- The paper proposes a pipeline-centric taxonomy that distinguishes LLM-intrinsic risks from those introduced via external knowledge access.
- It details four primary attack surfaces across six pipeline stages, highlighting persistent substrate poisoning and adaptive retrieval manipulation.
- It emphasizes the need for layered governance with upstream integrity checks, midstream hardening, and downstream context isolation to secure RAG systems.
Securing Retrieval-Augmented Generation: A Pipeline-Centric Taxonomy of Threats and Defenses
Introduction
Retrieval-Augmented Generation (RAG) systems, which enhance LLMs by making external knowledge accessible at inference time, are rapidly becoming a default paradigm due to their improvements in factuality, adaptability, and updateability. However, this external knowledge access paradigm introduces a new and expansive attack surface, distinct from inherent LLM risks. This paper (2604.08304) advances the field by reframing secure RAG as the security of the external knowledge-access pipeline, clearly delineating operational boundaries that separate LLM-intrinsic threats from those introduced or amplified by RAG. The analysis proceeds by abstracting the RAG pipeline into six stages, organizing threats and mitigations around trust boundaries and four primary security surfaces: pre-retrieval knowledge corruption, retrieval access manipulation, downstream context exploitation, and knowledge exfiltration.
Pipeline View: Security Surfaces and Trust Boundaries
The security exposure of a RAG system is best understood not as an isolated model property, but as a function of the broader knowledge-access pipeline. The authors systematically decompose the RAG workflow into six stages—ranging from external corpus ingestion through retrieval, assembly, and generation to final response delivery.
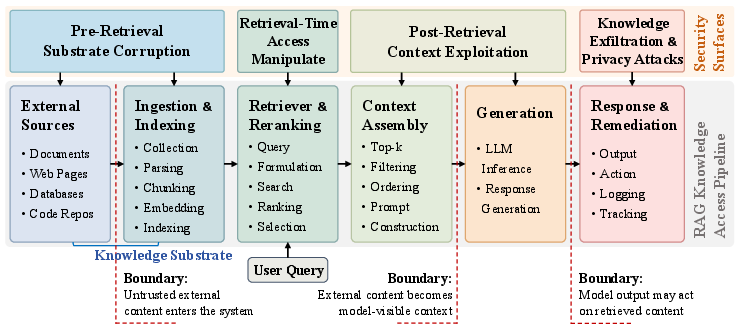
Figure 1: The RAG knowledge-access pipeline, showing critical security surfaces and three core trust boundaries for analysis.
Three trust boundaries structure the pipeline. The first is crossed when untrusted content enters the substrate via ingestion. The second—often the most critical—is crossed when retrieved evidence becomes visible to the LLM generator. The third occurs at system output, where generated content derived from untrusted context is revealed to end-users or external systems. Four attack surfaces align with these boundary transitions: (1) pre-retrieval substrate corruption, (2) manipulation during retrieval, (3) exploitation of retrieved context, and (4) exfiltration and privacy attacks at disclosure.
Taxonomy of RAG Attacks
The attack taxonomy is organized around where adversarial input enters the pipeline and which trust boundary it traverses.
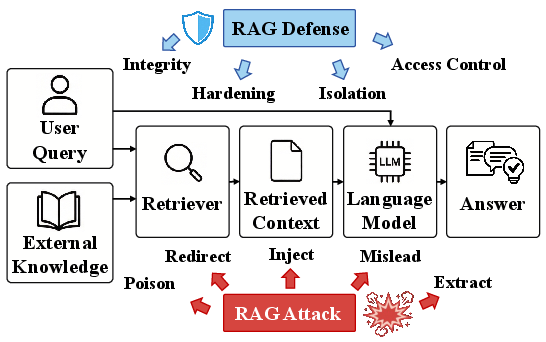
Figure 2: Types of attacks and defense alignments along the RAG knowledge-access pipeline.
1. Pre-Retrieval Knowledge-Substrate Corruption
The most persistent and damaging class of attacks targets the RAG system upstream, corrupting the indexed substrate before retrieval-time selection. Notable exemplars such as PoisonedRAG and BadRAG demonstrate that inserting only a few carefully optimized texts can induce targeted, durable poisons. Importantly, recent approaches (e.g., UniC-RAG, GARAG) achieve attacks that are both highly stealthy (semantically or visually inconspicuous) and broadly effective, including in multimodal substrates and code generation settings. Manipulating the ingestion interface itself (e.g., RAG Data Loaders) expands the threat model, underscoring the need to secure preprocessing and indexing, not just static corpora.
2. Retrieval-Time Access Manipulation
Retrieval-stage attacks operate by modifying the query or exploiting ranking heuristics to ensure the selection of attacker-chosen or misleading evidence. These attacks (e.g., GGPP, ReGENT) are typically less persistent than substrate corruption but remain effective in black-box scenarios. Attacks may also target retriever models themselves, e.g., via fine-tuned backdoored retrievers or coordinated prompt-retrieval poisoning.
