What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT
Abstract: Large reasoning models (LRMs) spend substantial test-time compute on long chain-of-thought (CoT) traces, but what characterizes an effective CoT remains unclear. While prior work reports gains from lengthening CoTs and increasing review (revisiting earlier steps) via appended wait tokens, recent studies suggest that shorter thinking can outperform longer traces. We therefore conduct a systematic evaluation across ten LRMs on math and scientific reasoning. Contrary to the "longer-is-better" narrative, we find that both naive CoT lengthening and increased review are associated with lower accuracy. As CoT unfolds step by step, token-level metrics can conflate verbosity with process quality. We introduce a graph view of CoT to extract structure and identify a single statistic-the Failed-Step Fraction (FSF), the fraction of steps in abandoned branches-that consistently outpredicts length and review ratio for correctness across models. To probe causality, we design two interventions. First, we rank candidate CoTs by each metric at test time, where FSF yields the largest pass@1 gains; second, we edit CoTs to remove failed branches, which significantly improves accuracy, indicating that failed branches bias subsequent reasoning. Taken together, these results characterize effective CoTs as those that fail less and support structure-aware test-time scaling over indiscriminately generating long CoT.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT”
1) What is this paper about?
This paper studies how AI “thinks out loud” when solving hard problems, like tricky math or science questions. Many AIs write long, step-by-step explanations called chain-of-thought (CoT). People often assume that longer thinking is better. The authors test that belief and look for what really makes AI reasoning effective.
