- The paper introduces DTCRS, a dynamic summarization framework that tailors summary tree construction to query semantics.
- It employs LLM-based classification and Gaussian Mixture Model clustering to reduce redundancy and enhance evidence relevance.
- Empirical results demonstrate improved F1 and METEOR scores on multi-hop QA tasks, particularly for abstractive questions.
DTCRS: Dynamic Tree Construction for Recursive Summarization
Motivation and Background
Retrieval-Augmented Generation (RAG) is central to mitigating hallucination in LLMs by injecting external, updatable knowledge at inference time. However, traditional RAG retrieval typically operates at the granularity of consecutive document chunks, which is insufficient for complex question-answering tasks requiring information integration across dispersed document sections. Recursive summarization strategies, particularly those constructing hierarchical summary trees via clustering and chunk-level summarization, have demonstrated efficacy in capturing document structure and enabling multi-hop reasoning. Nonetheless, static summary trees introduce substantial redundancy, with numerous summary nodes unrelated to the query, negatively impacting both computational efficiency and QA accuracy. Further, recursive summarization is not universally beneficial; its indiscriminate application can degrade performance for extractive or boolean questions.
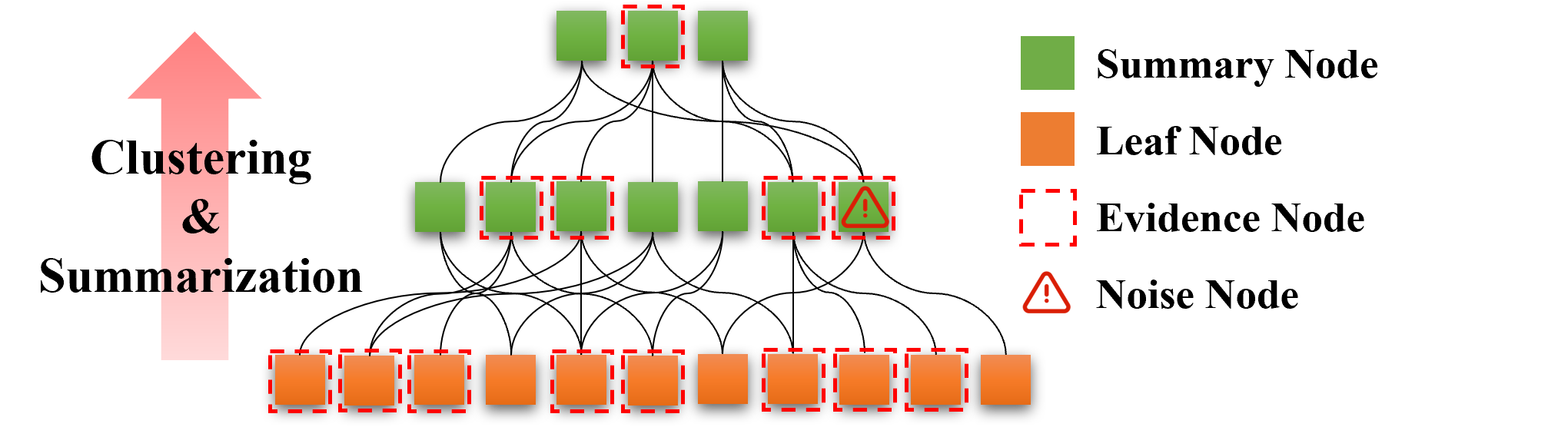
Figure 1: The presence of numerous query-irrelevant summary nodes in the summary tree increases construction time and may adversely affect correct answers.
DTCRS Framework and Algorithmic Innovations
DTCRS introduces a dynamic recursive summarization framework that tailors summary tree construction to query semantics and document structure. The system employs an LLM-based classifier to determine question complexity—specifically, whether multi-section summarization is required. For abstractive questions, DTCRS generates a Table of Contents (ToC) and decomposes the query into multiple sub-questions aligned with ToC sections. The embeddings of these sub-questions serve as initial cluster centers for Gaussian Mixture Model (GMM) clustering, directly guiding summary generation with query relevance.
