- The paper introduces a unified five-phase pipeline for human motion video generation, integrating multimodal inputs and LLM-based motion planning for semantic control.
- The paper analyzes various generative frameworks including diffusion models, GANs, and VAEs, highlighting trade-offs in fidelity, efficiency, and control.
- The paper identifies open challenges such as data scarcity, photorealism, and real-time deployment, providing a comprehensive roadmap for future research.
Human Motion Video Generation: A Comprehensive Survey
Introduction and Scope
Human motion video generation has rapidly evolved, driven by advances in generative modeling and the increasing demand for photorealistic digital humans in applications such as virtual avatars, entertainment, and human-computer interaction. This survey provides a systematic taxonomy and technical review of over 200 works, unifying the field under a five-phase pipeline: input, motion planning, motion video generation, refinement, and output. The review covers vision-, text-, and audio-driven modalities, with a particular emphasis on the integration of LLMs for motion planning—a dimension previously underexplored.
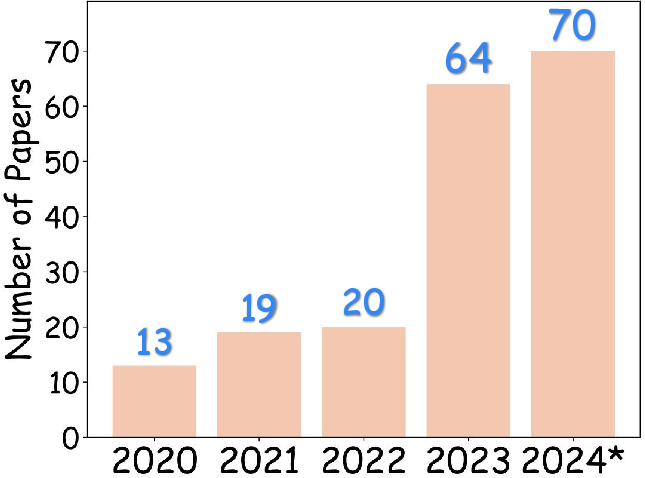
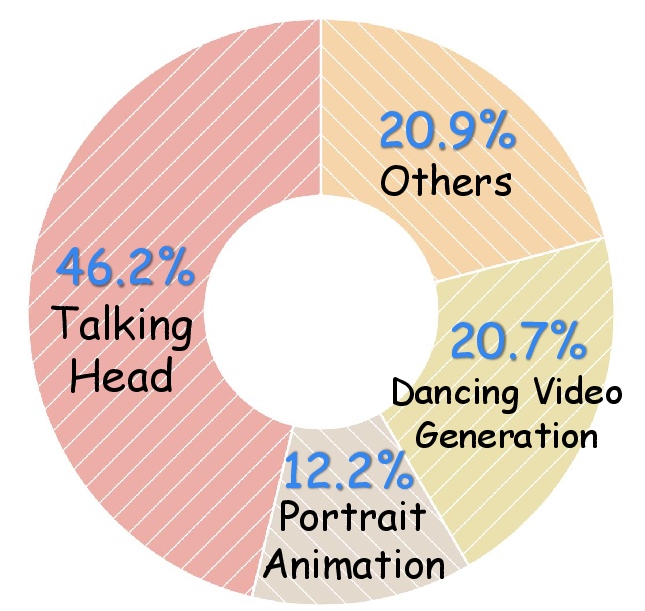
Figure 1: Quantity of papers in the four categories reviewed in this survey, showing rapid growth in human motion video generation, emphasizing key areas such as talking head and dance videos. (2024
denotes the period from Jan. to Aug. in 2024.)*
The Five-Phase Pipeline
The survey introduces a unified pipeline for human motion video generation, which is critical for understanding the interplay between different modalities and technical components:
- Input: Multimodal signals (vision, text, audio) are identified as driving sources.
- Motion Planning: Input signals are mapped to motion plans, either via feature mapping or LLM-based reasoning.
- Motion Video Generation: Generative models synthesize video sequences from planned motions.
- Refinement: Post-processing enhances fidelity, synchronizes details, and corrects artifacts.
- Output: Focuses on cost reduction, real-time streaming, and practical deployment.
