Benchmarking Multi-turn Medical Diagnosis: Hold, Lure, and Self-Correction
Abstract: LLMs achieve high accuracy in medical diagnosis when all clinical information is provided in a single turn, yet how they behave under multi-turn evidence accumulation closer to real clinical reasoning remains unexplored. We introduce MINT (Medical Incremental N-Turn Benchmark), a high-fidelity, multi-turn medical diagnosis benchmark comprising 1,035 cases with clinically labeled evidence shards, controlled turn granularity, and information-preserving decomposition. Through systematic evaluation of 11 LLMs on MINT, we uncover three persistent behavioral patterns that significantly impact diagnostic decisions: (1) intent to answer, models rush to answer before sufficient evidence has been observed, with over 55% of answers committed within the first two turns; (2) self-correction, incorrect-to-correct answer revisions occur at up to 10.6 times the rate of correct-to-incorrect flips, revealing a latent capacity for self-correction that premature commitment forecloses; and (3) strong lures, clinically salient information such as laboratory results trigger premature answering even when models are explicitly instructed to wait. We translate these findings into clinically actionable guidance: deferring the diagnostic question to later turns reduces premature answering and improves accuracy at the first point of commitment by up to 62.6%, while reserving salient clinical evidence for later turns prevents a catastrophic accuracy drop of up to 23.3% caused by premature commitment. Our work provides both a controlled evaluation framework and concrete recommendations for improving the reliability of LLMs in multi-turn medical diagnosis.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper studies how AI “doctor” systems make medical diagnoses when information comes in step by step, like a real clinic visit. The authors built a new test called MINT (Medical Incremental N‑Turn Benchmark) to see whether these systems can wait for enough evidence before deciding. They focus on three behaviors:
- Hold: Can the AI wait before committing to an answer?
- Self-correction: Can it fix wrong guesses when new facts arrive?
- Lure: Do certain “flashy” clues (like lab results) tempt it to answer too soon?
What questions the researchers asked
The team set out to answer, in simple terms:
- Do AI models rush to diagnose before they’ve seen enough information?
- If they wait longer, do they end up more accurate?
- As new facts appear, do they correct earlier mistakes more often than they spoil earlier correct answers?
- Are some kinds of information (like lab results) so tempting that they make AIs jump the gun?
How they studied it (in everyday language)
Think of a medical case as a mystery story. In most tests, the AI gets the whole story at once and then answers. But real doctors usually collect clues over several steps: history, symptoms, exams, lab tests, and so on.
The researchers:
- Built MINT, a “step-by-step” test with 1,035 cases. Each case was split into small, labeled pieces (“evidence shards”) like patient history, physical exam, labs, imaging, etc.—similar to puzzle pieces revealed one at a time.
- Checked that chopping cases into pieces didn’t lose information by comparing results when all pieces were shown together versus the original single story.
- Tested 11 different AI models (both general and medical-specific; both open and commercial).
- Ran two main setups:
- Ask-Question-First (Q‑First): The AI sees the question and answer choices up front, then receives clues piece by piece. It is told to wait and only answer when it feels ready. It can also revise its answer later.
- Ask-Question-Last (Q‑Last): The AI sees all the clues first and only gets the question at the end, so it answers once, after everything is known.
- Tracked when the AI first answered, whether it changed its mind later, and how accurate it was at each point.
- Moved lab results earlier or later in the clue order to see if labs “lure” AIs into premature answers. They compared diseases that truly depend on lab values (like endocrinology or infectious disease) versus those that don’t (like dermatology).
If you like analogies:
- Multi-turn diagnosis = a detective getting clues scene by scene.
- “Hold” = choosing not to guess yet.
- “Self-correction” = changing a wrong guess to the right one as new clues arrive.
- “Lure” = a flashy clue that tempts a detective to accuse the wrong suspect too early.
