- The paper introduces SHAPE, a framework that leverages potential estimation and stage-aware segmentation to enhance LLM reasoning, achieving a 3% improvement in accuracy.
- It employs entropy-based segmentation and a dynamic, length-dependent discount factor to provide precise token-level credit assignment while reducing token consumption by 30%.
- The approach enforces logical brevity and balanced reward distribution, effectively preventing overthinking and degenerate outputs in multi-step reasoning tasks.
SHAPE: Stage-aware Hierarchical Advantage via Potential Estimation for LLM Reasoning
Motivation and Background
LLMs have demonstrated substantial potential in complex multi-step reasoning tasks, particularly in mathematical problem solving. Reinforcement Learning (RL) is widely adopted for post-training these models, but standard outcome-based RL methods (such as Group Relative Policy Optimization, GRPO) are fundamentally constrained by sparse reward signals, undermining effective credit assignment and leading to phenomena like overthinking or inefficient, verbose output. The paradigm of process supervision—providing intermediate, denser rewards—has gained traction, though existing rule-based and learned reward frameworks (e.g., Process Reward Models, PRMs) exhibit notable limitations in annotation cost, vulnerability to reward misalignment, and incomplete alignment with desirable reasoning properties.
The SHAPE (Stage-aware Hierarchical Advantage via Potential Estimation) framework addresses these gaps by formalizing LLM reasoning as navigation in a state space measured via empirical solvability, introducing a notion of "reasoning potential" (Φ) as an explicit progress indicator. SHAPE unifies three critical desiderata for optimal reasoning: maximizing substantial logical breakthroughs (potential gain), prioritizing breakthroughs when uncertainty is highest (stage awareness), and enforcing computational efficiency via brevity (token efficiency). The fundamental insight is that reward shaping in LLM RL must be both stage-adaptive and hierarchical, with credit assignment mechanisms that operate at both the segment and token levels.
Framework and Methodology
SHAPE advances the process supervision paradigm through precise, theoretically motivated innovations in segmentation, reward shaping, and credit assignment:
Reasoning Trajectory Segmentation and Potential Estimation
SHAPE employs an entropy-based segmentation protocol, identifying boundary points in generated reasoning chains where token-level predictive entropy surges, capturing semantic transitions corresponding to pivotal logical decision points. At each segment boundary sk, potential Φ(sk) is estimated via a batch of forced-termination rollouts, which are scored for binary correctness and averaged, providing an empirical measure of partial solvability. The approach leverages prefix caching to curtail computational overhead, and experiments confirm that a relatively small number of segments (e.g., K=8) achieves strong trade-offs between granularity and cost.
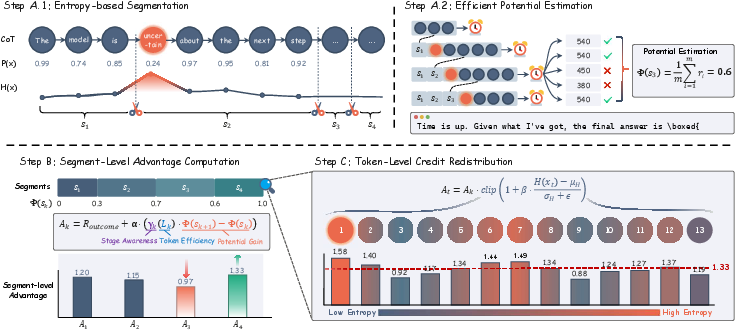
Figure 1: SHAPE pipeline, from entropy-based segmentation and potential estimation to hierarchical credit assignment.
Segment-Level Hierarchical Advantage
SHAPE conceptualizes reasoning as a Markov Decision Process (MDP) over segments, extending Potential-Based Reward Shaping (PBRS) with a dynamic, length-dependent discount factor γk(Lk). This formulation awards segments according to:
Ak=Routcome+α(γk(Lk)⋅Φ(sk+1)−Φ(sk))
where γk decays linearly with segment length Lk, subject to a lower bound γmin derived analytically to avoid undermining learning progress. This ensures that longer or verbose segments are penalized unless justified by substantial potential gains, while breakthroughs from low-potential states are proportionally rewarded, establishing a rigorous token efficiency bias. The decomposition into "gain" and "tax" formalizes how stage awareness is encoded: potential gains from earlier, low-confidence stages contribute more to the final outcome than marginal refinements in near-complete states.