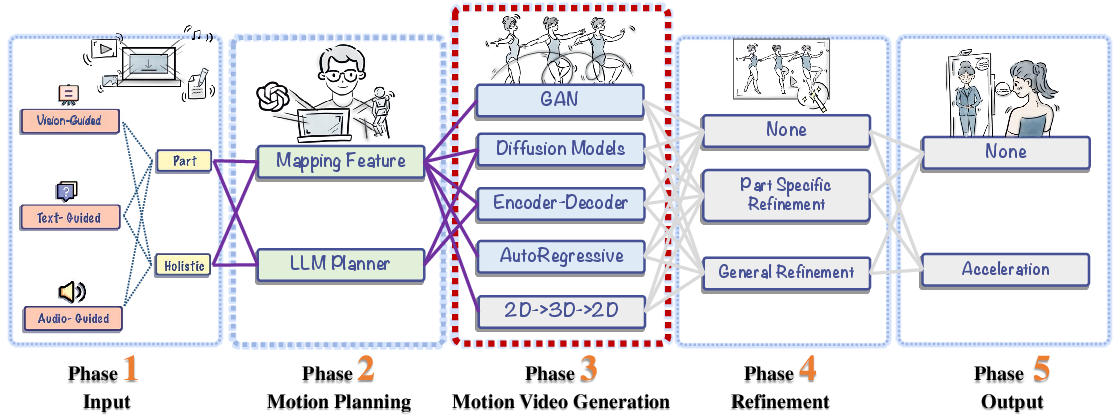
Figure 2: Pipeline of generating human motion videos, which can be divided into five key phases, from input to real-time deployment.
This decomposition enables a modular analysis of the field, facilitating targeted improvements and benchmarking.
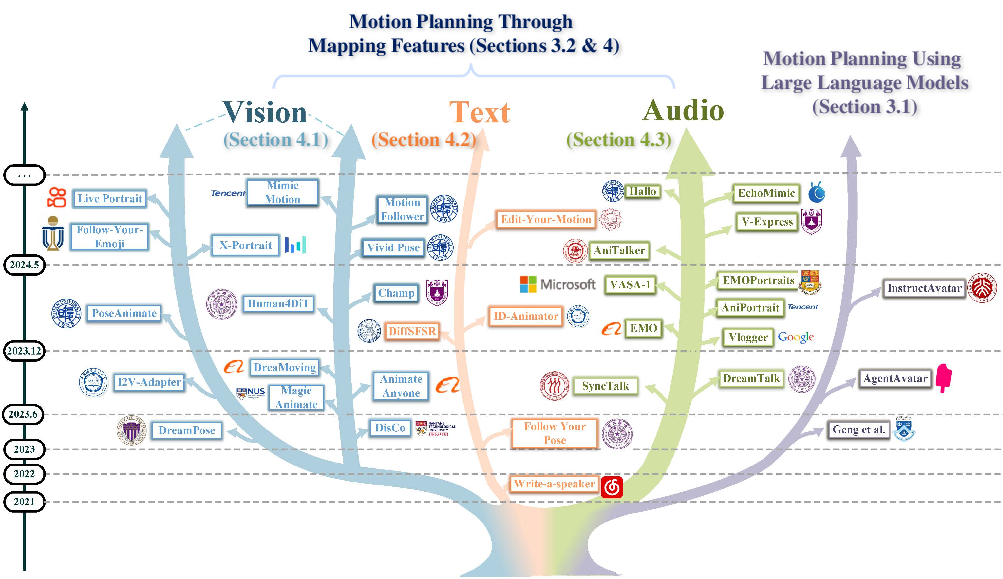
Historical Trends and Modalities
The field has seen exponential growth, particularly in talking head and dance video generation. The survey categorizes methods by their dominant modality:
This taxonomy clarifies the landscape and highlights the increasing complexity and multimodality of recent approaches.
Generative Frameworks and Human Data Representations
The survey provides a technical review of the main generative frameworks:
- VAE: Used for encoding reference images, but limited by mode collapse and sample sharpness.
- GANs: Achieve high-quality outputs but suffer from mode collapse and limited diversity.
- Diffusion Models (DMs): Currently dominant due to their distribution coverage and scalability, though computationally expensive. Latent diffusion models (LDMs) mitigate some of these costs.
Human data representations are categorized into mask, mesh, depth, normal, keypoint, semantics, and optical flow, each with specific trade-offs in spatial fidelity, control, and computational cost.