2) What questions are the researchers asking?
They focus on three simple questions:
- Does writing longer explanations make an AI more accurate?
- Does doing more “review” (checking, re-reading, or backtracking) help accuracy?
- Is there a deeper pattern in how the reasoning is organized that explains success or failure?
3) How did they study it?
Think of solving a maze:
- Each path you try is a “branch.”
- If you hit a dead end and turn back, that path was a failed branch.
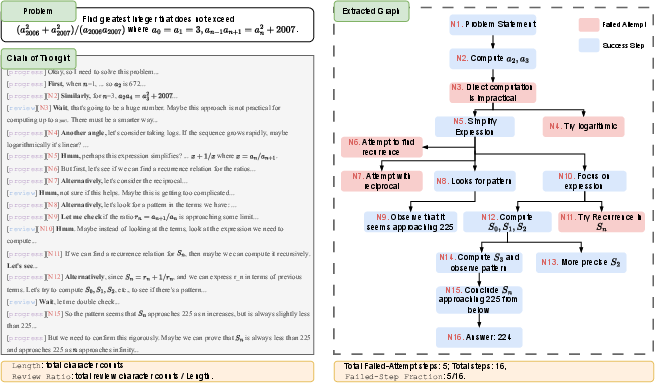
The authors looked at how AIs solve problems and turned each chain-of-thought into a “map” (a graph) of steps and branches—like a maze with paths and dead ends.
What they did, in everyday terms:
- They tested 10 different AI models on hard math and science questions.
- For each question, they asked each AI to think out loud many times (multiple tries), so they could compare different attempts on the same question.
- They measured:
- Length: how long the explanation is (in characters).
- Review Ratio: how much of the text is “reviewing” (checking or re-stating) instead of making new progress.
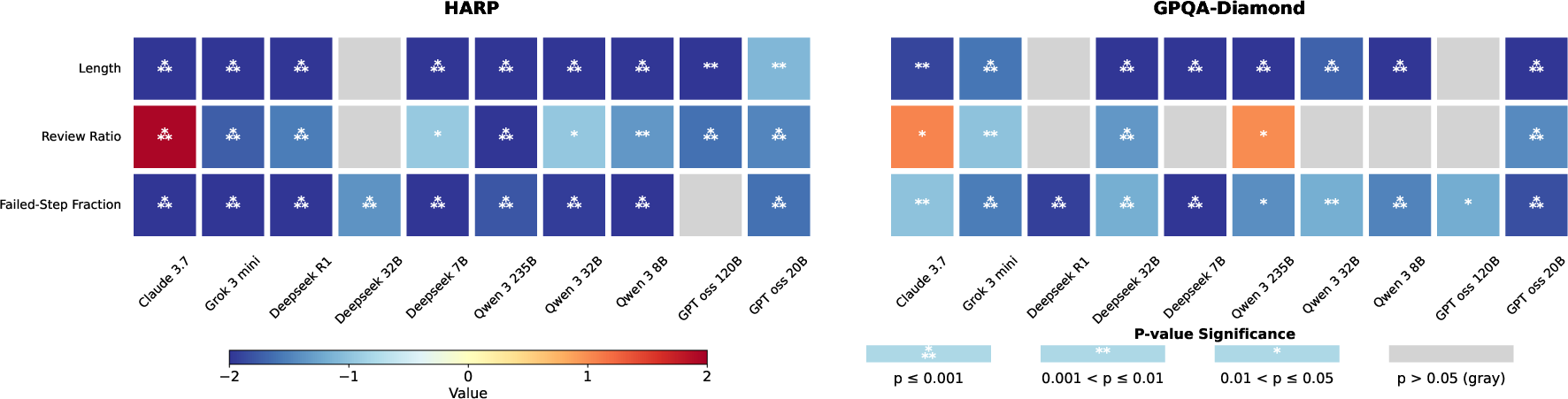
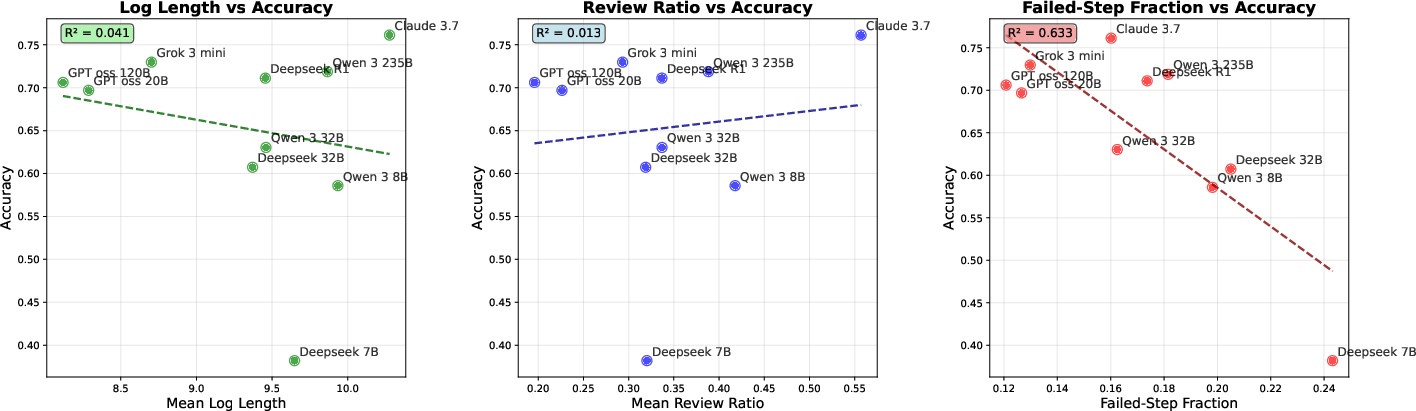
- Failed-Step Fraction (FSF): the share of steps spent on branches the AI later abandons (dead ends). In simple terms, FSF is “what percent of the thinking was wasted on paths that didn’t work out.”
They ran two kinds of tests:
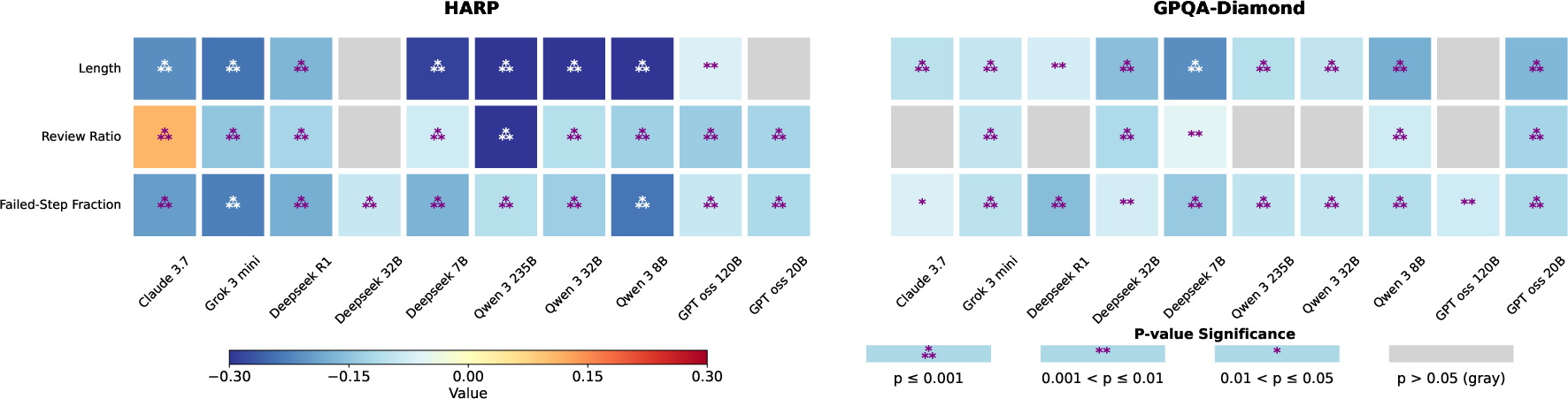
- Correlation: Within the same question, do longer, more-review, or lower-FSF explanations line up with higher accuracy?
- Causation checks:
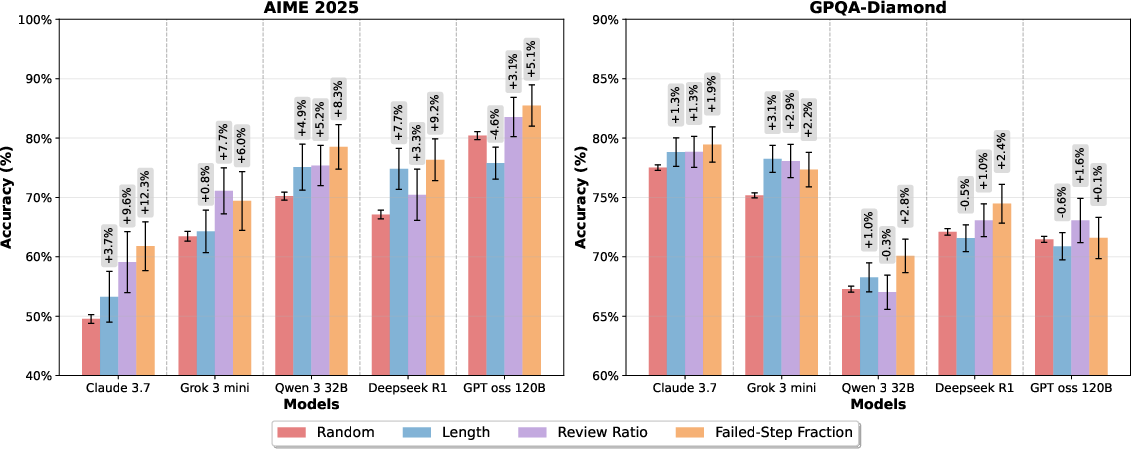
- Selection test: For each question, they generated many answers, then picked the one with the best metric (like lowest FSF) to see which rule improved accuracy the most.
