.
- This loop keeps improving the agent without needing tons of manual labeling.
Why one agent isn’t enough
A single agent often struggles with:
- Generalization: small changes in the app’s interface can confuse it (for example, a search box that needs two taps instead of one).
- Memory and consistency: long tasks need remembering past steps (like comparing prices across different shopping apps).
- Error recovery: if it clicks the wrong thing, it may wander instead of correcting itself quickly.
A team-of-agents design (Multi-agent Framework)
To fix those problems, ColorAgent uses a few specialized helpers:
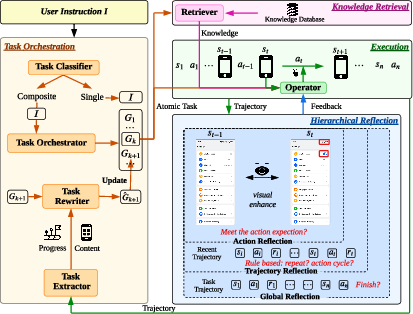
- Knowledge Retrieval: like checking a cheat sheet or manual. It pulls relevant tips (for example, “Red means high priority in this app”) to guide actions.
- Task Orchestration: like a project manager. It breaks big goals into smaller steps (atomic tasks), keeps track of progress, and passes important information from one step to the next.
- Hierarchical Reflection: like having three levels of “spellcheck”:
- Action Reflector: checks if a single move did what it should (before/after screenshots).
- Trajectory Reflector: checks recent steps (last few actions) to catch drift or confusion.
- Global Reflector: at the end, verifies if the whole task is truly done; if not, it tells the agent what to fix.
Making the agent warm and personal
The agent isn’t just a tool—it tries to be a helpful partner:
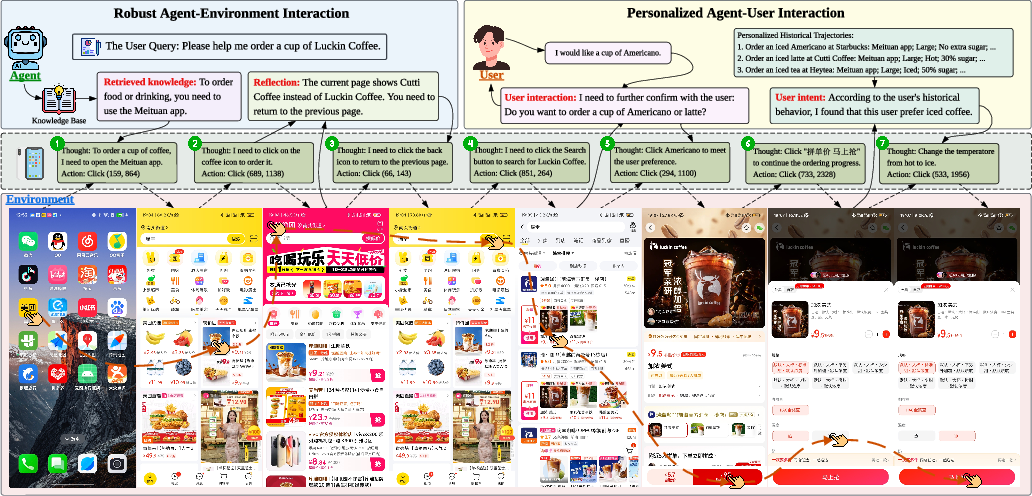
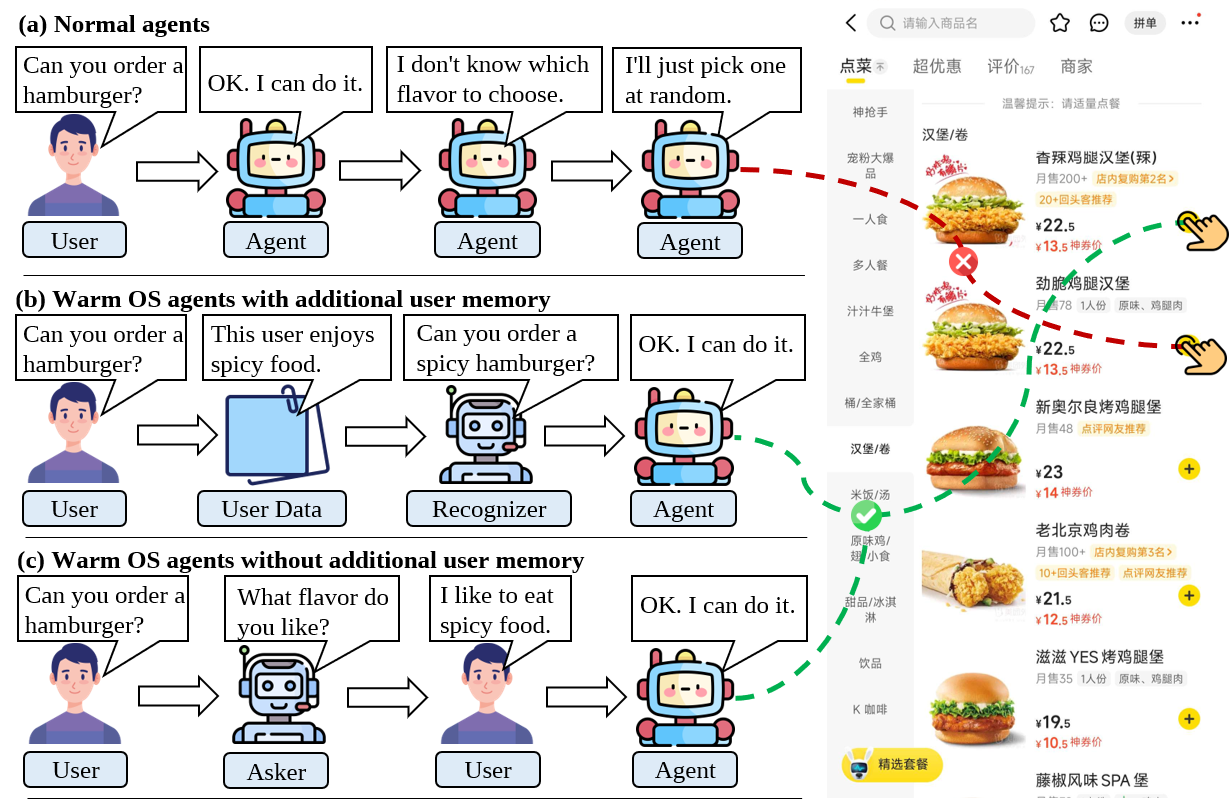
- Personalized Intent Recognition: if it has access to your history or profile, it can tailor actions. For example, when you say “order a burger,” it might choose your usual favorite if your past orders show you prefer spicy chicken.
