NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Abstract: We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation”
Overview
This paper introduces NextFlow, a single AI model that can both understand and create text and images. It does this quickly and at high quality, using a new way to build images from rough shapes to fine details. The goal is to combine the “smart thinking” of LLMs with the “high-quality visuals” of image generators, all inside one simple system.
What questions did the researchers ask?
They focused on a few big questions:
- Can one model understand and generate across different types of data (like text, images, and even image sequences) without needing separate systems?
- Can we make image generation fast at high resolution (like 1024×1024) using an autoregressive model, which usually is slow for images?
- Can we represent images in a way that captures both meaning (what’s in the image) and detail (how it looks) so the model can reason and generate well?
- How can we train this kind of model stably and align it with what users want?
How did they do it?
One model for everything
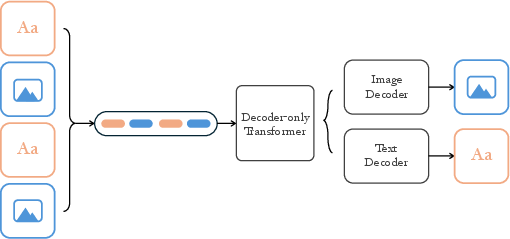
NextFlow uses one “decoder-only Transformer” (think: a single brain) that reads a sequence made of both words and image “tokens.” Tokens are like tiny pieces: for text, they’re word parts; for images, they’re code-like tiles that stand for parts of the picture. The model takes a mixed stream of these tokens and learns to predict what comes next.
A new way to draw pictures: next-scale prediction
Most text models generate one token after another. That works for text, but for images it’s slow, because big images have tons of tokens. NextFlow changes the game by predicting images “scale by scale” instead of “pixel by pixel.” Imagine an artist:
- First, sketch the rough layout (large shapes).
- Then add medium-level structure.
- Finally, add small details.
This “coarse-to-fine” process (called next-scale prediction) makes generation much faster and more stable. With it, NextFlow can make a 1024×1024 image in about 5 seconds—much faster than older autoregressive methods.
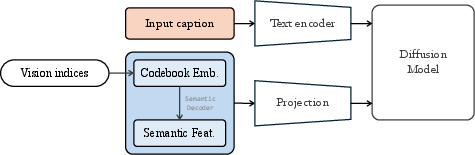
Better building blocks for images: a dual-codebook tokenizer
To turn images into tokens, NextFlow uses two kinds of codebooks:
- A “semantic” codebook for meaning (what objects are there: dog, tree, face).
- A “pixel” codebook for look and texture (colors, edges, fine detail).
Think of it like having both a clean outline (meaning) and a high-quality paint job (details). This helps the model both understand images (good for reasoning) and generate sharp pictures (good for quality).
Training strategy and tricks
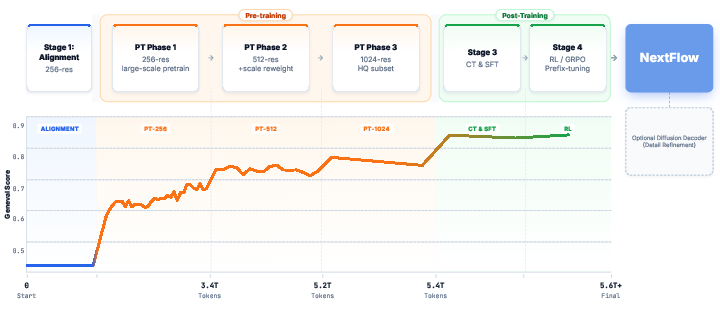
The team trained the model on about 6 trillion tokens across text, image–text pairs, interleaved content (like text-image-text), and even video-like sequences (frames treated as images). They used a step-by-step resolution schedule: first 256, then 512, then 1024. Along the way, they solved several problems:
- Scale reweighting: Early “coarse” scales are few tokens but super important for layout. Without care, the model ignores them. They increased the training weight of these early steps so the model learns strong structure.
- Self-correction: During training, they intentionally introduced small “mistakes” in earlier steps so the model learns to fix them later. This reduces errors that would otherwise grow over time.
- Position hints: They gave the model better “position labels” for where each image patch is and at what scale, so it can handle different resolutions more reliably.
- Continued training and SFT: After pretraining, they fine-tuned on higher-quality data and then on conversational data to improve instruction following and aesthetics.
- Reinforcement learning with prefix-tuning: They used a reward-based method to improve results, but only updated the early (coarse) steps—the ones that most affect the overall look. This makes the process stable and efficient.
Optional “detail polisher”
There’s an optional diffusion-based decoder you can plug in at the end to add super-fine details (like tiny text or faces). It boosts realism but can slightly change tiny structures, so it’s best for cases where you want maximum photographic detail.
What did they find and why is it important?
Here are the most important results:
- Speed: NextFlow makes 1024×1024 images in about 5 seconds and uses around 6× fewer operations than some popular diffusion-based systems at that size. That’s fast enough for interactive use.