Main findings and why they matter
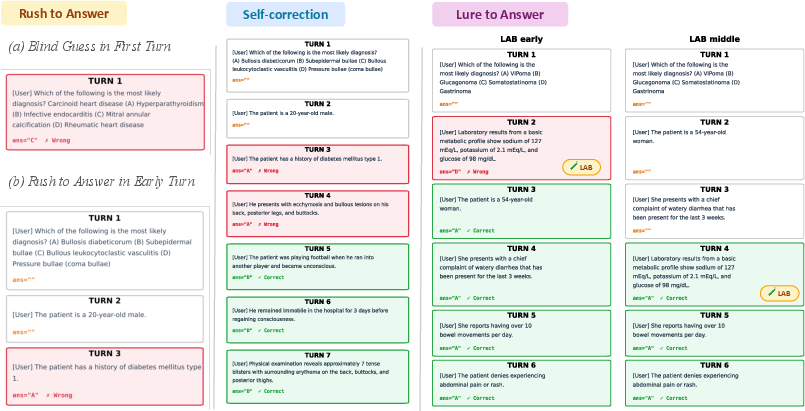
- Many AIs rush to answer too early
- Over half of the first answers (more than 55%) came in the first two turns—before enough evidence was shown.
- Early answers were often wrong, causing big drops in accuracy compared with seeing everything at once.
- When the question was delayed until the end (Q‑Last), accuracy bounced back close to single‑turn performance. In other words, the models can diagnose well—but only if they don’t commit too soon.
- In some models, simply seeing the question and multiple-choice options made them guess immediately, even when told to wait.
Why it matters: In medicine, rushing can lead to unsafe or unnecessary treatments. Just delaying the question (or forcing the model to wait) can greatly improve reliability—sometimes boosting the “first serious answer” accuracy by a lot (reported up to around 62% improvement).
- Waiting unlocks self-correction
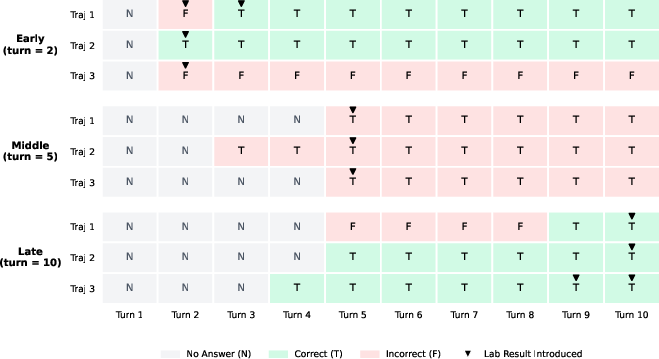
- As more clues arrived, AIs were much more likely to fix a wrong answer than to mess up a right one. In the best cases, “wrong-to-right” flips happened up to 10.6 times more often than “right-to-wrong” flips.
- This means waiting doesn’t just reduce early mistakes—it helps the AI use new evidence to correct itself.
Why it matters: In real care, being able to revise a diagnosis as new test results come in is crucial. Systems that wait can be safer and more dependable.
- Some clues act like “strong lures,” especially lab results
- Putting lab results early made AIs answer sooner—often right after the lab appears.
- For lab‑dependent diseases, early labs sometimes helped. But for diseases that don’t rely on labs, early lab placement pushed AIs into earlier—and more wrong—answers.
- Simply moving lab results later reduced premature answers and the errors that come with them, preventing large accuracy drops (up to about 23% mentioned in the paper).
Why it matters: How information is ordered changes AI behavior. Showing flashy clues too early may cause harmful guesswork.
What this means going forward
- Design AI tools to control “when” they answer, not just “what” they answer. Commitment timing is a core skill.
- In clinical workflows, consider:
- Asking the AI to wait until enough evidence is presented (or only asking the diagnosis at the end).
- Presenting especially tempting information (like labs) later, unless the disease truly depends on it.
- Encouraging the AI to hold and revise as new evidence comes in.
- Future systems should be “commitment-aware”: they should learn to wait, ask follow-up questions if needed, and only decide when the evidence is strong.
