iMontage: Unified, Versatile, Highly Dynamic Many-to-many Image Generation
Abstract: Pre-trained video models learn powerful priors for generating high-quality, temporally coherent content. While these models excel at temporal coherence, their dynamics are often constrained by the continuous nature of their training data. We hypothesize that by injecting the rich and unconstrained content diversity from image data into this coherent temporal framework, we can generate image sets that feature both natural transitions and a far more expansive dynamic range. To this end, we introduce iMontage, a unified framework designed to repurpose a powerful video model into an all-in-one image generator. The framework consumes and produces variable-length image sets, unifying a wide array of image generation and editing tasks. To achieve this, we propose an elegant and minimally invasive adaptation strategy, complemented by a tailored data curation process and training paradigm. This approach allows the model to acquire broad image manipulation capabilities without corrupting its invaluable original motion priors. iMontage excels across several mainstream many-in-many-out tasks, not only maintaining strong cross-image contextual consistency but also generating scenes with extraordinary dynamics that surpass conventional scopes. Find our homepage at: https://kr1sjfu.github.io/iMontage-web/.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces iMontage, a smart AI system that can take several input images and a text instruction, then create several new images that match the instruction while staying consistent with the input images. Think of it like making a photo collage that moves smoothly from one picture to the next, even if the scenes change a lot. iMontage aims to combine the strong “flow” understanding of video models with the creativity and variety of image models to produce sets of images that are both coherent and highly dynamic.
What questions did the researchers ask?
To make the system useful and reliable, the authors focused on a few simple questions:
- How can we generate multiple new images from multiple input images while keeping characters, objects, and styles consistent across all outputs?
- Can we use a pre-trained video model (which understands motion and time) to help image generation stay coherent across several images?
- How do we let the model handle big changes between images (like hard cuts, quick scene changes, or different camera angles) without getting confused?
How did they do it? (Methods explained simply)
The team built iMontage by “reusing” a powerful video-generation model and adapting it for sets of images. Here’s how the main pieces work, using simple analogies:
- Image and text encoding:
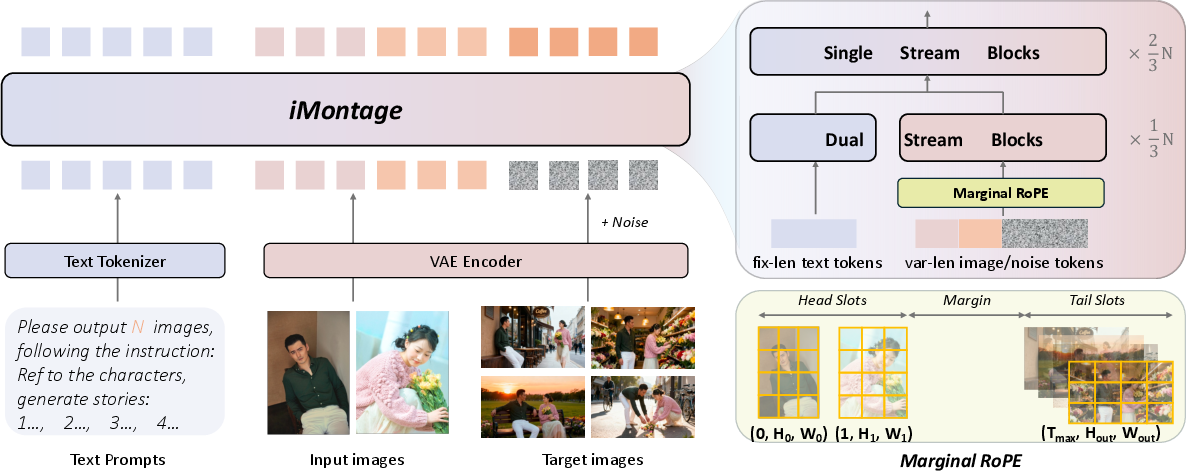
- Images are turned into compact “codes” using a tool called a 3D VAE (like compressing a photo so the model can process it efficiently).
- The text instruction (your prompt) is turned into a series of tokens using a LLM (like converting the sentence into a list of meaningful crumbs the model can follow).
- Token processing with a transformer:
- Both image tokens and text tokens are fed into a transformer (a type of AI that pays attention to relationships between pieces of information, like a smart organizer).
- The model is trained in a diffusion-like way: it starts with “noisy” versions of the target images and learns to “clean” them into clear, correct outputs. Think of it as starting with a blurry photo and gradually sharpening it based on the instruction and the input images.
