- The paper introduces $φ$-DeepONet, a framework that embeds interface information via latent codes to robustly approximate discontinuous PDE solutions.
- It employs multiple branch networks and an augmented trunk network to directly capture abrupt changes without explicit domain decomposition, achieving error reductions from 10⁻¹ to 10⁻³.
- Numerical evaluations in 1D and 2D settings demonstrate its scalability and computational efficiency in modeling multiphysics problems with heterogeneous interfaces.
Introduction and Motivation
The presented work introduces the φ-DeepONet architecture, a neural operator framework optimized for PDEs with discontinuities arising from interfaces in heterogeneous media. Traditional neural operators, including DeepONet and its physics-informed variants, are limited by assumptions of continuity in both input and output function spaces. This restriction hinders applicability to interface problems where input fields and solution gradients often contain abrupt changes due to material heterogeneity or coupled physical regimes.
The φ-DeepONet architecture directly addresses these challenges through a physics-informed and interface-aware neural operator embedding, designed for robust and accurate approximation of solution manifolds with strong and weak discontinuities. The method avoids explicit domain decomposition, leveraging latent embeddings to capture interface structure within the operator’s trunk network.
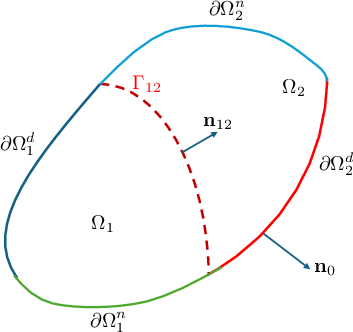
Figure 1: Schematic of the problem domain with two regions Ω1 and Ω2 separated by an interface $\Gamma_{\text{12}$.
Methodological Framework
φ-DeepONet extends the DeepONet formulation by integrating multiple branch networks to handle discontinuous inputs and a modified trunk network enriched with latent embeddings to encode output discontinuities caused by material interfaces. The architecture can be abstracted as follows:
- Branch Networks: Each subdomain possesses its own dedicated branch net, encoding sampled input fields (possibly discontinuous) localized to that region.
- Trunk Network Augmentation: The trunk is augmented to receive, alongside spatial coordinates, a latent variable ϕ that contains interface-specific information. The latent embedding is constructed via:
- Scalar embedding (prescribed per subdomain)
- Categorical (one-hot) embedding
- Non-linear categorical embedding (learned projection matrix, optionally with a non-linear activation such as tanh)
The interface information is provided to the trunk network as an additional input, facilitating expressive modeling of discontinuous solution spaces. The final network output is produced by a dot product between the augmented trunk output and the concatenated branch outputs.
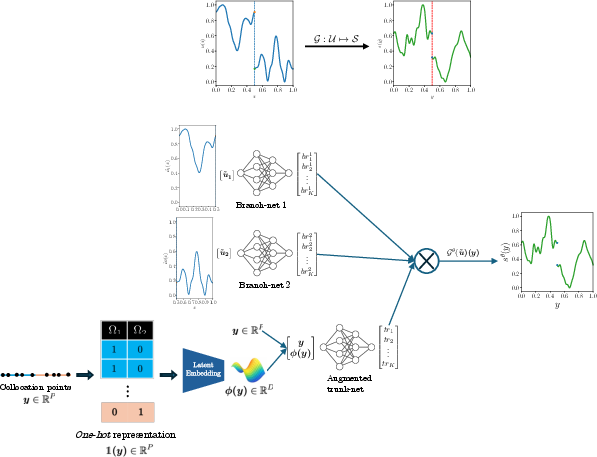
Figure 2: Schematic of the architecture of φ-DeepONet for approximating the operator φ0.
Training is performed with a loss comprising soft enforcement of PDE, boundary, and interface jump constraints, enabling simultaneous satisfaction of physical laws and discontinuity conditions.
Numerical Evaluation and Results
The φ1-DeepONet is systematically benchmarked against classical DeepONet and domain-decomposition operator networks (such as IONet) across a range of 1D and 2D problems with both continuous and discontinuous inputs.
1D Single Interface
For problems with a single sharp interface and continuous input functions, φ2-DeepONet achieves mean relative φ3 errors on the order of φ4 to φ5, substantially outperforming standard DeepONet (error φ6). Non-linear categorical embedding variants yield the best accuracy. Computational cost remains comparable or lower than IONet, which incurs higher parameterization and training cost as the interface complexity increases.
1D Multiple Interfaces
When scaling to four interfaces and five subdomains, the accuracy trend persists: non-linear CE variants with moderate latent dimension (φ7) produce mean test errors φ8, outscoring baseline methods. Empirically, increasing latent dimension saturates gains and, for high-dimensional embeddings, can degrade performance through overparameterization, as evidenced in bimodal error distribution studies.