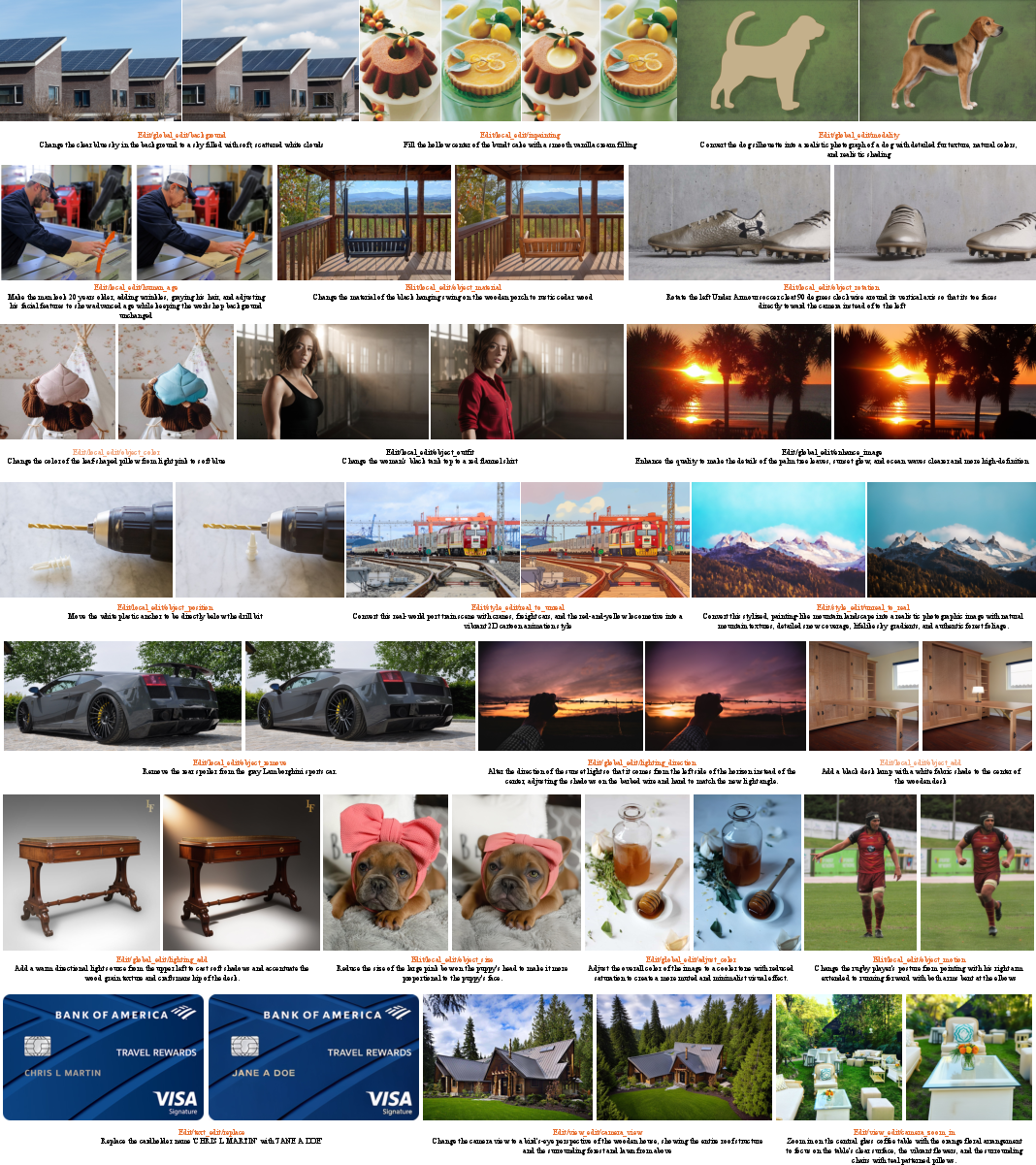
- Quality: A 7B-parameter NextFlow model matches or rivals strong diffusion models in visual quality and beats specialized models on image editing tasks.
- Unified abilities: Because it uses one model and one representation, it naturally handles:
- Text-to-image generation
- Image understanding and reasoning
- Image editing (local and global changes)
- Interleaved generation (mixing text and images in a single output)
- Even video-like sequences (by treating frames as images)
- Smarter training choices matter:
- The “shared head” (one output layer for both text and image tokens) worked better than separate heads.
- Mixing some text-only data did not hurt image generation.
- Self-correction worked best when paired with “residual” features (a cleaner input setup).
- Scale reweighting fixed structural artifacts at higher resolutions.
What could this change?
- Simpler systems: One model that can read, reason, and create across text and images reduces the need for clunky pipelines that glue multiple models together.
- Better user experiences: Faster, high-quality image generation means you can chat with a model that draws what you ask for in seconds, edits your photos with natural instructions, or produces illustrated stories and step-by-step visual guides.
- Stronger multimodal reasoning: Because the image tokens carry meaning, the model can better connect text and visuals, enabling smarter instruction following and more accurate edits.
- A practical path forward: The paper shows that autoregressive models—traditionally great at language—can be rethought to also be fast and excellent at images, opening a route to truly general, multimodal AI.
In short, NextFlow shows that a single, unified model can think in words, see in images, and create both—quickly and at high quality—by building pictures the way humans do: from the big idea to the tiny details.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues, uncertainties, and missing analyses that future work could address:
- Quantified speed claims lack context: “5s per 1024×1024 image” is not tied to specific hardware, batch size, precision, sampling settings, or baseline implementations for a fair wall-clock comparison.
- Inference memory and throughput trade-offs (with vs. without the diffusion decoder) are not reported across resolutions, batch sizes, and contexts (e.g., interleaved, multi-image conditioning).
- The paper claims interleaved content and video generation, but provides no quantitative evaluation, benchmarks, or baselines for interleaved image-text or video tasks (e.g., temporal coherence metrics, audio-visual alignment, narrative consistency).