Bottom line: These AI models can be very good at diagnosis—but only if we help them avoid answering too early. Careful timing and ordering of information can make them safer and more accurate in doctor-like, step-by-step situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and can guide future research.
Benchmark construction and validity
- Lack of real-world interaction data: MINT is derived by sharding static, single-turn vignettes rather than from genuine clinician–patient dialogues or EHR timelines; external validity to authentic clinical encounters and decision workflows is untested.
- LLM-driven sharding and labeling without clinician validation: Shard boundaries and 13-category clinical labels are produced by Qwen3-32B with no reported human adjudication or inter-annotator agreement; the extent and impact of segmentation or labeling errors on results are unknown.
- Information-preservation check limited to a single model: Equivalence between FULL and CONCAT was validated only with Qwen3-32B; whether other models experience information loss or ordering artifacts remains unassessed.
- Potential dataset contamination: Several source datasets (e.g., MedQA, MedMCQA) are widely used and may overlap with model pretraining; no analysis quantifies contamination risk or its impact on multi-turn behaviors.
Evaluation protocol and metrics
- Multiple-choice only: Findings may be specific to MCQ-format diagnosis with fixed options; generalizability to open-ended differentials, problem lists, or free-text diagnoses is untested.
- No calibration or utility-aware evaluation: The study reports accuracy and abstention but not confidence calibration, decision thresholds, or cost-sensitive utility (e.g., cost of premature vs delayed decisions), which are critical in clinical settings.
- No statistical significance reporting: Differences across settings/models lack confidence intervals or statistical tests, limiting interpretability of effect sizes.
- Limited analysis of rationales and reasoning traces: Self-correction is measured via answer flips (F2T/T2F) without inspecting whether underlying reasoning improves or simply oscillates; links between evidence assimilation and reasoning quality are unexamined.
- Unclear inference settings: Decoding temperature is fixed to 0 for benchmark construction, but inference temperatures/seeds for model evaluation are not fully specified—variance and reproducibility of flip dynamics are not characterized.
Scope of “lure” analysis
- Single evidence type emphasized: Lure effects are demonstrated primarily for laboratory results; the presence, strength, and differences of lure effects for imaging, pathognomonic phrases, vital signs, red-flag symptoms, or medication history remain unexplored.
- Granular attribution of lures: There is no systematic method to identify which specific tokens, phrases, or evidence subtypes trigger premature commitment; feature-level analyses or saliency-based attributions are absent.
- Modality gaps: Non-textual lures (e.g., images, waveforms) are not evaluated; how multimodal cues trigger or mitigate early answering remains an open question.
Interaction design and commitment control
- No tested interventions beyond question timing: While Q-Last improves accuracy, the paper does not evaluate alternative commitment-control strategies (e.g., uncertainty thresholds, explicit “hold” tokens, tool-mediated gating, external controllers, or reward models trained to defer).
- Instruction adherence mechanisms untested: The paper observes that models ignore “WAIT” instructions, but does not compare prompting strategies, system message variants, or supervised/RL fine-tuning to enforce deferral reliably.
- Absence of active information gathering: Models are not allowed to ask questions or choose tests; whether enabling adaptive questioning reduces premature commitment and improves self-correction is untested.
- Lack of dynamic question-reveal policies: Only “ask-first” vs “ask-last” is studied; when and how to reveal questions or evidence adaptively (e.g., mid-turn or confidence-based reveal) is not explored.
Generalizability and coverage
- Limited specialty breadth and case diversity: Although five datasets are included, the benchmark emphasizes exam-style vignettes and dermatology subsets; coverage of acute/emergent care, longitudinal cases, rare diseases, and comorbidity-heavy presentations is limited.
- Turn length and context limits: Experiments cap at 16 turns (and a 9/10-turn subset); how findings scale to longer, complex, or branching conversations—where context decay and instruction drift are stronger—remains unknown.
