- The paper introduces Personalized RewardBench to benchmark reward models that align with individual human values, demonstrating a strong correlation with downstream policy quality.
- The methodology leverages paired response generation and rigorous human validation to isolate performance based on adherence to personalized rubrics.
- Empirical results reveal that traditional scaling does not enhance subjective alignment, highlighting the need for planner modules to effectively integrate user profile data.
Personalized RewardBench: A Benchmark for Human-Aligned Personalization in Reward Models
Motivation and Contributions
The challenge of aligning LLMs with heterogeneous human values is increasingly recognized as central for advancing LLM alignment. While RLHF has substantially improved alignment with broad, general preferences, the field has yet to establish robust evaluation protocols for true personalization—where model behavior is tailored to individual user needs, stylistic preferences, and unique context. Existing benchmarks such as RewardBench and RM-Bench focus on general rubric adherence, neglecting the complexities of subjective, personal requirements, and failing to reliably predict downstream utility in open-domain generation tasks.
"Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization" (2604.07343) introduces a novel benchmark specifically designed to assess and accelerate progress toward highly personalized reward modeling. Key innovations of Personalized RewardBench include: (1) generation of chosen/rejected response pairs where both maintain high general quality but differ strictly in personal alignment, (2) rigorous human validation confirming that discrimination derives solely from adherence to individualized rubrics, and (3) a demonstrated, significantly stronger correlation between benchmark performance and quality of policies trained with BoN sampling or PPO, compared to prior benchmarks.
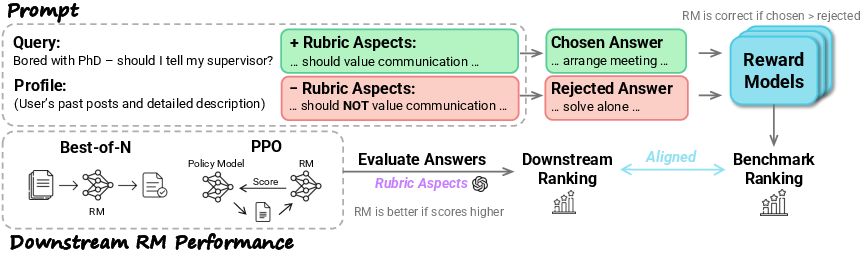
Figure 1: Sequential pipeline for Personalized RewardBench, from data construction to correlation analysis with downstream policy utility.
Dataset Construction and Human Evaluation
Personalized RewardBench leverages the LaMP-QA dataset, which features rich historical user interaction data and explicit, human-validated rubric aspects for satisfaction. For each user-query pair, profiles are constructed by retrieving relevant items from user history, ensuring that evaluations require reasoning over stable, contextually nuanced preferences. Generation of the chosen response conditions on the user query, profile, and fully specified rubric aspects; the rejected response is generated while deliberately violating those aspects, but still maintaining high fluency, factuality, and relevance.
Comprehensive human evaluations indicate that both types of responses achieve strong scores across general metrics (factuality, relevance, helpfulness), with the primary distinction being a marked drop in "Personal Rubrics" satisfaction for rejected answers. This design ensures that discriminative evaluation targets only the ability to align with subjective, personalized requirements, isolating performance from general capability.
Empirical Evaluation of Reward Models
A detailed comparative analysis spans three families of reward models: scalar RMs, generative RMs, and finetuned personalized RMs. Across state-of-the-art models, including Gemini-3-Flash, GPT-5.1, and various Llama and Qwen models, accuracy on Personalized RewardBench never exceeds 75.94%, markedly lower than what is typical for general reward modeling benchmarks. The top-performing model, Gemini-3-Flash, demonstrates robust generalization capabilities but still fails to capture the subtlety of human-aligned personalization.
Notably, model scaling trends observed in general NLP tasks do not hold; there is no monotonic improvement with increased parameter count, underscoring that subjective alignment requires specialized objective design rather than brute-force scale increases. Personalized models augmented with user profile information—when integrated naively—show performance degradation, indicating train-test distribution mismatch. Instead, a planner module which extracts structured rubric aspects from user history and profile, then conditions the RM on these aspects, is effective in restoring and even exceeding baseline accuracy.