- Proactive Engagement (Ask Agent): if your request is unclear and there’s no memory to rely on, the agent decides when to ask and how to ask. For instance, “Do you want a beef or chicken burger?” It only asks when needed, otherwise it proceeds.
What did they find?
ColorAgent was tested on two popular Android benchmarks:
- AndroidWorld: 77.2% success rate (new state of the art)
- AndroidLab: 50.7% success rate (also top-tier)
Why these scores matter:
- They show the agent can handle lots of real app tasks reliably (tapping, typing, swiping, searching, navigating).
- The improvements come from both the training methods and the multi-agent framework. Training boosted the model’s raw skill (seeing, reasoning, acting). The framework added planning, memory, and recovery, which made it stronger in longer, messier tasks.
Other notable findings:
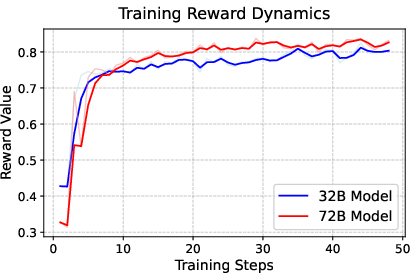
- Bigger models aren’t always better. A very large model fit the training data well but didn’t generalize as nicely as a slightly smaller model after careful training and better design. This suggests smart training and architecture choices beat raw size in real-world use.
Why does this matter?
- Better phone assistants: This agent can understand instructions, carry out multi-step tasks across different apps, and ask questions to get it right. That’s closer to a truly helpful digital partner.
- Personalization: It can adapt to you—your preferences, habits, and past actions—to make choices that feel natural, not random.
- Reliability: The reflection system and knowledge retrieval make it more trustworthy in real apps, not just demos.
- Future directions: The authors argue we need better ways to test these agents (not just simple pass/fail), improved teamwork between multiple agents, and stronger safety checks to prevent mistakes or misuse.