- Disease-type taxonomy for “lab-dependence”: The lab-dependent vs non-lab-dependent grouping is high-level and may not reflect case-by-case diagnostic reliance on labs; physician-validated per-case dependency labels are absent.
Safety, fairness, and clinical impact
- No harm or risk analysis: The clinical implications of premature incorrect answers (e.g., mis-triage, inappropriate therapy) are not quantified; safety-sensitive metrics are absent.
- Fairness and subgroup performance: Effects of patient demographics (e.g., age, sex, race, social history) on premature commitment and self-correction are not examined; potential biases remain unassessed.
Reproducibility and release
- Benchmark availability and API variability: MINT is to be released upon publication; until then, reproducibility is constrained. Commercial API version changes and nondeterministic behaviors are not controlled or audited over time.
- Option-related priors not controlled: Answer-option ordering and frequency effects that might inflate “guess rate” are not systematically randomized or analyzed.
Open research questions
- How do commitment-control strategies (e.g., confidence gating, abstention training, deliberative scratchpads, policy gradients for timing) compare to simple question deferral in reducing premature errors?
- Which evidence types, phrases, or multimodal features most strongly act as lures, and can models be trained to recognize and resist them?
- Can explicit “readiness” estimation or meta-cognition (e.g., calibrated uncertainty over sufficiency of evidence) improve both accuracy and safety in multi-turn diagnosis?
- Do the observed self-correction patterns hold in open-ended, interactive settings with clinician-validated shard boundaries and real dialogue structure?
- How does enabling active question-asking and test selection affect premature commitment, self-correction, and overall diagnostic utility?
- What is the trade-off between timeliness and accuracy under clinically realistic utility models, and how should models optimize commitment timing accordingly?
- To what extent do these findings persist across languages, healthcare systems, and multimodal clinical inputs (imaging, labs, notes) in real-world deployments?
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s benchmark (MINT), behavioral findings (intent to answer, self-correction, strong lures), and concrete guidance on question timing and evidence sequencing.
- Healthcare: commitment-aware prompting and workflow guardrails in clinical decision support
- Description: Configure LLM-based CDS, telemedicine triage, and symptom checker tools to default to Q-Last (withhold the diagnostic question until all evidence shards are presented) and explicitly encourage abstention/holding until sufficient information is available. Reorder clinically salient shards (e.g., lab results) away from early turns for non-lab-dependent conditions to reduce premature commitments.
- Tools/products/workflows: prompt wrappers enforcing Q-Last; conversation state machines that track “hold/answer/revise”; EHR UI elements that gate diagnostic prompts; “lure scheduling” policies for lab/result timing; dashboards that monitor guess rate, first-answer turn distribution, and F2T/T2F restoration rates.
- Sector: healthcare software (CDS, EHR, telemedicine, digital triage).
- Assumptions/dependencies: access to model configuration and UI; clinician buy-in for minor workflow changes; clear abstention handling; careful application to non-emergency contexts where delaying the diagnosis is safe.
- Healthcare: model selection and procurement criteria based on multi-turn metrics
- Description: Use MINT to compare candidate LLMs on multi-turn reliability (e.g., low guess rate, high restoration rate, lower accuracy drop from FULL to Q-First initial answer) to select safer models for clinical pilots.
- Tools/products/workflows: standardized evaluation reports; procurement checklists with Q-First/Q-Last deltas and lure sensitivity.
- Sector: healthcare procurement and compliance.
- Assumptions/dependencies: availability of the released MINT benchmark; compute/resources to run evaluations; alignment with institutional safety committees.
- Healthcare: safer scribe and intake assistants through evidence sharding
- Description: Structure patient intake and note-taking into clinically labeled shards (history, ROS, vitals, exam, labs) and avoid surfacing a diagnostic question during early documentation. Allow LLMs to ask clarifying questions but defer commitment.
- Tools/products/workflows: shard-aware scribe templates; “ask-clarify-hold” interfaces; lightweight abstention policies.
- Sector: clinical documentation, ambient scribing.