3. Downstream Retrieved-Context Exploitation
Once harmful context crosses into the model-visible prompt, standard LLM safety mechanisms are largely bypassed—especially since such content is treated as evidence rather than a user prompt. Indirect prompt injection and context-triggered jailbreaking (PANDORA, Phantom, TrojanRAG) can silently induce malicious behaviors. Attacks also target availability, e.g., causing denial-of-service or triggering overt refusals through the manipulation of retrieved safety-triggering content (Blocker, MutedRAG).
4. Knowledge Exfiltration and Privacy Attacks
RAG systems further introduce privacy risks by creating new disclosure channels. Membership inference (MIA-RAG, S2MIA), direct data extraction (Spill the Beans, IKEA), and corpus-scale crawling (RAGCRAWLER, Retrieval Pivot Attacks) can be launched in black-box settings, leveraging the retrieval interface to extract, reconstruct, or infer sensitive substrate content. This attack surface is distinct from classical parametric memorization and is compounded by the presence of valuable, dynamically updated substrates.
Defensive Taxonomy and Pipeline Controls
Defense mechanisms are mapped to pipeline stages, directly addressing each corresponding attack surface.
Upstream governance is underdeveloped but critical. Pre-ingest validation (D-RAG), admission control through cryptographic provenance, and forensic traceback (RAGForensics) offer means to prevent, attribute, and remediate substrate poisoning. However, practical, systematic and versioned governance capabilities are largely absent in current deployments.
2. Retrieval-Time Access Hardening
Most existing defenses are concentrated here. Approaches include reliability-aware aggregation (RobustRAG, ReliabilityRAG), candidate reranking and filtering (TrustRAG, GRADA), and sensitive retrieval model manipulation (RAGPart, RAGMask). Despite progress, these are primarily reactive and degrade under adaptive or fluency-optimized attacks.
3. Post-Retrieval Context Isolation
Defenses at this stage aim to filter or constrain suspect context after it becomes model-visible. LLM activation analysis (RevPRAG) and attention-variance detection (AV Filter) provide empirical filtering. Modifying intra-model dynamics (SDAG) by constraining cross-document attention has also demonstrated efficacy. Robust-generation methods (Discern-and-Answer, InstructRAG, Astute RAG) can contain adverse effects but are not specifically security-native.
4. Access Control, Privacy, and Confidentiality
To counter knowledge exfiltration, multi-level controls are required: authorization checks (SD-RAG, AC-RAG), differential privacy in retrieval and generation (DPVoteRAG, LPRAG), corpus-level transformations (SAGE), and cryptographically secured architectures (RemoteRAG, SecureRAG, C-FedRAG). These mechanisms often require substantial architectural modifications and may impact utility or system latency but are essential for deployment in privacy-sensitive domains.
Benchmarks and Evaluation Frameworks
The field is shifting from ad hoc demonstrations toward comprehensive, domain-relevant evaluation suites. Manipulation-oriented benchmarks (SafeRAG, Benchmarking Poisoning Attacks, OpenRAG-Soc) provide reproducible assessments under practical attack scenarios. Privacy- and extraction-oriented benchmarks (S-RAG, KE-Bench, MedPriv-Bench, SEAL-Tag) enable rigorous testing of disclosure risks and trade-offs. Systematic evaluation studies clarify modality-specific threat profiles and guide robust defense design.
Implications and Theoretical Advances
This pipeline-centric analysis reframes secure RAG as a cross-stage, multi-boundary control problem. Key structural insights are as follows:
- Pre-retrieval substrate corruption confers attackers persistent, hard-to-remediate influence.
- Midstream defenses, while important, are prone to being bypassed by adaptive and context-fluent attacks.
- Downstream containment is essential but incomplete without upstream integrity enforcement.
- Privacy and confidentiality must be layered; no single mechanism can independently address the composite security risks of open-knowledge RAG architectures.
The field is also shifting toward systematic, remediation-aware evaluation and toward deployment-relevant settings, such as multimodal, multi-turn, web-facing, and regulated-agent applications. The practical implication is that organizations must treat secure RAG as a layered governance problem, requiring controls and monitoring at each pipeline stage, as well as audit and recovery protocols.
Future Research Directions
Four primary research avenues are outlined:
- Governance and Substrate Recoverability: Admission control, provenance, rollback, and repair for poisoned corpora.
- Context Separation: Fine-grained separation of evidence and executable control within context, minimizing accidental instruction execution.
- Boundary- and Remediation-Aware Evaluation: Benchmarking and evaluation that localize failures, measure propagation, and test post-mitigation recoverability.
- Deployment-Driven Threat Models: End-to-end, realistic assessment in web, multimodal, multi-agent, and regulated environments.
Conclusion
Securing RAG systems demands a treatment at the pipeline level, explicitly separating LLM-intrinsic vulnerabilities from those introduced by external non-parametric knowledge access. The taxonomy and analysis in this paper (2604.08304) highlight the multi-surfaceted nature of the threat landscape and reveal a structural mismatch wherein most defenses remain mid-pipeline and reactive, while upstream substrate controls and recovery mechanisms are underdeveloped. Progress will require layered, boundary-aware governance, the design of unified evaluation frameworks, and practical, auditable rollback strategies that match the sophistication of contemporary attack methodologies.