- Video modeling is underspecified: it’s unclear how next-scale prediction extends to the temporal axis (e.g., next-time vs. next-scale scheduling, 3D spatiotemporal tokenization, temporal positional encoding) or how motion consistency is enforced/assessed.
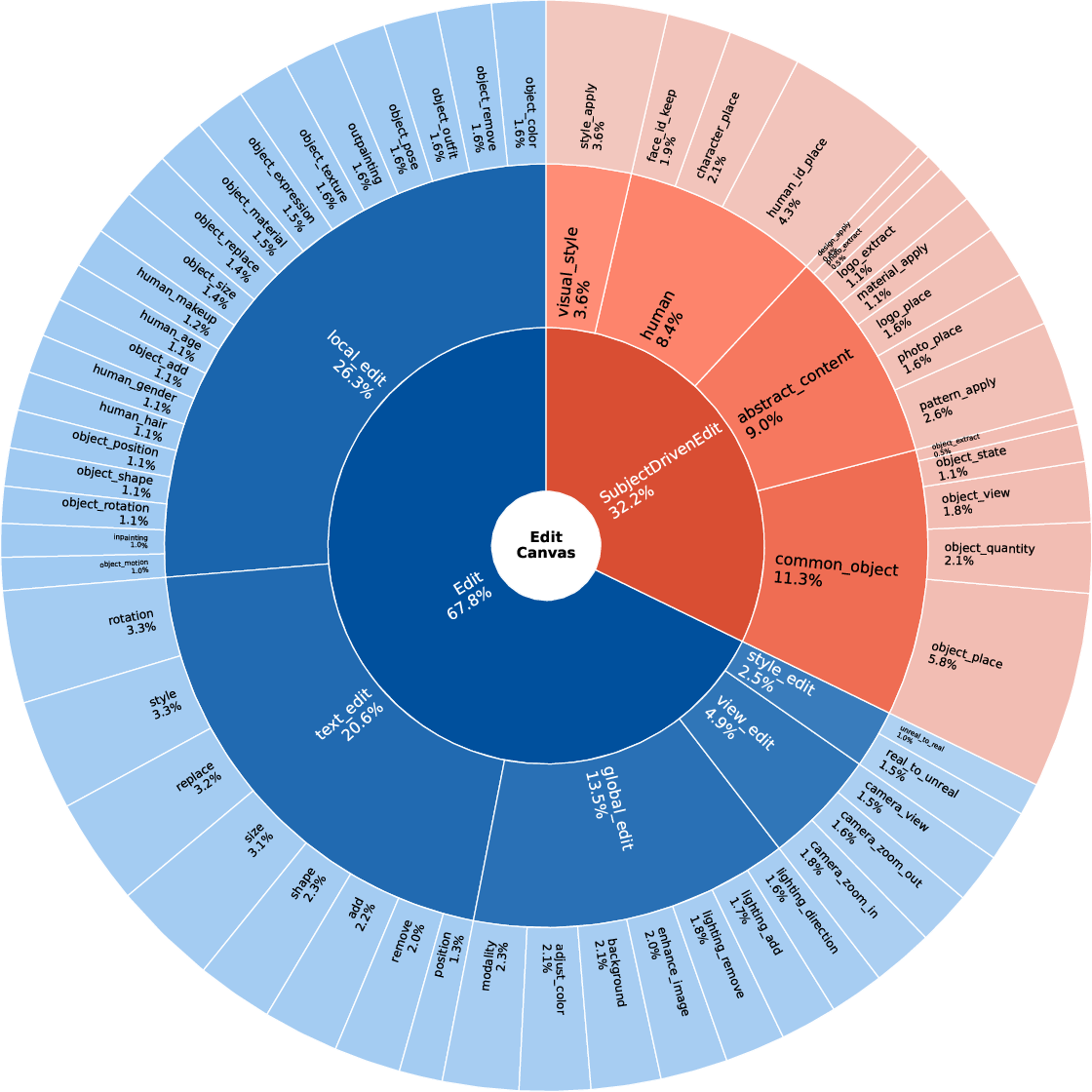
- Editing evaluation is narrow: beyond EditCanvas, there is no comprehensive quantitative study on local vs. global edits, mask-guided edits, identity preservation, or viewpoint changes with standard metrics (LPIPS, ID similarity, sFID, TEdBench).
- Optional diffusion decoder effects are under-characterized: the extent to which refinement changes layout consistency, text legibility, identity, and prompt adherence isn’t quantified; no controls (e.g., guidance scales, classifier-free guidance schedules) are explored to preserve structure.
- Tokenizer design details are incomplete: codebook sizes per scale, stride/downsampling schedule, and the loss weighting between semantic and pixel branches are not fully specified; ablations on these choices are missing.
- The impact of the semantic–pixel loss balancing coefficient(s) on understanding vs. generation quality is not studied; guidelines for setting these weights are absent.
- Multi-scale schedule (number of scales, resolutions per scale) is deferred to an appendix but not presented; how schedule choices affect quality, speed, and stability remains unclear.
- 3D multiscale RoPE constants (range factor C, offset choices) and alternative positional encodings are not ablated; robustness to extreme aspect ratios and unseen resolutions isn’t quantified.
- Scale reweighting (α in k_s = 1/(h_s·w_s)α) is only validated at α=0.9; sensitivity analyses (different α, curriculum over α, adaptive/tokens-per-scale-normalized losses) are missing.