- Assumptions/dependencies: integration with existing scribe tools; training clinicians to interpret “hold” and “revise” states.
- Academia: immediate benchmarking of multi-turn diagnostic behavior
- Description: Adopt MINT to evaluate LLMs in medical AI labs/classrooms; run controlled studies on question timing and shard order; teach “hold and self-correct” as a skill in OSCE-style exercises.
- Tools/products/workflows: course modules using MINT; lab protocols for Q-First/Q-Last comparisons; student exercises on lure-aware reasoning.
- Sector: medical education, AI research.
- Assumptions/dependencies: access to MINT data and prompts; institutional IRB not required (public data); basic compute.
- Policy and governance: guardrail requirements for multi-turn clinical AI deployments
- Description: Incorporate “commitment governance” into institutional policies: require abstention capability, delayed diagnostic commitment, and reporting of flip rates and lure sensitivity in pilots.
- Tools/products/workflows: policy templates; pilot safety checklists; audit logs capturing answer timing and revisions.
- Sector: hospital governance, digital health compliance.
- Assumptions/dependencies: policy authority; alignment with regulatory and payer expectations; clear scope limiting use to decision support (not autonomous diagnosis).
- Software industry beyond healthcare: deferral-first conversational agents
- Description: In customer support and expert advisory bots, default to hold/clarify before commitment; track and report first-answer timing and revision dynamics to reduce premature resolutions.
- Tools/products/workflows: conversation orchestrators with hold-state; timing-aware KPIs; lure detection (e.g., salient but incomplete signals).
- Sector: software (CX, enterprise support).
- Assumptions/dependencies: domain adaptation of MINT-like methodology; product UX support for deferral.
Long-Term Applications
The following applications require further research, scaling, clinical validation, or development before broad deployment.
- Healthcare: commitment-aware diagnostic orchestration engines
- Description: Build systems that optimize when to answer (not only what to answer) by learning a “commitment policy” that balances evidence sufficiency, uncertainty, and risk. Integrate dynamic evidence acquisition (e.g., test ordering suggestions) and lure-aware scheduling (when to expose labs to the model).
- Tools/products/workflows: “Commitment Manager” middleware; timing-aware RLHF or supervised objectives; uncertainty calibrators; active acquisition planners.
- Sector: clinical decision support, adaptive triage.
- Assumptions/dependencies: prospective clinical trials; regulatory review; integration with EHR/test ordering; robust handling of emergencies where deferral could be unsafe.
- Healthcare: EHR and lab system policies that are AI-aware
- Description: Formalize institutional policies that delay exposure of strong lures (e.g., lab results) to AI assistants until sufficient context has been gathered, particularly for non-lab-dependent conditions, while maintaining clinician-first visibility.
- Tools/products/workflows: lure-aware evidence schedulers; configurable shard ordering; override mechanisms for urgent cases.
- Sector: health IT, informatics.
- Assumptions/dependencies: clinician acceptance; workflow safety analyses; vendor collaboration; clear guardrails to avoid withholding critical info from humans.
- Academia and research: training objectives for timing and self-correction
- Description: Develop new learning objectives and architectures that penalize premature commitments, reward correct self-correction (high F2T/T2F), and explicitly model “hold” as a first-class action. Extend MINT to free-form and multimodal (imaging, waveforms) settings.
- Tools/products/workflows: timing-aware loss functions; multi-turn curriculum learning; multimodal MINT; lure-robust training pipelines.
- Sector: AI research, medical AI.
- Assumptions/dependencies: access to multimodal clinical data; compute; reproducible training; collaboration with clinical partners.
- Policy and standards: accreditation criteria for conversational medical AI
- Description: Establish standards that require multi-turn evaluation, abstention capability, commitment timing metrics, and lure sensitivity testing prior to deployment. Mandate logging of answer timing and revision events for post-market surveillance.
- Tools/products/workflows: standard test batteries (including Q-First/Q-Last, reordering of lures); audit frameworks; reporting templates.
