ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction
Abstract: Embodied cognition argues that intelligence arises from sensorimotor interaction rather than passive observation. It raises an intriguing question: do modern vision-LLMs (VLMs), trained largely in a disembodied manner, exhibit signs of embodied cognition? We introduce ENACT, a benchmark that casts evaluation of embodied cognition as world modeling from egocentric interaction in a visual question answering (VQA) format. Framed as a partially observable Markov decision process (POMDP) whose actions are scene graph changes, ENACT comprises two complementary sequence reordering tasks: forward world modeling (reorder shuffled observations given actions) and inverse world modeling (reorder shuffled actions given observations). While conceptually simple, solving these tasks implicitly demands capabilities central to embodied cognition-affordance recognition, action-effect reasoning, embodied awareness, and interactive, long-horizon memory from partially observable egocentric input, while avoiding low-level image synthesis that could confound the evaluation. We provide a scalable pipeline that synthesizes QA pairs from robotics simulation (BEHAVIOR) and evaluates models on 8,972 QA pairs spanning long-horizon home-scale activities. Experiments reveal a performance gap between frontier VLMs and humans that widens with interaction horizon. Models consistently perform better on the inverse task than the forward one and exhibit anthropocentric biases, including a preference for right-handed actions and degradation when camera intrinsics or viewpoints deviate from human vision. Website at https://enact-embodied-cognition.github.io/.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of the ENACT paper
Overview
This paper introduces ENACT, a test to see whether AI models that understand both images and text (called vision–LLMs, or VLMs) can think like beings that act in the world, not just look at it. The idea—called “embodied cognition”—is that real intelligence grows from actually doing things: moving, touching, and changing the environment, not just watching. ENACT checks if today’s AI can model how the world changes when a robot takes actions, using first-person (egocentric) videos from everyday activities.
What questions did the researchers ask?
- Do modern VLMs show signs of “embodied” thinking, or are they mostly good at describing pictures and text?
- Can these models understand how actions cause changes in the world over multiple steps (like a recipe with many steps)?
- Are the models better at figuring out what happened (looking back) or predicting what will happen next (looking forward)?
- Do these models have human-like biases (for example, preferring right-handed actions or human-like camera views)?
How did they test it?
The researchers turned robot videos from a simulated home into small puzzles the AI must solve. Here’s the setup, in everyday terms:
- Egocentric view: The “camera” is like the robot’s eyes, seeing from its point of view.
- Scene graph: Think of this as a neat list showing what objects are in the scene and how they relate (e.g., “cup is on table,” “fridge is open”).
- World modeling: The AI must understand how the world changes step-by-step when actions happen (like “grasp mug,” “open door,” “place book”).
They created two puzzle types:
- Forward world modeling: You’re given the first image, the list of actions in the correct order, and a shuffled stack of future images. Your job is to put the images back in the right order to match the actions. It’s like reordering frames in a comic strip so the story matches the script.
- Inverse world modeling: You’re given the first image and the later images in the correct order, but the actions are shuffled. Your job is to reorder the actions to match the images. It’s like reading the comic strip and figuring out which actions happened when.
Why this matters: These puzzles force the AI to connect actions to effects (cause and effect), recognize what objects afford (what you can do with them), remember changes across time, and handle partial visibility (you can’t always see everything). This focuses on reasoning rather than fancy video generation.
To make lots of puzzles, they used a robotics simulator called BEHAVIOR (a virtual home where robots perform long tasks), pulled out meaningful frames where something actually changed, and built nearly 9,000 question–answer pairs. They measured success with two simple scores:
- Task accuracy: Did the model get the entire order right?
- Pairwise accuracy: How many neighboring steps did the model order correctly (even if it missed the whole sequence)?
What did they find, and why is it important?
Here are the main results:
- Models are worse than humans, especially on longer tasks. Humans stayed very accurate even for long sequences, but model performance dropped a lot as the number of steps grew.
