- The paper introduces a tree-based hierarchical retrieval method that minimizes Semantic-Structural Entropy to preserve semantic and topological integrity.
- It employs LLM-based summarization and GNN encoding to efficiently index and retrieve complex textual graph information.
- Experimental evaluation shows up to 6.63% accuracy improvement and 62–84% token reduction over traditional graph-based RAG methods.
T-Retriever: Information-Theoretic Hierarchical Retrieval for Textual Graphs
Motivation and Limitations of Existing Approaches
Retrieval-Augmented Generation (RAG) has become a central mechanism for enabling LLMs to reason over external structured knowledge, particularly attributed graphs whose node and edge attributes are textual. However, state-of-the-art graph-based RAG methods suffer from two critical flaws in hierarchical context management: they either enforce arbitrary, rigid layer compression quotas that fragment meaningful local graph structure, or they disregard semantic coherence in favor of purely topological partitions. This leads to functionally misaligned hierarchies and suboptimal retrieval, ultimately undermining the quality of generated LLM responses for complex queries.
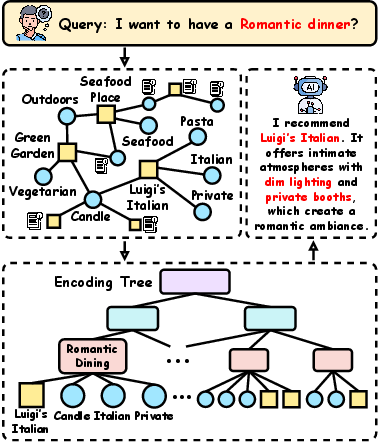
Figure 1: Hierarchical organization of attributed graph knowledge via encoding tree for multi-resolution question answering.
T-Retriever Architecture
T-Retriever introduces an explicit tree-based retrieval paradigm for textual attributed graphs, employing a novel encoding tree whose construction is jointly optimized for semantic and structural cohesion. The workflow comprises three main stages:
- Encoding Tree Construction: The tree is built top-down by minimizing Semantic-Structural Entropy (S²-Entropy), which fuses node/edge structural connectivity with the semantic density of node attribute embeddings. Partition, prune, and regulate operations recursively organize nodes into a hierarchy that preserves both semantic proximity and structural locality.
- Indexing and Summarization: Each tree node is indexed by embedding LLM-driven summaries of its clustered entities and relationships. Leaf nodes retain their raw attributes, whereas internal nodes are summarized by an LLM over their contained subgraph’s contents.
- Tree Retrieval and Generation: Query embeddings are matched against indexed nodes to identify relevant semantic-structural clusters. Retrieved subgraphs are then encoded by a GNN and textualized, providing enriched context to the downstream LLM for answer generation.
Figure 2: T-Retriever pipeline: joint entropy-driven tree construction, LLM-based hierarchical indexing, retrieval, and GNN-augmented generation.
Conventional graph hierarchies are typically built using bottom-up community detection, relying exclusively on topological features. T-Retriever instead defines the objective function for partitioning as the sum of structural entropy and semantic density entropy. Structural entropy measures the uncertainty introduced by cutting edges, while semantic entropy—estimated via kernel density over embedding distributions—quantifies intra-cluster attribute coherence. A weighting factor λ trades off between semantic and structural objectives.
Minimizing S²-Entropy yields clusters that optimize both structural separation and semantic thematicity, effectively solving the semantic-structural disconnect endemic in prior approaches, and realizes hierarchical encoding trees that support retrieval at multiple granularities.
Adaptive Encoding Tree Construction
Rather than enforcing per-layer quotas, the encoding tree is constructed using a global recursive partitioning algorithm inspired by Shannon-Fano coding. This strategy applies three key operations:
- Partition: Iteratively splits node clusters to minimize local S²-Entropy.
- Prune: Rebalances excessive depth in the tree, maintaining global entropy invariance.
- Regulate: Inserts intermediate nodes to ensure consistent depth and hierarchical completeness, as proven to preserve total entropy.
This adaptive, information-theoretic approach circumvents the limitations of bottom-up, quota-driven clustering, yielding balanced, multi-resolution indices ideal for efficient retrieval and reasoning.
Experimental Evaluation
Comprehensive experiments were conducted on three benchmarks—SceneGraphs, WebQSP, and BookGraphs—spanning from small to very large attributed graphs (tens to 77,000 nodes).
Key numerical results:
- Accuracy: T-Retriever achieves superior accuracy across all datasets, with improvements up to 6.63% on BookGraphs relative to the best baseline (ArchRAG).
- Efficiency: T-Retriever reduces the number of tokens provided to the LLM by 62–84% versus G-Retriever, and achieves a comparable node reduction rate (up to 84.5%).
- Robustness: Ablation reveals that joint S²-Entropy optimization outperforms semantic- or structural-only objectives by 7–18% in accuracy depending on configuration.
- Scalability: Preprocessing for the largest dataset (BookGraphs) completes within 7.3 hours on a single A100 GPU, establishing practical feasibility for real-world use.