- Editing test: They literally removed the failed branches from an AI’s partial solution and checked if continuing from a “cleaner” version increased the chance of getting the right final answer.
4) What did they find, and why does it matter?
Main results:
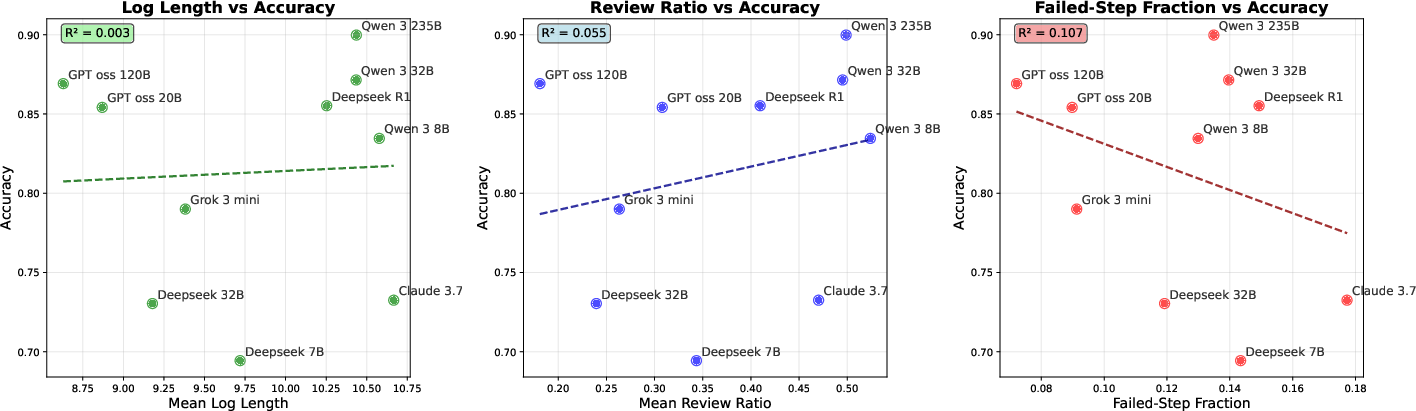
- Longer isn’t better. For the same question, shorter explanations tended to be more accurate.
- More review isn’t usually better. For most models, a higher review ratio (more checking/backtracking) was linked to worse accuracy. There are exceptions (one strong model sometimes benefited), but the general trend was negative.
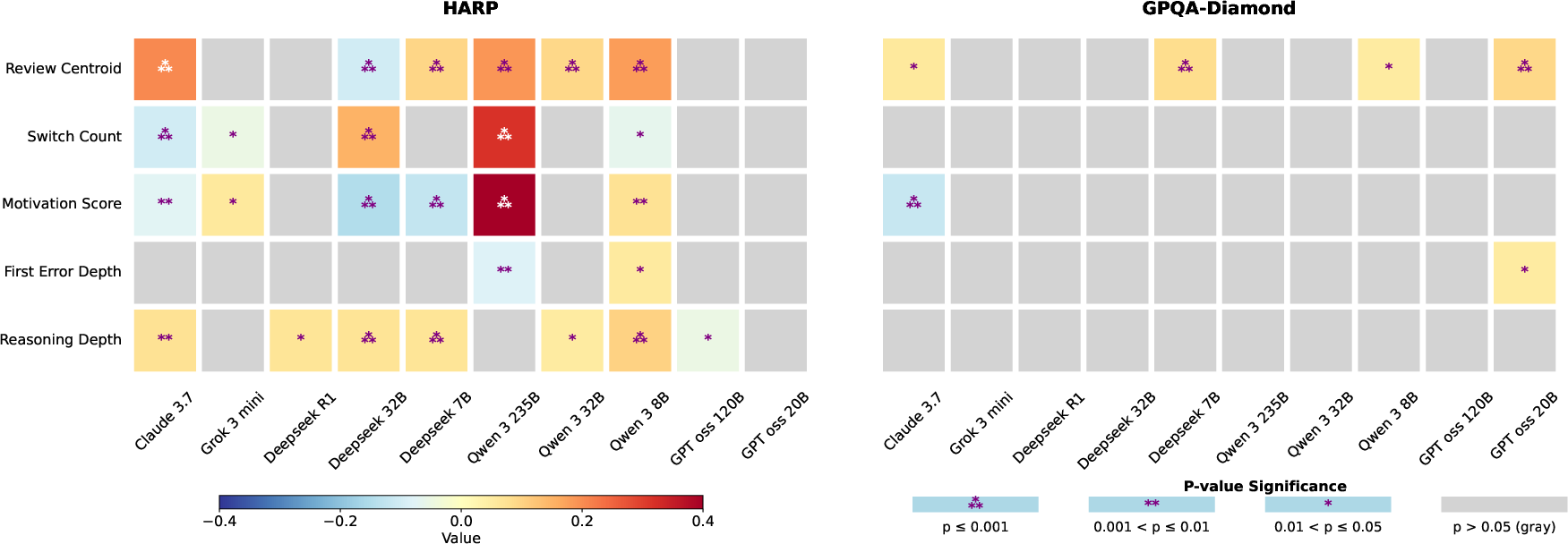
- Structure matters most. The strongest and most reliable signal of a good solution was a low Failed-Step Fraction (FSF). In other words, the less time the AI spent exploring dead ends, the more likely it was to be correct. This held across all 10 models and both math and science tasks.
