- The paper introduces a new calibration objective that aligns quantized outputs with original full-precision results by incorporating both inter-layer and compensation-aware errors.
- The methodology employs neuron decomposition and batchwise updates to compute refined error terms efficiently, significantly reducing perplexity.
- Experimental evaluations on Llama models demonstrate notable accuracy improvements, even under extreme low-precision and weight-activation quantization scenarios.
Motivation and Background
Recent growth in large-scale Transformer LLMs has dramatically escalated memory and computational demands, precluding broad deployment on resource-constrained hardware. Post-Training Quantization (PTQ) methods, typified by GPTQ and its derivatives, have established themselves as primary solutions for reducing model footprint without full retraining. GPTQ leverages second-order Hessian-based weight compensation to minimize output error during weight quantization, while GPTAQ further addresses inter-layer error accumulation via asymmetric calibration, aligning quantized layer outputs with their full-precision references.
Nonetheless, this manuscript asserts a critical flaw in the existing intra-layer calibration objective: current methods, including GPTQ and GPTAQ, align the quantized output to the output from compensated weights, not to the actual full-precision baseline. As a consequence, residual errors originating from intra-layer weight compensation discrepancies remain under-modeled. The paper thus proposes a refinement: at every step of iterative quantization, the calibration target should be the original full-precision output, not the compensated weight output, and the residual error must incorporate both propagated inter-layer and novel intra-layer weights-induced error.
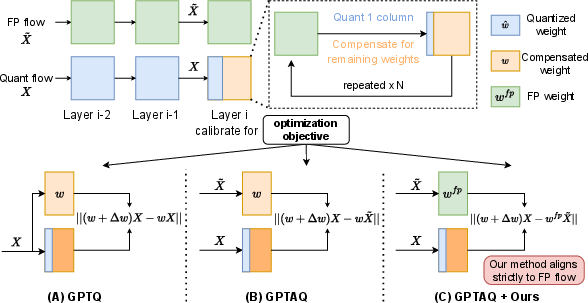
Figure 1: Overview of compensation-based LLM quantization methods. (A) GPTQ minimizes reconstruction error using the quantized input flow, neglecting previous layers’ error. (B) GPTAQ introduces asymmetric calibration to mitigate accumulated errors, but its calibration target is the compensated weights. (C) GPTAQ+Ours incorporates Compensation-Aware Error to precisely align with original outputs.
The paper formalizes the new calibration objective via:
- High-level (layer-level): Minimize the output discrepancy between quantized weights and original full-precision reference for each layer.
- Low-level (column-level): When quantizing a weight column, the objective is to minimize the difference between the quantized layer output and the untouched full-precision layer output, accounting for quantization and compensation steps.
The revised residual error, r′, comprises two terms:
- Inter-layer propagated error (r1): The output error from prior layers, as in GPTAQ.
- Compensation-aware error (r2): The discrepancy induced within the current layer's weight compensation, unique to this formulation.
The neuron decomposition technique from GPTAQ is extended to efficiently compute both r1 and r2, allowing for seamless integration into weight update steps and facilitating batched, parallel computation on modern GPUs.
Experimental Evaluation
Extensive experiments are conducted on Llama 2 and Llama 3 model families (scales up to 70B parameters) under several quantization regimes:
- Weight-only quantization: Integrating Compensation-Aware Error into GPTQ and GPTAQ yields substantial improvements. For instance, on Llama2-7B, GPTQ+Ours reduces C4 perplexity from 13.60 to 8.34, with average downstream accuracy rising from 64.9% to 66.5%. GPTAQ+Ours further increases average accuracy to 66.6%.
- Extreme low-precision (2-bit) quantization: Even with QuaRot weight rotation, GPTAQ+Ours generates notable accuracy gains over baselines.
- Weight-activation quantization: Compensation-aware residual errors maintain performance advantages amidst the added complexity of activation quantization, robustly countering outlier phenomena.
Ablation studies reinforce the indispensable contribution of the compensation-aware term, demonstrating that its inclusion in either GPTQ or GPTAQ consistently enhances zero-shot accuracy and reduces perplexity, especially under stringent compression settings.
Efficiency and Practicality
Analysis indicates that the additional memory and computation incurred by the compensation-aware error term are confined to offline calibration and remain tractable on conventional hardware. Model inference time and memory are unaffected, preserving practicality for real-world deployment. The quantization procedure incurs a nominal (∼5%) overhead relative to GPTAQ, attributed to efficient batchwise updates.
Implications and Future Directions
The introduction of intra-layer compensation-aware error provides a more principled foundation for PTQ in LLMs, yielding robust performance gains. Practically, this extends the operating regime of quantized LLMs to tighter resource constraints (e.g., lower-precision operation) and broader downstream applicability, as evidenced by improvements on both language and vision transformer benchmarks. Theoretically, the formulation clarifies the sources of quantization error, setting the stage for finer-grained modeling or adaptive correction mechanisms as models and hardware co-evolve.
Future research may extend compensation-aware error modeling to fine-tuning-aware quantization, dynamic mixed-precision scheduling, or structured sparsity pruning. Integration with rotation-based activation smoothing and adaptive block-wise quantization is also promising, given the method’s compatibility with existing architectures and its minimal intervention requirements. Enhanced calibration targeting datasets and other modalities could further broaden the method's use-case scenario.
Conclusion
This paper systematically redefines the residual error formulation in compensation-based quantization for LLMs, demonstrating that modeling intra-layer compensation-induced error is indispensable for precise calibration. Through rigorous theoretical exposition and empirical validation across multiple architectures and quantization settings, the compensation-aware residual error is shown to significantly improve perplexity and zero-shot task metrics, offering an efficient, generalizable enhancement to current PTQ paradigms. The results signal a trajectory toward ever more aggressive model compression without sacrificing task performance or generalization, critical for next-generation AI deployment under practical constraints.