- Inverse is easier than forward. Most models did better at figuring out what actions happened from the images (looking back) than predicting future images from actions (looking forward). This suggests they handle “reading” events more easily than “imagining” future consequences.
- Longer sequences are hard. As tasks require more steps (like 8–10 changes), model accuracy falls sharply, showing limits in long-term memory and tracking changes.
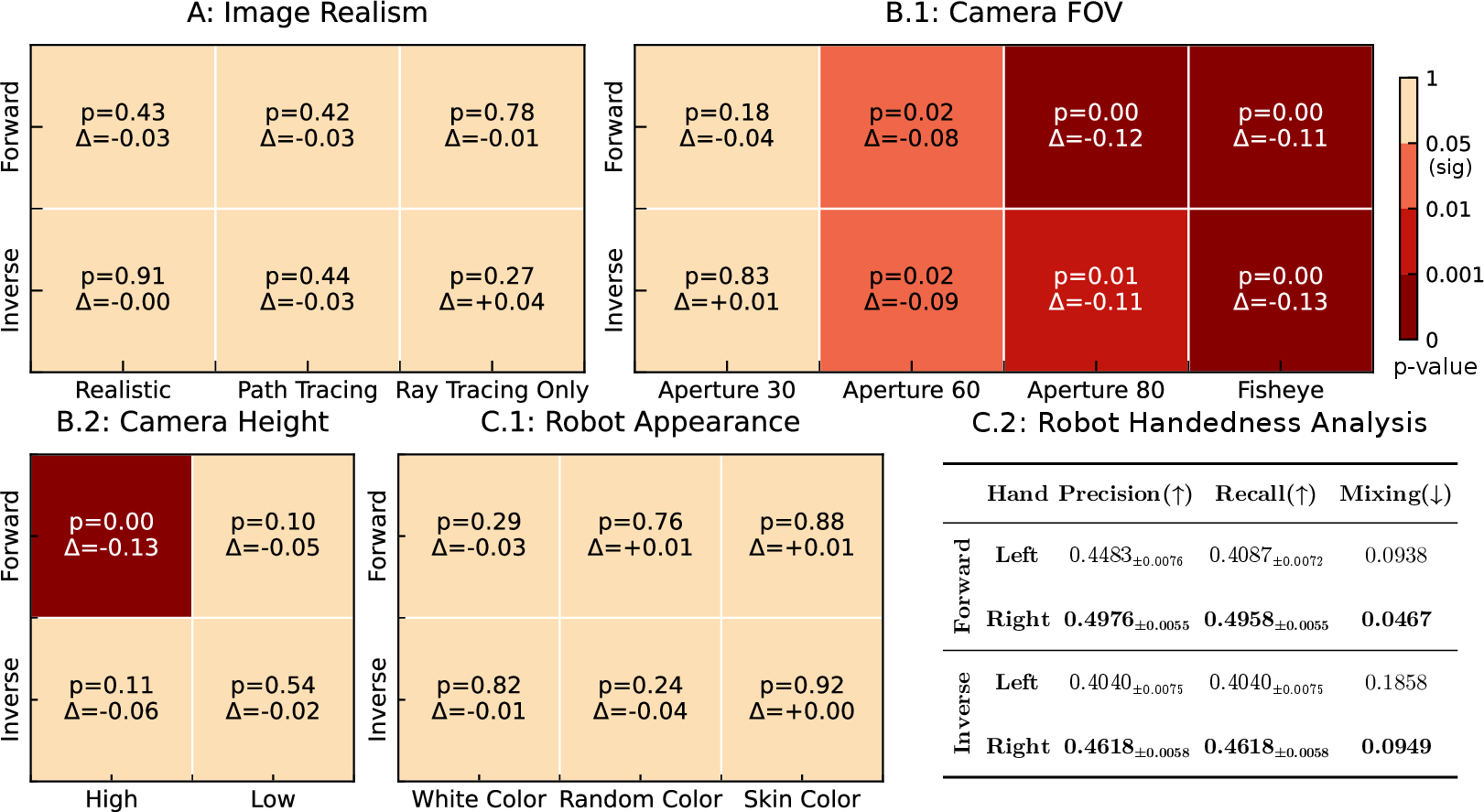
- Human-like camera settings help. When camera views are less like human eyes (very wide angles or fisheye lenses), models perform worse. This hints that training data and model assumptions favor human-style vision.
