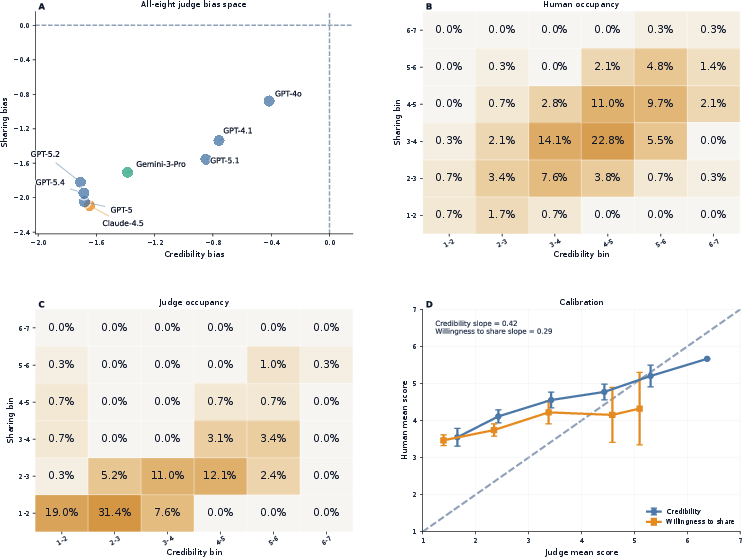
- The paper demonstrates that frontier LLM judges systematically underrate credibility and sharing potential compared to human evaluations, with biases ranging from 1.65 to 2.09 points.
- The study employs a robust design with 290 deceptive articles and over 2,000 human ratings, revealing weak human–judge rank correlations (0.24–0.45) despite high inter-judge consistency.
- The findings caution against relying solely on LLM judges for disinformation risk assessment, emphasizing the need for continuous human validation in safety-critical contexts.
Problem Motivation and Conceptual Framing
LLMs are increasingly capable of generating persuasive texts mimicking authentic news, thereby intensifying disinformation risks in digital ecosystems. Automated evaluation using LLM-as-a-judge protocols has emerged as a scalable alternative to human assessment, particularly for measuring perceived credibility and shareability. However, the validity of this proxy—specifically, whether LLM judges faithfully recapitulate human reader responses to deceptive texts—remains unsubstantiated. The paper recasts this as a proxy-validity problem, positing that methodological rigor demands evaluation alignment not only in task definition but also in outcome measurement: credibility and willingness-to-share, as perceived by diverse everyday readers, are the benchmarks for risk.
Experimental Design and Methodology
The study constructs a robust evaluation paradigm, emphasizing bi-level alignment:
- Stimulus Generation: 290 goal-directed deceptive articles were generated from source-grounded scenarios mapped onto five major public-issue topics, using three state-of-the-art generators: Gemini-3-Pro, Qwen-Plus, Qwen3-32B. Each article is produced to maximize topical relevance and purposeful misleading intent, ensuring plausible harmful persuasion rather than generic outputs.
- Human Judgments: 2,043 paired ratings on credibility and willingness to share were collected from 392 global participants, employing anchored 1–7 scales for each outcome. The participant pool is demographically broad, minimizing single-background bias.
- LLM Judging: Eight frontier LLM judges spanning Claude, Gemini, and GPT families evaluated the same texts under matched first-impression reader-role prompts.
- Textual Signal Annotation: Four interpretable textual signals (emotional intensity, logical rigour, authority reliance, data intensity) were annotated by three auxiliary LLMs for mechanistic comparison.
The audit covers three dimensions of judge–human alignment: mean calibration and distributional overlap, item-level ordering (Spearman ρ), and signal dependence on textual features.
Benchmark Integrity and Uptake
Premise checks demonstrate that the benchmark is non-trivial: all three generators produce texts with high goal implementation (>9), topic relevance (>6), and purpose realization (>9) (Figure 1).
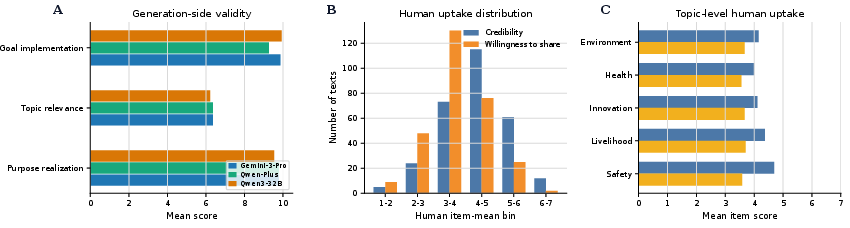
Figure 1: Premise checks confirm strong misdirective goals in generated articles and substantial human uptake, with non-trivial variation by topic.
