- The paper demonstrates that combining fine-grained quantization with low-chunk landmark selection significantly reduces memory overhead in context-intensive LLM tasks.
- The paper finds that SVD-based key compression leads to notable accuracy loss, necessitating aggressive quantization methods to maintain retrieval precision.
- The paper introduces the Text2JSON benchmark to robustly evaluate KV offloading methodologies and inform production-level LLM deployments.
KV Cache Offloading for Context-Intensive Tasks: Analysis and Advances
Introduction
Key-value (KV) cache management has become a critical bottleneck in scaling inference and throughput for long-context LLMs, driven by linearly increasing memory consumption with context length. While standard quantization and eviction methods mitigate memory footprint, they often degrade accuracy, especially on tasks where large-scale retrieval from prompt context is required. "KV Cache Offloading for Context-Intensive Tasks" (2604.08426) investigates the efficacy of modern KV offloading frameworks in such settings, systematically analyzing their limitations and introducing improved methodologies and benchmarks for robust evaluation.
Problem Setting and Motivation
Contemporary LLM applications such as document-level information extraction, program analysis, and agentic task orchestration demand handling input contexts on the order of 104–105 tokens or more. Accelerator memory becomes a limiting factor as the KV cache footprint quickly exceeds model parameter size, severely impacting inference throughput. Classical KV quantization (e.g., FP8, NVFP4, HIGGS) and cache eviction/pruning reduce memory use but often cannot maintain accuracy for context-intense tasks, since pruning removes potentially relevant attention tokens.
KV offloading has been posited as a solution: offload less frequently used KV entries to system RAM and retrieve them on demand, using heuristics (e.g., landmark selection, attention pattern prediction) to minimize data movement. Existing work claims near-parity with full attention on commonly used benchmarks—however, the majority of such evaluations focus on "needle-in-a-haystack" (NIAH) or synthetic tasks, where only a small fraction of input context is required to answer a prompt. This does not reflect real-world context-intensive workloads, which necessitate retrieval across a substantial portion of the prompt.
Benchmarks and Novel Task Design
To assess offloading methods under true context-intensive demands, the authors introduce the Text2JSON benchmark. This dataset, inspired by production data extraction scenarios, requires LLMs to extract structured, multi-field JSON data from long, unstructured text blocks (average 20K tokens, up to 63.5K). Ground-truth is evaluated via exact match and IoU, avoiding the unreliability of LLM-as-a-judge metrics. In addition, challenging instances from MultiNeedle (NeedleBench v2) and Loong benchmarks are incorporated to comprehensively test retrieval under multiple-needle, cross-document, and multi-hop requirements.
Analysis of Offloading and Compression Schemes
The central component under investigation is ShadowKV offloading, which amalgamates SVD-based key compression and heuristic (landmark-based) token selection for system memory management. The authors dissect ShadowKV through extensive ablation:
- SVD-based low-rank projection of keys, a standard acceleration strategy, introduces significant accuracy drops on context-intensive tasks, even when permitting 10× more tokens to be loaded compared to default settings. Strong ablation results indicate that higher-rank SVD improves accuracy but at the cost of eliminating any memory advantage over 8-bit or 4-bit quantization, making it noncompetitive.
- Memory-oriented quantization (HIGGS, 2–4 bits per key) substantially outperforms aggressive low-rank SVD, delivering better memory-accuracy tradeoffs in all context-intensive scenarios.