- Sector: regulators, accreditation bodies, payers.
- Assumptions/dependencies: stakeholder consensus; harmonization with existing frameworks (e.g., SaMD); evidence from clinical pilots.
- Industry tooling: timing-aware LLM middleware
- Description: Create reusable libraries that: (a) shard inputs into clinically labeled evidence; (b) orchestrate hold/answer/revise loops; (c) detect and deprioritize strong lures; (d) expose timing KPIs (guess rate, first-answer turn, restoration rate). Offer domain packs (medicine, legal, finance).
- Tools/products/workflows: “Evidence Sharder,” “Lure Detector,” “Commitment Orchestrator,” “Hold/Flip Dashboard.”
- Sector: AI platforms, enterprise software.
- Assumptions/dependencies: platform integration (OpenAI/Anthropic/open-source); developer adoption; domain adaptation and tuning.
- Cross-domain decision support (finance, legal, education): timing-first assistants
- Description: Adapt commitment-aware reasoning to domains where decisions unfold with sequential evidence (e.g., financial risk assessment, legal case analysis, educational tutoring). Teach users to gather more context before committing.
- Tools/products/workflows: timing-aware tutors; risk assessment agents that abstain until thresholds are met; lure-aware sequencing of salient but incomplete signals (e.g., single KPI spikes).
- Sector: finance, legal, education.
- Assumptions/dependencies: domain-specific datasets akin to MINT; careful calibration of abstention thresholds; user training on deferral.
- Safety science: formal models of lures and commitment risk
- Description: Build theoretical and empirical frameworks to quantify lure strength, commit-risk curves, and cost–benefit tradeoffs of deferral. Use these models to design optimal sequencing and stopping rules in high-stakes applications.
- Tools/products/workflows: lure strength estimators; commit-risk simulators; decision-theoretic stopping policies.
- Sector: AI safety, operations research.
- Assumptions/dependencies: availability of labeled multi-turn data; cross-institutional validation; interpretability of policies for end-users.
Glossary
- Abstention: The act of not producing an answer even after all information has been revealed in a multi-turn setting. "here, hold denotes choosing not to answer at an intermediate turn, whereas abstention denotes failing to produce a final answer after all turns."
- Abstention rate: The proportion of cases in which a model fails to give a final answer by the last turn. "Under Q-First, we report Ini. (accuracy at the first turn where the model answers), Final (accuracy at the final turn after all evidence shards are revealed), and Abs. (abstention rate)."
- Ask-Question-First (Q-First): An evaluation setting where the diagnostic question is revealed at the beginning and the model can choose when to answer as evidence arrives. "We compare two multi-turn settings that differ only in when the diagnostic question is presented: Ask-Question-First (Q-First) and Ask-Question-Last (Q-Last)."
- Ask-Question-Last (Q-Last): An evaluation setting where the diagnostic question is revealed only at the final turn, forcing a single, deferred answer. "We compare two multi-turn settings that differ only in when the diagnostic question is presented: Ask-Question-First (Q-First) and Ask-Question-Last (Q-Last)."
- Commitment timing: The decision process of when to commit to an answer as evidence unfolds across turns. "whether it can govern commitment timing as evidence unfolds."
- Commitment-aware diagnostic systems: Systems that explicitly optimize not only what diagnosis to make but also when to commit to it. "to develop commitment-aware diagnostic systems that explicitly optimize when to answer alongside what to diagnose."