- Right-hand bias. Models more accurately understand right-handed actions than left-handed ones, similar to common human behavior (most people are right-handed).
- Realistic rendering isn’t the issue. Changing how realistic the simulated images look didn’t make a big difference. That means the bottleneck is reasoning across multiple steps, not image quality.
- Small sim-to-real gap. Results in real-world videos matched what they saw in simulation, so the simulator is a reliable way to test embodied reasoning.
These findings matter because they show current AI models struggle with the core of embodied cognition: connecting actions to changing worlds over time. They also reveal biases that could limit how AIs work on robots that don’t see like humans or use the left hand more.
What does this mean for the future?
- Better training data: Models may need more experience with action–effect sequences, not only static images and text. Think “learning by doing” rather than “learning by reading.”
- Stronger memory and physics understanding: To handle long tasks, AIs need improved long-term memory and a clearer sense of how objects behave when touched, moved, or transformed.
- Design for diverse robots: If we want AIs to work well on different robots, we should train and test them with varied camera setups and embodiments (not just human-like views).
- A practical benchmark: ENACT gives researchers a clean, scalable way to measure embodied cognition, compare models to humans, and track progress on the skills that matter for real-world robot assistants.
In short, ENACT shows that today’s VLMs can recognize and describe, but they still have a lot to learn about doing—understanding how actions unfold in the real world and remembering those changes over time.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Scope of embodied cognition captured by sequence reordering
- The benchmark equates embodied cognition with ordering observations/actions; it does not assess closed-loop control, real-time decision-making, proprioception, or body-schema formation. How can tasks be extended to measure these core embodied capacities without conflating them with low-level generation?
- Representation of actions and states
- Actions are defined as visible scene-graph deltas and exclude non-visible effects (e.g., unobserved contacts, occluded state changes, force magnitudes, durations). What is the impact of including non-visible but causally relevant changes (e.g., contact force thresholds, compliance) on evaluation sensitivity?
- The predicate set is limited to BEHAVIOR’s taxonomy (e.g., Open, Cooked, Grasping). How comprehensive is this coverage for everyday interactions, and how should predicates be expanded or standardized across simulators and real-world datasets?
- Dataset scale, diversity, and sampling
- Only 29 activities with one trajectory per activity are used; the QA sampling draws combinatorially from single episodes. How do results change with many distinct episodes per activity, varied execution strategies, and branching/failure-recovery sequences?
- The “seat selection” skipping may produce non-adjacent state transitions that are valid but atypical for natural interaction. Are models exploiting temporal heuristics, and how can sampling be constrained to more ecologically plausible subsequences?
- Long-horizon limits and memory
- Horizons are capped at L ≤ 10. What happens at truly long horizons (e.g., L = 50–100) with intermittent observability, object reappearance, and delayed effects?
- Which architectural interventions (e.g., explicit object permanence modules, differentiable memory, scene-graph state trackers) measurably reduce omission and hallucination errors?
- Metrics and verifier assumptions
- Pairwise Accuracy favors local adjacency and may not penalize global misorderings that preserve many local pairs. Can alternative metrics capture global temporal coherence (e.g., Kendall’s τ, edit distance with semantic costs, causal consistency scores)?
- The online verifier allows multiple valid answers but only for visibility-based deltas; how robust is it to commutative or concurrent actions and to alternative valid orderings with equivalent end-states?
- Forward vs. inverse asymmetry
- Inverse tasks are consistently easier, likely due to reliance on textual action descriptions. Is the asymmetry caused by action text advantages? Would image/video-based action representations (e.g., action clips, pose graphs) narrow the gap?
