- The paper shows that disclosed source labels systematically bias trust judgments in both human evaluators and LLM judges.
- Methodologies, including counterfactual designs, eye-tracking, and attention analyses, reveal additive effects from true and disclosed source labels.
- Results highlight increased uncertainty for AI-generated labels and call for blind judging protocols in safety-critical health assessments.
Label Effects in Trust Judgment: Shared Heuristic Reliance in Humans and LLMs
Introduction
This work provides a rigorous empirical investigation into how disclosed source labels (i.e., "Human Authored" vs. "AI-Generated") bias trust judgments by both human evaluators and the increasingly prevalent LLM-as-a-Judge paradigm in health information assessment (2604.05593). The study leverages counterfactual experimental designs, eye tracking of human participants, and detailed mechanistic analyses of LLM internal states to systematically dissect judgment-level and mechanism-level alignment between humans and LLMs under provenance cue manipulations.
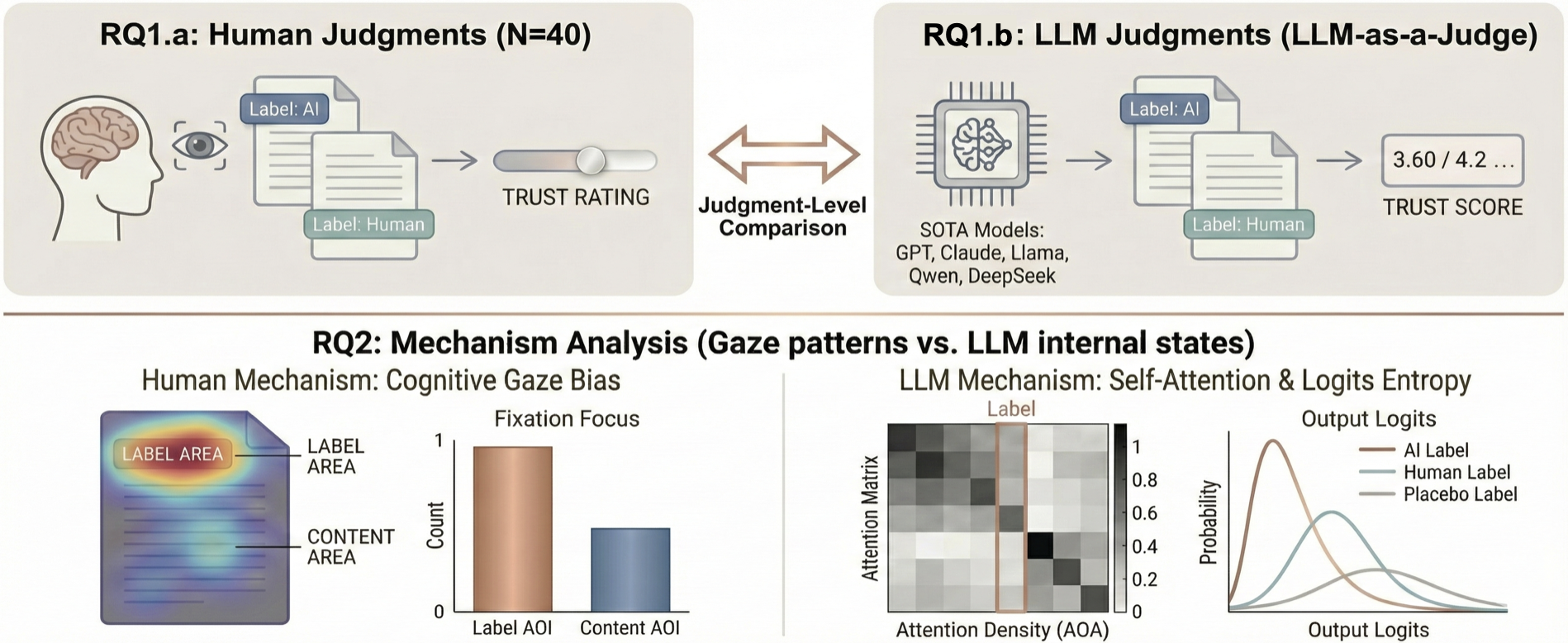
Figure 1: Three studies examine how source labels affect trust judgments by an LLM-as-a-judge and investigate the alignment with human behavior via mechanistic analyses of gaze attention, model self-attention, and logits entropy.
