- The paper introduces a novel diagnostic tool, Step-Saliency, to identify systematic failures like Shallow Lock-In and Deep Decay in large reasoning models.
- The paper employs a plug-and-play, test-time intervention called StepFlow that uses Odds-Equal Bridge and Step Momentum Injection to mitigate propagation errors.
- The intervention significantly boosts accuracy across benchmarks in mathematics, science, and code without retraining, illustrating practical enhancements in model reliability.
Diagnosing and Repairing Reasoning Failures in LRMs with Step-Saliency and StepFlow
Introduction
The paper "Reasoning Fails Where Step Flow Breaks" (2604.06695) addresses the persistent instability and opacity of large reasoning models (LRMs) on long-form, multi-step tasks in mathematics, science, and code. The authors introduce Step-Saliency, a diagnostic tool that aggregates token-level attention–gradient saliency into interpretable step-to-step maps along the canonical question–thinking–summary decomposition. Through comprehensive step-level analysis, the authors uncover two systematic information propagation failures—Shallow Lock-in and Deep Decay—that discriminate erroneous from correct reasoning traces. To mitigate these failures at test time without retraining, the authors propose StepFlow, a two-part intervention targeting shallow and deep layer saliency patterns via attention mass redistribution (Odds-Equal Bridge) and deep layer residual injection (Step Momentum Injection). StepFlow consistently yields substantial accuracy gains across state-of-the-art LRMs on standard reasoning and code benchmarks.
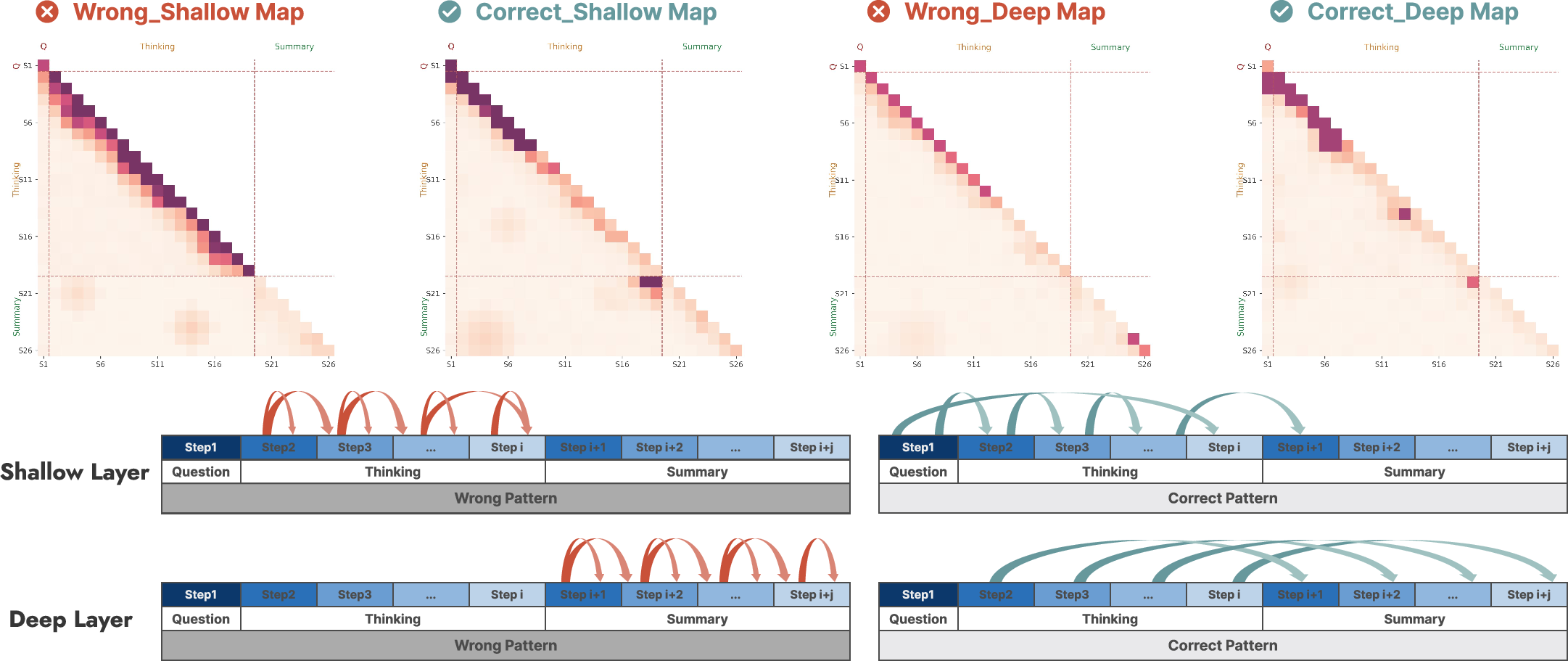
Traditional attention- or gradient-based interpretability methods generally output token-level saliency maps, which become inscrutable and noisy for long, structured reasoning traces. Step-Saliency provides a step-level aggregation mechanism, pooling token-wise saliency into block-wise maps corresponding to question, each reasoning step, and the final summary. In this scheme, within-diagonal mass represents step-wise self-reinforcement, while off-diagonal blocks reveal cross-step dependencies.