- What prompting, context windows, or planning scaffolds (e.g., tool-use, chain-of-thought, external memory) reduce the forward-task deficit?
- Real-world generalization
- Real-world validation covers only 3 scenes, 960 QAs, and a single model (InternVL3.5-241B-A28B). Do sim-to-real trends hold across more scenes (outdoor, industrial), diverse lighting and motion blur, heavy occlusion, and multiple models?
- Manual annotation is used to build real-world scene graphs. How can scalable, automated scene-graph extraction (e.g., detection+relation models, SLAM+semantics) be validated and integrated without introducing label noise?
- Anthropocentric biases and embodiment
- Right-handed bias is observed, but the causal source is unclear (data imbalance, viewpoint asymmetry, model inductive bias). Can controlled interventions (e.g., systematic mirroring, balanced left/right training, multi-arm embodiments) quantify and correct this bias?
- Camera intrinsics tests focus on aperture/FOV and modest height shifts. How do lens distortion, rolling shutter, extreme camera pose (e.g., ceiling-mounted, chest-mounted), stereo/depth, and multi-view setups affect performance?
- Image realism insensitivity
- Models are insensitive to rendering fidelity (Path Tracing vs. Ray Tracing). Are they ignoring shading/texture cues or primarily leveraging high-level semantics? Would aggressive texture/appearance randomization, domain adversarial tests, or photometric perturbations expose reliance on spurious cues?
- Error analysis assumptions
- The analysis treats atomic state differences as independent events, potentially ignoring structured dependencies (e.g., preconditions, mutual exclusivity, causal chains). How can error taxonomies incorporate causal graphs or constraint satisfaction to pinpoint failure modes more precisely?
- Ecological validity and task coverage
- Tasks focus on home-scale mobile manipulation. How well do conclusions generalize to deformable objects beyond simple categories, liquids, tool use with fine dexterity, multi-agent interactions, and tasks with social conventions or language-grounded affordances?
- RGB-only sensory modality
- The benchmark uses RGB egocentric views; absence of depth, tactile, audio, proprioception, and force sensing limits embodied evaluation. What is the effect of adding multimodal streams on forward world modeling and object persistence?
- Training and data design implications
- Models are not finetuned on ENACT. Does supervised/contrastive training on ENACT (or synthetic variants) measurably improve forward world modeling and reduce hallucination/omission? What curriculum (predicate sparsity, occlusion patterns, horizon ramp-up) is most effective?
- Prompting, resolution, and input format
- All inputs are 512×512 images and unified prompts. How sensitive are results to resolution, cropping, bounding-box overlays, scene-graph visualizations, or structured inputs (e.g., JSON actions plus images)? Can instruction tuning eliminate format-induced failures?
- Causal evaluation and counterfactuals
- The benchmark does not test counterfactual reasoning (e.g., “If action X were skipped, which frame would follow?”). How can counterfactual QAs and intervention-based probes be integrated to assess causal world models rather than associative ordering?
- Broader simulator and version dependence
- Results are tied to BEHAVIOR/Isaac Sim rendering and predicate APIs. How robust are findings across other simulators (e.g., Habitat, ManiSkill, PyBullet) and versions, including differing physics engines and asset libraries?
- Multiple comparisons and statistical rigor
- Many ablations use small samples (N = 300 QAs) and uncorrected p-values. Can future analyses include power calculations, multiple hypothesis corrections (e.g., Holm–Bonferroni), and effect-size reporting to strengthen claims?
- Equivalence classes of actions
- Some state changes can be achieved by different action orders. How can the verifier and metrics more fully account for action commutativity, concurrency, and reversible operations to avoid penalizing semantically equivalent sequences?
- Link to embodied agent performance
- The paper evaluates VLMs offline; it does not test whether higher ENACT scores predict improved performance in deployed robot policies. What is the empirical correlation between ENACT metrics and success on real robot tasks with feedback, failures, and recovery?
