- The paper introduces AgentGate, a candidate-aware two-stage routing engine that efficiently handles multi-agent requests under resource and privacy constraints.
- It utilizes compact LLM backbones and structured output targets to achieve high routing accuracy and robust safety measures in edge deployments.
- Experimental results demonstrate strong action, agent, and argument matching metrics while minimizing cloud fallback for ambiguous or unsafe queries.
AgentGate: Structured Routing for the Internet of Agents
The scaling of distributed multi-agent AI systems under heterogeneous resource, privacy, and latency regimes creates acute challenges for agent request dispatch. While agent discovery, naming (e.g., AgentDNS), and protocol standardization (e.g., A2H) layers have developed, routing—deciding which agent(s), if any, should handle a given request, and how—remains largely unsolved in systems optimized for edge deployment and real-world constraints. The widely adopted paradigm of using a centralized cloud LLM router is problematic: it incurs high latency, recurring costs, and privacy risks due to remote inference; conversely, relying solely on small edge models often yields unreliable or unsafe handling of ambiguous queries. The core research hypothesis is that multi-agent request routing should be posed as a structured decision problem over a constrained action set, rather than as open-ended text or tool generation.
AgentGate addresses this problem by introducing a lightweight, candidate-aware, two-stage routing engine explicitly designed for edge-first, privacy- and resource-constrained multi-agent environments.
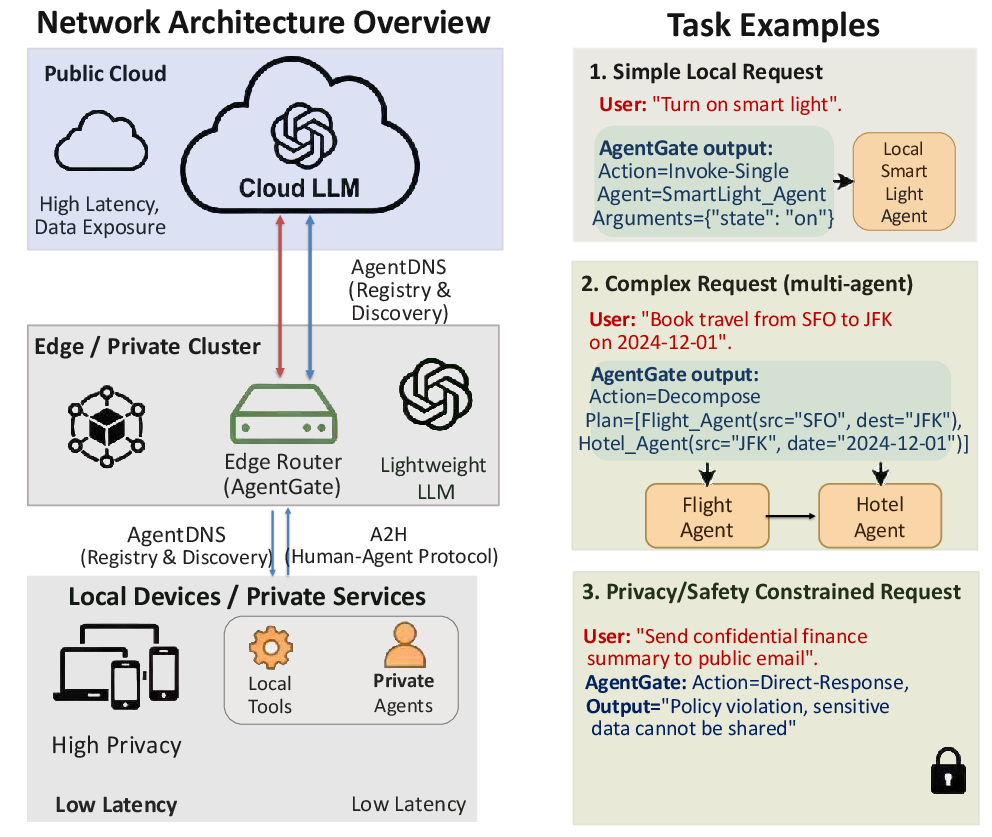
Figure 1: Overview of the proposed agent network architecture and representative routing task examples handled by AgentGate.