- Concatenated-shards single-turn input (CONCAT setting): A control condition where all shards are concatenated into one prompt to remove multi-turn effects while preserving content. "by concatenating all shards into a single prompt (the CONCAT setting)"
- Controlled reordering analysis: An experimental manipulation that changes the position of specific evidence (e.g., lab results) across turns while keeping content fixed. "we conduct a controlled reordering analysis under fixed-turn settings"
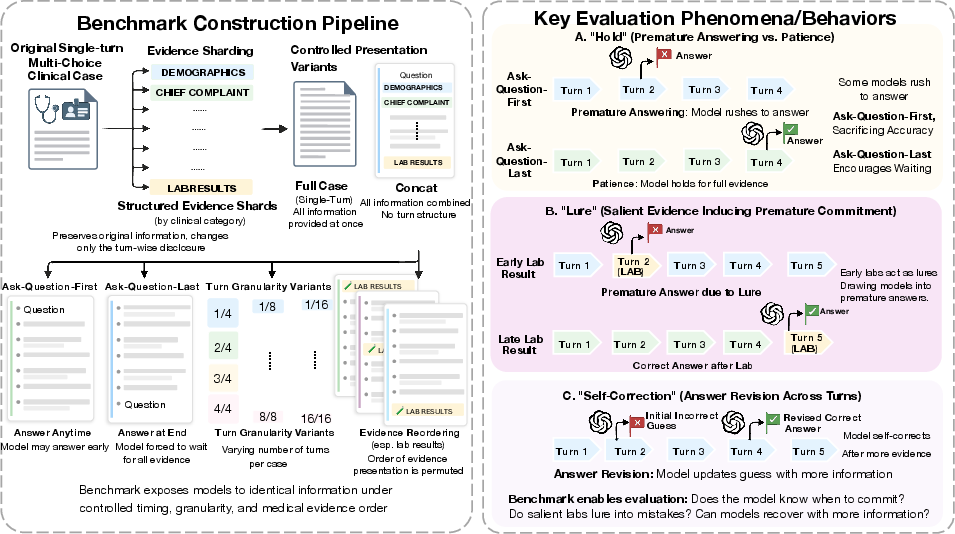
- Controlled turn granularity: Designing the number and size of turns explicitly to study sequential reasoning at different resolutions. "clinically labeled evidence shards, controlled turn granularity, and information-preserving decomposition."
- Deterministic decoding: Inference with fixed randomness settings to ensure reproducibility, often by setting temperature to zero. "All variants are generated using Qwen3-32B with a consistent prompting pipeline and deterministic decoding (temperature = 0), ensuring reproducibility across settings."
- Evidence shards: Segments of a clinical vignette presented sequentially in multi-turn evaluation. "As evidence shards are revealed sequentially, the model may continue to hold, answer at any turn, and revise its answer later if subsequent information changes its judgment."
- False-to-True (F2T): The rate at which an initially incorrect answer is revised to a correct one across turns. "FR denotes flip rate, T2F denotes true-to-false rate, and F2T denotes false-to-true rate."
- Flip rate (FR): The proportion of cases where a model changes its answer between turns. "FR denotes flip rate, T2F denotes true-to-false rate, and F2T denotes false-to-true rate."
- Full setting (FULL): The baseline single-turn condition with the original, unsharded input. "against the original full single-turn input (the FULL setting)"
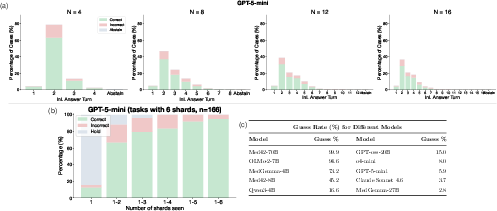
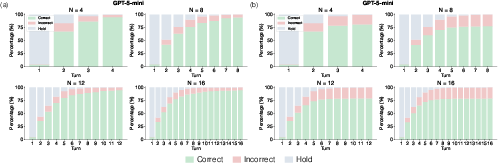
- Guess rate: The fraction of cases where the model answers immediately upon seeing only the question, before any evidence is shown. "We quantify this behavior as the guess rate, defined as the proportion of cases where the model answers at the initial question-only step."
- Hold (decision to wait): Choosing not to answer at a given turn and to wait for more evidence. "here, hold denotes choosing not to answer at an intermediate turn"
- Information-preservation verification protocol: A procedure to ensure that converting from single-turn to multi-turn does not lose or distort information. "we implement an explicit information-preservation verification protocol for MINT."