- Theoretical grounding of “embodied cognition” proxy
- The benchmark assumes world-model ordering tasks are a valid proxy for embodied cognition, but theoretical validation is limited. What principled framework (e.g., from enactivism, sensorimotor contingencies) can formalize which embodied faculties ENACT measures and which it does not?
Practical Applications
Immediate Applications
The following list summarizes practical, deployable uses of ENACT’s benchmark, data pipeline, and findings across sectors.
Industry (Robotics, Software, Consumer Devices)
- Benchmarking and gating VLMs for embodied use
- Use ENACT’s forward/inverse world modeling tasks and online verifier to qualify VLMs before deployment in mobile manipulation, warehouse automation, or home-assistant robots.
- Integrate “pairwise accuracy” as a robustness KPI for long-horizon tasks.
- Assumptions/dependencies: access to the ENACT dataset or pipeline; consistent image resolution and prompt parsing; representative task horizons for the target domain.
- Simulation-driven data augmentation for manipulation training
- Leverage the BEHAVIOR-based pipeline to generate millions of QA pairs per episode, enriching training/evaluation without expensive real-world collection.
- Build synthetic curricula focusing on long horizons and occlusions to reduce omission/hallucination errors.
- Assumptions/dependencies: simulator state access to derive scene-graph changes; calibrated visibility checks; sim-to-real validation for target platforms.
- Camera-intrinsics compliance testing for embodied AI
- Apply ENACT’s sensitivity analysis to choose camera FOV and height closer to human-like intrinsics (e.g., Aperture 40) to improve VLM performance on current models.
- Deploy a “FOV/height audit” tool that flags performance degradation under non-standard optics (e.g., fisheye).
- Assumptions/dependencies: current anthropocentric bias persists in evaluated VLM families; hardware constraints allow optics adjustment.
- Handedness bias audits for gripper/controller design
- Run predicate-level tests (LeftGrasping vs. RightGrasping) to detect asymmetries and tune controllers, workflows, or data sampling (e.g., oversample left-hand interactions).
- Assumptions/dependencies: gripper symmetry; accurate annotation of hand-specific predicates; willingness to rebalance training data.
- Production MLOps monitors for state-change reliability
- Convert post-hoc observations into action sequences (inverse task) for online introspection and error checking in robotic fleets.
- Use omission/hallucination rates as incident indicators for visual grounding failures.
- Assumptions/dependencies: logging of egocentric frames; lightweight scene-graph extraction or proxy detectors; privacy-safe storage.
Academia (AI/ML, Cognitive Science, HRI)
- Controlled evaluation of embodied cognition in VLMs
- Adopt ENACT’s POMDP-based, sequence-reordering tasks as standardized tests for affordances, action–effect reasoning, and long-horizon memory under partial observability.
- Assumptions/dependencies: unified prompt templates; consistent evaluation metrics; access to open-weight and proprietary VLMs.
- Course modules and lab assignments
- Integrate ENACT tasks into robotics, vision-language, and cognitive science courses to teach world modeling and error analysis (entity/predicate substitutions, polarity inversions).
- Assumptions/dependencies: simulator availability; basic Python tooling; graded templates for permutations and verifiers.
Policy and Standards (AI Safety, Procurement)
- Embodied AI readiness checklists for procurement
- Require vendors to report ENACT task/pairwise accuracies across horizons, camera configurations, and handedness predicates before deployment in public spaces or eldercare.
- Assumptions/dependencies: public access to benchmark artifacts; sector-specific performance thresholds.
- Bias audits for non-human embodiments
- Introduce conformance tests demonstrating robustness to non-standard optics and non-anthropocentric viewpoints to avoid exclusionary designs.
- Assumptions/dependencies: consensus on acceptable deltas (e.g., |Δ|<0.05); audit tooling for synthetic and real data.