Simple takeaway
ColorAgent is a smart phone agent designed to act like a careful, friendly helper. It learns step by step, practices on its own, works as part of a team of specialized modules, and either uses your preferences or asks you questions to do the right thing. In tests, it reached top scores, showing this approach can make phone assistants more reliable, personal, and truly useful in everyday life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps, limitations, and open research questions left unresolved by the paper. Each item is phrased to be actionable for future work.
- Evaluation/metrics coverage: Success rate alone fails to capture safety, efficiency (steps, time, energy), recovery rate, side effects, calibration (when to ask vs act), and user satisfaction; define and report richer, standardized metrics and statistical significance.
- Benchmark realism: Current AndroidWorld/AndroidLab tasks cover limited apps, initial states, and UI variability; build/benchmark on more dynamic scenarios (app updates, A/B tests, network delays, login/paywalls, permissions, CAPTCHAs, ads, pop-ups).
- Long-horizon and continual tasks: No evaluation on persistent, multi-session, or recurring goals; design tasks requiring memory across days, interruptions, and changing contexts.
- Real users and UX: Absence of user studies on “warmth,” helpfulness, burden of clarifications, and trust; evaluate proactive engagement and personalization with humans over longitudinal deployments.
- Cross-platform generalization: Unclear transfer to iOS, tablets, desktop OS, wearables, and cross-device workflows; quantify portability and required adaptation.
- Accessibility and inclusivity: No support/evaluation for accessibility UIs (screen readers, large fonts, high contrast, RTL scripts); test agents on accessible variants and multilingual interfaces.
- Non-visual modalities: The agent mainly relies on screenshots; explore robust speech I/O, haptics, notifications, and sensor data, and evaluate multimodal decision-making.
- Training–deployment gap: Results are on simulators and selected ColorOS devices; quantify performance, latency, and energy on resource-constrained, real consumer devices under background load.
- Safety and permissions: No concrete policy for dangerous actions (payments, deletes, privacy settings) or permission requests; formalize guardrails, just-in-time consent, and irreversible-action confirmations.
- Security and adversarial robustness: No red-teaming, phishing/overlay attacks, adversarial widgets, or prompt-in-UI attacks; create security test suites and mitigation strategies.
- Privacy and data governance: How user memories, profiles, and retrieved knowledge are stored, updated, anonymized, or deleted is unspecified; define privacy-preserving storage, access control, and on-device processing.
- Knowledge base construction: The retrieval corpus composition, freshness, curation, hallucination risks, and conflict resolution are not described; specify pipelines, versioning, and validation for knowledge updates.
- Retrieval reliability: No analysis of retrieval precision/recall, noisy knowledge impacts, or safeguards against misleading content; develop confidence-aware retrieval and filtering.
- Task orchestration reliability: Criteria, training, and error modes of the task classifier/orchestrator are not detailed; evaluate decomposition accuracy and failure cascades with diagnostics.
- Memory transfer fidelity: The task extractor/rewriter pipeline could drift or propagate errors; quantify information preservation, error amplification, and intervention strategies.
- Reflection loops and costs: Trigger policies, stopping criteria, and risk of oscillations in hierarchical reflection are unspecified; measure reflection overheads and define loop-breaking heuristics/theory.
- Step-wise RL scope: Optimization is single-step with rule-based rewards; explore trajectory-level rewards, sparse/delayed credit assignment, and end-to-end environment RL with safety constraints.
- Reward design validity: Format/accuracy rewards may not capture true task progress or user intent; incorporate learned reward models, preference-based RL, or automatic goal checks beyond JSON adherence.
- Overfitting and generalization: Larger models overfit training distributions; develop explicit regularization, domain randomization, hard-negative mining, and cross-domain curriculum to improve robustness.
- Self-evolving training risks: Discriminator quality, false positives/negatives, and self-reinforcement of model biases are not quantified; audit trajectory quality, inter-rater reliability, and error propagation across iterations.
- Human-in-the-loop efficiency: The amount and cost of manual correction during self-evolving training is unreported; measure label efficiency and propose active-learning strategies to minimize human effort.
- Multi-path augmentation impact: While conceptually helpful, its net effect on OOD generalization vs static benchmarks is not rigorously quantified; provide ablations across UI variability regimes.
- Domain mixing effects: Mixing mobile, web, and desktop data may help or hurt; analyze transfer benefits/negative transfer with controlled ablations and task taxonomy.