- Within-scale independence assumption persists: tokens per scale are sampled independently, which may limit local coherence; alternatives (2D AR orders, local 2D attention coupling, masked modeling, blockwise generation) are not explored.
- Self-correction design is partially ad hoc: exact top-k, sampling distributions, and per-scale probabilities are not fully specified for the main model; comparisons to alternative exposure-bias mitigations (scheduled sampling, professor forcing, diffusion-style denoising targets) are absent.
- Offline pre-extraction of image indices improves throughput but limits on-the-fly data augmentation/self-correction schedules; impacts on flexibility, storage footprint, and reproducibility aren’t evaluated.
- RL setup lacks critical specifics: reward function composition (aesthetics, prompt adherence, safety/NSFW, OCR legibility), group size G, clipping ε, KL β, reference policy construction, and sample efficiency are not reported.
- No ablation on RL “prefix-tuning”: how many scales to optimize (m), interactions with scale reweighting, and stability across reward mixtures remain untested; downstream gains (vs. SFT-only) are not quantified.
- Safety alignment is not described: content filters, NSFW policies, harmful image mitigation, watermarking, and memorization checks (PII leakage, face/person re-identification) are not evaluated.
- Data provenance, licensing, and compliance are unspecified; deduplication and benchmark contamination checks (near-duplicates, overlap with evaluation sets) are not reported.
- Text-only data mixing is only tested at 25% on a small scale; a systematic study of text/multimodal mixing ratios on both language and vision performance at full scale is missing.
- Scaling behavior is unknown: performance vs. model size (e.g., 1B–70B), data size, and inference compute scaling laws are not provided; trade-offs between model size and next-scale latency remain unquantified.
- Resolution generalization beyond 1024×1024 (e.g., 2K–4K) and to extreme aspect ratios is untested; failure modes and computational budgets for higher resolutions are not documented.
- Long-context and multi-image conditioning limits (context length, memory/latency profiles, degradation with many interleaved items) are not measured; strategies for memory-efficient context handling are absent.
- OCR and embedded text generation capabilities are not rigorously evaluated (e.g., TextOCR, ST-VQA, word accuracy); the effect of the diffusion decoder on text fidelity and legibility is not measured.
- Unified-head vs. dual-head conclusion is drawn from a small alignment/SFT setting; full-scale comparisons (including catastrophic interference, modality imbalance, and learning dynamics) are missing.
- Cross-modal reasoning benchmarks (e.g., MMMU, MMBench, TextCaps, ScienceQA, Chart/DocVQA) are not reported; benefits of the dual-codebook tokenizer for understanding tasks remain largely anecdotal.
- Training vs. inference compute comparisons to leading diffusion models are high-level; matched TFLOP/s budgets, throughput per dollar/watt, and end-to-end latency breakdowns (tokenization, AR decoding, VQ decode, diffusion refine) are not provided.
- Robustness to noisy captions, conflicting instructions, and adversarial prompts is unexamined; mitigation strategies (self-correction schedules, RL constraints) are not evaluated.
- Diversity and mode coverage are not measured (e.g., multi-prompt mFID, intra-prompt diversity, perceptual uniqueness metrics); risk of mode collapse at higher resolutions is not assessed.
- Reproducibility is limited: many key hyperparameters (tokenizer configuration, 3D RoPE constants, α schedules, self-correction k/p, RL settings) and training scripts are not fully disclosed; appendix references are incomplete.
- Edit localization interfaces (mask-guided vs. text-only) and their comparative effectiveness/latency are not examined; benchmarks requiring precise spatial control (e.g., InstructPix2Pix-local, HQ-edit) are missing.
- Integration with 3D/geometry or layout conditioning (depth, normal, segmentation, bounding boxes) is not explored; how next-scale AR interacts with structured controls remains unknown.
- Failure analyses are sparse: no systematic categorization of artifacts (structural drift across scales, tiling, texture repetition), nor diagnostics linking them to specific scales or sampling hyperparameters.
- Multilingual capabilities are not assessed; data language distribution, cross-lingual prompt adherence, and multilingual OCR performance are unreported.
- Uncertainty calibration and confidence estimation for generation/editing (e.g., detect unlikely prompts or out-of-distribution conditions) are not discussed; fallback strategies are absent.
- End-to-end joint training of the optional diffusion decoder with the AR model (to preserve structure via losses or constraints) is not attempted; distillation of refinement back into the AR model remains an open direction.
- Controllable randomness in the diffusion decoder (seed determinism vs. identity/layout preservation), as well as conditioning strength schedules to balance fidelity vs. adherence, are not investigated.
Practical Applications
Immediate Applications
Below are applications that can be deployed now with NextFlow’s current capabilities and supporting tools described in the paper.