- Treating images like “pseudo-frames”:
- To keep things consistent across multiple images, iMontage treats each input and output image like frames in a video. This helps the model remember what stays the same (like a character’s face or clothes) and what changes (like camera angle or background).
- Special positional tags (RoPE) to prevent confusion:
- The model uses rotary positional embeddings (RoPE) to tell “when” each pseudo-frame happens. The researchers created a “head–tail” plan: input images get early time positions, output images get late time positions, with a big gap between them.
- This separation is like placing input pictures at the start of a timeline and outputs at the end, so the model doesn’t mix them up. It keeps spatial details intact while guiding the order across multiple images.
- Training with carefully curated data:
- Pretraining used millions of pairs: image edits (before/after) and video frame pairs (nearby frames or cross-cut frames) to teach the model both consistency and dynamic changes.
- Supervised fine-tuning mixed different tasks (like style transfer, multi-view generation, multi-turn editing, and storyboard creation) in a “difficulty-ordered” schedule called CocktailMix. This helps the model learn from easier tasks first and then tackle harder ones smoothly.
- A final high-quality “polish” stage improves the crispness and fidelity of results.
What did they find? (Main results)
The model was tested on three kinds of challenges:
- One-to-one editing (single input to single output):
- iMontage matches or beats strong open-source models and is competitive with commercial systems. It follows instructions well and keeps details intact, especially for edits involving motion or actions.
- Many-to-one generation (several inputs to a single output):
- On benchmarks that check in-context understanding (like fusing multiple reference images—characters, objects, scenes—into one result), iMontage preserves identity, style, and layout while following complex prompts.
- Many-to-many generation (several inputs to several outputs):
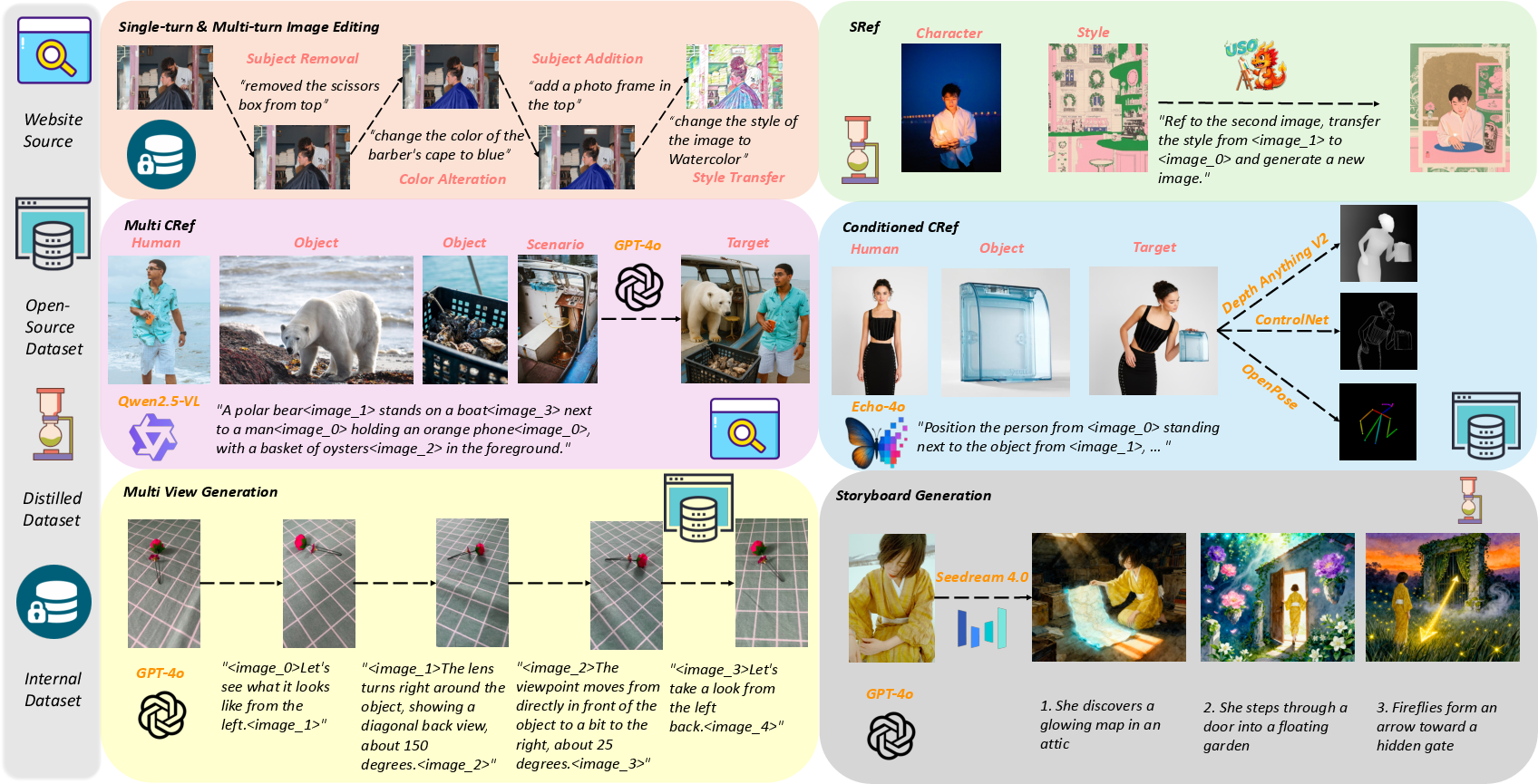
- iMontage can produce multiple coherent images in a single pass for:
- Multi-view generation (changing camera angles while keeping identity and structure),
- Multi-turn editing (applying several edits in sequence without “drifting”),
- Storyboard generation (creating a set of images that tell a story, with both smooth transitions and big changes).