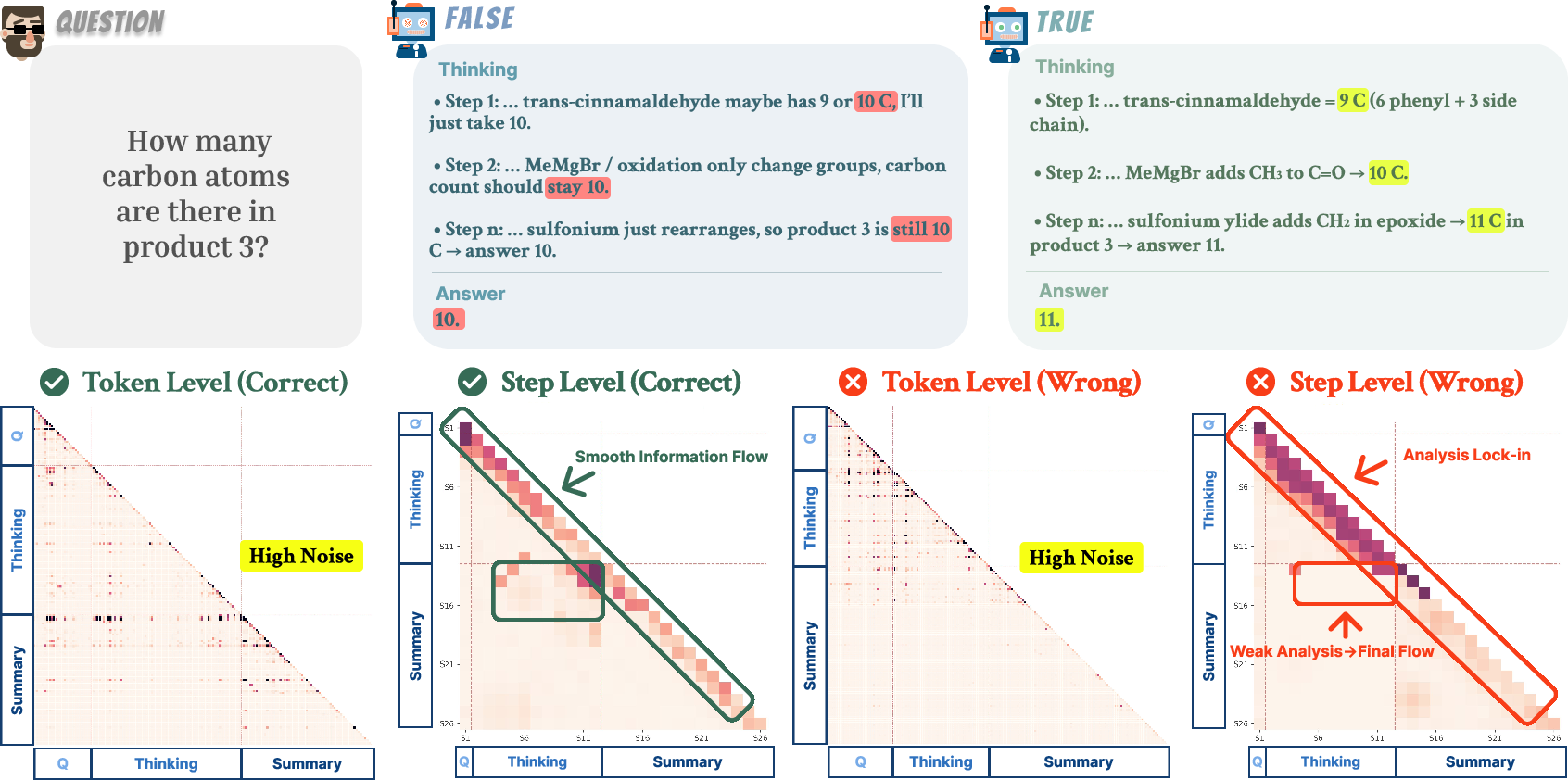
Figure 1: Step-Saliency pools token-level saliency into step-level question→thinking→summary dependencies; correct traces exhibit smooth stepwise flow, while errors show shallow lock-in and weak summary links.
Layer-wise analysis of Step-Saliency maps reveals contrasting information flow patterns in correct and incorrect model generations:
Quantitative saliency metrics—mean within-thinking and within-summary self-reinforcement—across layers corroborate these findings across several LRMs.