Daily Life (Consumer Robotics, AR/VR, Smart Home)
- Practical setup guidance to improve robot reliability
- Prefer human-like camera intrinsics and mounting heights on consumer robots to reduce planning/recognition errors.
- Assumptions/dependencies: adjustable hardware; compatibility with current VLM-based perception stacks.
- Post-hoc troubleshooting with inverse modeling
- Use inverse tasks to reconstruct likely action sequences from observed states for diagnosing home-robot mistakes.
- Assumptions/dependencies: access to logs; simple UI to visualize predicted action orderings.
Long-Term Applications
These applications require further research, scaling, or engineering to reach maturity.
Industry (Robotics, Software Platforms, Digital Twins)
- World-model pretraining for embodied agents
- Train RL/IL agents with ENACT-style forward modeling objectives to improve prospective reasoning, long-horizon memory, and causal scene understanding.
- Potential products: “world-model cores” for robot OS; planning modules with explicit action–effect forecasts.
- Assumptions/dependencies: scalable multimodal training infrastructure; stable scene-graph representations; integration with control stacks.
- Self-correcting controllers via inverse/forward duality
- Combine inverse (retrospective) and forward (prospective) consistency checks to auto-detect and correct plan drifts and visual grounding errors during execution.
- Assumptions/dependencies: real-time scene-graph updates; efficient permutation solvers; low-latency verifiers.
- Digital twin instrumentation for state-change QA
- Embed ENACT’s predicate-level change signatures into factory/home digital twins for traceability, compliance, and incident analysis.
- Assumptions/dependencies: high-fidelity twins; standardized predicate schemas across devices.
Academia (Model Architectures, Training Data, Evaluation Science)
- Architectures targeting forward modeling deficits
- Design memory-augmented VLMs that maintain object persistence and reduce omission/hallucination errors over long horizons.
- Research directions: explicit contact modeling, object-centric latent states, structured causal decoders.
- Assumptions/dependencies: benchmarks that isolate perception vs. prediction; datasets beyond household domains.
- Non-anthropocentric embodied datasets
- Systematically generate and study data for diverse optics (fisheye, telephoto), viewpoints (ceiling cams), and embodiments (multi-arm, non-symmetric grippers) to mitigate anthropocentric bias.
- Assumptions/dependencies: large-scale synthetic generation; open annotation tools; adoption by the community.
- Unified embodied cognition metrics
- Extend ENACT’s task/pairwise accuracy into standardized suites for certification (e.g., affordance recognition, action–effect robustness, partial observability resilience).
- Assumptions/dependencies: agreement on taxonomy; shared verifiers; cross-lab reproducibility.
Policy and Standards (Certification, Safety, Inclusion)
- Certification frameworks for embodied AI
- Establish ENACT-derived tests as part of licensing (e.g., ISO/CE-like marks) requiring performance thresholds under varied camera intrinsics and horizons.
- Assumptions/dependencies: regulatory buy-in; public test repositories; independent auditors.
- Safety baselines for hallucination/omission mitigation
- Mandate reporting and remediation plans for structural error profiles (high hallucination/omission) before deployment in healthcare or eldercare robots.
- Assumptions/dependencies: sector-specific risk models; post-market surveillance protocols.
Daily Life (Assistive Tech, Education, Accessibility)
- Bias-aware assistive robots
- Design workflows that detect and adapt to user-specific contexts (e.g., left-handed users, wheelchair height viewpoints), informed by ENACT’s bias diagnostics.
- Assumptions/dependencies: personalization layers; diverse training data; user consent and privacy controls.
- Interactive learning tools for embodied reasoning
- Build apps that teach causal action–effect reasoning (forward) and forensic reconstruction (inverse) to students via gamified household scenarios.
- Assumptions/dependencies: simplified simulators; teacher dashboards; age-appropriate curricula.
Cross-cutting Tools and Workflows That Might Emerge
- ENACT SDK: plug-and-play toolkit to convert simulator or robot logs into scene-graph deltas, sample key-frame trajectories, and produce QA pairs at scale.