- Compared to other systems, iMontage better preserves character identity across panels and keeps temporal consistency (the sense that images belong together in a sequence). User studies and feature similarity scores (DINO, CLIP, and VLM ratings) back this up.
Why this is important:
- It shows we can get the best of both worlds: the coherence of video models and the variety of image models.
- It simplifies pipelines: instead of running multiple models or many steps, iMontage can generate a whole set of images at once with strong consistency.
Why it matters and what’s next (Implications)
iMontage is a step toward unified, flexible visual creation. It can help:
- Artists and designers generate consistent characters, scenes, and styles across a series of images (like comics, storyboards, or ads).
- Content creators make dynamic photo sets matching detailed instructions without losing identity or quality.
- Researchers explore “many-to-many” generation further, using video knowledge to improve image coherence.
Limitations and future directions:
- Right now, the best quality is achieved with up to about four input images and four outputs; very long sequences are still challenging.
- The team plans to scale up “long-context” training, improve data quality, and cover more task types.
- Code and model weights will be released, encouraging open research and community progress.
Overall, iMontage shows that teaching an image model to think a bit like a video model can make sets of images more consistent, more dynamic, and more useful for real creative work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or unexplored in the paper and can guide future research:
- Scaling beyond short contexts: the model is reported to work best with up to four inputs and four outputs; there are no experiments quantifying performance degradation or design adaptations for longer many-to-many contexts (e.g., ≥16 pseudo-frames), including memory, latency, and attention-chunking strategies.
- Sensitivity of Marginal RoPE: the chosen temporal index allocation (inputs {0–7}, outputs {24–31}) lacks a systematic sensitivity study—how do different margins, index ranges, or input/output orderings affect interference, diversity, and coherence?
- Alternative positional encodings: the paper does not compare Marginal RoPE against learned positional embeddings, ALiBi, disentangled spatio-temporal encodings, or cross-attention gating that might better separate discrete image sets from continuous video priors.
- Diagnostics for discrete-set vs continuous-sequence behavior: while the approach aims to avoid conflating image sets with videos, there are no probe tasks or controlled tests (e.g., hard cuts, jump transitions) that quantify when the model applies motion priors versus treating frames as independent images.
- Backbone generality: iMontage is built on HunyuanVideo; portability and performance when adapting other video backbones (e.g., CogVideoX, Sora/Veo-like, Lumiere) are untested, including how minimally invasive the adaptation strategy truly is across architectures.
- Frozen components: VAE and text encoders are frozen; there is no ablation on partial/full fine-tuning to assess potential gains in instruction following, identity fidelity, or robustness (including multilingual prompts).
- Multilingual and compositional instructions: evaluation appears predominantly English and short-form; robustness to long, multi-step, compositional, multilingual instructions and mixed formatting (e.g., without <image_n> placeholders) is not assessed.
- Teacher/distillation bias: Storyboard data distills Seedream4.0 outputs and uses GPT-4o captions/filters; potential teacher-style imprinting, evaluation contamination, and generalization to entirely independent datasets are not quantified.
- Motion diversity coverage: optical-flow filtering and re-clipping are described, but there is no quantitative characterization of the motion distribution (e.g., hard cuts, whip pans, large subject jumps) or stress tests demonstrating reliable handling of abrupt temporal discontinuities.