- Causal proof:
- Picking the answer with the lowest FSF among many tries boosted accuracy (on a tough math test, gains were up to about 10%).
- Editing out failed branches and then continuing the reasoning increased success rates by roughly 8–14%. That means dead-end thinking doesn’t just waste time—it can pull the AI off track later, even after it “backs up.”
Why it matters:
- These results challenge the idea that we should just make AIs “think longer.” It’s not the amount of thinking but the quality and structure that matter.
- Reducing time spent on failed branches improves performance and saves time and computing power.
5) What’s the big takeaway?
If you want better AI reasoning:
- Don’t just ask the AI to think more. Aim for cleaner thinking.
- Focus on structure-aware strategies: avoid or trim failed branches, and pick solutions that show fewer abandoned paths.
- Tools that detect and reduce failed steps during reasoning could make AIs faster, cheaper, and more accurate.
Key terms in plain language
- Chain-of-thought (CoT): The AI’s step-by-step explanation of how it’s thinking.
- Review: Parts where the AI checks or restates earlier steps instead of advancing the solution.
- Reasoning graph: A “map” of the AI’s thinking, showing branches and dead ends.
- Failed-Step Fraction (FSF): The percentage of steps spent on dead-end branches. Lower is better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, expressed as concrete, actionable gaps for future research.
- Generalization beyond math and scientific QA: Validate whether FSF’s predictive and causal effects hold in code generation, theorem proving, planning, long-form writing, multimodal reasoning, and real-world task chains.
- Applicability to models without accessible CoT: Determine if FSF-based insights transfer to models that do not expose reasoning traces (e.g., purely “final-answer” systems) or that obfuscate CoT.
- Mechanistic explanation of failure bias: Identify the internal representational or attention-level mechanisms by which failed branches bias subsequent reasoning; probe hidden states or token-attribution to quantify “failure propagation.”
- Online FSF estimation: Develop methods to estimate FSF incrementally during generation (without post-hoc extraction), enabling dynamic pruning or early stopping when failure accumulates.
- Training-time interventions: Explore curricula, objectives, or RL schemes that directly minimize FSF (or penalize failed-branch proliferation) during training, and measure downstream effects on reasoning efficiency and accuracy.
- Decoding policy design: Systematically evaluate beam/search-like policies, tree-of-thought schedulers, and inference-time RL that actively suppress failed branches vs. encourage breadth; quantify compute–accuracy trade-offs under FSF-aware control.
- FSF as a stopping criterion: Test whether dynamic stopping policies triggered by rising FSF (or its derivative) can reduce latency and compute while preserving accuracy.
- Granular review taxonomy: Disaggregate “Review” into finer categories (e.g., verification, restatement, backtracking, deletion) and measure their distinct effects on correctness across models and tasks.
- Why Claude benefits from higher Review Ratio: Investigate model-specific differences (architectural, training, prompting) that led Claude 3.7 to show a reverse Review–accuracy trend on math; identify conditions under which review is beneficial.
- Joint modeling of metrics: Fit multivariate models controlling jointly for FSF, Length, and Review Ratio to quantify partial effects and potential multicollinearity; assess whether combined predictors outperform FSF alone.
- Graph extraction faithfulness: Establish benchmarks and human annotation protocols to validate that extracted reasoning graphs—and “failed” node labels—faithfully represent the CoT’s logical structure across diverse tasks.
- Algorithmic failure labeling: Replace LLM-as-judge failure labeling with explicit, rule-based or verifier-aided criteria (e.g., algebraic checkers, constraint satisfiers) to reduce subjectivity and leakage risks.
- Robustness to annotation noise: Quantify how errors in review labeling and graph extraction (currently ~10% disagreement) affect correlation strength, selection outcomes, and intervention gains; propose denoising methods.
- Cross-language and domain terminology: Test whether keyword-based segmentation and review labeling generalize to other languages and specialized jargon (law, medicine, finance) without substantial manual retuning.
- Decoding hyperparameters sensitivity: Report how temperature, top‑p, repetition penalties, and nucleus sampling affect FSF, Length/Review correlations, and selection gains; derive robust operating regimes.
- Pass@k and aggregation strategies: Compare FSF-based top‑1 selection against self-consistency, majority vote, weighted voting, and confidence-weighted aggregations; evaluate hybrid selectors.
- Compute overhead and ROI: Measure the latency and cost of graph extraction and FSF estimation versus the achieved accuracy gains; develop lightweight estimators that make FSF-based selection practical at scale.
- Early pruning risks: Evaluate whether pruning “failed” branches harms beneficial exploration on hard problems; characterize when exploration with temporary failure improves ultimate success.
- Effects on correct traces: Test whether removing or summarizing failed branches in already-correct CoTs ever reduces accuracy (false pruning); define safety checks for interventions.