- Industry (Creative/Marketing/Media): High-resolution, fast text-to-image generation for ad assets, social posts, and campaign ideation
- Tools/Products/Workflows: “NextFlow Studio” plugin for Adobe/Figma; workflow combining Chain-of-Thought prompt refinement, next-scale generation, and optional diffusion decoder for detail polishing
- Assumptions/Dependencies: Access to 7B model weights/API; GPU resources for ~5s 1024×1024 generation; brand/style reward model if using RL prefix-tuning
- E-commerce: Subject-driven editing for catalog updates (background removal, colorway changes, identity-preserving product photos)
- Tools/Products/Workflows: “Catalog Editor” service integrating local/global edits and subject-driven generation; disable optional diffusion decoder when strict spatial consistency is required
- Assumptions/Dependencies: Product identity datasets and reward models; controls to prevent undesired changes to product geometry
- Software (Design/UX): Rapid UI mockups, icon sets, and asset generation with textual specifications
- Tools/Products/Workflows: “Design Copilot” for sprint planning; prompt refinement via CoT; visual edits for variant testing
- Assumptions/Dependencies: Domain-tuned reward models for UI aesthetics and accessibility; training data covering design conventions
- Media/Entertainment: Storyboarding from brief text into interleaved frames plus caption drafts
- Tools/Products/Workflows: “Storyboarder” pipeline leveraging interleaved generation; export sequences to animation suites
- Assumptions/Dependencies: Limited temporal coherence out of the box; quality depends on video-length and domain examples
- Education: Instructional illustrations and step-by-step diagrams; multimodal lesson pages (interleaved text and images)
- Tools/Products/Workflows: “Lesson Builder” assistant for teachers; OCR-aware chart/table generation and captioning
- Assumptions/Dependencies: Factuality guardrails; curated reward models for pedagogy; human review for accuracy
- Enterprise Documentation/Knowledge: Visual summaries of reports (charts, tables, plot descriptions), alt-text generation, image-captioning
- Tools/Products/Workflows: “DocVision Assist” workflow using the tokenizer’s semantically rich codebooks for chart/table understanding
- Assumptions/Dependencies: Domain-specific tuning for accuracy; compliance review; data governance for sensitive content
- Social Media/Daily Life: Personal photo edits (object add/remove, style changes), holiday card creation, blog post illustration
- Tools/Products/Workflows: Consumer photo apps using next-scale generation for speed; optional diffusion decoder for photorealistic details
- Assumptions/Dependencies: On-device or cloud GPU; safe content filters; UI for local vs. global edit selection
- Content Safety and Brand Governance: Enforce style or policy via RL prefix-tuning focused on coarse scales (global layout and semantics)
- Tools/Products/Workflows: “Brand Tuner” and “Safety Filters” that apply GRPO prefix-tuning to layout and high-level content decisions
- Assumptions/Dependencies: Robust, well-calibrated reward models (brand aesthetics, inappropriate content); rigorous evaluation; human-in-the-loop
- Cost-Efficient Cloud Inference: Lower serving cost with ~6× fewer FLOPs than MMDiT-based diffusion at 1024² and kernel fusions for throughput
- Tools/Products/Workflows: “Gen API” serving stack using fixed-computation-budget packing, fused kernels (RoPE/RMSNorm/Flash-Attn), and offline index pre-extraction
- Assumptions/Dependencies: Optimized CUDA kernels; workload balancing; accurate latency/SLA estimates based on deployment hardware
- Image Editing Suites (Pro/Prosumer): Production-grade local/global edits and identity-preserving subject-driven transformations
- Tools/Products/Workflows: “EditCanvas” integration; in-context learning for zero-shot edits; coarse-scale reweighting for robust layouts
- Assumptions/Dependencies: Careful use of optional diffusion decoder (may alter fine structure); datasets/rewards for identity and layout fidelity
- Synthetic Data Generation (Industry/Academia): Balanced, high-quality image-text pairs for training other models (UI, OCR, recognition)
- Tools/Products/Workflows: Use NextFlow to create diverse datasets with topic balancing; capture interleaved sequences for temporal/narrative tasks
- Assumptions/Dependencies: Licensing/IP compliance; quality filtering (aesthetic/motion); domain shift monitoring
- Research/Engineering (Modeling Methods): Apply dual-codebook tokenizer and next-scale AR to new domains; stabilize RL training via prefix-tuning
- Tools/Products/Workflows: Adoption of multi-scale 3D RoPE, scale reweighting, residual feature self-correction, and GRPO prefix-tuning
- Assumptions/Dependencies: Availability of domain-appropriate semantic teachers; compute to retrain tokenizers/models at target resolutions
Long-Term Applications
These applications are promising but require additional research, scaling, domain adaptation, or regulatory clearance.