- Control adherence: in Conditioned CRef, ControlNet signals (pose, depth, lineart) are added but not evaluated with quantitative control-following metrics (e.g., pose keypoint alignment, depth consistency) or studies of conflicting/multiple controls.
- Prompt-engineering ablations: the effects of the system-style preamble, placeholder formatting, and instruction templates on task performance, stability, and overfitting are not explored.
- Curriculum specifics and forgetting: CocktailMix is selected, but the precise task difficulty ordering, sampling weights, and anti-forgetting strategies are not disclosed; there is no quantitative analysis of catastrophic forgetting across tasks.
- Objective choice: the model uses flow matching without comparison to ε/v-prediction diffusion or rectified flow; effects on convergence speed, identity preservation, and temporal coherence remain unanswered.
- Output resolution constraints: output resolution is fixed during SFT; the impact on generalization to variable output sizes/aspect ratios and the efficacy of test-time up/down-scaling for many-to-many outputs is unknown.
- Efficiency scaling: one-shot generation with 50 steps is claimed, but empirical trade-offs among number of outputs, steps, GPU memory, and latency are not reported; scalability beyond four outputs and batching strategies need quantification.
- Controllable consistency/diversity: there is no explicit mechanism to tune cross-output coupling (e.g., a coherence knob); how to systematically adjust diversity vs identity/layout consistency across outputs remains open.
- Metrics for discrete-set temporal coherence: reliance on DINO/CLIP similarity and VLM ratings leaves gaps—standardized, reproducible metrics for identity preservation and temporal coherence across discontinuous image sets are needed.
- Baseline fairness and breadth: comparisons include some models enhanced by UMO and rely on VLM scoring; blinded, third-party evaluations and broader many-to-many baselines (including token-centric unified models under matched conditions) are missing.
- Robustness and edge cases: performance under domain shifts (non-photorealistic, low-light, medical), heavy occlusion, extreme viewpoints, motion blur, corrupted inputs, and conflicting references is not tested.
- Safety guardrails: identity-preserving many-to-many generation raises deepfake risks; there is no discussion of consent mechanisms, watermarking/provenance, content moderation/refusal policies, or a safety evaluation protocol.
- Data ethics and licensing: internal corpora and web-scraped content are used without detailing licensing, consent, or copyright status; distillation from closed-source outputs (Seedream4.0) poses unresolved IP and compliance questions.
- Cross-modality extensions: storyboards are image-only; alignment with audio or video outputs (e.g., multi-modal story generation) and consistency across modalities are unexplored.
- Video capability retention: repurposing a video backbone may affect its native video generation performance; there is no evaluation of whether original motion priors and video quality are preserved post-adaptation.
- Failure mode taxonomy: “several capabilities remain limited” is noted, but a detailed taxonomy with frequencies, conditions, and root-cause analyses (identity drift, background leakage, style bleeding, instruction miss) is absent from the main text.
- Reproducibility: code/weights are promised but not yet available; full training recipes, dataset manifests, sampling schedules, and hyperparameters (especially for CocktailMix and resolution bucketing) are insufficiently detailed for replication.
- Fairness across demographics: identity preservation and style transfer across diverse demographics, ages, and cultures (and potential VLM scorer biases) are not evaluated or mitigated.
- Formal analysis of pseudo-frame modeling: how temporal RoPE interacts with denoising dynamics and attention routing (e.g., misrouting across inputs/outputs) lacks theoretical grounding or interpretability studies.
- Low-resource training: feasibility for academic labs is unclear; lower-cost alternatives (LoRA/PEFT, teacher–student distillation, curriculum with fewer GPUs) and carbon/energy footprints are not addressed.
Practical Applications
Overview
iMontage repurposes a large pre-trained video diffusion model for unified many-to-many image generation and editing. Its key innovations—Marginal RoPE to separate input and output pseudo-frames, variable-length token handling in MMDiT, motion-diverse data curation, and a curriculum-like CocktailMix training regimen—enable one-shot generation of multiple, temporally coherent and content-consistent images from multiple references and a single prompt. Below are practical applications across industry, academia, policy, and daily life, categorized by deployment readiness.
Immediate Applications
The following applications can be prototyped or deployed now, leveraging available model weights, commodity GPUs, and existing creative toolchains.
- Storyboard and previsualization assistant (Media/Entertainment)
- Use: Generate multi-panel storyboards with consistent character identity, dynamic scene changes, and temporal continuity from a few reference images and a prompt.