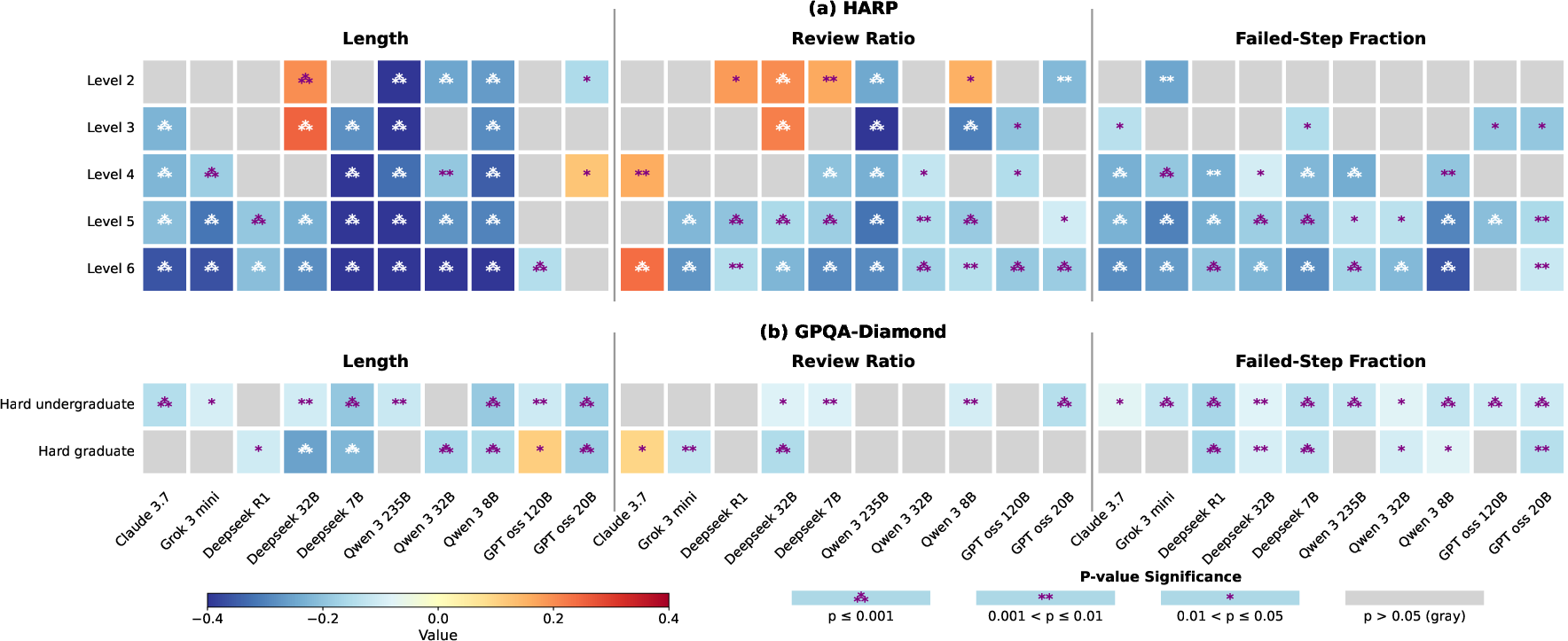
- Domain difficulty calibration: Investigate whether human difficulty labels match model difficulty; build model-centric difficulty measures and re-examine correlation strength across matched strata.
- Dataset coverage and contamination: Assess contamination risks for GPQA-Diamond; expand to larger, cleaner, and more diverse benchmarks to stress-test FSF’s robustness.
- Self-estimation reliability: Measure how well each model can self-extract its own reasoning graph and FSF (without external judges), and whether “self-estimate, self-select” improves accuracy consistently.
- Integration with verifiers: Combine FSF with step-level mathematical or logical verifiers (e.g., Math-Verify) to distinguish “failed exploration” from “incorrect computation,” and test composite selectors.
- Temporal dynamics of failure: Analyze when failures occur (density over steps), their persistence, and recovery patterns; test whether the timing and clustering of failures affects outcomes beyond total FSF.
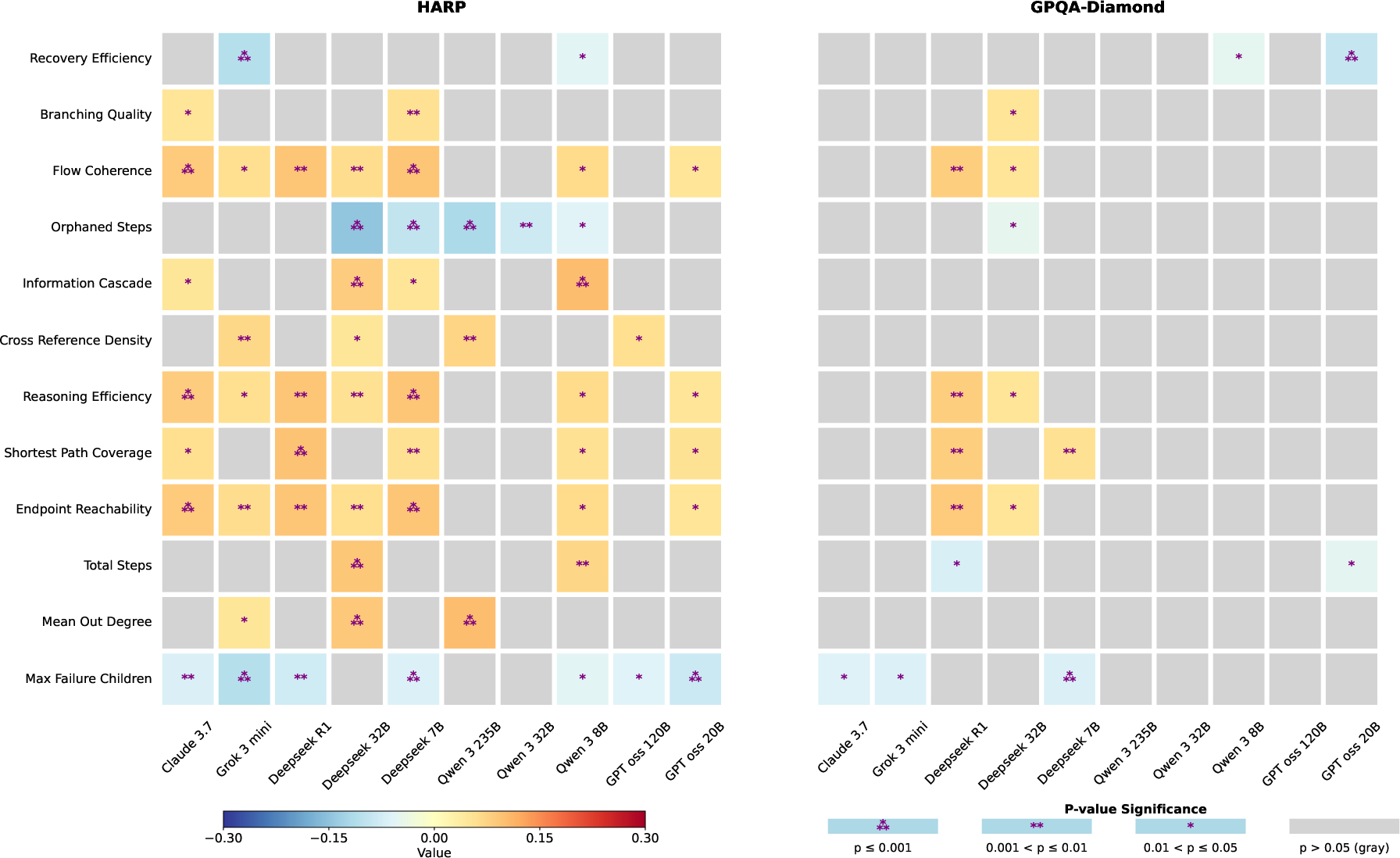
- Branch structure beyond FSF: Explore additional structural metrics (branching factor, depth variance, rejoin frequency, cycles) and whether combinations predict correctness better than FSF alone.
- External validity in user settings: Evaluate FSF-based selection and pruning in interactive scenarios (limited budgets, latency constraints, streaming outputs) and measure user-perceived improvements.
- Prompting and instruction effects: Systematically vary prompts that encourage verification or concise planning; test whether prompt engineering can reduce FSF without sacrificing accuracy.
- Multimodal reasoning graphs: Extend graph extraction to include visual/audio nodes and cross-modal edges; assess whether FSF generalizes in multimodal contexts.
- Theoretical framing: Develop formal models (information-theoretic or decision-theoretic) explaining why failed branches reduce success probability, and derive principled design criteria for inference policies.
Glossary
- AIME 2025: A 30-problem math benchmark often used to evaluate reasoning without contamination concerns. "We evaluate on AIME 2025 (30 problems), which is widely regarded as contamination-free math dataset for recent LRMs,"
- Bayesian generalized linear mixed-effects model (GLMM): A statistical model combining fixed and random effects under a Bayesian framework to analyze binary outcomes like correctness. "we fit a Bayesian generalized linear mixed-effects model (GLMM) for correctness as a function of each metric,"