- Baseline parity and compute: Comparisons lack matched-parameter baselines and training budget normalization; report compute costs and fairness-adjusted comparisons.
- Action space coverage: Current actions focus on point/gesture/text; evaluate multi-touch, drag-and-drop, long-press nuances, system dialogs, accessibility APIs, and WebView/Canvas controls.
- Screen/layout variability: Robustness to different resolutions, DPI, split-screen, rotation, and foldables is untested; add systematic perturbation suites.
- App/account states: Handling of login, 2FA, paywalls, session expiration, and cold-start personalization is unspecified; design stateful benchmarks and recovery policies.
- Proactive ask agent calibration: How thresholds for asking vs acting are set, adapted, or personalized is unclear; study calibration, user burden, and context-aware ask policies.
- Data and label provenance: Heavy reliance on LLMs (for history summaries, multi-path labels, filtering) risks label errors and hidden biases; quantify LLM-induced noise and its downstream effects.
- Reproducibility of fixes: The paper mentions “fixed issues” in benchmarks but does not enumerate them; document all modifications and provide seeds, configs, and patched environments.
- Personalization risks: SOPs/profiles may encode biases or stale preferences; study concept drift, fairness across demographics, and mechanisms to edit or forget outdated preferences.
- Knowledge conflicts with intent: How the agent resolves clashes between retrieved knowledge and user-specific preferences is unspecified; design arbitration policies and meta-reasoning.
- Continual learning and safety: No method to update the model online without catastrophic forgetting or violating safety constraints; explore safe continual learning protocols.
- Formal guarantees: No formal verification of critical actions, rollback guarantees, or invariants; investigate verifiable execution, sandboxing, and transactional semantics for OS operations.
- Error taxonomy transparency: The failure pie chart is referenced but not fully detailed; publish the taxonomy, annotation guidelines, and per-class metrics to guide targeted improvements.
- Cross-lingual and code-switching: Agent robustness to multilingual instructions/UI content and mixed-language contexts is not evaluated; add multilingual benchmarks and training.
- Collaboration among agents: The framework is modular but does not study coordination among multiple specialized agents or concurrency/conflict resolution; develop protocols for cooperative/competitive multi-agent OS control.
- Economic and environmental cost: Training with large models (e.g., 72B) and multi-stage pipelines is compute-intensive; quantify energy/cost and investigate smaller, on-device, or distilled models.
- Ethical deployment: Policies for human oversight, auditability, and recourse when the agent errs are not defined; propose governance, logging, and user-facing controls.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed with today’s Android/ColorOS ecosystems, leveraging the paper’s agent framework (task orchestration, knowledge retrieval, hierarchical reflection), training paradigm (step‑wise RL via GRPO, rule-based rewards), and “warm” interaction modules (personalized intent recognition and proactive ask agent).
- OS-level mobile assistant for multi-step device operations
- Sectors: consumer devices, mobile OEMs
- What it does: Executes long-horizon tasks across settings and apps (e.g., “enable Wi‑Fi, set 70% brightness, share last photo via WhatsApp”), clarifies ambiguous requests, remembers user preferences to personalize actions.
- Tools/products/workflows: OEM-integrated “Agent Hub” using Accessibility Service; Knowledge Retrieval for app-specific tips; SOP mining for frequent routines; hierarchical reflection for safe recovery.
- Assumptions/Dependencies: Accessibility APIs and permissions; stable UI semantics (labels, content-desc); user consent for memory; on-device or low-latency model access.
- Enterprise mobile RPA (robotic process automation) on BYOD/COPE
- Sectors: finance, HR, sales ops, field service
- What it does: Automates repetitive multi-app workflows (expense capture, CRM updates, timesheets), transfers context across steps/apps via task orchestration and memory transfer.
- Tools/products/workflows: “Workflow Builder” for SOPs; policy-aware Runner; ask agent for approvals/exceptions; audit trails.
- Assumptions/Dependencies: MDM/EAS integration, app ToS, strong identity/permissions, handling 2FA/OTP legally and safely.
- Mobile app QA and CI/CD automation
- Sectors: software/devops
- What it does: Auto-generates and executes test trajectories, reproduces bugs on device farms, uses hierarchical reflection as an oracle and self‑evolving training to expand edge-case coverage.