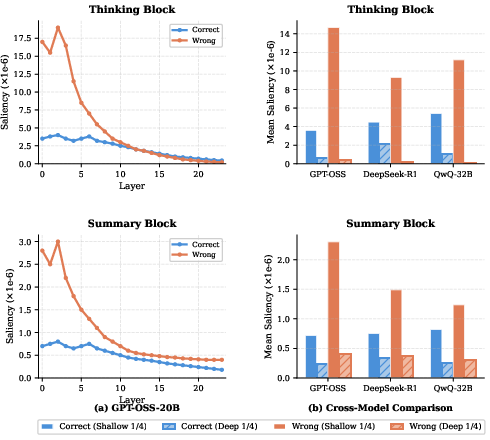
Figure 3: Error traces show pronounced shallow lock-in and premature summary self-intensity in deep layers relative to correct traces, across multiple LRMs.
StepFlow: Test-Time Saliency Intervention
Guided by these diagnostic discoveries, the authors develop StepFlow, a plug-and-play test-time intervention leveraging the segmentation and block structure of Step-Saliency.
- Odds-Equal Bridge (OEB): Applied to shallow layers, OEB ensures that attention mass on "bridge" regions (i.e., question for reasoning, reasoning for summary) does not fall below a soft threshold. When collapse is detected, attention logits are shifted group-wise to maintain sufficient bridge mass, preventing early lock-in and context neglect.
- Step Momentum Injection (SMI): In deep layers, at reasoning step boundaries, a residual summary vector is computed from the value states of the preceding step and injected into the starting token of the next step. This mechanism counteracts the observed deep-decay effect, preserving earlier reasoning context until the summary is produced.
Empirical analysis shows that StepFlow does not merely regularize the model: accuracy gains are tightly localized to benchmarks and error types predicted by Step-Saliency patterns; shallow/deep split selection matches diagnostic leverage; and improvements are explained by restored information propagation, not altered knowledge content.
Empirical Results
StepFlow was evaluated on the DeepSeek-R1-Distill (7B/14B/32B), GPT-OSS-20B, and QwQ-32B-Preview architectures across six demanding benchmarks in mathematics, science, and code (AIME24, AIME25, AMC23, MATH-500, GPQA-Diamond, LiveCodeBench). The intervention strictly modifies only a quarter of layers at both ends (shallow/deep), and is computation-efficient (30-37% overhead relative to baseline decoding).
Highlights include:
- Error correction analysis: Across AIME 24/25, StepFlow converts a substantial proportion of propagation errors (arithmetic carry-forward: 34–38%, premise forgetting: 30–42%), while rarely correcting conceptual errors, confirming the specificity of the methodology.
- Accuracy gains: For example, StepFlow yields +11.8 points on AIME25 for R1-Distill-32B, +9.5 on LiveCodeBench for GPT-OSS-20B medium—a magnitude not matched by prompt modifications, increased decoding length, or self-consistency methods at equivalent compute.
- Compute normalization: At equivalent runtime cost, StepFlow achieves improvements 5–8× greater than simply generating longer outputs, and outperforms majority-vote self-consistency even with more samples.
Step-Saliency maps before and after StepFlow intervention, both case-wise and aggregate, demonstrate enhanced question→thinking and thinking→summary connectivity, validating the causal link between repaired information flow and improved LRM reasoning.