- Bootstrap: A resampling technique to estimate uncertainty by repeatedly sampling with replacement. "we estimate uncertainty via bootstrap: for each model–problem, we draw 200 replicates by resampling the 64 candidates with replacement,"
- Chain-of-thought (CoT): Step-by-step natural language reasoning traces generated by a model before answering. "Large reasoning models (LRMs) spend substantial test-time compute on long chain-of-thought (CoT) traces,"
- Claude 3.7 Sonnet: A specific LLM variant from Anthropic used here for graph extraction without thinking mode. "Specifically, we prompt Claude 3.7 sonnet with thinking disabled to convert each CoT into Graphviz format"
- Conditional correlation analysis: Correlation computed after controlling for confounders (e.g., per-question effects) to isolate relationships. "Using a conditional correlation analysis to isolate the question-level confounding factors"
- Difficulty strata: Subdivisions of datasets by human-labeled difficulty levels to analyze behavior across hardness. "allowing us to examine patterns across different difficulty strata."
- Failed-Step Fraction (FSF): The proportion of reasoning steps in a graph marked as failed or abandoned. "Failed-Step Fraction(FSF): the fraction of steps belonging to failed exploratory branches."
- GPQA-Diamond: A graduate-level, “Google-proof” scientific reasoning benchmark split. "and the GPQA-Diamond dataset \citep{rein2024gpqa}, which covers scientific reasoning."
- Graph-level metrics: Measures computed over a reasoning graph (nodes/edges) rather than tokens or characters. "This representation allows for the evaluation of graph-level metrics."
- Graphviz: A graph description language and toolchain used to render and analyze graphs. "to convert each CoT into Graphviz format"
- HARP: A human-annotated math reasoning dataset with difficulty labels. "We leverage the HARP dataset \citep{yue2024harp}, which is centered on mathematical reasoning,"
- Large reasoning models (LRMs): LLMs optimized for multi-step reasoning and extensive test-time computation. "Large reasoning models (LRMs) increasingly exploit test-time compute by generating long chain-of-thought (CoT) traces."
- LLM-as-a-judge: Using a LLM to label or evaluate outputs from another model. "We measure Review behavoirs with an LLM-as-a-judge procedure."