AgentGate Architecture and Routing Pipeline
AgentGate formalizes routing as a composition of two stages: coarse action decision followed by conditional structural grounding. Each incoming request, with its candidate agent set and optional contextual metadata, is first classified into one of four explicit action types: (1) single-agent invocation, (2) multi-agent planning, (3) direct natural-language response, or (4) safe escalation (reject/abstain under safety/policy conditions). This factorization enables explicit early filtering, boundary handling, and reduces the complexity of downstream structural prediction. The second stage conditionally instantiates the chosen action into concrete outputs—e.g., agent selection and arguments for invocation, or an ordered agent sequence for plans—consistent with candidate schemas and the derived action.
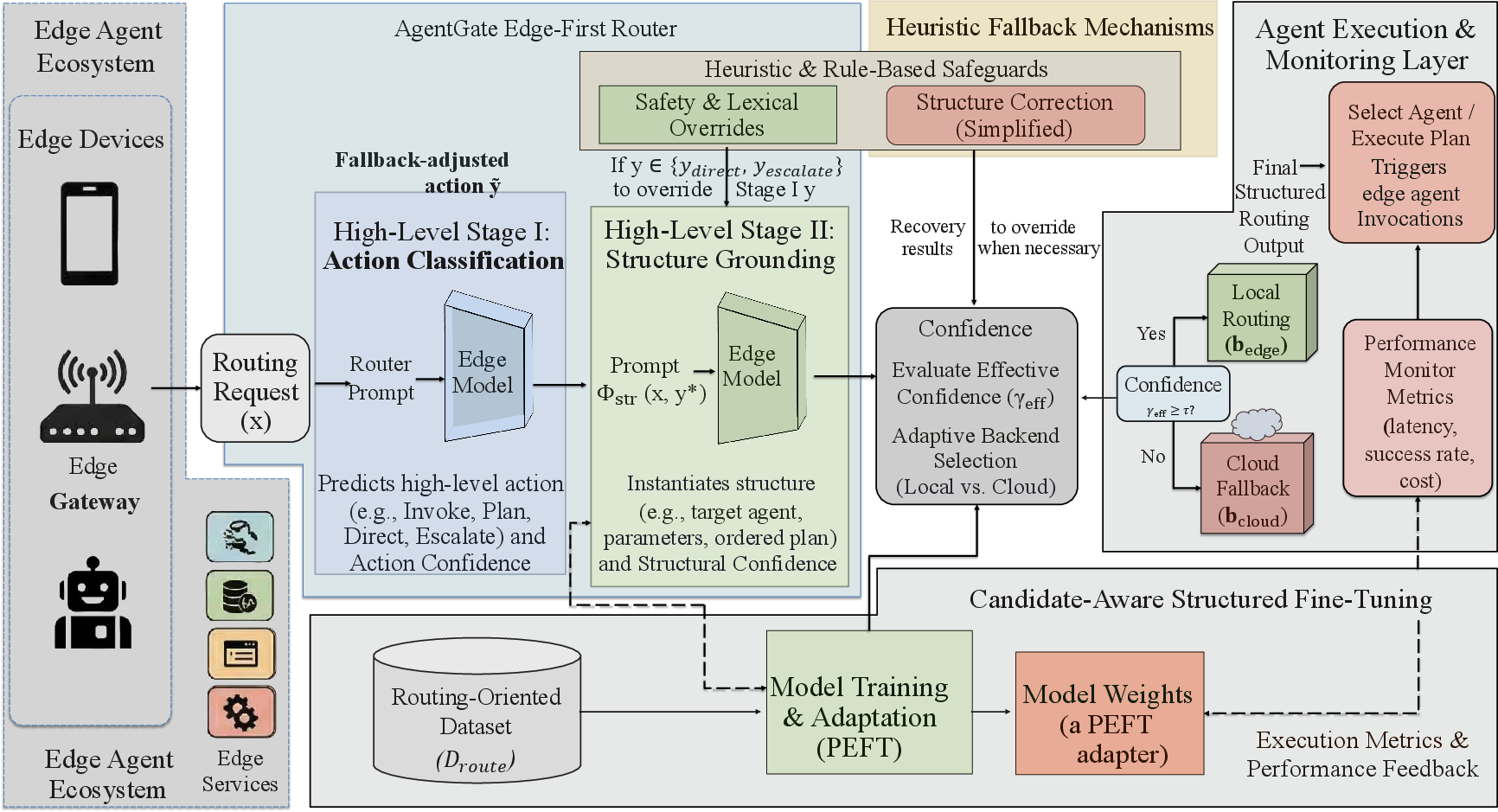
Figure 2: Detailed architecture of the AgentGate framework, illustrating the two-stage structured routing pipeline, heuristic fallback mechanisms, and confidence-aware backend selection.