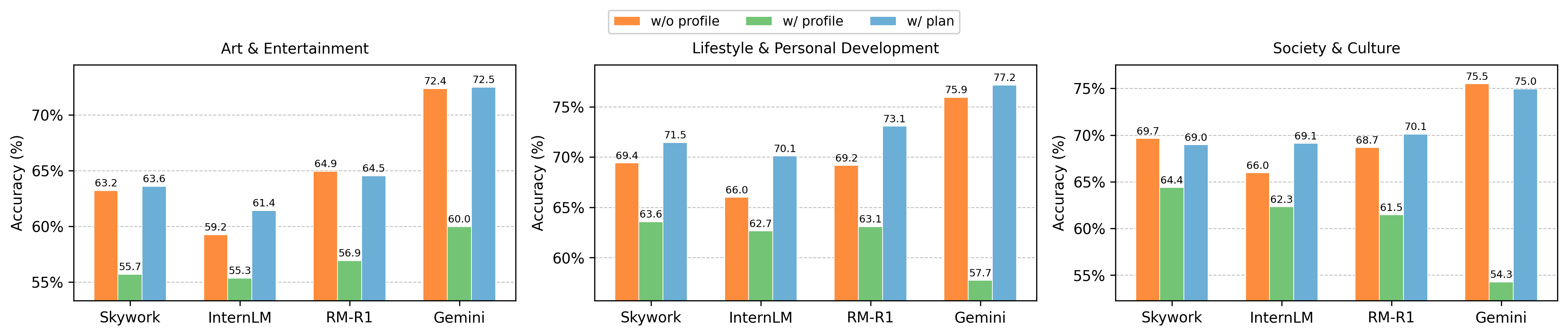
Figure 2: Comparison of user profile integration strategies, illustrating the superiority of planner-based profile-to-rubric inference over raw profile injection or absence of personalization.
Correlation with Downstream Policy Quality
A critical, underexplored dimension in reward modeling is the relationship between static benchmark performance and actual downstream policy improvement—termed the "proxy gap." Extensive experiments in both BoN (Best-of-N) sampling and PPO settings demonstrate that performance on Personalized RewardBench aligns much more closely with downstream utility than prior benchmarks such as PRISM-Personalized and PersonalRewardBench (NDCG > 0.91, Weighted τ > 0.34, substantially higher than baseline correlations). This is critical: models with high Personalized RewardBench scores consistently yield higher-quality responses in generation, as judged by rubric-aware LLM evaluation.
Implications and Future Directions
The analysis reveals a critical "personalization gap": top-performing frontier RMs fail to meaningfully model individual values even in well-posed settings, highlighting a major limitation for current alignment paradigms. The discrepancy is not due to data ambiguity or noise; when provided ground-truth rubrics, models achieve near-perfect accuracy (>98%). The limitation lies in inferring and operationalizing these subjective values from user history and context.
Practical implications are significant. As LLMs increasingly see deployment in settings requiring nuanced adaptation to user history and preferences—education, therapy, creative work, expert assistance—the need for robust, highly predictive personalized reward signals will only intensify. Personalized RewardBench, by establishing an evaluation protocol where performance is causally tied to downstream policy improvements, provides a new standard for iterative development and objective assessment in this domain.
On the theoretical front, the work suggests architectural scale is insufficient for subjective alignment; methods for inferring, representing, and applying explicit rubric aspects from complex user profiles represent a necessary new research direction. Moreover, as user populations become more diverse, pluralistic alignment frameworks that modularize preference learning and dynamically synthesize personalized reward functions in real time may emerge as the dominant paradigm.
Conclusion
Personalized RewardBench (2604.07343) constitutes a rigorous, human-validated, and highly predictive benchmark for evaluating personalized alignment in reward modeling. By showing that current SOTA models underperform in strictly personalized settings and that traditional scaling provides limited gains, the benchmark exposes critical limitations and clear avenues for future research. Its direct empirical link to downstream policy effectiveness makes it a vital tool for accelerating the development of user-aware, genuinely personalized LLMs.