- Information-preserving decomposition: The process of splitting cases into turns without altering or omitting content. "clinically labeled evidence shards, controlled turn granularity, and information-preserving decomposition."
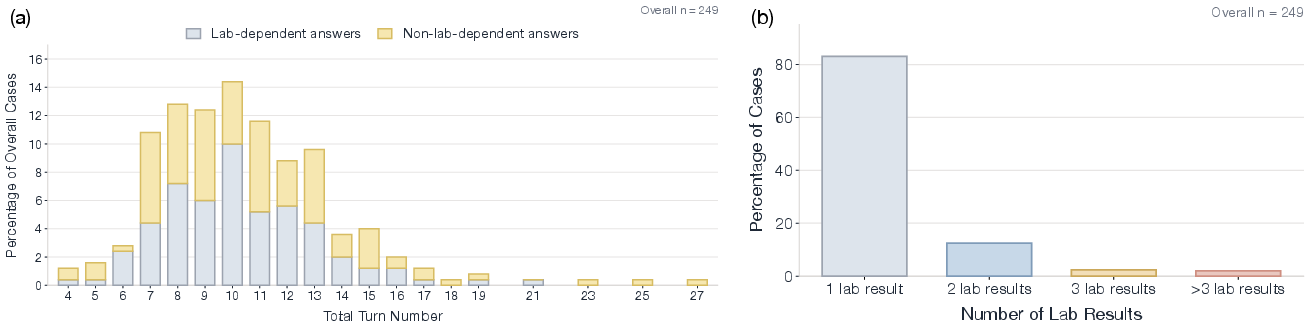
- Lab-dependent diseases: Diagnoses for which laboratory evidence is central to decision-making. "we further group cases into two categories: cases with lab-dependent diseases (e.g., Endocrinology, Infectious Diseases, Hematology and Oncology)"
- Laboratory results: Clinically salient diagnostic evidence that can trigger premature answering when presented early. "clinically salient information such as laboratory results trigger premature answering even when models are explicitly instructed to wait."
- Lures (Strong lures): Highly salient evidence that induces early answering, sometimes prematurely. "(3) strong lures, clinically salient information such as laboratory results trigger premature answering even when models are explicitly instructed to wait."
- Multi-turn evidence accumulation: Sequentially revealing information across turns to mimic real clinical reasoning. "how they behave under multi-turn evidence accumulation closer to real clinical reasoning remains unexplored."
- Premature commitment: Committing to an answer too early, before sufficient evidence has been observed. "preventing a catastrophic accuracy drop of up to 23.3% caused by premature commitment."
- Restoration rate (RR): The ratio of false-to-true to true-to-false flips, quantifying net self-correction. "RR denotes restoration rate, computed as , under the multi-turn Q-First setting."
- Self-correction: A model’s tendency to revise an earlier incorrect answer to the correct one as more evidence appears. "self-correction, incorrect-to-correct answer revisions occur at up to 10.6 the rate of correct-to-incorrect flips"
- Shard (clinical shard): A labeled segment of the clinical case used as a turn in the multi-turn setup. "After decomposing each case into sequential shards"
- Stratified sampling: A sampling method that preserves balance across categories (e.g., diseases) by sampling within strata. "we apply stratified sampling based on disease categories"
- Structured labeling: Systematic annotation of shards with clinically meaningful categories. "with controlled decomposition, verification, and structured labeling"
- Taxonomy of clinical categories: A predefined set of clinical evidence types used to label shards. "a predefined taxonomy of 13 clinical categories"
- Turn-level dynamics: Analyses that track how answers and behaviors evolve at each turn. "and 6) turn-level dynamics in Figure~\ref{fig:panel_figure2}."
- Window size: The number of turns between two prediction states (e.g., incorrect-to-correct) used to characterize revision locality. "using window size, defined as the turn difference between the first occurrence of two prediction states"
Collections
Sign up for free to add this paper to one or more collections.