- Tools/Workflows: Adobe Premiere/After Effects or Figma plugins; “Storyboard Studio” built around iMontage’s many-out generation; batch prompt templates for episodic sequences.
- Assumptions/Dependencies: Best quality up to ~4 inputs/outputs per run; human-in-the-loop review; content rights for reference images.
- Multi-view product imagery at scale (E-commerce/Retail)
- Use: Produce consistent multi-angle product shots and contextual variants (seasonal, background, lighting) from a single hero image.
- Tools/Workflows: Shopify/Shopware plugins; DAM integrations (“Catalog360”); optional ControlNet maps (pose/depth/edge) via OpenPose/Depth-Anything/Lineart for tighter control.
- Assumptions/Dependencies: Accurate geometry and material depiction needed for high-fidelity SKUs; brand approval workflows; rights to product imagery.
- Batch identity-preserving style transfer (Brand/Marketing/Design)
- Use: Apply a brand’s visual style to diverse assets while preserving character or object identity across a campaign.
- Tools/Workflows: “Brand Style Consistency Engine” that pairs content references with style references (SRef pipeline); rollout across web, social, and print.
- Assumptions/Dependencies: Curated style libraries; tone/brand guidelines; risk of style leakage mitigated by VLM scoring.
- Multi-turn, localized editing pipelines (Creative Agencies/Photo Ops)
- Use: Run sequential edits (color changes, object insert/remove, pose tweaks) in one shot while preserving non-target content—reducing drift.
- Tools/Workflows: “EditChain” for batched instructions; integration with Adobe Photoshop; revision tracking and side-by-side diffing.
- Assumptions/Dependencies: Clear edit instructions; human QA before publishing; prompt templates for standardized operations.
- Character sheets and environment variations (Gaming)
- Use: Generate consistent poses, angles, and outfits for a character; create environment variations maintaining art bible constraints.
- Tools/Workflows: Unity/Unreal plugins; asset packs for NPC/hero visuals; quick “look-dev” boards for art direction.
- Assumptions/Dependencies: Art style alignment; legal clearance of character references; scale to limited frame count per run.
- Educational visual narratives (Education/Publishing)
- Use: Create multi-panel sequences explaining processes (e.g., historical events, physics concepts) with consistent visual entities.
- Tools/Workflows: “NarrativeComposer” for lesson plans; LMS integration; textbook illustration pipelines.
- Assumptions/Dependencies: Age-appropriate content filters; fact-checked captions; instructor review.
- Social media episodic content (Creator Economy)
- Use: Produce weekly multi-image episodes with consistent identity and story arcs for influencer narratives or brand storytelling.
- Tools/Workflows: Content calendar integrations; A/B testing of sequences; auto-caption generation via VLM.
- Assumptions/Dependencies: Platform TOS compliance; watermarking; moderation filters.
- Real estate staging and multi-angle listing images (Real Estate)
- Use: Generate staged interiors and exterior multi-view shots with consistent property features and temporal transitions (day/night).
- Tools/Workflows: MLS/DAM pipelines; “OmniView” staging generator; variant packs for different buyer personas.
- Assumptions/Dependencies: Clear disclaimers to avoid misleading representation; local regulations; consent from property owners.
- 2D animation keyframe augmentation (Animation)
- Use: Produce consistent keyframe sequences across shots and camera moves for early previsualization or animatic creation.
- Tools/Workflows: Timeline-aware batch generation; integration with Toon Boom/Blender for layout/boarding.
- Assumptions/Dependencies: Art team supervision; limit to concept stages (not final production).
- Dataset augmentation for CV research (Academia/Software)
- Use: Generate multi-view, multi-turn edited image sets for robust training of perception systems and benchmarking identity/temporal consistency.
- Tools/Workflows: “AssetAugmentor” scripts; optical flow-based motion filtering (RAFT), VLM scoring for quality; identity-preserving dataset synthesis.
- Assumptions/Dependencies: Avoid synthetic-to-real leakage in evaluation; document synthetic origins; target domain alignment.
- Design system asset generation (Software/UI/UX)
- Use: Produce consistent themed illustrations across multiple sizes/aspect ratios and contexts from brand templates.
- Tools/Workflows: Figma/Adobe XD plugins; auto-resize and cropping; content-aware consistency enforcement.
- Assumptions/Dependencies: Governance on design tokens; review gates for accessibility and inclusivity.
- Content compliance and curation workflows (Policy/Trust & Safety)
- Use: Integrate NSFW and face detection filters, watermarking, and provenance tracking in generation workflows.