- Tools/products/workflows: “Agent QA Studio” plugged into CI; emulator/real-device lab runner; trajectory discriminators as quality gates.
- Assumptions/Dependencies: Scalable device farms; access to debug builds/test hooks; tolerance for flakiness during UI churn.
- On-device customer support co-pilot
- Sectors: OEMs, telecom, ISPs, app developers
- What it does: Troubleshoots device/app issues (network resets, cache clears, permission fixes); asks clarifying questions; executes or guides step-by-step.
- Tools/products/workflows: “Support Agent” app with SOP library; knowledge base RAG; reflection to avoid mis-operations.
- Assumptions/Dependencies: User consent; clear rollback/recovery; safe-mode operation; liability boundaries.
- Accessibility assistant for motor/visual impairments
- Sectors: healthcare, public sector, NGOs
- What it does: Voice-to-action across arbitrary GUIs; personalized SOPs; proactive clarifications to avoid errors; consistent long-horizon help (forms, payments).
- Tools/products/workflows: Accessibility Service integration; profile-based personalization; ask agent for disambiguation.
- Assumptions/Dependencies: Regulatory compliance (ADA, EN 301 549); latency constraints; robust speech/VL support; privacy of user memory.
- Retail/e-commerce companion
- Sectors: retail/e-commerce, fintech
- What it does: Compares prices across apps, applies coupons, adds best offer to cart, aligns with preferences (brand, size, delivery).
- Tools/products/workflows: Cross-app task orchestration; coupon knowledge retrieval; reflection to handle checkout errors.
- Assumptions/Dependencies: App ToS/anti-bot policies; CAPTCHA handling; consent for account access; payment safety.
- Field workforce helper
- Sectors: logistics, utilities, inspections
- What it does: Automates photo capture -> form fill -> upload sequences; caches context offline; recovers from dead-ends.
- Tools/products/workflows: Portable agent pack; SOPs per route/job; self-evolving data from real trajectories.
- Assumptions/Dependencies: Offline robustness; battery/network limits; device ruggedization.
- Personal life admin co-pilot
- Sectors: finance, healthcare, travel
- What it does: Pays bills across apps, books appointments, checks in to flights; remembers preferences; asks when details are missing.
- Tools/products/workflows: “Life Admin” agent with encrypted memory; task orchestration for multi-app handoffs.
- Assumptions/Dependencies: Secure credential handling; 2FA UX; compliance (GDPR/CCPA); explainability.
- Synthetic GUI data/trajectory generation as a service
- Sectors: academia, ML tooling, app testing vendors
- What it does: Provides curated, filtered trajectories and SOPs using self‑evolving loop and discriminators to reduce labeling costs.
- Tools/products/workflows: “Trajectory Forge” API; quality discriminators; benchmark packs (AndroidWorld/AndroidLab variants).
- Assumptions/Dependencies: Device diversity; licensing of seed data; reproducibility across OS/app versions.
- Research toolkit for training/evaluating GUI agents
- Sectors: academia, labs, startups
- What it does: Re-usable GRPO step-wise RL setup with rule-based rewards; reflection modules; orchestration/RAG scaffolding; benchmark harnesses.
- Tools/products/workflows: Open-source agent framework; unit tests; seeds for self-evolving loops.
- Assumptions/Dependencies: Compute/GPU budget; dataset licenses; careful reward design to avoid overfitting.
Long-Term Applications
The following opportunities require further research, scaling, standardization, or policy/regulatory development before broad deployment.
- OS-native agent platform and semantic action APIs
- Sectors: OS vendors, standards bodies, developer tools
- What it enables: Stable “agent-first” interfaces (intent schemas, semantic selectors beyond pixels), robust sandboxes and capability scoping, standardized reflection hooks.
- Tools/products/workflows: Agent Capability API, Intent/SOP registries, developer linting for agent-friendliness.
- Assumptions/Dependencies: Cross-OEM standards; developer adoption; backward compatibility; security proofs.
- Privacy-preserving, on-device personalization
- Sectors: consumer, finance, healthcare
- What it enables: Federated/DP learning over user memory, secure enclaves for preferences and SOPs, per-app consent and revocation.
- Tools/products/workflows: “Personal Memory Vault,” federated training scheduler, privacy audits.
- Assumptions/Dependencies: On-device accelerators; mature privacy tooling; regulatory alignment (HIPAA/PCI/GDPR).