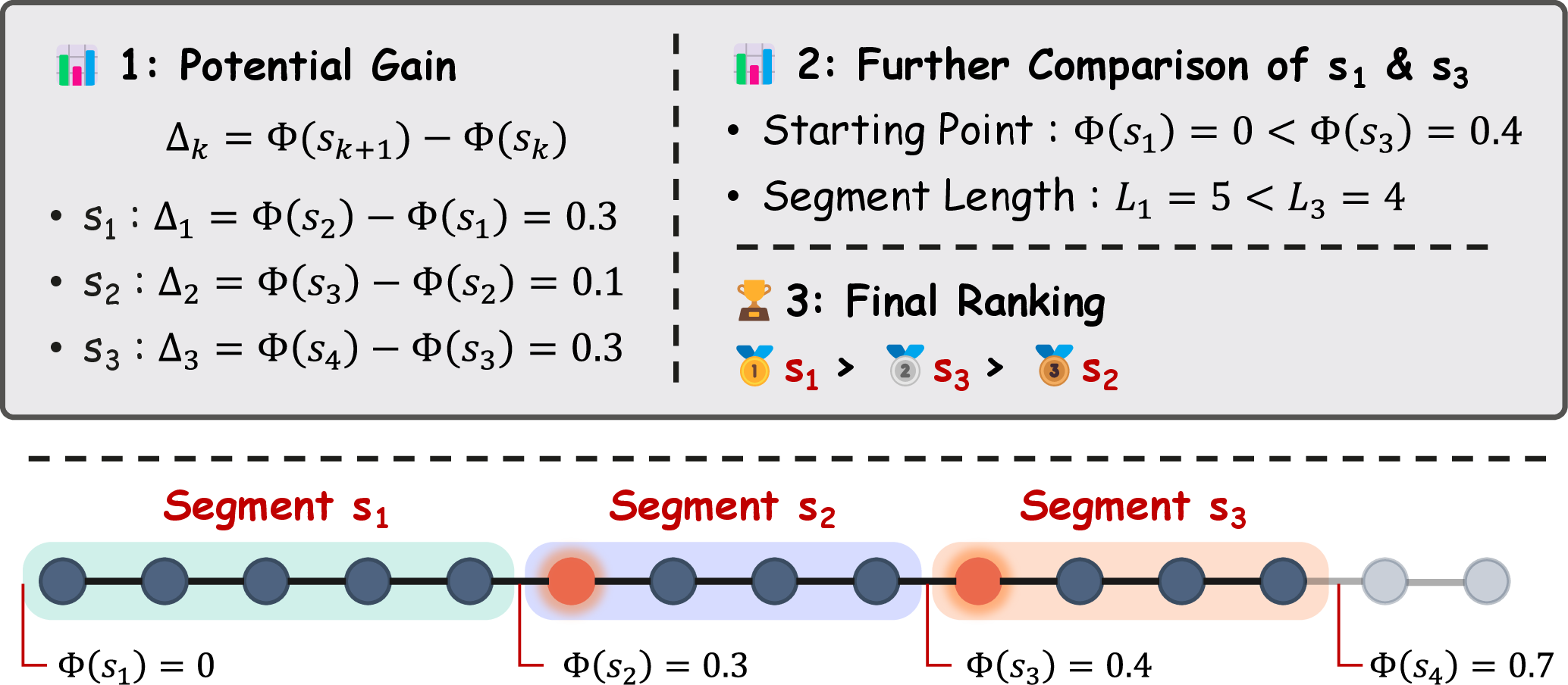
Figure 2: Optimal reasoning path illustration, highlighting stage awareness and efficiency; s1 maximizes both criteria through efficient, early breakthroughs.
Token-Level Entropy-Driven Redistribution
At the sub-segment level, SHAPE further sharpens the learning signal through token-level credit redistribution. Rather than distributing advantage uniformly across a segment, local token entropy is used for Z-score normalization, amplifying credit at high-uncertainty decision tokens or logical pivots. This refinement focuses learning on critical steps in the trajectory and prevents uniform dilution of the reward signal, promoting better local reasoning accuracy.
