- The paper introduces a full-process debiasing method for multilingual PLMs that integrates MCDA, PEFT, and MSD to target bias at multiple stages.
- It demonstrates that parameter-efficient fine-tuning techniques within Multiple-Debias consistently lower bias metrics in models like mBERT and XLM-R compared to monolingual strategies.
- The combined use of multilingual counterfactual data augmentation and self-debiasing is essential for achieving scalable and reproducible fairness across diverse linguistic contexts.
Full-process Multilingual Debiasing in Pre-trained LLMs
Introduction
The paper "Multiple-Debias: A Full-process Debiasing Method for Multilingual Pre-trained LLMs" (2604.02772) presents a comprehensive debiasing framework for multilingual pre-trained LLMs (MPLMs). The work addresses persistent issues of gender, racial, and religious bias that these models inherit from large-scale, real-world multilingual corpora. Moving beyond monolingual or attribute-specific debiasing, this approach operationalizes a full-process method integrating multilingual counterfactual data augmentation (MCDA), parameter-efficient fine-tuning (PEFT), and multilingual self-debiasing (MSD), validated through expanded multicultural fairness benchmarks.
Multiple-Debias Framework
The Multiple-Debias (MD) framework systematically targets bias at pre-processing, in-processing, and post-processing stages:
- Pre-processing uses MCDA, generating balanced corpora by swapping sensitive attribute terms across five languages (English, Chinese, German, Spanish, Japanese), ensuring cultural and linguistic alignment.
- In-processing applies MCDA-powered training to mBERT and XLM-R via three PEFT techniques: adapter-tuning, prompt-tuning, and prefix-tuning. This reduces computational overhead and allows for fine-grained mitigation targeting bias-laden parameters.
- Post-processing leverages MSD, a multilingual extension of self-debiasing, where templates in all target languages prompt the model to recognize and suppress bias after generation.
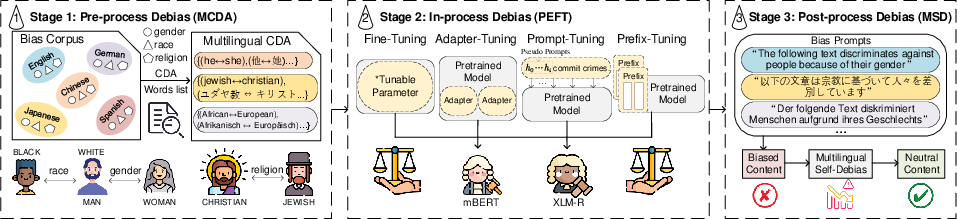
Figure 1: The architecture of the Multiple-Debias framework, illustrating the integration of MCDA, PEFT, and MSD across the full model development lifecycle.
This modular design not only targets various stages of bias infiltration but also facilitates adaptation to other languages and sensitive attributes.
Multilingual Bias Evaluation Methodology
Recognizing the need for appropriate fairness evaluation in multilingual contexts, the authors extend CrowS-Pairs—originally an English-only masked language bias benchmark—to four additional languages. Sentence pairs reflecting and countering stereotypes for gender, race, and religion are constructed via high-quality translation and term mapping, enabling systematic and consistent cross-lingual evaluation.
Additionally, Multilingual Bias Evaluation (MBE) is used for quantitative, parallel corpus-based gender bias assessment in non-English languages. Both CrowS-Pairs and MBE scores are normalized such that proximity to 0 indicates optimal balance.
Experimental Results and Analysis
Extensive experiments on mBERT and XLM-R reveal the following consistent outcomes:
- Multilingual debiasing outperforms monolingual methods: Both MCDA and MSD, and notably their integration in MD, show lower bias scores for gender, racial, and religious attributes compared to monolingual CDA or Self-Debias. For instance, in the reduction of gender bias (MBE scores), multilingual strategies provide more robust, consistent improvements across Chinese, Japanese, German, and Spanish.
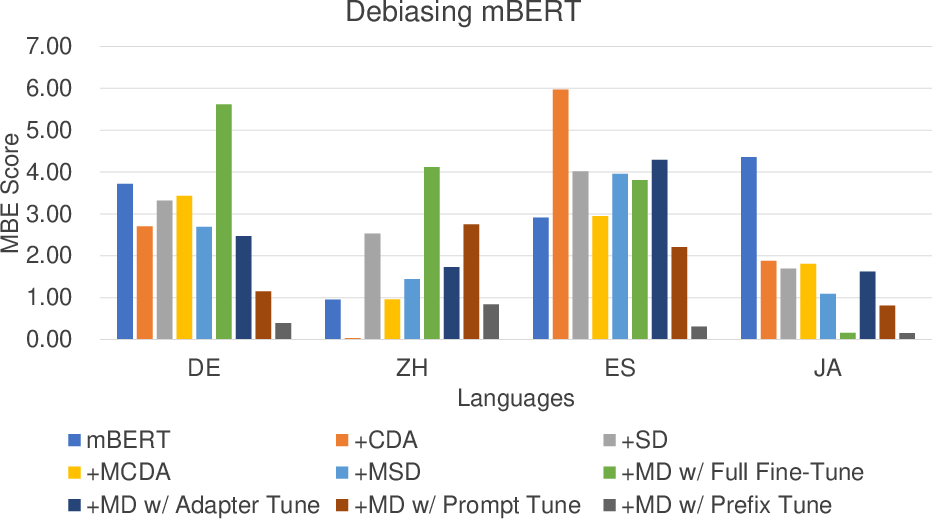
Figure 2: MBE bias scores for various debiasing strategies on mBERT, demonstrating stability and reduction of gender bias through multilingual approaches.