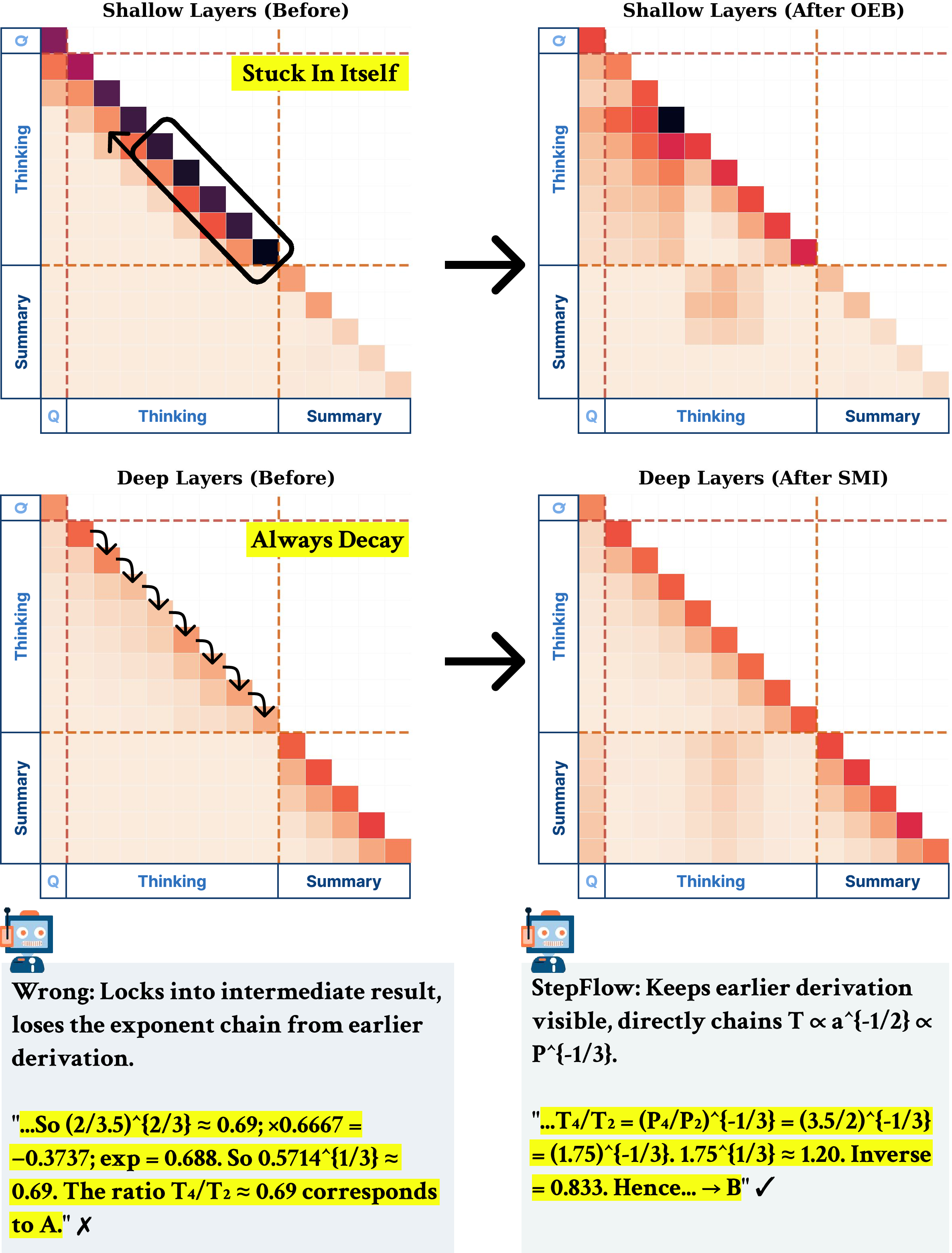
Figure 4: StepFlow reduces shallow local self-loops and restores deep summary→thinking connections in an error trace, visualized via Step-Saliency.
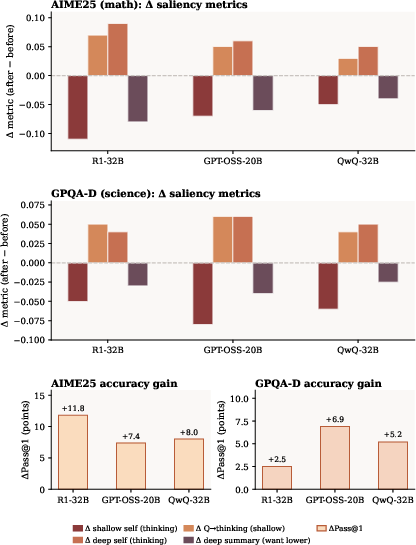
Figure 5: On two complex benchmarks, StepFlow decreases shallow thinking and deep summary self-reinforcement, increasing question→thinking transfer and overall accuracy.
Practical and Theoretical Implications
Practically, StepFlow is immediately deployable as a lightweight, single-pass improvement for LRMs, requiring neither model retraining nor architectural modifications. Its compatibility with other decoding-time interventions and synergistic gains when paired with self-consistency sampling highlight its composability.
Theoretically, the step-level diagnostic and targeted repair framework advances the mechanistic interpretability of large transformers. The separation of information-flow (propagation, memory) failures from conceptual (reasoning, knowledge) errors fosters new approaches to modular diagnostic and repair tools. Future work may generalize Step-Saliency to finer- or coarser-grained decompositions, or extend interventions to head-level or value-space projections.
This approach also invites studies isolating memory versus reasoning deficits in LLMs: StepFlow repairs only the flow of intermediate results and premises, not misapplied domain knowledge; further interventions may need to address faithfulness and trace verification.
Conclusion
The study systematically diagnoses where reasoning fails within LRM traces as a breakdown of information propagation (quantified by Step-Saliency) and demonstrates that targeted interventions (StepFlow) can restore cross-step flow and significantly improve multi-step reasoning accuracy. This work provides both diagnostic clarity and a practical repair protocol, with implications for model interpretability, evaluation, and deployment across reasoning-intensive AI applications.