Empirical Results
Experiments are conducted across three representative LLM architectures (DeepSeek-R1-Distill-Qwen-1.5B, DeepScaleR-1.5B-Preview, Qwen3-4B) and five established mathematical reasoning benchmarks. The results are robust:
- SHAPE achieves an average accuracy gain of approximately 3% compared to both outcome-based (GRPO) and prior process-based (MRT) baselines.
- Simultaneously, SHAPE reduces token consumption by about 30% across tasks, setting a new Pareto frontier in the accuracy-efficiency spectrum.
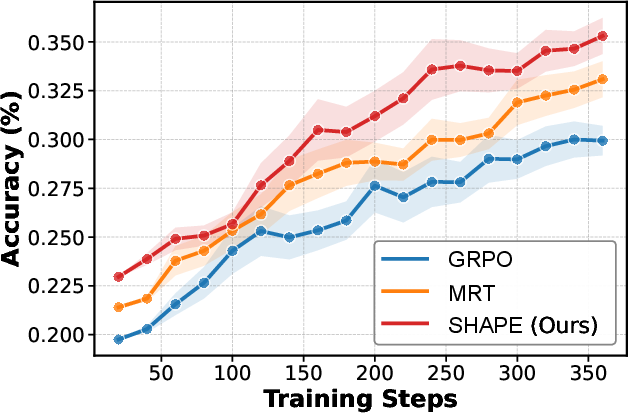
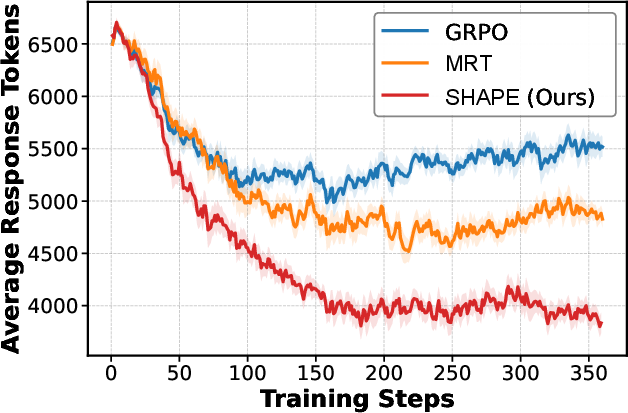
Figure 3: Accuracy trajectory of SHAPE versus GRPO and MRT on AIME 24; SHAPE sustains significantly higher final accuracy.
SHAPE also demonstrates improvements on out-of-distribution (OOD) tasks (GPQA Diamond, LiveCodeBench) and coding tasks, indicating that its inductive biases towards logical conciseness and stage-aware progress generalize beyond mathematical reasoning.
Analysis and Ablation
Sensitivity analysis reveals that potential gains from low-starting-potential states yield marginally higher returns on final task success than equivalent gains in high-potential states (~18% higher marginal utility), empirically motivating the stage-aware mechanism.
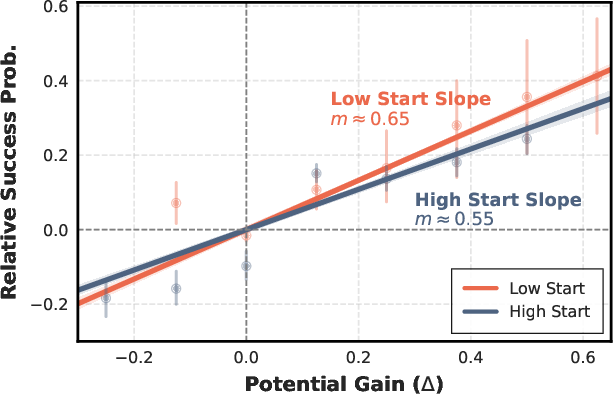
Figure 4: Marginal effect of potential gains—regression slope significantly steeper for low-potential starts, confirming the increased value of breakthroughs.
Strategic sandbagging, where an agent can artificially degrade intermediate state potential to later recover for cumulative reward, is effectively eliminated by the local, monotonic PBRS-based shaping; SHAPE shows a low, consistent rate of negative progress, unlike MRT.