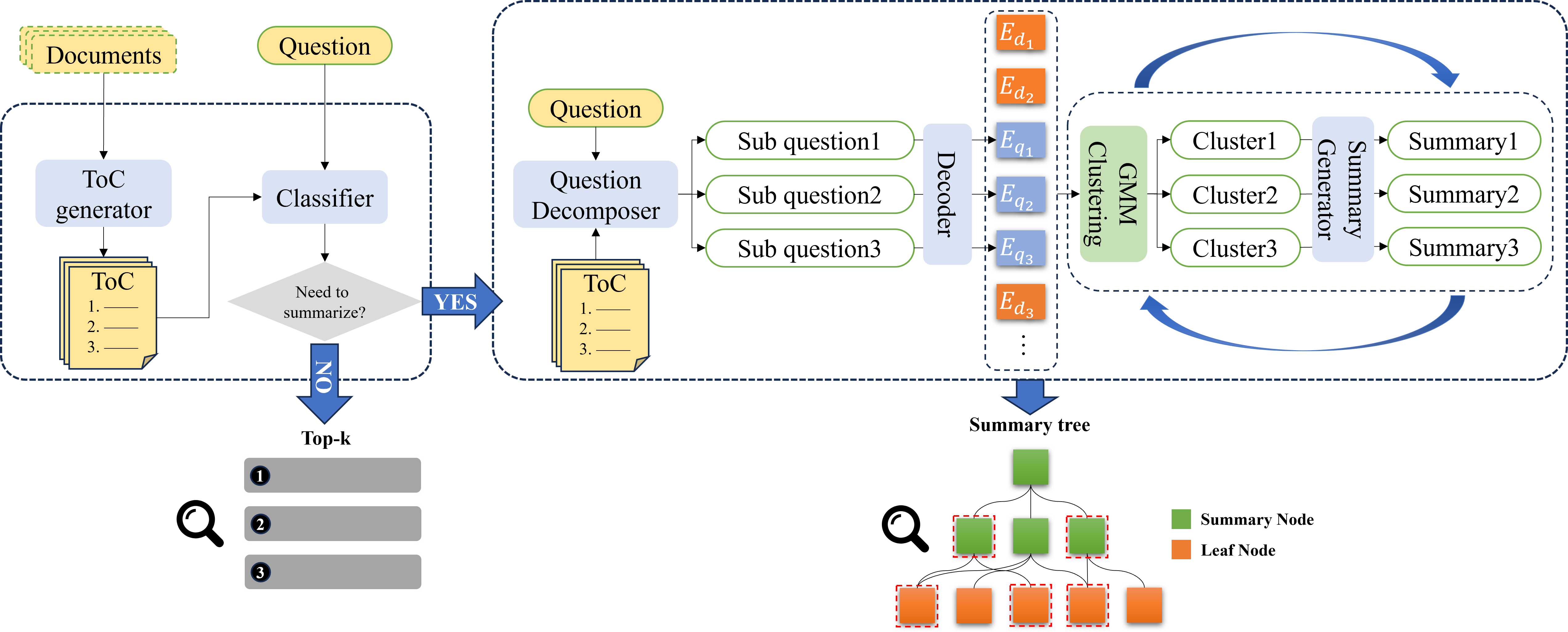
Figure 2: The overall process of DTCRS. The classifier first determines the question type. If summarization of document information is required, a dynamic summary tree is constructed; otherwise, DPR retrieval is used.
By leveraging sub-question embeddings as adaptive cluster centers, the method reduces node redundancy in summary trees, optimizes the clustering workload, and enhances evidence relevance for downstream QA. UMAP-based joint embedding reduction ensures semantic alignment between document chunks and sub-questions prior to clustering. Global, as opposed to hierarchical, clustering is preferred given the small sub-question set and improved computational efficiency.
Empirical Evaluation and Numerical Results
DTCRS was evaluated across NarrativeQA, QASPER, and QuALITY datasets, enabling rigorous validation on long-context, diverse QA tasks. On QASPER, DTCRS+GPT-4 yields an F1 score of 58.5%, outperforming RAPTOR+GPT-4 at 55.7% and LongT5 XL at 53.1%. On QuALITY, DTCRS+GPT-4o-mini achieves 74.7% accuracy (full set) and 62.9% on the hard subset, notably exceeding RAPTOR and DPR baselines. On NarrativeQA, DTCRS attains a METEOR score of 14.4% with GPT-4o-mini, the highest reported, though other metrics show no overall advantage compared to DPR or RAPTOR due to the prevalence of extractive questions.
Importantly, DTCRS demonstrates pronounced gains on abstractive questions, as evidenced by direct comparison to DPR (Figure 3).