- Unified Multimodal Agent Platforms (Software/Robotics/Education): Agents that perceive, reason, and generate across text, images, and interleaved sequences for planning, tutoring, and creative tasks
- Tools/Products/Workflows: “Multi-Agent Studio” integrating CoT reasoning with next-scale generation and editing; tool-use orchestration
- Assumptions/Dependencies: More reliable factuality; tool integrations; robust safety/ethics frameworks
- Robotics (Simulation and Perception): Synthetic environment generation for sim2real training; multimodal perception paired with instruction-following visual planning
- Tools/Products/Workflows: “Sim-to-Real Data Engine” producing scene variations and task visuals
- Assumptions/Dependencies: Robotics-specific datasets; tight evaluation of safety; temporal consistency and physics realism
- Healthcare (Medical Imaging/Patient Education): Assistive image augmentation, anonymization, and educational visuals for care communication
- Tools/Products/Workflows: “MedGen Assist” for non-diagnostic content; synthetic data for model training
- Assumptions/Dependencies: Regulatory approval; training on medical-domain data; strict identity preservation; bias and safety audits
- Real-Time Video Generation (Media/Streaming): Longer, coherent video sequences with consistent subjects and scenes
- Tools/Products/Workflows: “VideoFlow” pipeline scaling interleaved generation; temporal reward models for coherence
- Assumptions/Dependencies: Advances in temporal modeling and rewards; higher throughput hardware; dataset expansion beyond short clips
- Virtual Try-On and Product Personalization (Retail/Fashion): Identity-preserving subject-driven generation across poses, contexts, and lighting
- Tools/Products/Workflows: “Try-On Studio” with 2D-to-3D-aware consistency and multi-view generation
- Assumptions/Dependencies: Multi-view/3D conditioning; privacy and consent management; robust identity controls
- Digital Twins and AEC (Architecture/Engineering/Construction): Generative plan visualization, interior layouts, and constraint-aware design exploration
- Tools/Products/Workflows: “PlanFlow” that converts specifications into visual layouts and iterations
- Assumptions/Dependencies: Integration with CAD/BIM; domain constraints (codes, measurements); precise geometry retention
- Scientific Communication (Academia/R&D): Automatic figure and diagram generation from text (methods/results), with accurate captions and visual reasoning
- Tools/Products/Workflows: “SciViz Composer” fine-tuned on technical domains
- Assumptions/Dependencies: Domain-specific training; strict factuality and provenance; peer-reviewable outputs
- Finance/Enterprise Reporting: Compliant, data-driven reports with charts, interleaved narratives, and visual explanations
- Tools/Products/Workflows: “Report Composer” respecting regulatory language and brand styles via RL alignment
- Assumptions/Dependencies: Secure data connectors; auditability; robust accuracy guarantees; human oversight
- On-Device Multimodal Creativity (Mobile/Edge): Offline generation/editing with compressed models and fused kernels
- Tools/Products/Workflows: “EdgeFlow” leveraging kernel fusion and model distillation/quantization
- Assumptions/Dependencies: Model compression without quality loss; memory and battery constraints; secure on-device inference
- Provenance/Watermarking (Policy/Trust & Safety): Content provenance and watermarking integrated into the generation stack for governance
- Tools/Products/Workflows: Tokenizer/decoder-level watermarking and verifiable metadata pipelines
- Assumptions/Dependencies: Standardized policies; interoperable verification; minimal impact on image quality
- Multimodal Search and Retrieval (Software/Search): Interleaved reasoning over multiple images/documents to answer complex queries
- Tools/Products/Workflows: “Search Assistant” combining retrieval with NextFlow generation and explanations
- Assumptions/Dependencies: Scalable retrieval backends; evaluation of hallucination risks; domain-tuned rewards
- Internationalization/Localization (Global Media/Education): Culturally appropriate visuals and narratives aligned with local norms via RL rewards
- Tools/Products/Workflows: Locale-specific reward models for imagery and text co-generation
- Assumptions/Dependencies: High-quality, representative datasets; fairness assessments; regional compliance
- Personalized Tutors (Education): Interactive, multimodal lessons and micro-videos tailored to learner profiles and curricula
- Tools/Products/Workflows: “TutorFlow” with pedagogic rewards and analytics
- Assumptions/Dependencies: Curriculum integration; privacy & data protection; robust safeguards against misinformation
- Emergency/Public Policy Communication: Rapid generation of visual advisories and public information materials
- Tools/Products/Workflows: “CivicViz” with crisis-specific templates and multilingual interleaved content
- Assumptions/Dependencies: Verified data sources; human validation; accessibility standards; clear provenance markers
These applications build directly on NextFlow’s innovations: a unified AR transformer, next-scale visual generation for speed, dual-codebook tokenization for rich semantics, robust training (scale reweighting, residual feature self-correction), and stable RL prefix-tuning for coarse-scale alignment, with an optional diffusion decoder when photorealistic detail is paramount.
Glossary
- Advantage (RL): A scalar estimate of how much better an action performed than the group average in reinforcement learning, used to weight policy updates. "Within each group, the advantage can be calculated by:"
- AGI: The goal of building systems that can perceive, reason, and create across diverse modalities at human-like breadth and depth. "The pursuit of artificial general intelligence (AGI) has long envisioned a unified system capable of perceiving, reasoning, and creating across diverse modalities."
- AR‑Diffusion hybrid architecture: A unified modeling approach combining autoregressive and diffusion components for understanding and generation. "Recently, AR-Diffusion hybrid architecture including Transfusion and Bagel demonstrated promising results for unified understanding and generation."
- Arithmetic intensity: The ratio of computation to memory access; higher intensity can improve GPU efficiency. "These fused kernels store intermediate results in registers or shared memory, significantly improving arithmetic intensity."
- Autoregressive transformer: A model that generates sequences by predicting the next element conditioned on previous ones. "We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens."
- Bidirectional alignment: Training tasks that map in both directions between modalities (e.g., image captioning and text-to-image). "We used 10 million image-text pairs for bidirectional alignment tasks (image captioning and text-to-image generation) during this phase."
- Chain‑of‑Thought (CoT): A reasoning technique where models generate intermediate steps to improve accuracy and adherence. "NextFlow can perform Chain-of-Thought (CoT) reasoning to refine prompts before generation"
- Codebook: A finite set of discrete vectors used to quantize continuous features into token indices. "The model is trained with cross-entropy loss to predict codebook indices across both modalities."
- Cross‑entropy loss: A standard classification loss used to train the model to predict token indices. "Losses are computed using cross-entropy loss."
- Continued Training (CT): A post‑training phase on curated data to refine aesthetics and adherence after large-scale pretraining. "First, we conduct continued training (CT) on a curated subset of high-quality data to improve the aesthetic quality of the generated images."
- Curriculum (progressive resolution curriculum): A staged training schedule that gradually increases image resolution to stabilize learning. "We adopt a progressive resolution curriculum across three sub-stages: 256-level, 512-level, and 1024-level pre-training."