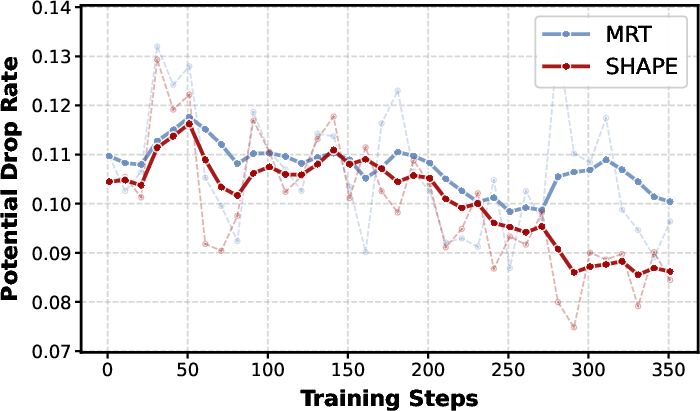
Figure 5: Potential drop rate per segment transition—SHAPE maintains monotonic progress while MRT exhibits volatility and late-stage spikes due to sandbagging.
Ablation studies demonstrate that both entropy-based segmentation and token-level redistribution are necessary: omitting either feature leads to marked performance drops. Furthermore, setting the discount lower bound sk0 too low leads to learning collapse by inverting positive reward attribution for correct progress; a theoretical lower bound is derived and experimentally validated.
Segmentation granularity analysis uncovers that performance gains saturate beyond sk1; higher sk2 only increases training cost without further benefit, confirming the efficient design of the segmentation protocol.
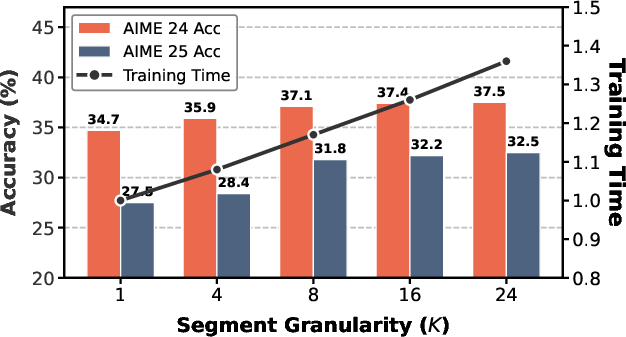
Figure 6: Trade-off between segmentation granularity and computational cost; sk3 is a strong optimum.
In hard tasks, SHAPE is shown to prevent degenerate "reasoning collapse," where models under other supervision frameworks hit the maximum context length, producing non-convergent outputs.
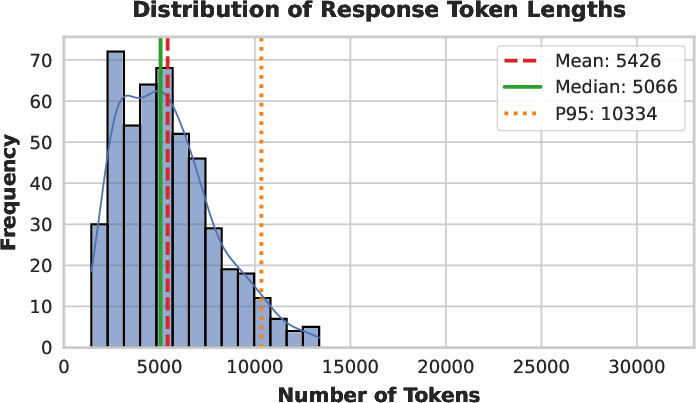
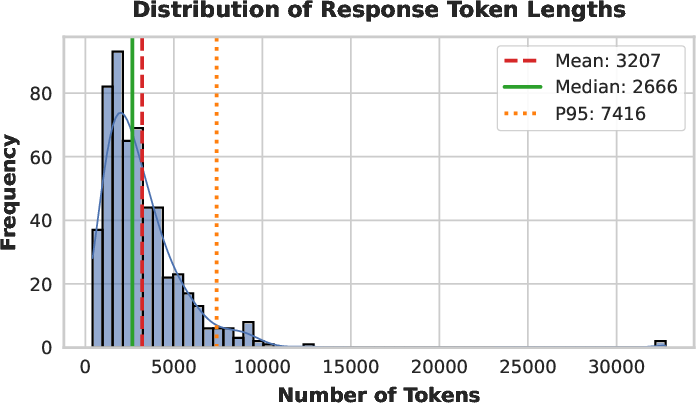
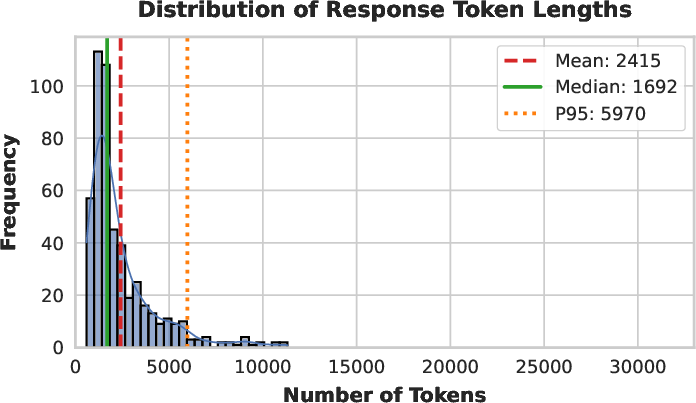
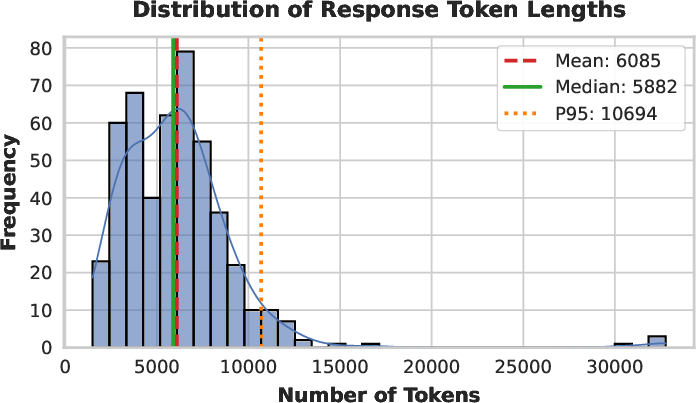