- Tools/Workflows: CLIP-based NSFW filters; invisible watermark standards (e.g., C2PA); audit logs and user attestation flows.
- Assumptions/Dependencies: Alignment with evolving regulatory guidance; maintain opt-in consent for identity uses.
Long-Term Applications
These opportunities require further research, scaling, long-context modeling, and/or ecosystem standards before robust deployment.
- Long-context episodic storytelling and continuity management (Media/Entertainment)
- Use: Generate dozens of panels/scenes with persistent memory of characters, props, and layout; flag continuity errors and propose fixes.
- Tools/Workflows: Shot-list–aware narrative engines; scene graph memory modules; integration with production asset databases.
- Assumptions/Dependencies: Extended context handling beyond 4 frames; memory architectures; studio workflows and approvals.
- Geometry-consistent multi-view for 3D reconstruction (3D/Robotics/AR/VR)
- Use: Use iMontage’s multi-view outputs as priors for NeRF/photogrammetry or texturing pipelines, enabling asset creation from sparse photos.
- Tools/Workflows: Bridge to NeRF toolchains; geometry consistency metrics; “Render-to-Recon” pipeline.
- Assumptions/Dependencies: Strong geometric fidelity and camera parameter recovery; domain-specific fine-tuning; evaluation against ground truth.
- Image-set to video generation (“montage-to-video”) (Video/Media Tech)
- Use: Convert coherent many-out image sets into short videos with learned motion priors and controlled transitions.
- Tools/Workflows: Hybrid image/video diffusion; cut-aware transition models; editor-ready export (EDL/XML).
- Assumptions/Dependencies: Joint training with contiguous and discontinuous clips; user control layers for pacing and transitions.
- Personalized marketing at massive scale (AdTech)
- Use: Deliver millions of individualized multi-image sequences with consistent identity/style for lifecycle campaigns.
- Tools/Workflows: Scalable inference (distributed GPU/accelerators); prompt program synthesis; campaign-level guardrails and auditing.
- Assumptions/Dependencies: Compute efficiency; data privacy and consent management; on-platform content moderation.
- Synthetic dataset factories for multimodal foundation models (Academia/Industry)
- Use: Generate motion-diverse, instruction-rich image sets to pretrain or finetune unified multimodal models.
- Tools/Workflows: Automated curation with optical flow and VLM scoring; captioning via LLMs; open benchmarks for identity+temporal consistency.
- Assumptions/Dependencies: Avoid biased content; clear provenance/watermarking; alignment with ethical data guidelines.
- Avatar consistency across metaverse apps (XR/Platforms)
- Use: Maintain consistent avatar identity and wardrobe across scenes and platforms via image-set generation and translation.
- Tools/Workflows: Identity embedding registries; cross-platform asset adapters; user-controlled style packs.
- Assumptions/Dependencies: Standards for identity representation and consent; portability across engines.
- CAD/CAE design iteration with multi-angle render sets (Manufacturing/Architecture)
- Use: Rapidly generate consistent multi-angle design visuals for stakeholder reviews and ergonomic assessments.
- Tools/Workflows: CAD plugins; variant proposal boards; traceability to design changes.
- Assumptions/Dependencies: Material/geometry fidelity; integration with CAD metadata; regulatory compliance for safety-critical domains.
- Healthcare education visuals (Healthcare Education)
- Use: Produce consistent multi-panel procedure explanations and patient education narratives.
- Tools/Workflows: Medical curriculum tooling; clinician-in-the-loop validation; controlled vocabularies for accuracy.
- Assumptions/Dependencies: No diagnostic or clinical decision support; rigorous review; HIPAA and consent compliance.
- Robotics simulation domain randomization (Robotics/Autonomy)
- Use: Generate consistent scene sequences with controlled variations for training robust perception and planning models.
- Tools/Workflows: Scenario libraries; perception evaluation harness; sim-to-real transfer studies.
- Assumptions/Dependencies: Accurate depiction of physical constraints; label generation; alignment with simulator physics.
- Policy frameworks for provenance, licensing, and deepfake mitigation (Policy/Standards)
- Use: Establish watermarking/provenance standards, identity consent requirements, and auditing norms for generative multi-image systems.
- Tools/Workflows: C2PA-like standards; platform enforcement APIs; public registries.
- Assumptions/Dependencies: Multistakeholder agreement (platforms, vendors, regulators); global interoperability.
- Cross-app creative automation with LLM-mediated instructions (Software)
- Use: Orchestrate sequences across design/video/apps via unified prompts and image-set generation, reducing manual handoffs.