Methodological Framework
The experimental methodology incorporates a 2×2 counterfactual factorial design, manipulating both the true source of health advice (GPT-4o-generated or human professional) and the disclosed source label, with content presentations strictly controlled. Human participants (N=40, non-medical background), as well as a suite of leading proprietary and open-weight LLMs (e.g., GPT-5.2, Claude-Sonnet-4.5, LLaMA-3.2-70B, Qwen3-235B), performed trust ratings for each item on a multidimensional Likert scale.
Task instructions for LLMs mirrored those for human judges. Eye-tracking was employed to record human gaze allocation across defined Areas of Interest (AoI): Label AoI (for source label), Content AoI (for information text), and Rating AoI (for rating region).

Figure 2: An example heatmap of gaze points on stimuli during human assessment, delineating predefined AoIs for label, content, and rating.
Empirical Results: Judgment-Level Effects
Human Judges
Controlled label swaps yielded robust label effects in human ratings: for identical content, information labeled as "Human Authored" consistently attracted higher trust scores than the same text labeled as "AI-Generated" (ANOVA: p<.001, effect size =0.39). Notably, a secondary source effect emerged, where LLM-generated content was trusted more, on average, than human-authored content, regardless of labeling. These effects are additive and independently significant.
LLM-as-a-Judge
All tested LLMs mirrored the human label effect: holding content constant, LLMs assigned higher trust scores to items with "Human Authored" labels compared to "AI-Generated" labels (Wilcoxon signed-rank test: p<0.001 in most models). The effect persists even when controlling for true content origin, indicating that disclosed label provenance, not answer quality, governs trust attribution.
Mechanistic Analysis: Gaze, Attention, and Uncertainty
Human Visual Attention
Eye-tracking revealed label-contingent gaze patterns. Under "Human" labels, participants fixated more frequently and longer on the Label AoI; under "AI" labels, gaze shifted toward the Content AoI, indicating deeper scrutiny of content in the absence of an authority cue.
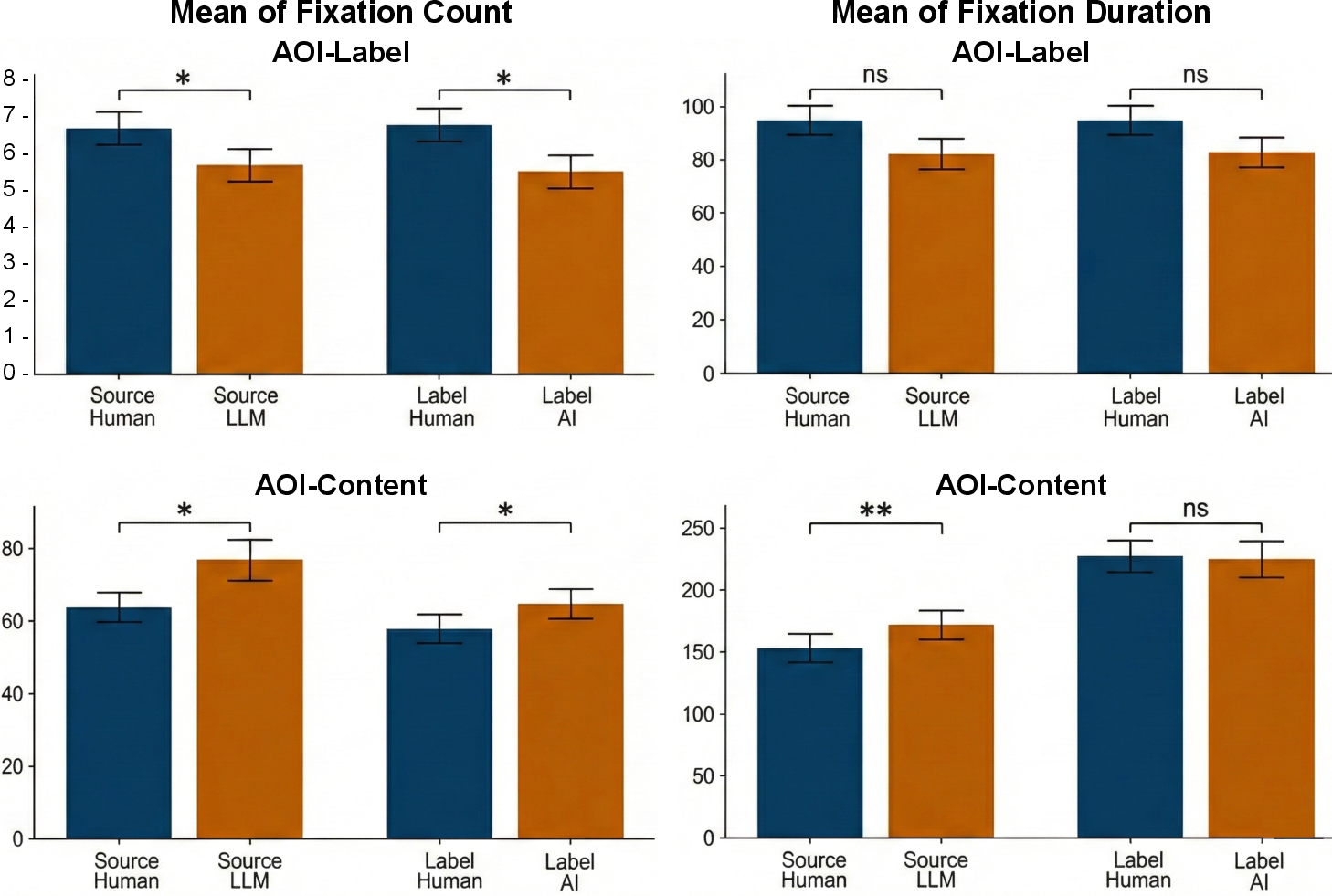
Figure 3: Analyses by GEE test of human gaze patterns (fixation count/duration) by label and content AoI.