- Bias Audit Suite: automated tests for camera intrinsics, viewpoints, and handedness; reports with Δ and p-values against baselines.
- Structural Error Analyzer: predicate-level omission/hallucination dashboards for model debugging and safety reviews.
- Camera & Embodiment Configurator: design assistant for selecting optics and mounting parameters that minimize performance degradation, with trade-off visualizations.
Dependencies and assumptions for these tools include reliable scene-graph extraction, consistent predicate schemas, integration with simulators (Isaac Sim/BEHAVIOR) or digital twins, and stable model APIs for permutation outputs and verification.
Glossary
- Action–effect reasoning: Inferring how actions causally change the environment over time. "affordance recognition, action–effect reasoning, embodied awareness, and interactive, long-horizon memory from partially observable egocentric input"
- Affordance recognition: Identifying possible actions an agent can take with objects based on their properties and context. "affordance recognition, action–effect reasoning, embodied awareness, and interactive, long-horizon memory from partially observable egocentric input"
- Anthropocentric biases: Systematic preferences aligned with human perception or behavior that affect model performance. "Models consistently perform better on inverse task than forward one and exhibit anthropocentric biases, including a preference for right-handed actions and degradation when camera intrinsics or viewpoints deviate from human vision."
- Aperture: A camera intrinsic controlling the lens opening that influences field of view and image characteristics. "The baseline is Aperture 40. We examine Aperture 30, 60, 80, and Fisheye."
- BEHAVIOR (simulator): A robotics simulation platform providing long-horizon, home-scale manipulation tasks with accessible physical states. "We construct the benchmark from the BEHAVIOR simulator and challenge"
- Camera intrinsics: Internal parameters of a camera (e.g., focal length, aperture, FOV) that determine how scenes are imaged. "human-like egocentric viewpoints and intrinsics (e.g., FOV, aperture)"
- Contact-based predicates: Simulation-derived symbolic indicators capturing physical contact events used to enrich state changes. "augmenting key-frame selection with contact-based predicates derived from low-level physics yields qualitatively similar behavior"
- Egocentric: From the agent’s own viewpoint, emphasizing first-person visual observations. "casts embodied cognition evaluation as world modeling through egocentric interaction."
- Embodied awareness: An agent’s understanding of its own body and its role in interactions. "affordance recognition, action–effect reasoning, embodied awareness, and interactive, long-horizon memory from partially observable egocentric input"
- Embodied cognition: The theory that intelligence emerges from sensorimotor interaction rather than passive observation. "Embodied cognition argues that intelligence arises from sensorimotor interaction rather than passive observation."
- Field of view (FOV): The extent of the observable world seen at any given moment through a camera. "human-like egocentric viewpoints and intrinsics (e.g., FOV, aperture)"
- Fisheye: A wide-angle lens setting producing strong distortion and extremely large field of view. "We examine Aperture 30, 60, 80, and Fisheye."
- Forward world modeling: Ordering future observations given a sequence of actions to predict how the world evolves. "forward world modeling (ordering observations given actions)"
- Handedness asymmetry: Performance differences between left- and right-hand interactions reflecting a dominant hand bias. "Do VLMs exhibit a handedness asymmetry in their interactions with the world?"
- Inter-annotator agreement (IAA): A measure of consistency among human annotators labeling the same items. "For inter-annotator agreement (IAA), we uniformly stratify 240 items over QA type and step length and collect independent labels from three annotators."
- Isaac Sim: NVIDIA’s simulation platform used for realistic rendering and physics in robotics environments. "BEHAVIOR uses Isaac Sim"
- Inverse world modeling: Ordering actions given an ordered sequence of observations to infer the action progression. "inverse world modeling (ordering actions given observations)"
- Krippendorff’s alpha: A reliability coefficient assessing inter-annotator agreement across categorical labels. "Krippendorff’s α = 0.83 indicates strong agreement."