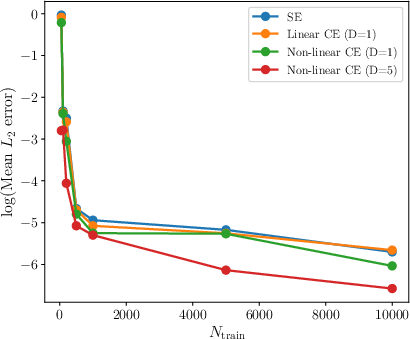
Figure 3: Variation of the test φ9 errors with increasing size of the input dataset (φ0).
2D Discontinuous Domains
In two-dimensional interface problems (e.g., square domain with diagonal interface), φ1-DeepONet achieves φ2 errors down to φ3 for non-linear CE trunk designs, reducing errors by up to two orders of magnitude over DeepONet. For complex, non-trivial interfaces (e.g., petal-shaped), compact latent embedding (φ4 or φ5) suffices for optimal performance, while higher-dimensional latent spaces are detrimental.
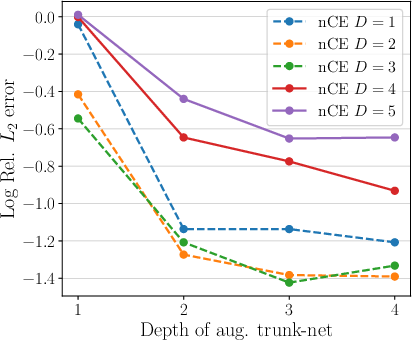
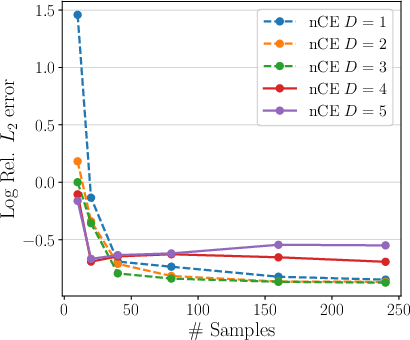
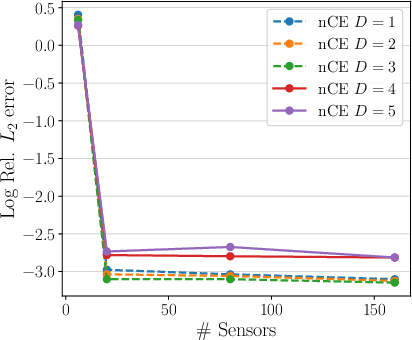
Figure 4: Ablation study for 2D petal-shaped interface: error as function of trunk depth, number of training samples, and sensor resolution for different embedding dimensions.
For cases where both input and output functions are discontinuous, multiple branch networks per subdomain encode distinct input fields. The method sustains accuracy (φ6 error φ7 for moderate embedding dimension), while baselines deteriorate further.
Implications and Theoretical Insights
φ8-DeepONet demonstrates that latent embedding of interface structure within trunk networks can supplant explicit domain decomposition for operator learning in heterogeneous domains. This approach reduces parameter proliferation as interface count increases, attaining both computational efficiency and improved fidelity near sharp transitions. The use of categorical or non-linear embeddings delivers flexibility and adaptability, important for problems with complex or evolving interfaces.
The tendency for diminishing returns and possible overfitting with high-dimensional latent spaces highlights the importance of embedding dimension selection—a critical hyperparameter warranting further theoretical investigation.
Practically, φ9-DeepONet enables mesh-free surrogate modeling for multiphysics, materials science, and engineering problems that previously required laborious mesh generation or retraining for each new PDE parameterization. The approach supports broad generalization within the scope of training distributions and provides some, albeit limited, out-of-distribution generalization.
Future Directions
Potential extensions include:
- Implicit interface learning: Removing reliance on fixed domain decomposition and learning interface structure entirely from data.
- Continuous latent fields: Replacing piecewise constant embeddings with continuous, possibly learned, fields for finer interface modeling.
- Strict constraint satisfaction: Transitioning from soft penalty enforcement to hard constraint satisfaction in trunk/branch parameterizations.
- Multiphysics and uncertainty: Application to stochastic, multiphase, or coupled multiphysics systems where interface positions, properties, or dynamics are uncertain or time-varying.
- Automated embedding selection: Theoretical and empirical analysis to determine optimal embedding dimension as function of interface and domain complexity.
Conclusion
Ω10-DeepONet constitutes an authoritative advance in operator learning for PDEs with discontinuous solutions, particularly interface-driven phenomena. By embedding interface information directly within the operator architecture rather than relying on explicit domain partitioning, the framework achieves substantial improvements in solution accuracy, computational efficiency, and scalability relative to conventional neural operators and domain-decomposed surrogates.
The architecture is robust across diverse problem settings as long as the interface partition and embedding are adequately specified. The framework’s limitations with unknown interfaces and dependence on embedding dimensionality underscore ongoing research directions for adaptive and fully data-driven interface representation. Ω11-DeepONet extends the neural operator paradigm toward practical modeling of discontinuous systems in applied mathematics, computational physics, and engineering.