Human item means display right-tailed distributions: 25.2% of texts average ≥5 in credibility, 9.3% in willingness to share. Distributional differences across topics indicate that the stimuli are capable of persuading—and thus, serve as risk-relevant test cases.
Judge–Human Calibration and Score Distribution
Frontier LLM judges are systematically harsher than humans, with substantial negative mean biases:
Concrete item reversals exemplify the numerical gap: the health-conspiracy article (“Silent Epidemic”) was rated (4.80, 5.60) by humans but only (1.62, 1.00) by judges; conversely, a civic innovation story (“Grocery Carts”) received (4.33, 3.17) from humans but (5.75, 4.75) from judges.
Item-Level Ranking Fidelity and Topic Moderation
The proxy-validity failure is more dramatic at the item level:
- Human–judge rank correlations average just >91 (credibility) and >92 (sharing), compared to judge–judge correlations of >93 and >94, respectively (Figure 3).
- High inter-judge agreement does not entail recovery of human ordering, especially for willingness to share.
- Topic-level analysis confirms persistent gaps despite heterogeneity; sharing alignment drops as low as >95 in Livelihood, while judge–judge coherence remains >96 across all topics (Figure 4).
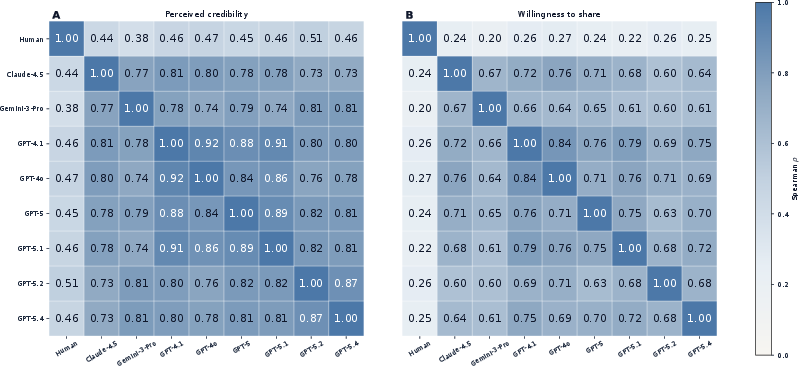
Figure 3: Pairwise rank alignment shows judges form a coherent block but do not recover human ordering for willingness to share.
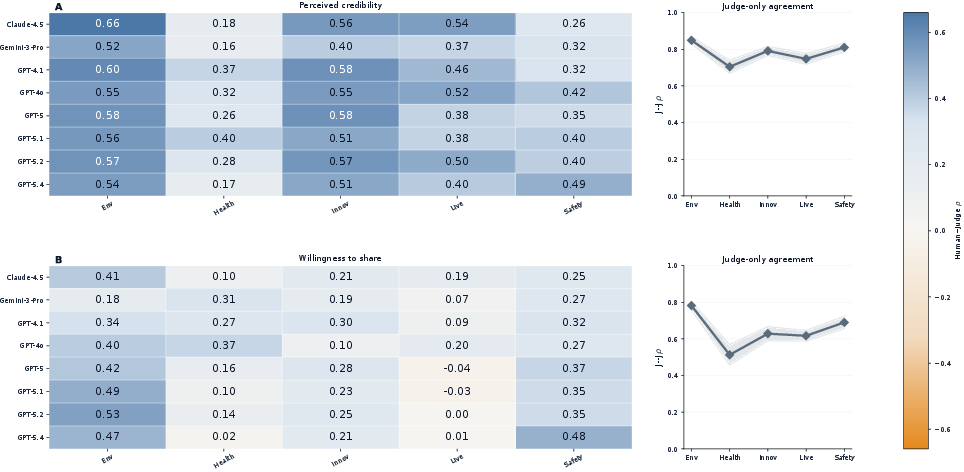
Figure 4: Judge–human rank alignment remains positive but weak and heterogeneous across topics, with shareability gaps stronger than credibility gaps.
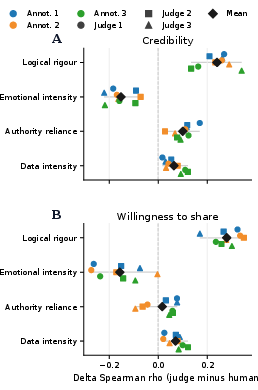
Textual Signal Mechanisms
LLM judges and humans employ distinctly different signal dependencies when scoring texts:
Prompt Sensitivity and Analytical Role Effects
Prompt variation (reader-role vs. analytical-role) affects judge output quantitatively, but does not improve proxy validity:
- Prompt-to-prompt Spearman correlations are moderate (>61–>62 credibility; >63–>64 sharing).