- Cross-device, multi-agent collaboration
- Sectors: automotive, PC, smart home, wearables
- What it enables: Coordinated agents across phone–PC–car–home (e.g., plan trip on PC, check-in on phone, navigate in car), shared task graphs and memory transfer.
- Tools/products/workflows: Inter-agent protocols; shared knowledge fabric; conflict resolution policies.
- Assumptions/Dependencies: Interoperability standards; low-latency sync; identity federation.
- Agent-first app ecosystems and marketplaces
- Sectors: app stores, platform economics
- What it enables: Apps publish SOPs/intents/affordances; “Agent Readiness Score”; marketplaces for certified workflows and micro‑SOPs.
- Tools/products/workflows: SOP SDK; certification pipeline using hierarchical reflection; revenue share for workflow creators.
- Assumptions/Dependencies: Incentives for developers; governance; anti-abuse mechanisms.
- Safety, verification, and certification of OS agents
- Sectors: policy/regulation, insurance, enterprise IT
- What it enables: Formalized checklists/specs, red-teaming of agents, VeriOS-like certification for safe execution and rollback guarantees.
- Tools/products/workflows: Conformance test suites; explainability/trace logs; incident response and kill-switches.
- Assumptions/Dependencies: Accepted metrics (beyond success rate) for safety/fairness/latency; liability frameworks.
- Enterprise governance and SLAs for autonomous mobile agents
- Sectors: finance, healthcare, government
- What it enables: Role-based access, approvals, segregation of duties, continuous monitoring; human-in-the-loop via ask agent for exceptions.
- Tools/products/workflows: Policy engine; immutable audit trails; risk scoring of trajectories.
- Assumptions/Dependencies: Integration with IAM, DLP, SIEM; third-party audits.
- Longitudinal accessibility co-pilots
- Sectors: eldercare, disability services
- What it enables: Persistent support that adapts over time, proactive reminders, safe execution with verification and caregiver oversight.
- Tools/products/workflows: Care-team dashboards; explainable action summaries; escalation rules.
- Assumptions/Dependencies: Clinical validation; ethical review; fail-safe designs.
- Robotics/IoT bridge via mobile GUIs
- Sectors: industrial automation, smart home
- What it enables: Robots/edge devices operating apps when native APIs are absent, using perception+grounding and reflection for safety.
- Tools/products/workflows: Robot-to-phone control stacks; semantic overlays; fallback strategies.
- Assumptions/Dependencies: Robust multimodal grounding; low-latency control; sandboxing.
- Energy/utilities orchestration and demand response
- Sectors: energy, smart grid
- What it enables: Agent negotiates tariffs, enrolls in demand-response, schedules high-load appliances via utility apps.
- Tools/products/workflows: Energy knowledge packs; cross-app task graphs; compliance logging.
- Assumptions/Dependencies: Utility cooperation; API/access policies; reliability SLAs.
- Government digital services assistant
- Sectors: public sector, civic tech
- What it enables: Form-filling, benefits management, multilingual guidance across fragmented apps; proactive eligibility checks.
- Tools/products/workflows: Verified SOPs; citizen consent flows; transparency reports.
- Assumptions/Dependencies: Policy buy-in; accessibility standards; data minimization.
- Next-generation evaluation standards and benchmarks
- Sectors: academia, standards bodies, platforms
- What it enables: Multi-metric evaluation (safety, reliability, cost, fairness, user satisfaction), collaborative tasks, security adversarial tests.
- Tools/products/workflows: Community datasets; scenario generators using self‑evolving pipelines; shared leaderboards beyond success rate.
- Assumptions/Dependencies: Cross-institution collaboration; legal/ethical data sharing; reproducibility norms.
- Financial and healthcare task co-pilots with governed autonomy
- Sectors: fintech, healthtech
- What it enables: High-stakes workflows with gated autonomy (e.g., claims, prior auth, KYC), proactive clarifications, robust error recovery.
- Tools/products/workflows: Tiered autonomy policies; dual-control approvals; explainable reasoning snapshots.
- Assumptions/Dependencies: Regulatory approvals; rigorous red-team testing; strong encryption and key management.