- Mixture of expert models: Architectures that route inputs to specialized expert subnetworks to improve efficiency or capability. "including both dense models and mixture of expert models."
- pass@1: The probability that the top-1 selected solution is correct when multiple candidates are sampled. "and evaluate top-1 (pass@1) performance."
- Progressiveness entropy: A stylistic/structural measure related to how steadily reasoning progresses (referenced as an auxiliary metric). "and progressiveness entropy (Appendices~\ref{append:other metrics} and \ref{append:further})."
- Question fixed effects: Per-question controls included in a model to account for question-specific difficulty or bias. "i.e., include question fixed effects"
- Random intercepts: Random-effect terms allowing baseline outcomes to vary across groups (e.g., questions). "with random intercepts at the question level."
- Reasoning frontier: The current point in a solution where new progress is being made. "advances the active reasoning frontier, producing information that later steps rely on."
- Reasoning graph: A structured representation of a CoT where nodes are reasoning steps and edges encode dependencies. "we further extract a reasoning graph for each CoT to probe structural properties."
- Residualized correctness: Correctness values adjusted by removing group-level means (e.g., per-question) before correlation. "and then correlate these residualized values with residualized correctness across all data."
- Review Ratio: The fraction of tokens/characters labeled as review (checking/backtracking) within a CoT. "We define Review Ratio as the fraction of Review tokens within a CoT to isolate the effect of Review from Length."
- Rerank: Ordering candidate solutions by a metric to select a final answer. "we rerank by each metric, and evaluate top-1 (pass@1) performance."
- S1 approach: A test-time scaling method that appends “wait” prompts/tokens to extend reasoning and encourage review. "In the S1 approach, inserting wait increases generation Length and encourages Review behaviors,"
- Structure-aware selection: Choosing outputs based on structural reasoning quality (e.g., graph metrics) rather than length alone. "prefer structure-aware selection \citep{yao2023tree, bi2024forest}"
- Test-time compute: Computation performed during inference (generation), as opposed to training time. "increasingly exploit test-time compute"
- Test-time scaling: Improving performance by increasing computation at inference, such as generating longer thoughts. "exhibiting characteristic test-time scaling behavior."
- Test-time selection: Selecting among multiple sampled generations at inference time using a metric or policy. "We now use test-time selection as a causal probe."
- Wait tokens: Special tokens or prompts that encourage a model to continue thinking/reviewing without finalizing an answer. "appends wait tokens to increase generation length"
Practical Applications
Practical, Real-World Applications Derived from the Paper
The paper provides actionable insights and tools for improving the reliability, efficiency, and user experience of large reasoning models (LRMs) by focusing on structure-aware test-time scaling rather than indiscriminately lengthening chain-of-thought (CoT). The centerpiece is the Failed-Step Fraction (FSF) metric and associated workflows for graph-based CoT extraction, selection, and editing. Below are immediate and longer-term applications across sectors.
Immediate Applications
The following applications can be deployed now using the paper’s methods (FSF-based selection, CoT graph extraction, review-aware filtering, branch pruning/summarization) and observed causal gains.
- FSF-based candidate selection in LLM inference
- Sector: software/AI platforms, search, knowledge work tools
- Tool/workflow: sample multiple CoTs per query (e.g., 16–64), auto-extract a reasoning graph, compute FSF, select the lowest-FSF trace (pass@1 gains of 5–13% reported)
- Use cases: math/scientific problem-solving assistants, coding copilots selecting the most reliable reasoning trace, internal QA systems picking the best answer from multiple drafts
- Assumptions/dependencies: access to multiple generations per query; a reliable FSF estimator (via graph extraction with an LLM and Graphviz); modest added compute for multi-sampling
- Cost and latency reduction by curbing overthinking
- Sector: AI/ML infrastructure, customer support, consumer assistants
- Tool/workflow: dynamic stop rules that penalize long CoTs and high review ratio; early termination when FSF rises; “no-wait-token” policies unless needed
- Use cases: faster assistants for routine queries; lowering API token bills; improved responsiveness in live chat and call centers
- Assumptions/dependencies: telemetry on CoT length/review behaviors; policy controls in decoding; user tolerance for slightly lower recall on very hard questions
- Reasoning Quality Gate for high-stakes decisions
- Sector: finance (research, risk), legal/compliance, healthcare (patient education, administrative support)
- Tool/workflow: gate outputs using FSF thresholds; escalate to human or additional sampling when FSF is high; require low-FSF before actioning
- Use cases: investment research summaries, policy memo drafting, patient-facing educational content where clarity and correctness matter
- Assumptions/dependencies: CoT access or internal reasoning extraction; calibration of FSF thresholds to domain risk; human-in-the-loop escalation path
- Structure-aware chain-of-thought pruning/summarization
- Sector: education, software development, research assistance
- Tool/workflow: detect failed branches in real time, remove or summarize them before continuation; emit cleaner, shorter explanations
- Use cases: student tutors that avoid confusing detours; coding assistants that drop dead-end hypotheses; literature review helpers that keep the reasoning focused
- Assumptions/dependencies: ability to segment and annotate CoT; lightweight summarization module; models that support continuation from edited contexts
- Reliability scoring and monitoring for LLM operations
- Sector: MLOps/LLMOps
- Tool/workflow: dashboards tracking FSF, length, review ratio per domain, model, and prompt cohort; alerting when FSF spikes
- Use cases: detecting regressions after model updates; identifying prompts yielding high failure-driven verbosity; capacity planning based on FSF-driven token budgets
- Assumptions/dependencies: CoT observability; standardized FSF computation; integration with ops telemetry
- Evaluation upgrades in academia and industry benchmarking
- Sector: academia, model evaluation, QA teams
- Tool/workflow: add FSF to metrics alongside accuracy; run conditional correlation analyses controlling for question difficulty; test-time selection experiments for causal validation
- Use cases: better model comparisons on math/science reasoning; prompt engineering studies; assessment of test-time scaling strategies
- Assumptions/dependencies: multiple generations per item; difficulty-stratified datasets (e.g., HARP, GPQA); a stable FSF extraction pipeline
- Policy guidance for procurement and governance
- Sector: public sector, enterprise governance, AI ethics
- Tool/workflow: guidance discouraging indiscriminate “wait token” usage; recommend structure-aware selection and pruning; require reporting of FSF-like quality metrics in vendor assessments
- Use cases: RFPs for AI systems that mandate reasoning quality controls; audit-ready reporting for AI deployments in regulated contexts
- Assumptions/dependencies: standardized measurement protocols; vendor cooperation; alignment with existing risk frameworks
Long-Term Applications
These applications require further research, scaling, or development—particularly training-time integration, model architecture changes, domain generalization, and broader standardization.