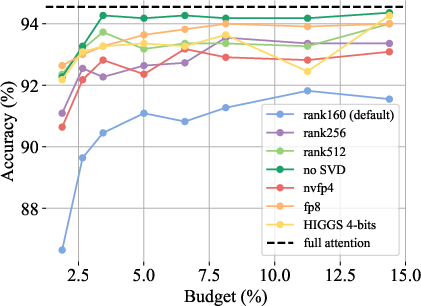
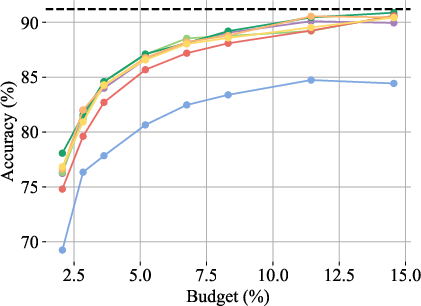
Figure 1: Evaluation of ShadowKV offloading with different KV compression strategies for Llama-3.1-8B-Instruct on MultiNeedle (left) and Qwen3-4B-Instruct-2507 on Text2JSON (right), emphasizing the inability of SVD compression to achieve lossless accuracy even at large token budgets.
- Dissecting offloading budgets: varying the allocation between sparse, outlier, and local-popularity tokens demonstrates that the traditional allocation—minimizing outlier/local budgets and maximizing "sparse" tokens loaded from RAM—is necessary but insufficient. Increasing budget for outlier or recent tokens has negligible impact, whereas increasing the sparse (RAM-loaded) budget is essential for maintaining retrieval accuracy.
- Landmark and chunking strategies are shown to be performance bottlenecks: traditional "chunk-8 averaging" for landmark computation leads to token selection errors because semantic importance is diluted across tokens, causing the system to fetch many irrelevant chunks.
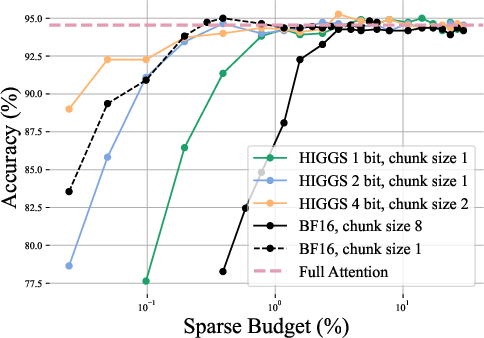
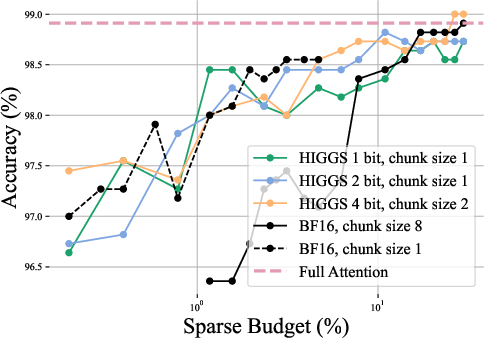
Figure 2: Evaluation of ShadowKV offloading with different landmark precisions and chunk sizes on MultiNeedle, showing distinct performance improvement with smaller chunk sizes and high-precision quantization.
- An oracle variant that selects tokens using ground-truth dot products between queries and cached keys demonstrates that existing heuristics significantly underperform optimal (albeit computationally infeasible) strategies.
Improving Landmark Selection and Quantization
The authors advance the offloading methodology by transitioning landmark storage from high-precision chunk-averages to lower-precision, smaller-chunk quantization using the HIGGS method. Systematic experiments reveal:
- For equivalent GPU memory budgets, lowering chunk size to 1–2 with 2–4 bit quantization yields comparable or superior accuracy compared to original ShadowKV settings, mitigating landmark-induced selection errors.
- Residual quantization—storing high-precision (e.g., 4-bit) chunk-8 landmarks and augmenting with 1-bit per-token residuals—enables near-2-bit effective per-key representations with minimal accuracy loss, outperforming pure 1-bit or 2-bit schemes.