- Decoder‑only Transformer: A Transformer architecture that uses only the decoder stack for autoregressive generation. "Our autoregressive framework builds upon a standard decoder-only Transformer architecture"
- Diffusion‑based decoder: A generative refinement module that uses diffusion to restore high‑frequency details from discrete tokens. "we introduce an optional diffusion-based decoder acting as a refinement module."
- Diffusion Models: Generative models that iteratively denoise samples to produce images with high fidelity. "Diffusion Models have revolutionized visual generation"
- Dual‑codebook tokenizer: A tokenizer with separate semantic and pixel codebooks to balance high-level concepts and fine detail. "we employ a dual-codebook tokenizer that decouples semantic and pixel-level features"
- Dynamic resolution framework: A training/inference setup that supports variable image sizes and aspect ratios. "ensuring both high-level conceptual alignment and fine-grained visual fidelity within a dynamic resolution framework."
- Exposure bias: The train‑test mismatch where models trained with ground truth context must generate conditioned on their own predictions at inference. "More fundamentally, autoregressive models suffer from exposure bias"
- Flash‑Attention: An optimized attention kernel that reduces memory usage and increases speed for long sequences. "such as RoPE, RMS norm and Flash-Attention"
- FLOPs: Floating point operations per second; a measure of computational cost. "requiring fewer FLOPs during inference compared to MMDiT-based diffusion models"
- Flow matching: A training technique emphasizing difficult intermediate steps to stabilize generative training. "Inspired by flow matching techniques that emphasize difficult intermediate timesteps"
- fp32 precision: 32‑bit floating point computation used to maintain numerical stability. "Additionally, we enforce fp32 precision during quantization to maintain numerical stability."
- FusedLinearCrossEntropy: A memory‑efficient kernel fusing the final linear projection with cross‑entropy loss computation. "we adapt FusedLinearCrossEntropy, which fuses the final linear projection and cross-entropy loss computation into a single kernel"
- GenEval: A benchmark for evaluating text‑to‑image generation quality. "The plot below tracks the Geneval score against the cumulative number of training tokens (in trillions)."
- Gradient checkpointing: A technique to reduce memory by recomputing activations during backpropagation. "We employ DeepSpeed ZeRO with gradient checkpointing to enable efficient distributed training at scale."
- Group Reward Policy Optimization (GRPO): A policy optimization method that normalizes rewards within sampled groups to stabilize RL updates. "we can directly employ Group Reward Policy Optimization (GRPO) for reinforcement learning"
- Image boundary tokens: Special tokens marking the start and end of image sequences for interleaved modeling. "expand the vocabulary to include vision codes and image boundary tokens ⟨boi⟩, ⟨eoi⟩."
- In‑context learning: The ability to adapt behavior based on example context without parameter updates. "or enable in-context learning for zero-shot image editing."
- Interleaved text‑image sequences: Mixed sequences of text and image tokens processed jointly. "NextFlow processes interleaved text-image discrete token sequences as input and generates interleaved multimodal outputs."
- KL divergence (D_KL): A regularization term measuring distance between policies used in RL fine‑tuning. "-β D_{KL}(\mathbf{\pi}\theta,\mathbf{\pi}{ref})."
- Koala36M: A large video dataset used in constructing interleaved generation data. "and Koala36M, processed through a rigorous multi-stage filtering strategy."
- LAION: A large-scale image‑text dataset used in pretraining and ablations. "All experiments are conducted using a high-quality subset of LAION"
- LoRA (Low‑Rank Adaptation): A parameter‑efficient fine‑tuning method injecting low‑rank updates into pretrained models. "the 12B and 18B models are trained using Low-Rank Adaptation (LoRA)"
- LLMs: Models trained on massive text corpora for understanding and reasoning in natural language. "While LLMs have achieved mastery in text understanding and reasoning"
- Markov Decision Process (MDP): A formalization of sequential decision making used to model multi‑scale generation as actions. "The generation of a VAR sequence can be formulated as a multi-step Markov Decision Process (MDP)"
- MMDiT: A diffusion architecture variant used as a baseline for efficiency comparisons. "compared to MMDiT-based diffusion models at resolution"
- MLP layer: A projection layer used to map discrete token features into transformer model dimensions. "the Transformer variants utilize an MLP layer to project the discrete tokens into the model's native dimension."
- Megalith: A high‑quality photographic dataset used for text‑to‑image training. "and Megalith, CommonCatalog, which provide valuable high-quality photographs"
- Motion score: A quality metric ensuring sufficient temporal change in video clips. "we require a motion score greater than 4."
- Multi‑scale VQ: A vector‑quantization approach using multiple scales to improve quantization quality. "We employ multi-scale VQ to further enhance the quantization quality."
- Multiscale 3D RoPE: A positional encoding scheme extending rotary embeddings to 3D for text and multi‑scale vision tokens. "We introduce Multiscale 3D RoPE to handle interleaved text and multiscale vision tokens"
- Next‑scale prediction: A hierarchical visual generation paradigm predicting tokens scale‑by‑scale instead of raster order. "retain next-token prediction for text but adopt next-scale prediction for visual generation."
- OCR capability: The model’s ability to recognize and understand text in images. "to enhance the OCR capability of our model"
- OmniCorpus‑CC: A curated corpus for video‑text data collection. "Our data pipeline aggregates sources including OmniCorpus-CC, OmniCorpus-YT"
- OmniCorpus‑YT: A curated YouTube‑based corpus for video‑text data collection. "Our data pipeline aggregates sources including OmniCorpus-CC, OmniCorpus-YT"
- Optional diffusion decoder: An add‑on refinement model to improve photo‑realistic detail beyond discrete decoding. "we introduce an optional diffusion-based decoder acting as a refinement module."