LLM Attention Allocation
Mechanistically, LLMs' final-layer self-attention exhibited:
LLM Judgment Uncertainty
Inference uncertainty, assessed by logits entropy of model output distributions over trust ratings, was consistently higher for "AI-Generated" labeled content relative to "Human Authored," regardless of actual content origin. This indicates greater indecision/conflict when the provenance cue is AI.
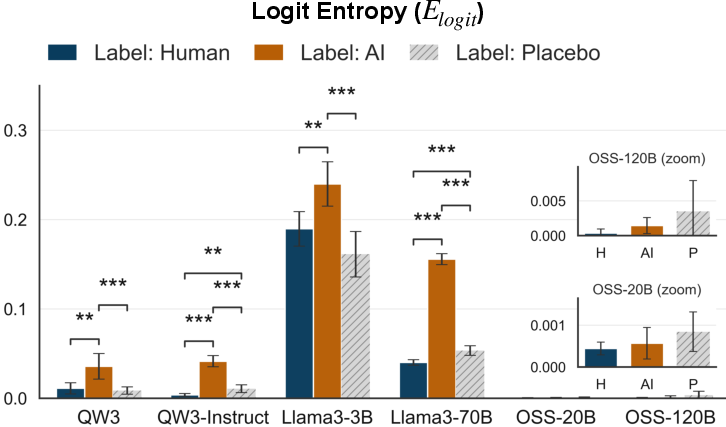
Figure 5: LLM's logit entropy between label versus content AoAs, stratified by label condition.
Placebo and Control Probes
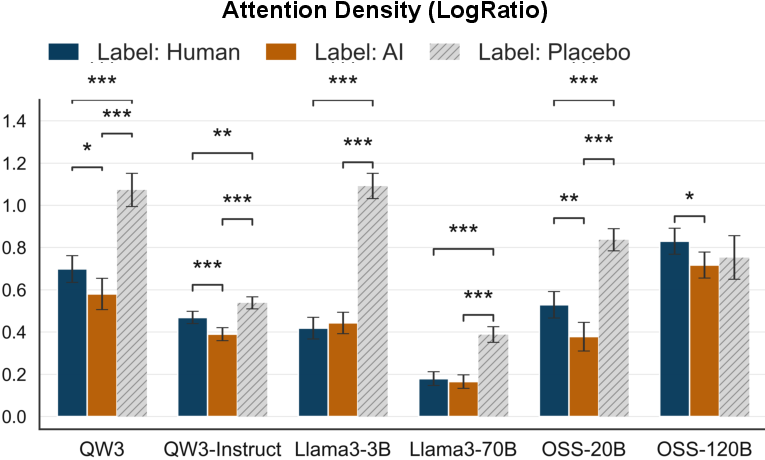
Introducing a semantically null "placebo" label [TAG] yielded the strongest label focus in LLM attention (but not in trust, aligning with placebo control literature), indicating that semantic content of the label, not merely the label’s presence or position, governs both attention allocation and trust calibration.