- Tools/Workflows: “Creative RPA” agents; prompt templates and DSLs; task graphs spanning Adobe, Figma, NLEs.
- Assumptions/Dependencies: Robust instruction following across heterogeneous tasks; app ecosystem APIs; error recovery strategies.
- Carbon-aware and cost-efficient AIGC at scale (Energy/Cloud)
- Use: Optimize inference/training schedules and model routing to minimize energy use and cost for large content factories.
- Tools/Workflows: Cost/energy telemetry; dynamic resolution bucketing; green compute scheduling.
- Assumptions/Dependencies: Model quantization/distillation; access to low-carbon data centers; business alignment on sustainability.
Notes on Feasibility and Assumptions
- Model availability and licensing: iMontage code/weights “will be made publicly available”; verify license terms and permissible commercial use.
- Compute constraints: Current best quality with up to four inputs/outputs; default ~50 diffusion steps; plan GPU/memory budgets and batch scheduling.
- Control signals: For conditioned generation, leverage ControlNet-compatible maps (pose/depth/edge) to improve determinism.
- Data rights and consent: Ensure rights for reference images; obtain consent for identity-preserving uses; apply watermarking/provenance.
- Safety and moderation: Integrate NSFW filters and content policies; monitor for misuse (e.g., deepfake risks).
- Domain adaptation: For high-stakes verticals (e.g., medical, industrial), require domain-specific finetuning and expert review before deployment.
- Geometry fidelity caveats: Multi-view outputs are not guaranteed to be metrically accurate; treat 3D reconstruction applications as research-stage until validated.
- Human oversight: Maintain human-in-the-loop review for narrative accuracy, brand compliance, and ethical standards.
Glossary
- 3D VAE: A variational autoencoder that encodes spatiotemporal image volumes (frames) into latent representations for video/image sequences. "Images are encoded by a 3D VAE separately, text by a LLM, and both token streams are processed by an MMDiT."
- Annealing (learning rate): Gradually reducing the learning rate to improve final model fidelity at the end of training. "During this stage, we anneal the learning rate to zero."
- Aspect-ratioâaware resolution bucketing: Grouping samples by aspect ratio and resizing to a set of fixed canonical resolutions for stable, efficient training. "we adopt aspect-ratioâaware resolution bucketing: for each sample, we select the best-fitting size from a set of 37 canonical resolutions and resize accordingly."
- Attention maps: Matrices that define which tokens attend to which others; here built to handle variable-length image token sequences. "constructing variable-length attention maps over their image tokens, guided by prompt-engineering cues."
- Autoregressive generation: Generating outputs by predicting the next tokens conditioned on previously generated tokens. "and autoregressively generate target tokens conditioned on the inputs"
- CLIP feature similarity: A metric comparing semantic similarity of images using CLIP embeddings. "we use DINO and CLIP feature similarity"
- CocktailMix: A difficulty-ordered fine-tuning schedule that introduces tasks progressively, adjusting sampling weights. "CocktailMix: Difficulty-Ordered Fine-Tuning."
- ControlNet: A diffusion model add-on that conditions generation on control signals like pose, depth, or edges. "We apply some classic ControlNet\citep{zhang2023adding} generation control maps to the target image."
- Curriculum Training: Training strategy that orders tasks by curriculum (stages) to stabilize learning. "StageMix: Curriculum Training."
- Data-curation pipeline: A structured process to collect, filter, and organize datasets for training. "We further provide a data-curation pipeline, which is carefully categorized and filtered for motion diversity and instruction quality"
- Denoising: The core diffusion step that removes noise to produce clean images from noisy latents. "We concatenate clean reference-image tokens with noisy target tokens before denoising."
- DINO feature similarity: A metric comparing visual identity/content using DINO embeddings. "we use DINO\citep{caron2021emerging} and CLIP\citep{radford2021learning} feature similarity"
- Diffusion steps: The number of iterative denoising steps used during inference in diffusion models. "with a default of 50 diffusion steps."
- Discontinuous video generation: Treating multi-image tasks as non-contiguous video sequences to leverage video priors. "which re-frames multi-image generation as 'discontinuous video generation.'"
- Dual stream to single stream blocks: An architectural training transition where separate token streams are merged into one. "transitions from dual stream to single stream blocks."
- Flow matching: A training objective that aligns model-generated flows with target data distributions for generative modeling. "the training target follows flow matching\citep{lipman2022flow}."
- Full-finetune: Updating all parameters of a selected module during fine-tuning. "During training, we frozen VAE and text encoder, only full-finetune the MMDiT."