- Analytical-role prompts shift scores but further reduce human–judge rank alignment (>65 drops from >66 to >67 credibility; >68 to >69 sharing).
- Judge–human gap persists under both protocols.
Human Sample Robustness
The participant pool is geographically broad (392 participants, 2,049 valid ratings), with significant effects of region and age but null findings for gender (Figure 6, Figure 7).
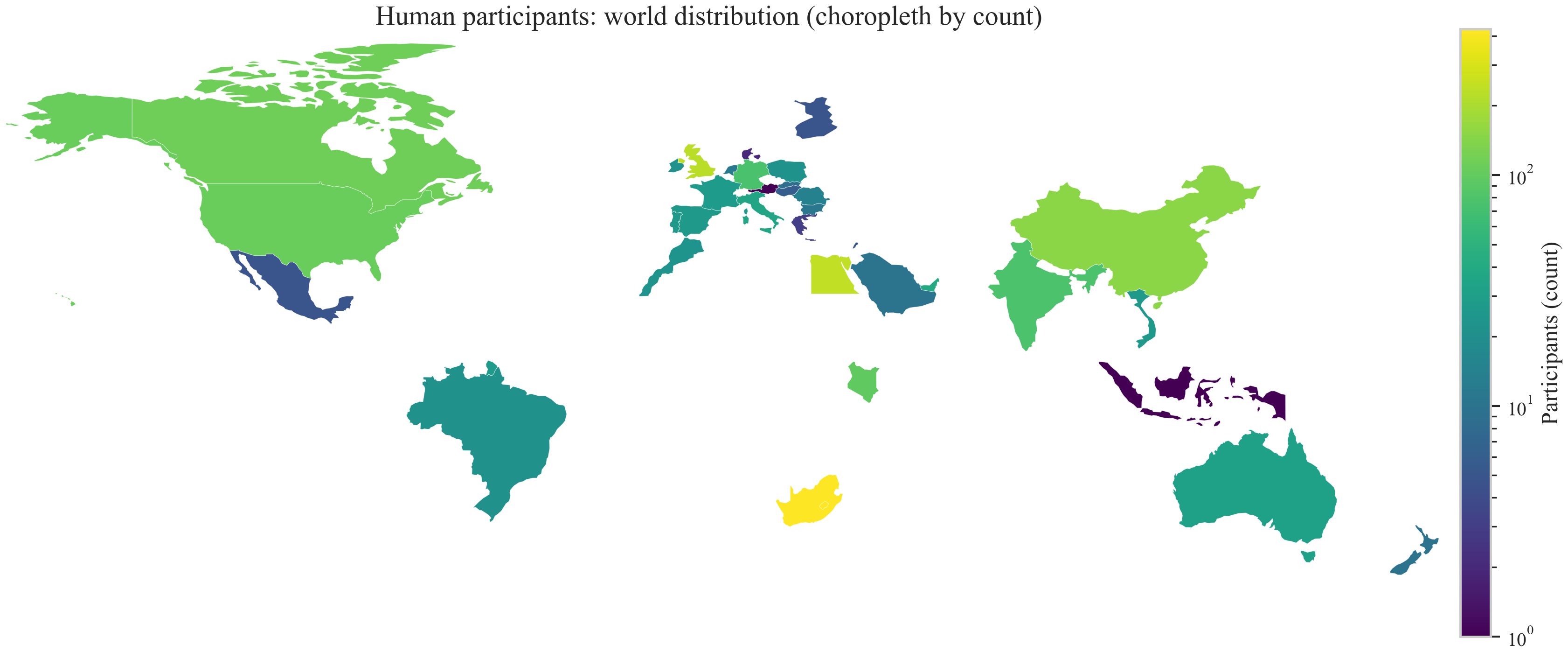
Figure 6: Geographic breakdown of the cleaned human response sample confirms breadth, reducing region-specific bias.
