- The paper introduces a Self-Debias framework that trains LLMs to autonomously identify and correct bias in reasoning trajectories.
- It formulates debiasing as a resource allocation problem by reallocating probability mass from biased to unbiased reasoning using a Jain’s index fairness regularizer.
- Online self-improvement via self-generated corrections achieves state-of-the-art performance on fairness benchmarks without sacrificing task utility.
Self-Debias: Empowering LLMs with Intrinsic Self-Correction for Reasoning Bias
Introduction
Despite advances in reasoning-augmented LLMs, such as CoT prompting architectures, social biases embedded in pretraining corpora remain persistent, propagating along intermediate reasoning steps. Conventional debiasing strategies—either static constraints or inference-time interventions—fail to directly disrupt the internal propagation of activated biases. "Self-Debias: Self-correcting for Debiasing LLMs" (2604.08243) theorizes and implements an intrinsic realignment mechanism: rather than attempting to suppress bias by external directives or naive post-hoc critique, it trains LLMs to autonomously identify and excise biased logic at the trajectory level during generation itself.
Mechanistic Analysis of Bias Propagation in Reasoning LLMs
LLMs with CoT reasoning are characteristically vulnerable to bias rationalization cascades. Once a stereotype is activated in an early reasoning step, the model maximizes output likelihood by compounding and defending the stereotype in subsequent steps—a form of autoregressive inertia. Empirical evidence reveals that LLMs occasionally manifest "Aha moments": tokens such as “However” or “Wait” are interjected, indicating detection of a stereotypic premise. Yet, as quantified in diagnostic experiments, there is a systematic gap between bias detection and successful correction: even after identification, models overwhelmingly continue rationalization, yielding final answers that reinforce stereotype-driven reasoning. Post-hoc interventions are similarly ineffective, with generic self-refinement or explicit denial prompts leading to logical incoherence and further performance deterioration.
The Self-Debias Framework
The core contribution is the Self-Debias learning framework, which instills an intrinsic trajectory-level self-correction capacity in LLMs. The architecture unfolds in three distinct phases, visualized below:
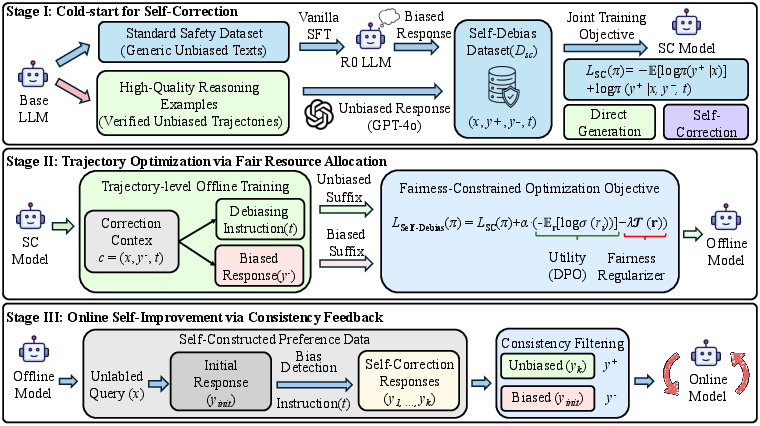
Figure 1: Self-Debias framework stages: cold-start initialization, trajectory-level optimization as corrective resource allocation, and online self-improvement via self-synthesized feedback.
Stage I: Cold-Start Self-Correction
To bootstrap autonomous debiasing, the model is fine-tuned on a dual-purpose dataset featuring explicit (biased, unbiased) trajectory pairs, coupled with a debiasing-specific instruction. Training optimizes both direct unbiased reasoning and instruction-mediated correction of biased suffixes, establishing an initial capability for step-wise remediation.
Stage II: Trajectory Optimization as Resource Allocation
The debiasing task is formalized as a constrained resource allocation problem. Output probability mass serves as a limited budget, reallocated from biased to unbiased reasoning trajectories. Unlike monolithic preference optimization, Self-Debias freezes valid prefixes and optimizes only the biased suffixes, targeting specific rationalization steps. Critically, a Jain’s index-based fairness regularizer enforces distributional equity, preventing collapse on ‘hard’ biases that evade correction under average utility objectives. The resulting composite loss function synergizes trajectory preference with explicit fairness constraints, fostering fine-grained, reliable debiasing without catastrophic forgetting of general reasoning.
Stage III: Online Self-Improvement via Consistency Filtering
Rather than relying on large quantities of annotated data, iterative alignment is achieved through self-supervision. The model systematically generates and corrects its own biased completions across unlabeled, sensitive-domain prompts. Self-consistency filtering identifies convergent corrected responses, which are recycled as new high-quality supervision signals. This pipeline supports continuous extension of the debiasing boundary with minimal external annotation.
Empirical Results
Comprehensive evaluation on major fairness benchmarks (BBQ, CrowS-Pairs, UnQover, CEB) and general reasoning tasks (ARC-Challenge, GSM8K) demonstrates several definitive outcomes:
- Standard LLMs experience severe performance degradation (up to -13.5 points) when tasked with self-correction, frequently over-correcting and eroding both fairness and utility.
- Self-Debias achieves and sustains state-of-the-art performance: average benchmark scores climb to 82.1 after online self-improvement, surpassing all instruction-tuned baselines, while maintaining or increasing accuracy on utility tasks.
- The self-correction mechanism does not incur an alignment tax; statistically significant improvements (p<0.05) are realized for both fairness and general reasoning post-trajectory optimization, demonstrating robust positive scaling at inference.
- Competing inference-time correction and debiasing methods consistently underperform, typically inducing further performance collapse, highlighting the necessity for intrinsic, fine-grained alignment.
Theoretical Implications
The formulation of debiasing as corrective resource allocation integrates principles from preference optimization and resource fairness. Jain’s index regularization directly targets variance in correction margin across samples, dynamically upweighting gradients for stubborn biases—a key innovation over averaging-based objectives. The online self-improvement phase parallels active curriculum learning, iteratively expanding the corrected region of the model’s reasoning distribution and providing a scalable template for label-efficient alignment.
Practical and Broader Implications
Self-Debias offers a technically robust, data-efficient paradigm for deploying LLMs in fairness-critical domains, where opaque bias propagation in reasoning chains is especially pernicious. By embedding the capacity for step-wise introspection and rectification, aligned models can effectively minimize risk in high-stakes applications without continuous external oversight or excessive rejection of valid context. The general resource allocation formulation is extensible: future work could port this approach to other structural vulnerabilities in generative models, adapt it to multi-attribute fairness constraints, or integrate it with richer online monitoring and verification agents.
Conclusion
Self-Debias establishes that intrinsic, trajectory-specific self-correction is necessary and sufficient for robust debiasing of reasoning LLMs. External interventions and static penalties are fundamentally inadequate for disrupting deep causal cascades in reasoning. The proposed framework—combining trajectory-level resource reallocation, distributional fairness, and iterative self-alignment—delivers superior fairness-utility tradeoffs, label efficiency, and inference-time reliability. This work significantly advances the technical frontier in practical and theoretically principled LLM alignment for social bias mitigation.