- The paper proposes a novel vision-centric approach by embedding all modalities into a unified image space using flow matching.
- It employs a Dual-Path Spatially-Adaptive Modulation mechanism to balance semantic evolution and precise spatial edits.
- Benchmarking on VisPrompt-5M and VP-Bench shows improved pass rates and superior geometric accuracy over existing methods.
Unified Visual Flow Matching for Multimodal Generation: An Expert Analysis of FlowInOne
Motivation and Vision-Centric Paradigm
Multimodal generative pipelines have traditionally adopted text-driven conditioning—relying on linguistic embeddings to guide image synthesis via DDPMs, LDMs, DiTs, and related architectures. This approach introduces inherent cross-modal bottlenecks and restricts management of spatial control, physical reasoning, and compositional editing, since language dictates vision and not vice versa. FlowInOne (2604.06757) reformulates this paradigm by embedding all input modalities (text, layouts, spatial edits, instructions) into a unified visual representation, establishing an image-in, image-out pipeline exclusively governed within visual space.
This formulation leverages flow matching, whereby the generative process is modeled as deterministic velocity field evolution, enabling precise and efficient transition from input visual instructions to target images. Such vision-centric encapsulation naturally circumvents the critical alignment issues and task-specialized architectural complexity present in cross-modal systems.

Figure 1: VisPrompt-5M dataset covers a wide spectrum of image-to-image generation, including compositional editing and physics-aware instruction following.
Dataset Construction and Benchmarking
Central to FlowInOne is the VisPrompt-5M dataset—a multimodal corpus containing 5M visual prompt pairs spanning text-to-image, class-to-image, text-in-image editing, bounding box-guided insertion, marker-based edits, doodle-driven synthesis, force/trajectory modeling, and diverse spatial instruction following. All prompts are explicitly rendered into images (with randomization in style, placement, and format), unifying discrete modalities and geometric directives within pixel space.
VP-Bench, the curated benchmark, assesses instruction faithfulness, spatial precision, visual realism, and content consistency using VLMs and human experts. Key quantitative metrics include CLIP-IQA, CLIP Score, Directional CLIP Similarity, and DINOv3 Sim—enabling rigorous evaluation of semantic alignment and structural transformations, particularly in tasks requiring nontrivial spatial reasoning and physics-aware edits.
Flow Matching and Model Architecture
FlowInOne leverages the flow matching framework, optimizing a deterministic velocity field that continuously transports latent representations between visual instruction and target image in a shared latent space. The process eliminates noise scheduling, stochastic sampling, and modality-specific condition heads, providing both sampling efficiency and stable optimization.
A Dual-Path Spatially-Adaptive Modulation mechanism dynamically balances structural preservation and instruction adherence: for purely text-driven tasks, the structural branch is bypassed, focusing on semantic evolution; for image-editing, spatially-adaptive gating and cross-attention are activated, injecting source priors and modulating the denoising process at pixel granularity via learnable gating coefficients. This approach effectively manages semantic versus spatial dependencies, enabling fine-grained edits with strict geometric conformity.
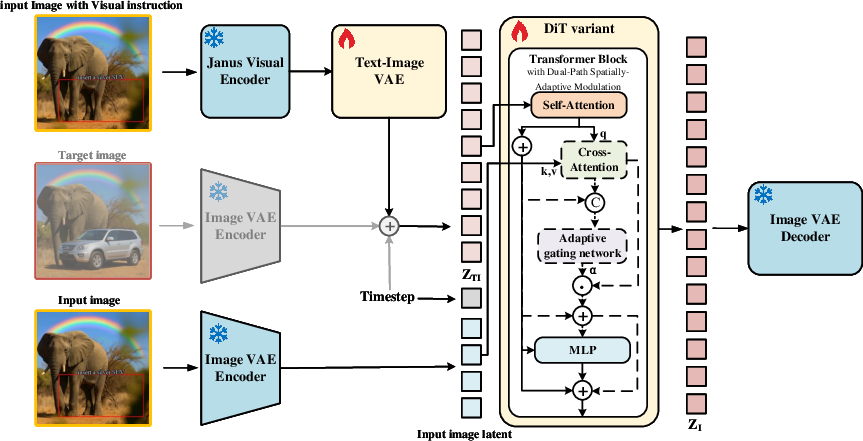
Figure 2: FlowInOne achieves continuous visual evolution within a single modality, modulating the path based on task type and input composition.
Numerical Results and Comparative Analysis
Extensive benchmarking on VP-Bench demonstrates FlowInOne's superiority across all unified generation tasks. Pass rates under GPT-5.2 (39.2%), Qwen3.5 (50.3%), and human evaluation (44.9%) substantially surpass competitive open-source (OmniGen2, FLUX.1-Kontext, Qwen-IE-2509) and commercial (Nano Banana) baselines. FlowInOne achieves the highest DINOv3 Sim (48.7%), outperforming commercial models in fine-grained spatial and physical tasks.
Qualitative assessment reveals FlowInOne's robustness in instruction decomposition, spatial marker reasoning, force/trajectory modeling, and local fusion. Competing systems frequently misinterpret visual markers, reconstruct instructions as scene elements, or disregard spatial constraints—particularly in bounding box and physics-aware reasoning. FlowInOne’s strict adherence to bounding box dimensions, marker-localized edits, and force-induced dynamics is consistently observed.
Notably, FlowInOne efficiently consolidates diverse tasks under one image-in, image-out interface, bypassing task-specific architectural branches and achieving strong generalization from semantic generation to spatial-geometric and physical transformations.
Ablation Studies and Architectural Insights
Ablation results validate critical design choices:
- Compression/mapping: Dual MLP projection preserves semantic and spatial structure.
- Modulation: Dual-Path SAM (Spatially-Adaptive Modulation) outperforms standard cross-attention, maximizing pass rates and fidelity via pixel-level adaptive gating.
- Training: Joint training across all task types enhances instruction enforcement and generalization compared to two-stage approaches.
These insights support the efficacy of FlowInOne’s unified processing: robust handling of spatial heterogeneity, semantic triggers, and strict geometric alignment.
Practical and Theoretical Implications
The fully visual flow matching paradigm has substantial implications:
- Practical: Streamlined deployment for multimodal generative workflows, with a single model executing text-driven synthesis, spatially-constrained edits, and physics-aware generation. Eliminates architectural complexity of task-specific heads, text encoders, and cross-modal alignment modules.
- Theoretical: Establishes deterministic, continuous transport as a universal principle for generative modeling, closing modality gaps and bridging perception-generation under a shared representation. Advances vision-centric learning and opens paths for robust instruction-following agents capable of adaptive editing, synthetic data generation, and compositional reasoning.
Future Prospects
Scalable expansion to higher resolutions, larger model capacities, and multi-turn interactive workflow will further extend the paradigm. Integration with real-time visual reasoning, reinforcement learning, and interactive visual agents is anticipated. Continuous evolution via flow matching is likely to become a foundational component in unified vision-language systems, fostering genuine multimodal cognition.
Conclusion
FlowInOne introduces a coherent, vision-centric framework for multimodal generative modeling, demonstrating state-of-the-art results across a spectrum of unified tasks. By encapsulating all instructions within the visual domain and leveraging flow matching for deterministic evolution, the model achieves precise, efficient, and versatile image synthesis and editing. The approach fundamentally redefines perceptual and generative boundaries, addressing longstanding modality and alignment bottlenecks, and establishes a scalable foundation for future multimodal AI systems (2604.06757).