- Long-horizon: Tasks involving many sequential steps that require sustained memory and reasoning over extended time. "Long-horizon degradation reveals limited interactive, spatial memory under partial observability."
- Mobile manipulation: Robotic control combining mobility and manipulation to interact with objects across environments. "The human–model gap shows that current VLMs are still far from robust embodied world models in mobile manipulation settings."
- Mixing Rate: The proportion of ground-truth cases for one hand incorrectly predicted as the other hand. "Mixing is the proportion of ground truth left or right cases that are predicted as the other hand (i.e., mixing one hand into the other)."
- Online verifier: A checker that validates predicted permutations by consistency with constraints, accepting multiple correct answers. "we use an online verifier that accepts any predicted permutation, σ or τ, consistent with the input constraints."
- Pairwise Accuracy: Evaluation metric measuring the fraction of adjacent pairs ordered correctly within a sequence. "Pairwise Accuracy grants partial credit for near-correct sequences."
- Partially Observable Markov Decision Process (POMDP): A decision framework where the agent acts under uncertainty with incomplete observations. "Grounded in a partially observable Markov decision process (POMDP)"
- Path Tracing: A high-fidelity rendering technique simulating global illumination via stochastic ray paths. "Path Tracing (higher-fidelity rendering, \citet{kajiya1986rendering})"
- Predicate: A symbolic boolean or relational assertion describing properties or relations of objects in a scene. "The BEHAVIOR simulator exposes boolean and relational predicates"
- Ray Tracing: A rendering technique tracing rays to compute lighting and reflections; used as a baseline renderer. "Ray Tracing Only (Ray Tracing with global effects such as reflections and stage lights disabled)"
- Scene graph: A structured representation of objects and their relationships within a scene. "Framed as a partially observable Markov decision process (POMDP) whose actions are scene graph changes"
- Scene-graph difference: The symbolic delta between consecutive scene graphs capturing abstract state changes. "the scene-graph difference δ(s_t, s_{t-1}) ≠ ∅"
- Semi-MDP: A decision process with actions of variable durations abstracted into discrete decision epochs. "This initial abstraction into discrete decision epochs is similar to a semi-MDP"
- Sequence reordering: Framing tasks as ordering shuffled sequences (actions or observations) to evaluate reasoning. "they are formulated as sequence reordering for evaluating embodied cognition for a VLM."
- Sim-to-real gap: Performance discrepancy between simulation and real-world evaluation. "anthropocentric biases (e.g., right-handed priors, human-like camera intrinsics), and real-world evaluations that mirror simulator trends with only a limited sim-to-real gap."
- Symbolic scene graph: A scene graph using discrete symbols for objects and relations rather than raw pixel data. "A symbolic scene graph is a structured data model that represents the objects in a scene as symbolic nodes (e.g., On(fridge)) and their relationships as edges (e.g., OnTop(pen, desk))."
- Task Accuracy: Evaluation metric measuring exact correctness of the entire predicted ordering. "Task accuracy captures exact ordering"
- Visible state change (ΔVis): The subset of scene-graph differences that are visually observable in the paired images. "the action connecting consecutive key frames is the visible scene-graph delta a_k:=\Delta_\mathrm{Vis}(s_{i_{k+1}, s_{i_k})"
- Visual grounding: Reliably linking symbolic or textual predictions to the actual visual evidence in images. "The dominance of hallucinations suggests models rely on learned textual priors rather than faithful visual grounding."
- Visual Question Answering (VQA): A task format where models answer questions about visual inputs. "a visual question answering (VQA) format."
- Vision–LLMs (VLMs): Models jointly processing images and text for multimodal understanding and reasoning. "Vision–LLMs (VLMs)"
- World modeling: Learning or evaluating a predictive representation of how the world evolves under actions and observations. "casts evaluation of embodied cognition as world modeling from egocentric interaction in a visual question answering (VQA) format."
Collections
Sign up for free to add this paper to one or more collections.