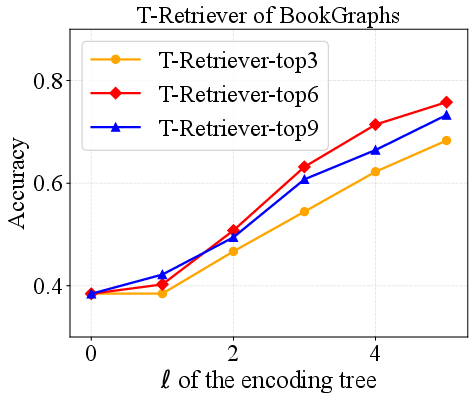
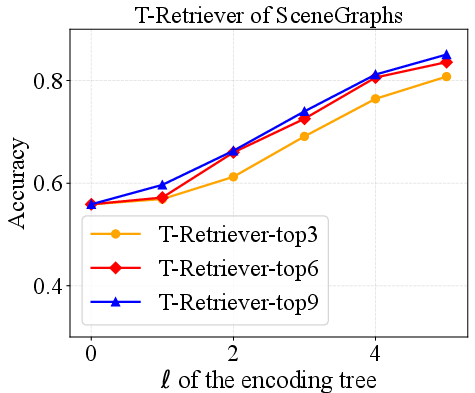
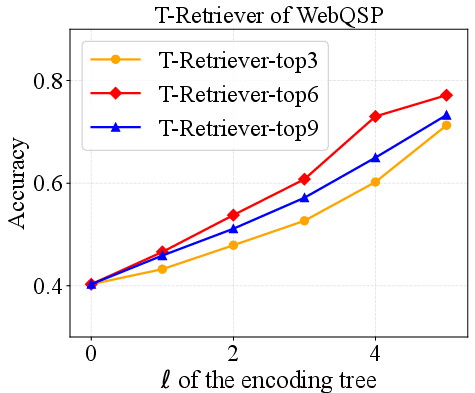
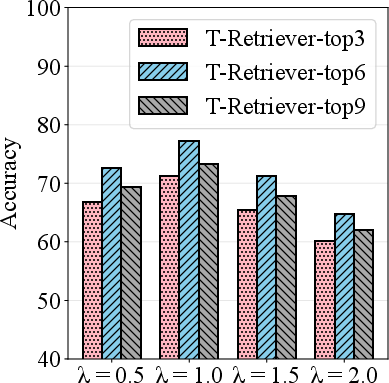
Figure 3: Performance and hyperparameter analysis on BookGraphs, exhibiting increasing accuracy with deeper encoding trees and optimal retrieval volume.
Qualitative Analysis and Ablation
Visualization of case studies in BookGraphs demonstrates the hierarchy's ability to group semantically relevant but structurally distant nodes, thereby facilitating retrievals that are both contextually rich and structurally appropriate. Ablation confirms that pure semantic entropy neglects essential topological constraints, while purely structural methods overlook interrelated concepts.
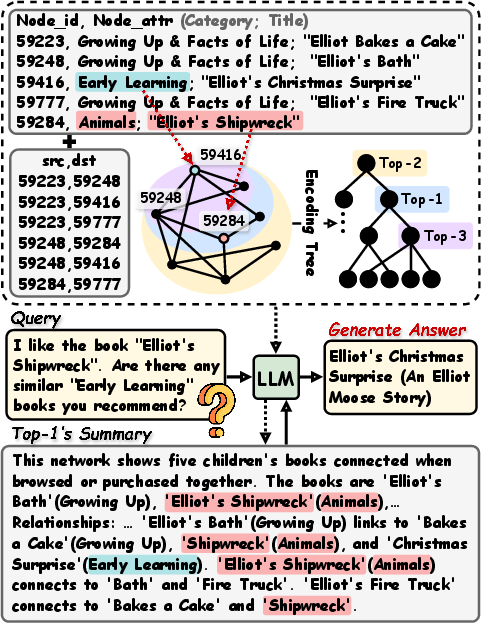
Figure 4: Qualitative case study from BookGraphs showing the alignment between hierarchical organization and contextually relevant retrieval.
Theoretical and Practical Implications
The catalytic effect demonstrated—whereby semantically similar but topologically distant entities can be clustered together via S²-Entropy minimization—enables retrieval and reasoning over distributed graph knowledge that would otherwise be inaccessible to topology-driven methods. This has strong practical implications for reasoning tasks on enterprise, scientific, or social graph data, where relevant information often spans multiple, weakly connected regions. From a theoretical perspective, T-Retriever presents an extensible framework for multi-modal hierarchical retrieval, generalizing beyond graphs to other attributed structured data domains.
Conclusion
T-Retriever advances retrieval-augmented generation for textual graphs by introducing a rigorously optimized, multi-resolution encoding tree index. By minimizing Semantic-Structural Entropy, the framework guarantees clusters that synthesize semantic coherence with topological integrity, outperforming state-of-the-art baselines in both performance and efficiency. The proposed paradigm has actionable implications for scalable LLM inference on complex graph data and provides a flexible foundation for future research in information-theoretically guided, hierarchical retrieval systems.