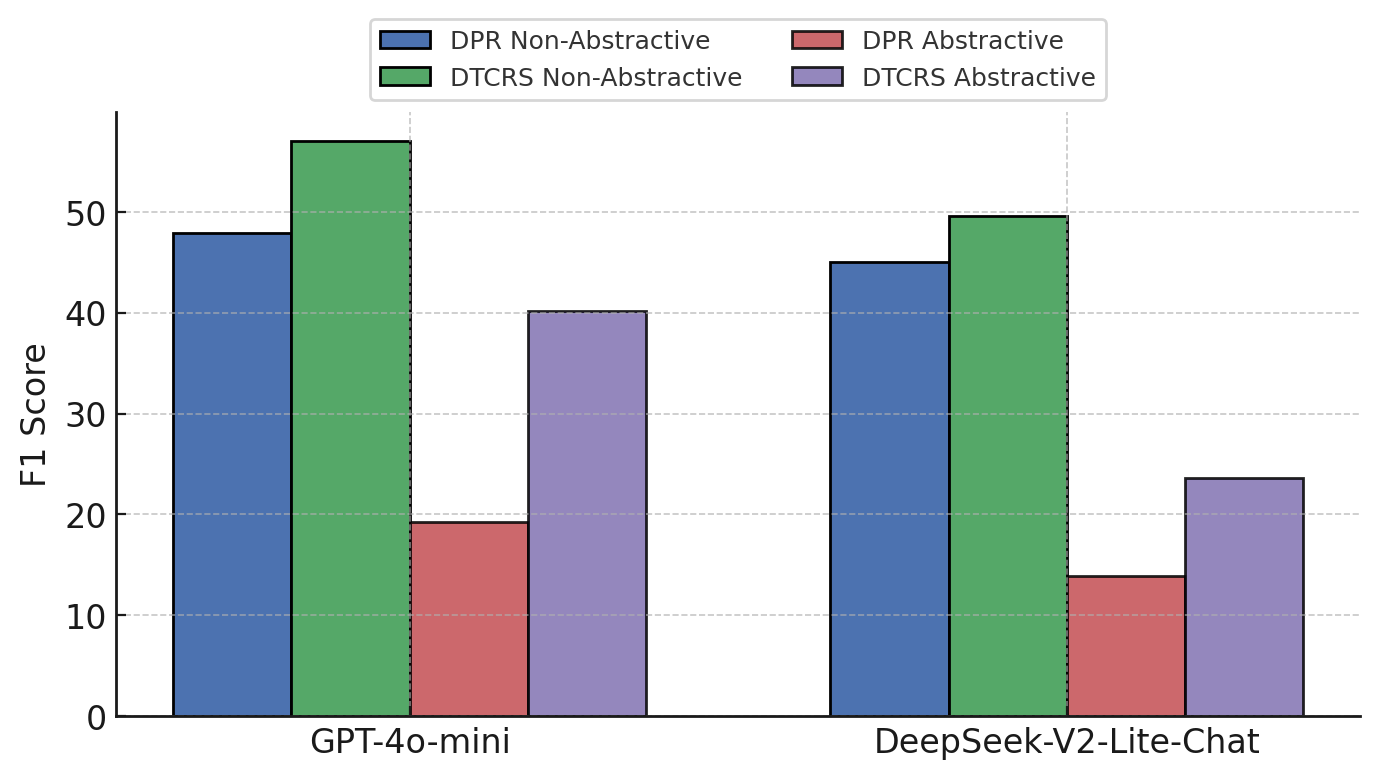
Figure 3: F1 scores comparison of DTCRS and DPR on abstractive vs. non-abstractive questions.
Ablation studies underscore the criticality of question classification: recursive summarization improves performance on abstractive questions but degrades it for extractive/boolean types. Removing components such as the ToC generator or classifier leads to significant performance drops. DTCRS reduces summary-layer nodes by 92.2% and summary tree construction time by 80.95% relative to RAPTOR, scaling efficiently to longer documents.
Qualitative Analysis and Relevance
Sample output comparisons visually illustrate DTCRS's evidence succinctness and query alignment. Unlike RAPTOR, which retrieves superfluous redundant evidence, DTCRS yields concise, relevant evidence with minimal hallucination, directly contributing to more accurate answer generation.