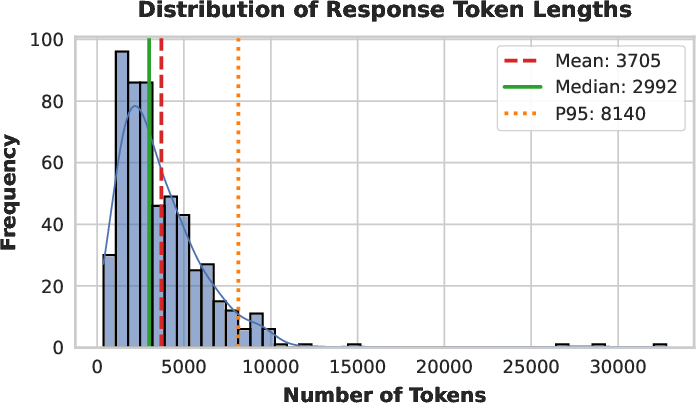
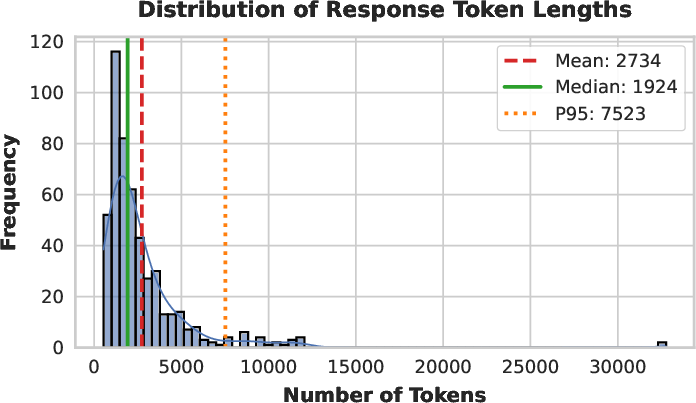
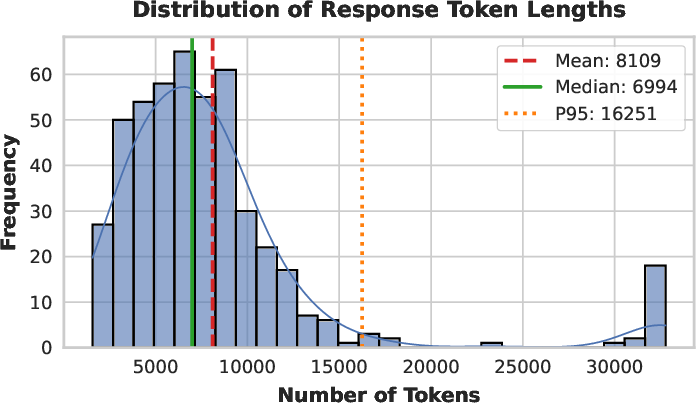
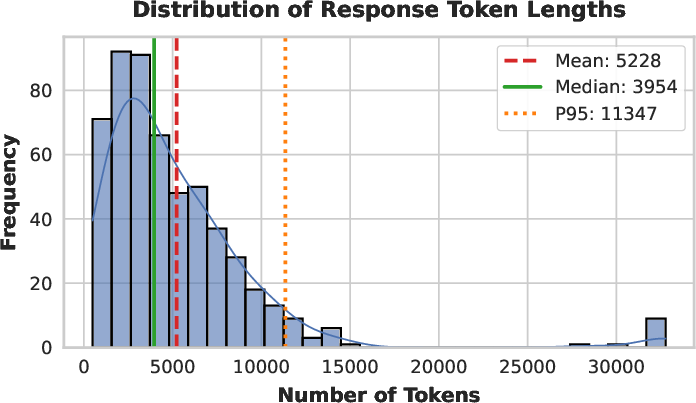
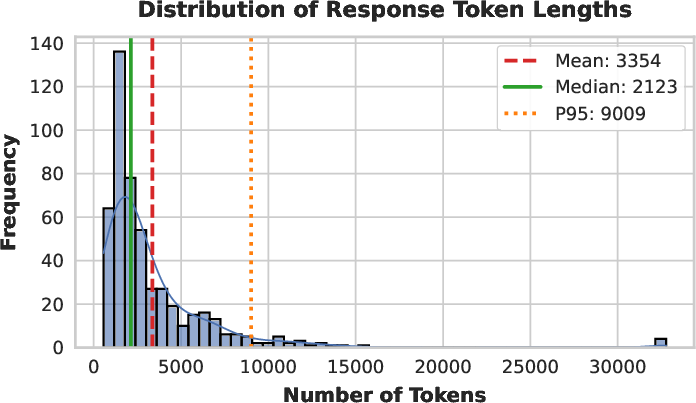
Figure 7: Distribution of token lengths on AIME 2025—SHAPE produces long-tail, well-calibrated solutions without anomalous spikes at length limits.
Theoretical and Practical Implications
Theoretically, SHAPE grounds its shaping mechanism in proven PBRS theory but systematically modifies it to encode efficiency and logic progression in a manner that preserves reward sign consistency and outcome dominance. This results in a framework that avoids known pitfalls of previous methods (sparse reward misspecification, verbosity, and reward hacking) while offering a formal guarantee that correct, efficient solutions always outscore incorrect or verbose ones within certain parameter regimes.
Practically, SHAPE's dual focus on accuracy and token economy makes it highly suitable for real-world deployment scenarios where computational cost and interpretability are critical, such as automated mathematical tutors, code synthesis, or scientific problem solving. Its hierarchical design is poised for extension to broader LLM domains, particularly those with well-specified partial credit or semantic progression structure.
Future Directions
Key limitations lie in SHAPE's reliance on the deterministic verifiability of mathematical tasks, where potential estimation is unambiguous. Adapting the framework to open-ended, subjective tasks (creative writing, open-domain coding) would require significant advances in the robust quantification of intermediate reasoning quality. Extensions to automatic segmentation and adaptive potential estimation in such tasks represent an important research vector, as does analysis of transfer to much larger LLM backbones and integration with other RL reward structures.
Conclusion
SHAPE establishes a systematic, theoretically-sound, and empirically validated process supervision paradigm for LLM reasoning. By unifying stage awareness, efficiency, and token-level refinement via reasoning potential estimation and dynamic discounting, SHAPE achieves superior accuracy and efficiency compared to both outcome- and prior process-supervised methods. The architecture is broadly transferable to other structured progression tasks and presents a robust foundation for future advances in LLM-based reasoning systems.
Reference: "SHAPE: Stage-aware Hierarchical Advantage via Potential Estimation for LLM Reasoning" (2604.06636)