- Hard cuts: Abrupt transitions between scenes or shots that break temporal continuity. "which rarely contains hard cuts, abrupt transitions, or large camera/subject motions"
- Head--tail layout: A positional indexing scheme that places inputs early and outputs late along a temporal axis to reduce interference. "This head--tail layout reduces positional interference between inputs and targets and empirically promotes more diverse output content while preserving temporal coherence."
- HunyuanVideo: A large video generative framework used as the initialization backbone. "All components are initialized from HunyuanVideo \citep{kong2024hunyuanvideo}"
- I2V checkpoint: A pretrained video model checkpoint for image-to-video tasks used to initialize components. "the MMDiT and 3D VAE are taken from the I2V checkpoint, while the text encoder is taken from the T2V checkpoint."
- Identity Preservation: Maintaining consistent subject identity (e.g., facial or body features) across outputs. "Identity Preservation."
- In-context learning: Using provided references or context within the prompt to guide generation without explicit fine-tuning. "in-context learning benchmark (many-to-one)"
- Marginal RoPE: A RoPE variant that assigns input and output pseudo-frames to separated temporal index ranges to reduce interference. "we apply Marginal RoPE, a headâtail temporal indexing that separates input and output pseudo-frames"
- MLLMs (Multimodal LLMs): LLMs that process and reason over multiple modalities (text, images, etc.). "with the integration of powerful multimodal LLMs (MLLMs) as reasoning engines."
- MMDiT: A multimodal diffusion transformer processing joint image and text token streams. "both token streams are processed by an MMDiT."
- Motion priors: Learned biases in video models about how objects move and scenes change over time. "pre-trained motion priors to markedly enhance temporal coherence"
- Many-in-many-out tasks: Generative tasks with multiple input images and multiple output images. "iMontage excels across several mainstream many-in-many-out tasks"
- NSFW filter: A content filter to exclude not-safe-for-work images from datasets. "an NSFW filter \citep{Clip-based-nsfw-detector}"
- OpenPose: A pose estimation system used to derive human skeletal keypoints for conditioning. "We use OpenPose\citep{cao2019openpose} to generate the character poses of the composite image"
- Optical-flow estimator: A model that computes motion vectors between frames to measure and filter motion. "we apply motion filtering with an optical-flow estimator \citep{teed2020raft}"
- Patchified tokens: Image features split into patches and converted into token sequences for transformers. "Reference images are encoded by the 3D VAE seperately and then patchified into tokens;"
- Prompt Engineering: Designing and structuring textual instructions to elicit desired model behavior across tasks. "Prompt Engineering"
- Pseudo-frames: Treating independent images as frames along a temporal axis to leverage video model structure. "treats both inputs and outputs as pseudo-frames."
- RoPE (Rotary Positional Embedding): A positional encoding method using rotations in embedding space to encode order. "We introduce a novel rotary positional embedding (RoPE) strategy to prevent conceptual ambiguity between multiple image frames and video frames."
- SFT (Supervised Fine-Tuning): A stage using labeled data to refine a pretrained model for specific tasks. "a Supervised Fine-tuning (SFT) dataset."
- Spatial RoPE: RoPE applied to spatial dimensions to preserve spatial positional geometry. "we preserve the pretrained spatial RoPE"
- Temporal RoPE: RoPE applied to the temporal dimension with per-image indices to signal ordering. "and introduce a separable temporal RoPE with per-image index offsets"
- Token budget: The constraint on total tokens per batch used to balance memory and stability. "equalizing the token budget across resolutions"
- Token-centric models: Systems that unify modalities as token streams and generate targets by token prediction. "token-centric models that represent text and images as a unified multimodal token stream and autoregressively generate target tokens conditioned on the inputs"
- UMO: An optimization technique used to improve identity and quality in unified models. "the evaluated OmniGen2 and UNO models are optimized by UMO\citep{cheng2025umo}"
- Variable numbers of input and output frames: A capability to flexibly handle differing counts of input and output images. "accommodate variable numbers of input and output frames"
- Video-centric pipelines: Approaches that use video diffusion backbones to naturally support variable-length generation. "video-centric pipelines that repurpose video diffusion generation as backbones"
- Video diffusion generation: Applying diffusion models to video sequences for temporally coherent synthesis. "repurpose video diffusion generation as backbones"
- VLMs (Vision LLMs): Models that jointly process visual and textual inputs for understanding or generation. "inspired by the success of LLMs and large vision LLMs (VLMs)"
Collections
Sign up for free to add this paper to one or more collections.