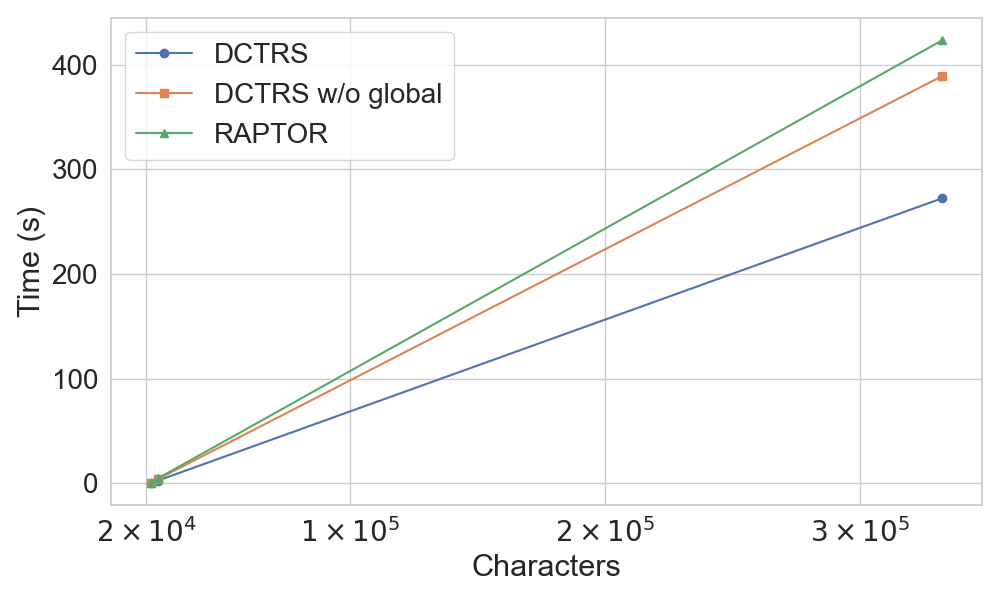
Figure 4: The sample outputs of RAPTOR and DTCRS: the yellow-highlighted parts in the evidence indicate information relevant to the question, the orange-highlighted parts represent redundant evidence included by RAPTOR compared to DTCRS, and the red bold text in the answer denotes the ground truth.
Further analysis of node statistics across summary tree layers validates the reduction of redundant nodes in DTCRS while maintaining evidence coverage critical for answer generation.
Classification results using GPT-4o-mini illustrate task-adaptive routing: QASPER and QuALITY contain substantial fractions of abstractive questions, amplifying DTCRS's benefit; NarrativeQA, consisting almost entirely of extractive questions, gains little.
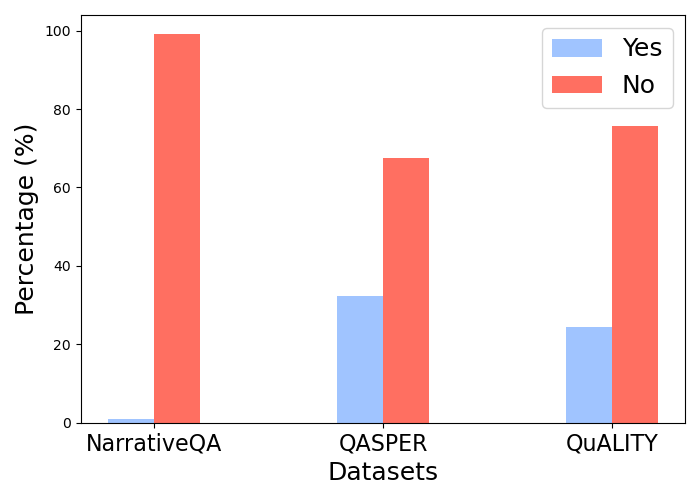
Figure 5: Classification results using GPT-4o-mini as the classifier on different datasets: Yes'' indicates abstractive questions,No'' indicates non-abstractive questions.
Practical and Theoretical Implications
DTCRS advances the modularity and interpretability of long-context QA pipelines, furnishing a query-driven, document-aligned summarization mechanism. The integration of ToC-based question decomposition, adaptive clustering, and dynamic summary tree construction addresses the granularity mismatch between retrieval sources and query needs. Practically, this approach enables LLMs to synthesize and reason over dispersed evidence, sharply reducing unnecessary computation and improving QA metrics.
Theoretically, DTCRS lays groundwork for further exploration in hierarchical semantic alignment, adaptive evidence aggregation, and cluster initialization strategies. Its methodology provides a framework for extending recursive summarization to arbitrary document structures, paving the way for improved long-form reasoning with evolving models.
Prospects for Future Work
Key limitations include potential misclassification of question types and scalability constraints for extremely long documents. Future directions can pursue more robust classifiers, hierarchical ToC generation beyond LLM input capacity, and advanced summary generation techniques mitigating hallucination. Integrations with domain-adaptive retrieval and hybrid evidence aggregation frameworks could further extend applicability.
Conclusion
DTCRS introduces a principled, query-adaptive recursive summarization mechanism with validated efficacy on multi-hop QA tasks. By optimizing summary tree construction for query semantics and document structure, DTCRS achieves superior relevance, efficiency, and accuracy metrics, especially for abstractive QA scenarios. The framework establishes a robust foundation for future research in dynamic evidence synthesis and long-context QA architectures.