A key mechanism in AgentGate is confidence-aware backend selection: edge-side models produce calibrated confidence scores for both stages, and a tunable threshold triggers cloud fallback only for low-confidence (i.e., ambiguous or potentially unsafe) instances. This decouples task-level escalation (declining/rejecting a request) from system-level remote inference escalation, further enhancing privacy guarantees and adaptable resource utilization.
Heuristic fallback layers—including sensitive-content recognition, sequential marker detection, and lightweight argument slot-completion—reinforce the learned router, providing robustness against hallucinations or partial failures.
Model Training and Candidate-Aware Supervision
AgentGate adapts compact LLM backbones (3B–7B parameters) as structured routers via a fine-tuning pipeline that leverages:
- Task-specific, candidate-aware supervision wherein, for each training query, only the currently accessible candidate agents are considered;
- Hard negative sampling with misleading lexical compositions, ambiguous boundaries, and semantically overlapping candidates to enforce sharp action/plan discrimination;
- Structured output targets including canonical JSON for argument/plan grounding;
- Parameter-efficient methods (e.g., LoRA) to ensure edge-feasible deployment.
The loss focuses exclusively on output tokens for actions, agent indices, arguments, and plans, eschewing generic instruction tuning. Empirical ablations indicate primary improvements from structured supervision are realized in output regularity and schema adherence, while action and rough candidate selection can already be performed acceptably by strong instruction-tuned backbones absent task-specific fine-tuning.
Experimental Evaluation
AgentGate is evaluated on a 3,200-instance benchmark tailored to AgentDNS settings, encompassing diverse domains and realistic agent registry subsets. The evaluation suite encompasses multiple routing metrics: action accuracy, agent accuracy, argument exact match, plan exact match, output JSON validity, and escalation precision/recall.
Notably, AgentGate (Qwen2.5-7B backbone) delivers the following strong results:
- Action Accuracy: 0.9425
- Agent Accuracy: 0.8800
- Argument Exact Match: 0.9325
- Plan Exact Match: 0.8075
- Escalation Precision/Recall: 1.0000/1.0000
Compact 3B–7B models, under structured routing and candidate-aware fine-tuning, achieve competitive end-to-end routing with perfect safety/abstention for the test set. Retrieve-rank baselines, leveraging semantic search, perform strongly but are outperformed by AgentGate on structured routing quality and reliably distinguishing boundary/unsafe cases. Unmodified, open-ended tool-calling paradigms perform substantially worse.
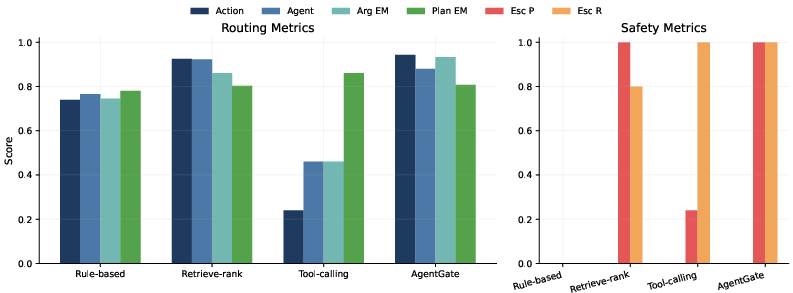
Figure 3: Baseline comparison on the AgentDNS runtime benchmark. The left panel reports routing metrics, and the right panel reports escalation precision and recall.