- Packing (Fixed computation budget packing): A batching strategy that equalizes per‑GPU computational load to reduce idle time. "Fixed max computation budget packing reduces inter-GPU idle time and improving overall training throughput."
- Prefix‑tuning (RL): Fine‑tuning only early scale policies to stabilize and focus reinforcement learning on global structure. "we introduce a prefix-tuning strategy for reinforcement learning."
- PSNR: Peak Signal‑to‑Noise Ratio; a reconstruction metric that may not correlate with perceptual quality. "While the single-branch baseline yields marginally higher raw reconstruction fidelity (+0.5 PSNR at )"
- Qwen2.5‑VL‑7B: A multimodal model used as the initialization for the decoder‑only transformer. "initialized from Qwen2.5-VL-7B to leverage its strong multimodal priors."
- Quantization: The process of mapping continuous features to discrete codebook indices. "our quantization process is jointly constrained by both reconstruction fidelity and semantic consistency."
- Raster‑scan methods: Sequential pixel‑order generation that is computationally costly at high resolutions. "This departs from traditional raster-scan methods"
- REPA: A representation learning approach referenced to explain semantically aligned latents aiding AR modeling. "aligning with findings in REPA and VA-VAE."
- Residual features: Non‑accumulated per‑scale features retrieved from the codebook to simplify input space during self‑correction. "We modify the visual input to use residual features directly from the codebook without accumulation."
- RMS norm: Root Mean Square normalization; an alternative to LayerNorm used in transformer blocks. "such as RoPE, RMS norm and Flash-Attention"
- Reward model: A learned model that scores generated outputs for RL optimization. "where R is the reward model."
- Scale‑aware loss reweighting: Weighting losses by scale to emphasize coarse, structurally important predictions. "we introduce scale-aware loss reweighting while maintaining the total vision loss constant."
- Self‑correction: Training the model to recover from suboptimal earlier predictions by stochastic codebook sampling. "we introduce a self-correction mechanism during training"
- SigLIP: A vision-LLM used for video content classification and dataset balancing. "we employ SigLIP to classify video content."
- SigLIP2 (naflex): A flexible-resolution variant used to enable variable aspect ratios in the tokenizer’s semantic encoder. "upgrade the semantic encoder initialization from siglip-so400m to siglip2-so400m-naflex"
- Sinusoidal encoding: A positional encoding function applied to encode scale length. "we further introduce scale length positional embeddings. Specifically, we employ sinusoidal encoding over the number of scales"
- SFT (Supervised Fine‑Tuning): A fine‑tuning phase on high‑quality dialog data focusing supervision on model responses. "Subsequently, we performed supervised fine-tuning (SFT) using a small set of high-quality conversational data."
- Teacher forcing: Training method where models are conditioned on ground‑truth previous tokens, leading to exposure bias at inference. "during training with teacher forcing, the model always conditions on ground-truth tokens from previous steps"
- TFLOPS: Tera FLOPs per second; used to precompute sequence costs for balanced packing. "Specifically, we precompute the TFLOPS for all sequence lengths and balance workloads accordingly."
- TokenFlow: The tokenizer framework the dual‑codebook design builds upon. "The NextFlow tokenizer adopts a dual-codebook architecture building upon TokenFlow"
- Top‑k/top‑p sampling: Stochastic decoding strategies limiting choices to the top probability mass or top k tokens. "tokens within each scale are sampled independently using top-k/top-p sampling."
- Transformer‑based models: Diffusion backbones built on transformer architectures at larger parameter scales. "and two Transformer-based models with 12B and 18B parameters, respectively."
- UNet‑based model: A diffusion backbone using UNet architecture for image refinement. "We explore three model variants: a 1B parameter UNet-based model"
- VA‑VAE: A reconstruction‑focused approach cited in support of semantically aligned latent structures. "aligning with findings in REPA and VA-VAE."
- VAR (multi‑scale AR for images): A multi‑scale autoregressive framework that predicts images from coarse to fine scales. "In original VAR framework, the input features for each scale are accumulated from all previous scales."
- ViT (Vision Transformer): A transformer vision backbone replaced by the tokenizer during alignment. "we replace the original ViT in Qwen2.5-VL-7B with our vision tokenizer"
- VLM (Vision‑LLM): A model used for captioning, assessment, and dataset curation. "The image captions are rewritten using Vision-LLMs (VLM)"
- VQGAN: A single‑branch vector‑quantized generative adversarial network baseline for tokenizer comparison. "We validate the efficacy of the TokenFlow-style dual-codebook design by comparing it against a standard single-branch VQGAN."
- VQ‑VAE: A vector‑quantized variational autoencoder, typically reconstruction‑oriented for pixel fidelity. "Unlike standard VQ-VAE that relies solely on pixel reconstruction"
- Workload balancing: Strategy to balance heterogeneous data compute during packing to increase throughput. "We address this through a workload balancing strategy during data packing"
- ZeRO (DeepSpeed ZeRO): A memory‑optimization technique for distributed training that partitions optimizer states. "We employ DeepSpeed ZeRO with gradient checkpointing to enable efficient distributed training at scale."
Collections
Sign up for free to add this paper to one or more collections.