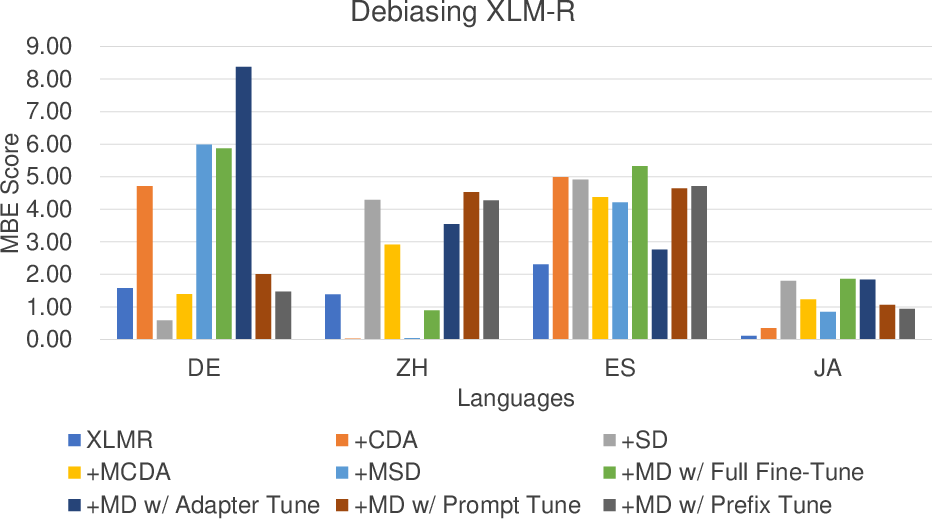
Figure 3: MBE bias scores for XLM-R, confirming the enhanced fairness of multilingual debiasing over single-language baselines.
- Parameter-efficient fine-tuning is crucial: MD applied with PEFT (especially adapter- and prompt-tuning) consistently outperforms MD with traditional full fine-tuning. In mBERT for gender bias, PEFT-enhanced MD reduces mean bias scores to as low as 2.24 (prompt-tuning), compared to 2.66 (full fine-tuning).
- Combination of MCDA and MSD is critical: Applying MCDA or MSD in isolation often yields unstable or insufficient debiasing, particularly for race and religion in XLM-R. Their integration in MD leads to the only methods that stably outperform the original baselines across all evaluated attributes and languages.
- **Bias reduction is particularly pronounced for gender, with more challenges remaining in deeply sociocultural attributes (race, religion), hinting at both the complexity of source data and the limitations of current benchmarks.
Implications and Theoretical Considerations
This research advances the field by establishing the necessity of treating debiasing as a full-process, multilingual problem. The findings explicitly support cross-linguistic data as a resource for bias mitigation—it is shown that sharing fairness-inducing data across typologically and culturally distinct languages amplifies the fairness effect, corroborating and extending earlier claims on the transferability of debiasing signals.
The strong performance of PEFT-enhanced debiasing demonstrates that targeted, parameter-localized interventions are not only computationally favorable, but theoretically appropriate for modular debiasing layered into large multilingual models. The modularity and explicit layering of MCDA, PEFT, and MSD provide a template for model-agnostic, scalable debiasing applicable to future architectures.
From a practical perspective, the expansion of CrowS-Pairs and validation of MBE in a multilingual context establish reproducible and extensible benchmarks for cross-lingual bias research. This concretely enables comparative analysis and further work in underrepresented languages and sensitive attributes.
Future Developments
Potential future directions include:
- Extension of MD to encompass even more languages and dialects, or to address biases beyond gender, race, and religion, such as disability, age, or socioeconomic status.
- Incorporation of unsupervised or weakly supervised term mapping to further improve the fidelity of MCDA in low-resource settings.
- Exploration of model adaptation techniques that can dynamically adjust debiasing intensity based on downstream application-specific fairness requirements.
- Integration of multilayered fairness signals during pre-training, potentially leveraging multilingual contrastive objectives or adversarial invariance to sensitive attributes.
Conclusion
The MD framework offers a structured, empirically validated methodology for comprehensive bias mitigation in MPLMs. Its full-process orientation, multilingual augmentation, and parameter-efficient interventions establish new best practices and resources for the systematic pursuit of fairness in language technologies, with broad theoretical and practical implications for multilingual NLP (2604.02772).