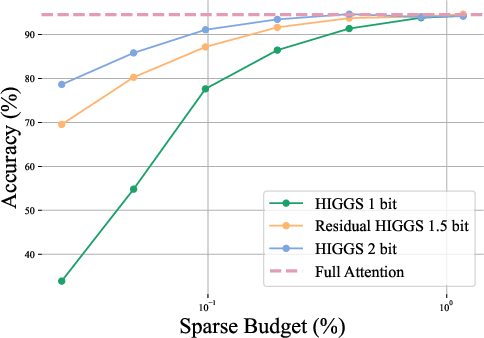
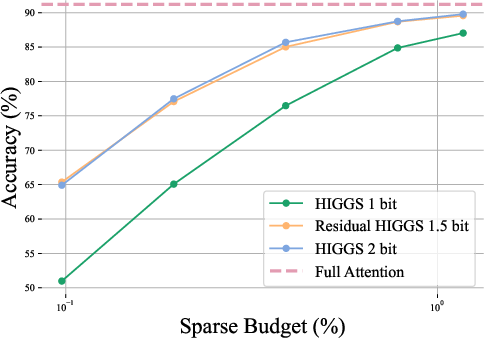
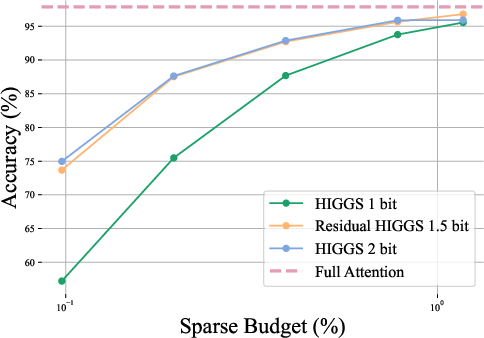
Figure 3: Comparison of 1.5-bit residual landmark quantization with 1-bit and 2-bit HIGGS, highlighting the gain from incorporating residual information at negligible memory cost.
Empirical Findings
A synthesis of ablation results demonstrates several notable claims:
- All tested offloading methods exhibit pronounced accuracy degradation on context-intensive tasks when using default hyperparameters. For some open benchmarks, increasing the sparse budget up to 10% or more of input tokens is required to achieve near-lossless behavior, in contrast to typical settings (<2%).
- SVD-based key compression—a staple for pre-offloading acceleration—becomes nonviable for real-world extraction and multi-needle retrieval: low-rank projections truncate essential attention information, irreversibly impairing accuracy.
- Aggressive quantization, if combined with improved (fine-grained, low-chunk) landmarking and residual storage, achieves compression with much less accuracy loss, establishing a more robust path for offloading in production LLM deployments.
Practical and Theoretical Implications
The results have significant implications for both LLM system designers and researchers:
- Production LLM deployments targeting context-intensive applications cannot rely on only synthetic benchmarks: widespread practices in both academia and industry risk overestimating system robustness if only NIAH or LongBench-style tasks are considered.
- Current offloading implementations, while theoretically more powerful than hard pruning, are limited in practice by landmark heuristics and key compression. Integrating quantized, low-chunk, and residual landmark selection mechanisms is critical for maintaining accuracy in high-intensity retrieval scenarios.
- The proposed Text2JSON benchmark serves as a reliable, discrimination-sensitive testbed decoupled from LLM-specific difficulties, uniquely illuminating the retrieval, storage, and compression tradeoffs inherent to long-context inference.
Prospects for Future Work
The study outlines several promising directions:
- Integration of adaptive, on-demand token loading strategies (e.g., hierarchical or layer-wise pruning, per-step attention quantization) that dynamically allocate memory to maximize accuracy with minimal overhead.
- Hardware-aligned implementation of quantized landmark selection (e.g., optimized HIGGS kernels) into mainstream inference frameworks and server stacks such as vLLM and SGLang.
- Systematic exploration of context-intensity axes across benchmarks to construct a generalized framework for evaluating and tuning offloading algorithms.
Conclusion
"KV Cache Offloading for Context-Intensive Tasks" (2604.08426) systematically exposes the limitations of current LLM offloading schemes on retrieval-heavy workloads, attributing most failures to aggressive low-rank key compression and inaccurate landmark heuristics rather than to offloading itself. Quantization-first, fine-grained landmarking, and residual compression represent effective solutions, with empirical evidence validating their efficacy across models and datasets. The work establishes stronger benchmarks and methodological foundations, driving future research toward production-ready, context-intensive, long-context LLM deployment.