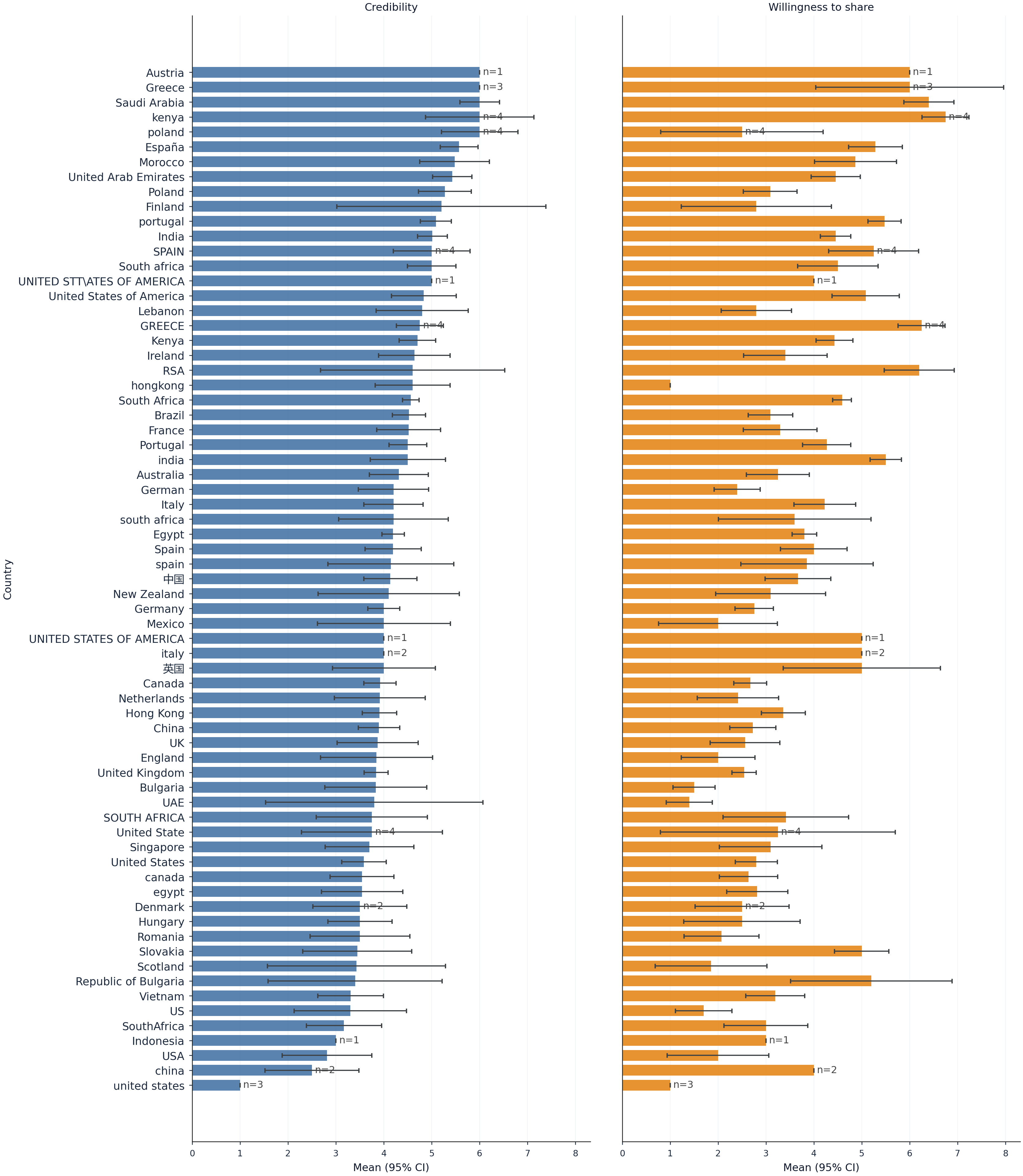
Figure 7: Country-level means indicate noisy but non-random divergence in outcomes, further supporting global applicability.
Fatigue analysis shows no monotonic decline across trial indices (Figure 8).