These applications directly leverage the paper’s innovations: step-wise RL and rule-based rewards for precise action grounding; self-evolving data generation for coverage and robustness; multi-agent orchestration and hierarchical reflection for long-horizon reliability; and personalization/proactive engagement to align with human intent. The primary feasibility levers are access to device control surfaces (Accessibility/API), privacy/security regimes for user memory, standardized agent-app interfaces, and dependable evaluation/certification to build trust.
Glossary
- Action grounding: Linking a model’s intended operation to the correct GUI element or location. "It addresses key challenges like perception ambiguity and action grounding by sequentially enhancing the model, moving from single-step optimization to iterative, data-driven improvement."
- Action Reflector: A component that checks each step’s immediate outcome to detect and explain execution errors. "Action Reflector is responsible for real-time monitoring of individual actions."
- Atomic task: A minimal, self-contained sub-goal produced during task decomposition. "a task orchestrator will decompose it into a sequence of manageable atomic tasks:"
- Clipped surrogate objective: The PPO/GRPO training objective that limits policy ratio changes to stabilize updates. "After estimating the relative advantages, the policy is updated by maximizing a clipped surrogate objective, regularized by Kullback-Leibler (KL) divergence to prevent abrupt policy shifts:"
- Difficulty-based filtering: A data curation strategy that removes too-easy or too-hard samples to improve learning efficacy. "To ensure that the training process focuses on informative and valuable samples, we introduce a difficulty-based filtering strategy."
- Global Reflector: A task-level checker that verifies final completion and triggers additional steps if needed. "Global Reflector provides an overall assessment at the task level."
- Group Relative Policy Optimization (GRPO): A policy-gradient RL method that uses groupwise, critic-free relative advantages for stable training. "We conduct step-wise reinforcement learning with the Group Relative Policy Optimization (GRPO) algorithm."
- Hierarchical Reflection: Multi-level feedback (action, trajectory, global) that detects and corrects errors at different granularities. "we incorporate a hierarchical reflection module to improve the resilience of autonomous mobile systems"
- Knowledge Retrieval module: A component that fetches task-relevant external knowledge to guide decisions. "To enhance the agent's adaptability to a wide range of tasks, we introduce a knowledge retrieval module that provides task-specific knowledge."
- Kullback-Leibler (KL) divergence: A regularization term that penalizes deviation from a reference policy to stabilize updates. "regularized by Kullback-Leibler (KL) divergence to prevent abrupt policy shifts:"
- Memory transfer mechanism: A process that extracts and injects critical information from one subtask into the next to preserve context. "To address this, we introduce a memory transfer mechanism."
- Multi-agent framework: An architecture where specialized agents/modules (execution, orchestration, retrieval, reflection) collaborate to improve robustness. "we construct a multi-agent framework designed to significantly enhance its capabilities."
- Multi-Path Augmentation: An annotation strategy that recognizes multiple valid actions for the same step and rewards them equally. "Multi-Path Augmentation."
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm; GRPO serves as a lightweight alternative to it. "providing a lightweight and stable alternative to Proximal Policy Optimization (PPO)"
- Retrieval-Augmented Generation (RAG): A method that conditions generation on retrieved knowledge, used here to personalize SOPs. "using a retrieval-augmented generation (RAG)-based approach"
- Rule-based reward: A deterministic scoring scheme (e.g., format and accuracy) used to evaluate generated actions during RL. "To evaluate the responses, we apply a rule-based reward consisting of two aspects: the format reward and the accuracy reward."
- Self-evolving training: An iterative loop that generates, filters, and learns from new trajectories to continuously improve the model. "we propose a self-evolving training pipeline that establishes a robust reinforcing cycle"
- Step-wise reinforcement learning: RL optimized at the single-step level to improve local decision accuracy within GUI contexts. "Stage I employs step-wise sample-based reinforcement learning (RL) to enable the model to explore optimal actions given observationsâspecifically, historical interaction records and current GUI screenshots."
- Task Orchestration: High-level decomposition and memory management that turns complex instructions into executable atomic tasks. "a Task Orchestration module decomposes complex goals and manages information flow across steps."
- Trajectory Reflector: A short-horizon monitor that checks recent steps for coherence and provides corrective feedback. "Trajectory Reflector oversees short sequences of actions to track ongoing progress."
- Trajectory rollout: Executing the current policy in environments (simulated or real) to produce interaction trajectories for training. "Trajectory Rollout."
Collections
Sign up for free to add this paper to one or more collections.

