- The paper presents a sparse-aware framework that combines CNN-based sparse encoding with DNN decoding to mitigate exponential sample complexity in high dimensions.
- It leverages universal discretization techniques and arbitrary dictionaries to overcome the curse of dimensionality with explicit, dimension-insensitive error bounds.
- Results demonstrate efficient learning rates for Hölder-continuous functionals across various function spaces, showing only mild dependence on input dimension.
Sparse-Aware Neural Networks for Nonlinear Functionals: Mitigating Exponential Dependence on Dimension
Motivation and Background
The problem of approximating nonlinear functionals defined over infinite-dimensional function spaces is fundamental in operator learning, with applications ranging from inverse problems and PDEs to high-dimensional regression. Traditional neural operator learning frameworks often employ linear encoders, grid-valued sampling, or basis truncations, but suffer from slow convergence rates when the dimensionality of input grows, manifesting the curse of dimensionality even under favorable smoothness assumptions. Empirical evidence shows that deep neural networks (DNNs), especially convolutional neural networks (CNNs), achieve efficient operator learning, yet rigorous theoretical results explaining this phenomenon with explicit, dimension-insensitive rates have been lacking.
This paper introduces a sparse-aware neural network framework, leveraging sparse approximation theory and CNN encoders, to address functional learning in infinite-dimensional spaces. By exploiting sparsity in feature extraction, the authors derive theoretical guarantees demonstrating exponential improvement in sample complexity and convergence rates. The approach further accommodates arbitrary dictionaries, random sampling schemes, and broad function spaces, providing explicit bounds that reveal only mild dependence on input dimension.
Unified Functional Learning Framework
The proposed framework consists of a two-stage encoder–decoder architecture:
- Sparse CNN Encoder: CNNs are used to extract sparse feature representations from finite samples of input functions. Traditional linear methods are replaced by adaptive nonlinear encoding, closely aligned with sparse approximation paradigms.
- DNN Decoder: Fully connected deep networks process the finite-dimensional sparse codes to approximate target nonlinear functionals.
By combining universal discretization techniques with sparse dictionary representations, the approach achieves stability and approximation guarantees from finite random samples rather than requiring structured grid or cubature points.
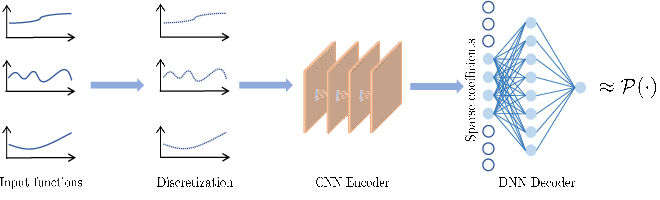
Figure 1: Functional learning pipeline proposed in Theorem~\ref{thm:holder}: sparse CNN encoding followed by deep DNN decoding enables efficient dimension-independent learning of nonlinear functionals.
Sparse Approximation via CNNs
Sparse coding theory establishes error bounds for CNN-based encoding: if fs is the CNN-based sparse approximator for f, the approximation satisfies
∥f−fs∥Lp(Ω,ν)≤c1e−c2J+c3σs(F,DN)L∞(Ω,ν),
where J is the number of CNN parameters and σs(F,DN)L∞(Ω,ν) is the sparse dictionary approximation error. With sufficient CNN complexity and under suitable dictionary coherence, sparse coding can be reliably recovered from random sampling, and supports high sparsity levels under low mutual coherence.
Sample Complexity: Deterministic and Random Sampling
Universal discretization requirements are satisfied both with deterministic construction and random sampling. For arbitrary dictionaries meeting mild boundedness and Riesz basis conditions (including orthogonal and wavelet bases), the sample size m required for s-sparse universal discretization scales as O(slogNlog3sloglogN) for deterministic sampling, and comparably for random sampling with high probability. The framework quantifies mutual coherence, admissible sparsity, and sample complexity, establishing substantial reductions compared to previous operator learning approaches.
Approximation Rates for Nonlinear Functionals
The paper considers Hölder-continuous nonlinear functionals and characterizes the learning rates using functional neural networks. The main result states that, for input functions of smoothness order α, the approximation error using networks with K nonzero parameters behaves as:
f0
for Hölder functionals whose modulus of continuity f1. Here, dimension f2 appears only in a secondary logarithmic term, and the dominant decay is exponential in log-parameters.
Explicit Rates in Function Spaces
- Rapid Frequency Decay: For functions with coefficients decaying as f3 under an orthogonal dictionary, the sparse approximation is of order f4, leading to the dimension-insensitive learning rate stated above.
- Sobolev Spaces with Mixed Smoothness: For f5 belonging to Wiener algebra class f6 with mixed derivatives, rates are similarly exponential in f7, with additional mild dependence on dimension through f8.
These results contrast sharply with classical operator learning bounds, which scale as f9 and deteriorate rapidly with increasing ∥f−fs∥Lp(Ω,ν)≤c1e−c2J+c3σs(F,DN)L∞(Ω,ν),0.
Numerical and Theoretical Implications
The theoretical guarantees provided are highly robust, covering a wide range of functional spaces and sampling regimes. The dimension-independence achieved through sparse-aware encoding and nonlinear dictionary selection sheds new light on the practical success of deep neural networks in operator learning, image processing, and PDE problems. The framework's flexibility in accommodating arbitrary dictionaries, finite random sampling, and practical architectures supports wide applicability in large-scale and high-dimensional settings.
Future Directions
The implications are substantial for both theory and application:
- Operator Learning Extension: The approach can be generalized to full operator learning and model reduction problems, bridging empirical performance and rigorous error bounds.
- Generalization Analysis: Future work may incorporate statistical learning theory to analyze generalization beyond approximation, including sample estimation error and model selection.
- Dictionary Learning and Adaptive Sampling: Data-driven or learned dictionaries can be explored, as well as adaptive sampling in complex domains such as manifolds or non-Euclidean settings.
Conclusion
This paper establishes a comprehensive sparse-aware neural network framework for nonlinear functional approximation in infinite-dimensional spaces, mitigating the exponential dependence on input dimension. The combination of universal discretization, random sampling, and sparsity-adaptive CNN encoding enables dimensionally robust learning rates, explicating the empirical efficiency of deep networks in operator learning and functional regression. The theoretical results open new avenues for scalable deep learning in high-dimensional scientific and engineering applications.