- Training-time optimization for low-FSF reasoning
- Sector: AI model development
- Tool/workflow: integrate FSF into reinforcement learning or inference-time RL rewards; train models to avoid failed branches and reduce failure propagation
- Potential products: “FSF-optimized” reasoning models; low-FSF decoding strategies
- Assumptions/dependencies: reliable FSF labels during training; alignment with task goals; generalization beyond math/scientific reasoning
- Graph-native reasoning architectures and agents
- Sector: software/AI, autonomous agents, robotics planning
- Tool/workflow: reasoning graph as a first-class primitive; tree/forest-of-thought orchestrators that plan exploration, prune branches, and manage context using FSF and related graph metrics
- Potential products: reasoning orchestration engines; agent planners with FSF-aware search; IDEs that show live reasoning graphs for code synthesis
- Assumptions/dependencies: faithful graph extraction; latency constraints; robust mapping between natural language steps and logical graph structure
- Compute schedulers that adapt token budgets using FSF
- Sector: cloud AI infrastructure, edge AI
- Tool/workflow: real-time schedulers that allocate more compute to low-FSF traces and cut budget on high-FSF candidates; tiered resource allocation across users/tasks
- Potential products: FSF-aware inference controllers; energy-efficient LLM serving
- Assumptions/dependencies: accurate early FSF estimation; predictable effects across diverse tasks; integration with serving stacks
- Domain-specific safety layers using FSF and failure controls
- Sector: healthcare decision support, finance trading/compliance, legal drafting
- Tool/workflow: combine FSF gating with domain verifiers (e.g., math-checkers, medical knowledge bases); enforce branch pruning before tool calls
- Potential products: “Safe Reasoner” gateways; compliance auditors that log FSF and branch edits
- Assumptions/dependencies: tool grounding and verification; robust FSF generalization; human sign-off and policy integration
- Educational analytics from AI tutors’ reasoning quality
- Sector: education technology
- Tool/workflow: track FSF and review ratio in explanations; personalize tutoring by reducing failure-driven detours; teacher dashboards showing reasoning quality trends
- Potential products: classroom analytics; student-facing “clean explanation” modes
- Assumptions/dependencies: CoT access; alignment with pedagogical goals; avoiding over-pruning that hides valuable reflection
- Cross-model standardization and regulation for reasoning metrics
- Sector: policy and standards bodies
- Tool/workflow: define a standardized FSF computation protocol; reporting requirements for reasoning quality and test-time scaling behavior; certification frameworks
- Potential products: auditing toolkits; public benchmarks with FSF baselines
- Assumptions/dependencies: widespread acceptance; interoperability across vendors; evolution as models change internal reasoning visibility
- Robotics and autonomous systems planning with failure-aware pruning
- Sector: robotics, industrial automation
- Tool/workflow: translate FSF-like concepts to planning graphs; prune failed action sequences; summarize detours to prevent bias in subsequent steps
- Potential products: safer task planners; failure-aware multi-agent coordination
- Assumptions/dependencies: reliable mapping from language CoT to planning graphs; integration with sensors and simulators; validation in real environments
- Energy and sustainability optimization through reasoning efficiency
- Sector: energy-conscious computing, green AI
- Tool/workflow: quantify energy savings by reducing unnecessary review and long CoTs; FSF-based policies to cut wasteful compute
- Potential products: sustainability dashboards; greener inference policies
- Assumptions/dependencies: accurate energy measurement; alignment with performance targets; user acceptance of tighter budgets
Key Assumptions and Dependencies Across Applications
- CoT access or the ability to extract reasoning graphs from model outputs; some proprietary LRMs restrict or mask internal “thinking.”
- FSF estimation fidelity: depends on robust graph extraction and labeling of failed branches; current method uses LLMs and Graphviz learned during pretraining.
- Multi-sample inference budget: FSF-based selection requires sampling multiple candidates; organizations must weigh accuracy gains against added compute.
- Generalization: FSF effects are validated on math and scientific reasoning (HARP, GPQA-Diamond); performance in other domains may vary and should be tested.
- Safety and compliance: high-stakes contexts need human oversight, tool grounding, and domain-specific verification alongside FSF gating.
- User experience: pruning/summarization must preserve clarity and necessary reflection; aggressive pruning may omit valuable explanatory context.
Collections
Sign up for free to add this paper to one or more collections.