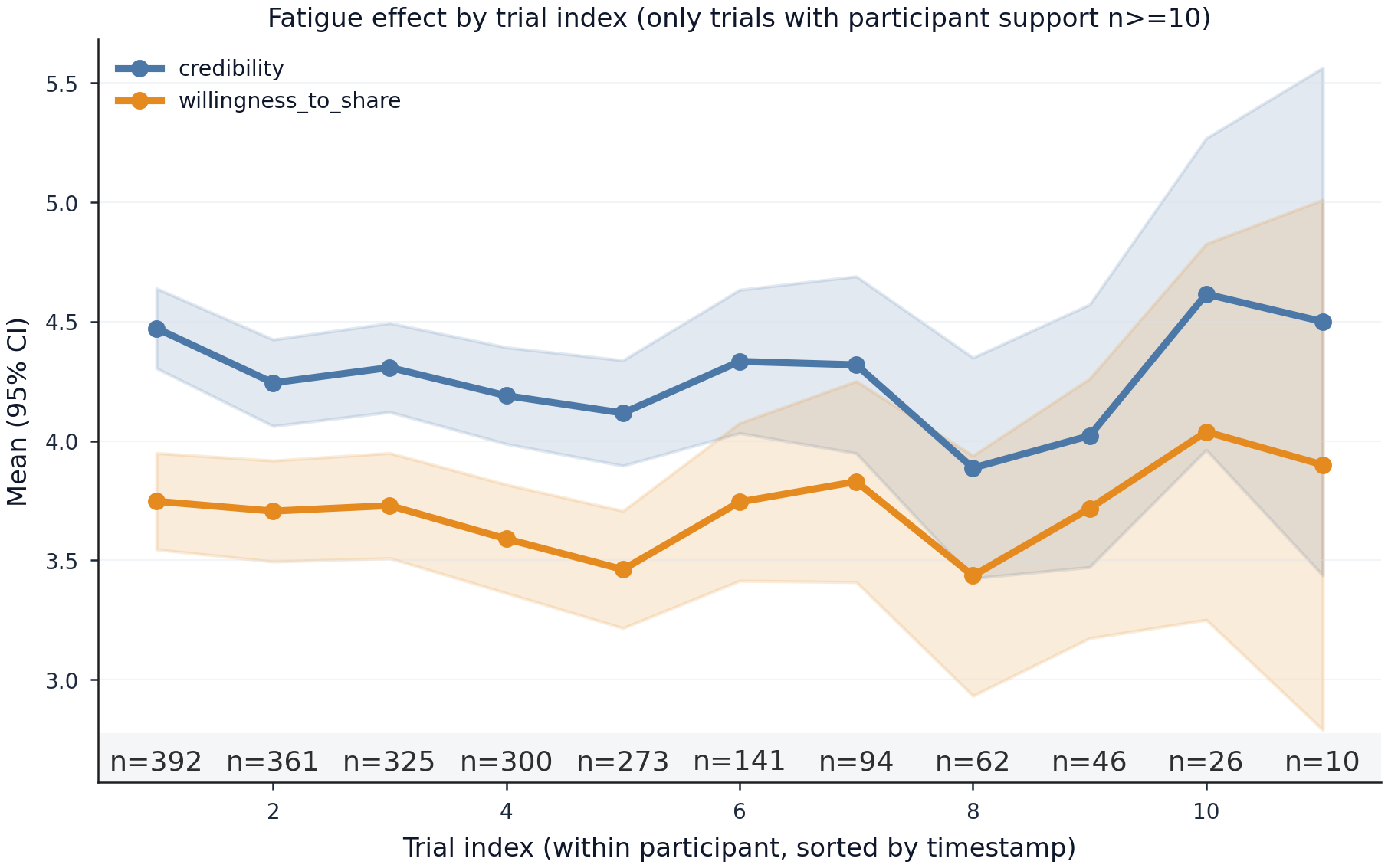
Figure 8: Mean human outcomes show stability across trials, indicating fatigue does not confound evaluation.
Implications for Safety and Methodology
The findings emphasize that LLM-based risk evaluation cannot be naively substituted for audience-facing assessments. Internal consistency among judges does not confer proxy validity for downstream risk when the outcome of interest is belief or sharing. There is a Goodhart-like risk: optimizing or benchmarking against judge scores may produce systems that excel at impressing other LLMs rather than persuading or dissuading real audiences, potentially leaving propagation risk unmitigated or distorted.
Practically, LLM judges can support preliminary monitoring and filtering, but must always be validated against human response benchmarks when the evaluation target is inherently subjective (credibility, sharing). Theoretical implications include the necessity for signal-aware calibration and targeted intervention when deploying judge-mediated filters in safety-critical contexts.
Future Directions
Further investigation is required into fine-grained scenario dependence, judge-side prompting and calibration methods, and more elaborate harnessing frameworks for potential improvements in human-faithfulness. Expanded global sampling and scenario stratification would clarify cross-cultural and demographic effects.
Conclusion
The paper demonstrates that frontier LLMs, when deployed as judges for evaluating LLM-generated disinformation, exhibit substantial gaps from actual human reader responses in calibration, item ranking, and mechanistic dependence on textual signals. Internal judge coherence is decisively stronger than judge–human alignment, invalidating surface-level agreement as evidence for proxy validity. Robust risk evaluation in audience-facing disinformation domains requires human-grounded audits and cannot rely solely on LLM judges as substitutes (2604.06820).