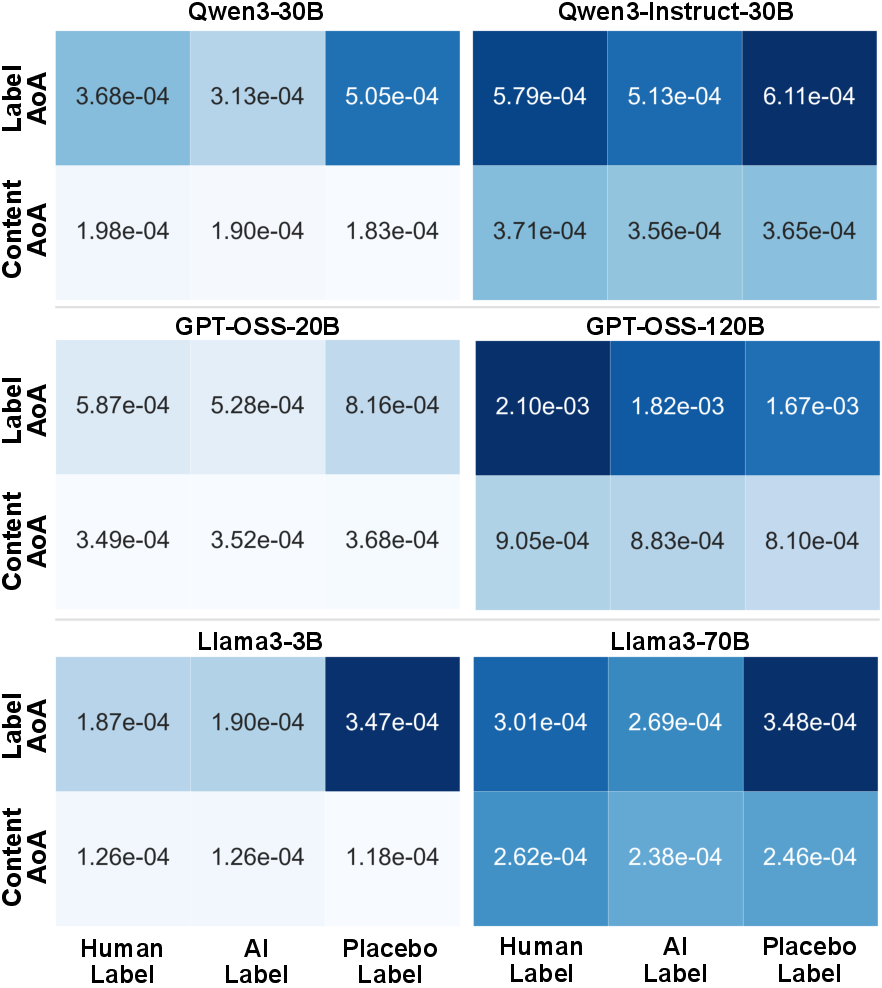
Figure 6: LLM attention distribution density across Label/Content AoAs and three label variants (Human, AI, Placebo) in multiple models.
Implications and Theoretical Impact
The study provides conclusive evidence that both humans and current-generation aligned LLMs employ source labeling as a dominant heuristic cue in trust assessment, overriding objective content evaluation:
- Alignment Risk: Preference-based alignment (e.g., RLHF) risks amplifying human heuristic reliance on provenance cues in models. This human-model heuristic synchronization exposes LLM judges to label spoofing attacks and diminishes their utility as impartial evaluators.
- Evaluation Validity: Reliable automated evaluation via LLMs in safety-critical domains (notably health) cannot be assumed unless provenance cues are carefully controlled or masked. Uncontrolled label artifacts can invalidate outcome interpretation.
- Cognitive-Computational Parallels: Eye-tracked human gaze and model self-attention are functionally aligned in cue exploitation, but dissociation emerges in the locus of uncertainty—humans scrutinize content more when labels lower trust, while LLMs’ attention remains label-focused but decision entropy increases for AI labels.
- Mitigation: The results call for blind or identity-debiased judging protocols—both in model training (preference curation, label masking) and in deployment (identity-controlled evaluation pipelines).
Limitations and Directions for Future Work
The study is domain-constrained (health QA), and future inquiry should extend to other settings and more granular provenance cues (e.g., expert review, mixed attribution, multiple placebo variants). Mechanistic analysis via token-level attention and logits entropy, while informative, is correlational rather than causally explanatory. Further research must deploy causal interventions (e.g., label ablation) and deeper representational probes.
Conclusion
This work establishes that source labels powerfully and systematically bias trust judgments both in humans and state-of-the-art LLMs, with underlying mechanistic convergence in cue processing. These findings challenge the validity of LLM-as-a-Judge in high-stakes evaluative contexts and highlight concrete risks of propagating human heuristic biases via alignment. For both practical deployment and theoretical understanding, future evaluation and alignment must rigorously address label and provenance effects to preserve analytic objectivity.