Backbone analysis shows Qwen2.5-7B and Phi-3.5-mini achieve the most consistent accuracy and safety metrics. Smaller models (Qwen2.5-3B) retain acceptable action/agent accuracy, but exhibit degraded argument/plan grounding and escalation recall. Llama2-7B and Mistral-7B display less stable or less efficient runtime behavior.
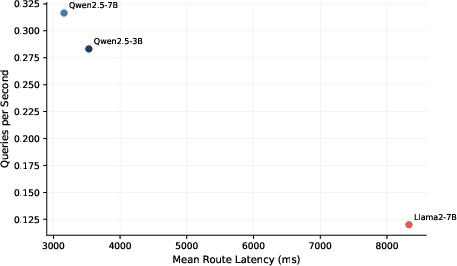
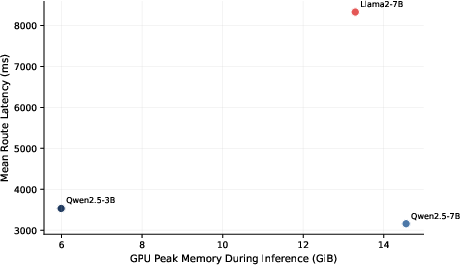
Figure 4: Performance trade-offs across representative backbones.
System-level analytics reveal practical trade-offs: Qwen2.5-7B provides optimal balance between throughput, latency, GPU memory footprint, and routing accuracy for edge deployment. Runtime is dominated by the structural grounding stage; Qwen2.5-3B yields reduced memory demands but at a significant accuracy cost; Llama2-7B incurs excessive latency and memory consumption.
In hybrid mode, with aggressive fallback to a commercial cloud LLM, the hybrid solution's performance matches that of the dominant cloud model, but the results highlight that the decision threshold for fallback requires careful calibration. The system’s resilience under hybrid deployment is established, though further work on fallback policy optimization is necessary to maximize both privacy and robustness.
Implications and Future Directions
AgentGate demonstrates that structured action/grounding decomposition permits small edge-side LLMs to achieve high-fidelity, privacy-preserving routing in multi-agent settings with explicit safety controls and actionable escalation. This advances the architectural separation of agent discovery, naming, and routing, establishing the feasibility of decoupled, modular agent ecosystems suitable for the Internet of Agents vision.
The explicit empirical finding that retrieve-rank pipelines are highly competitive but insufficient for robust boundary/escallation handling underscores the necessity of an action-structured, candidate-aware approach. AgentGate’s confidence-aware hybrid design further enables adaptive system behavior at deployment, providing a rigorous foundation for integrating edge and cloud intelligence in a cost-effective and privacy-conscious manner.
Future theoretical work may focus on: (i) learning optimal fallback policies for minimizing cloud usage while ensuring robust ambiguous query handling; (ii) extending the structured routing paradigm to encompass multi-hop, partially observable agent graphs; and (iii) enabling online adaptation to dynamic agent registries and evolving safety/policy constraints. Practical evolution toward on-device multimodal agents and federated structured routing across the edge-cloud continuum is anticipated as agent ecosystems mature.
Conclusion
AgentGate systematically advances the state of agent routing for resource-constrained multi-agent environments by reframing routing as a candidate-constrained, two-stage structured decision process. Experiments confirm compact models can perform this task with strong routing and safety metrics when provided with candidate-aware fine-tuning and explicit output constraints. The architectural, algorithmic, and empirical insights from AgentGate offer a robust template for scalable, safe, and efficient agent orchestration in the Internet of Agents paradigm.