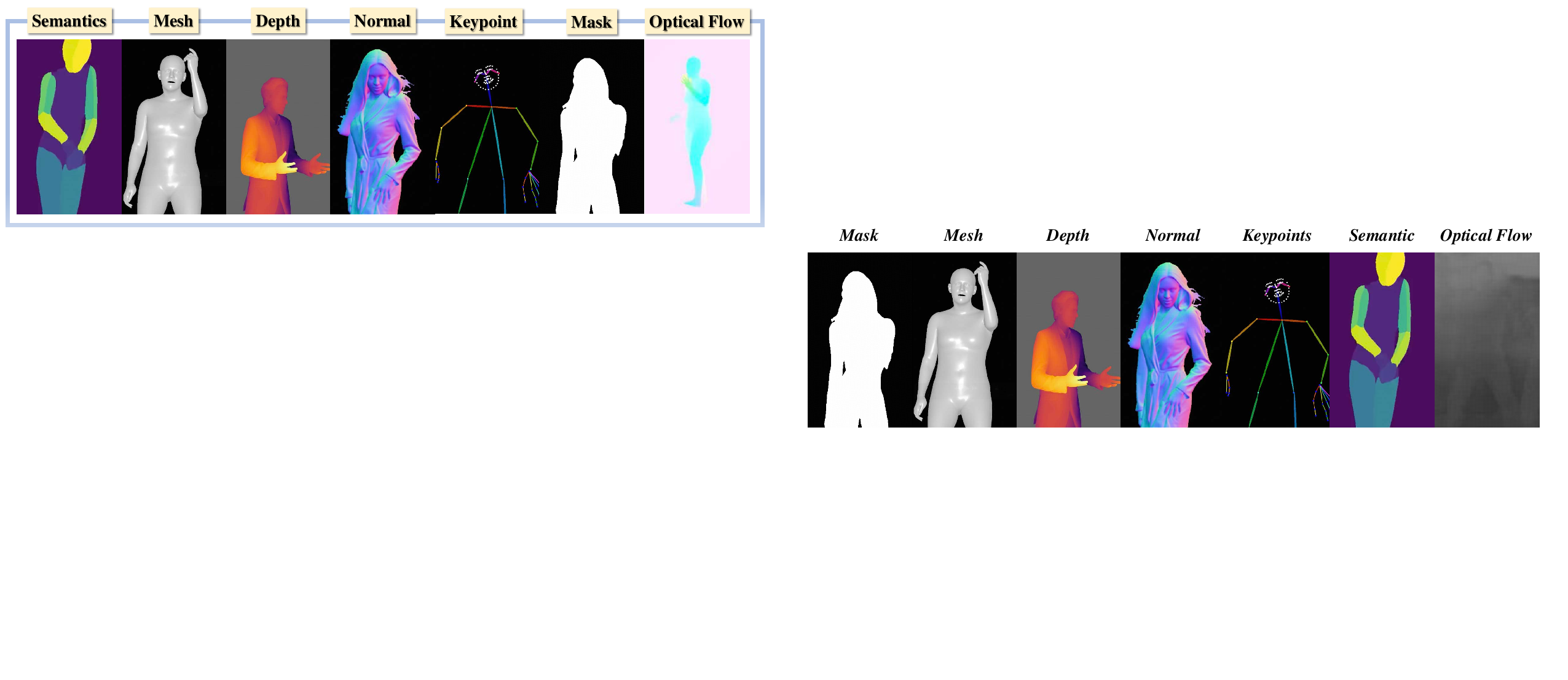
Figure 4: Different human data representations.
Motion Planning: LLMs and Feature Mapping
A key contribution of the survey is the detailed analysis of motion planning strategies:
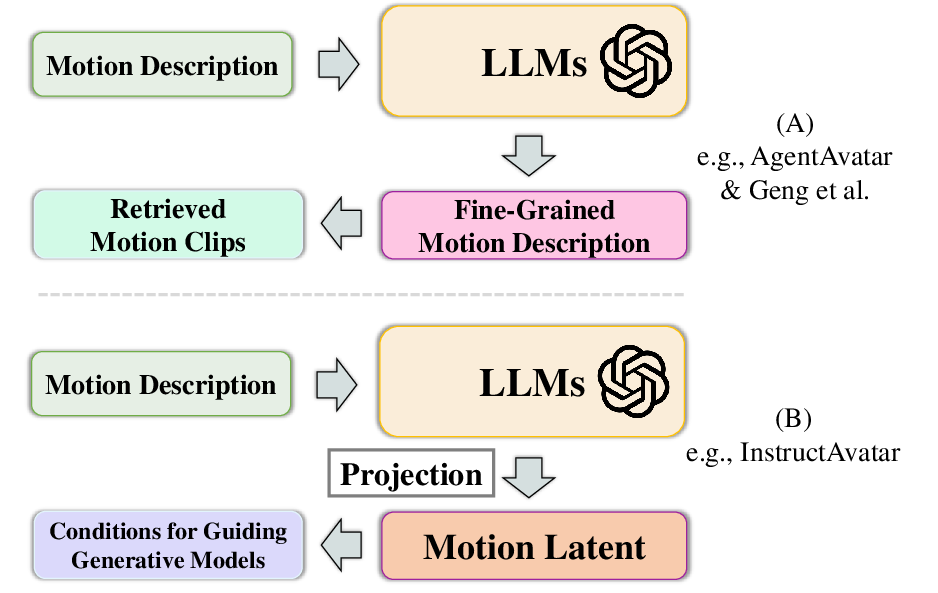
- LLM-based Planning: LLMs are leveraged for semantic understanding and reasoning, enabling fine-grained motion planning from high-level instructions or dialogue. Two paradigms are identified:
- Feature Mapping: Most current works still rely on implicit feature mapping between input conditions and motion, often with stochasticity for diversity.
The survey highlights the underutilization of LLMs as motion planners and the need for more expressive intermediate representations beyond text or codebooks.
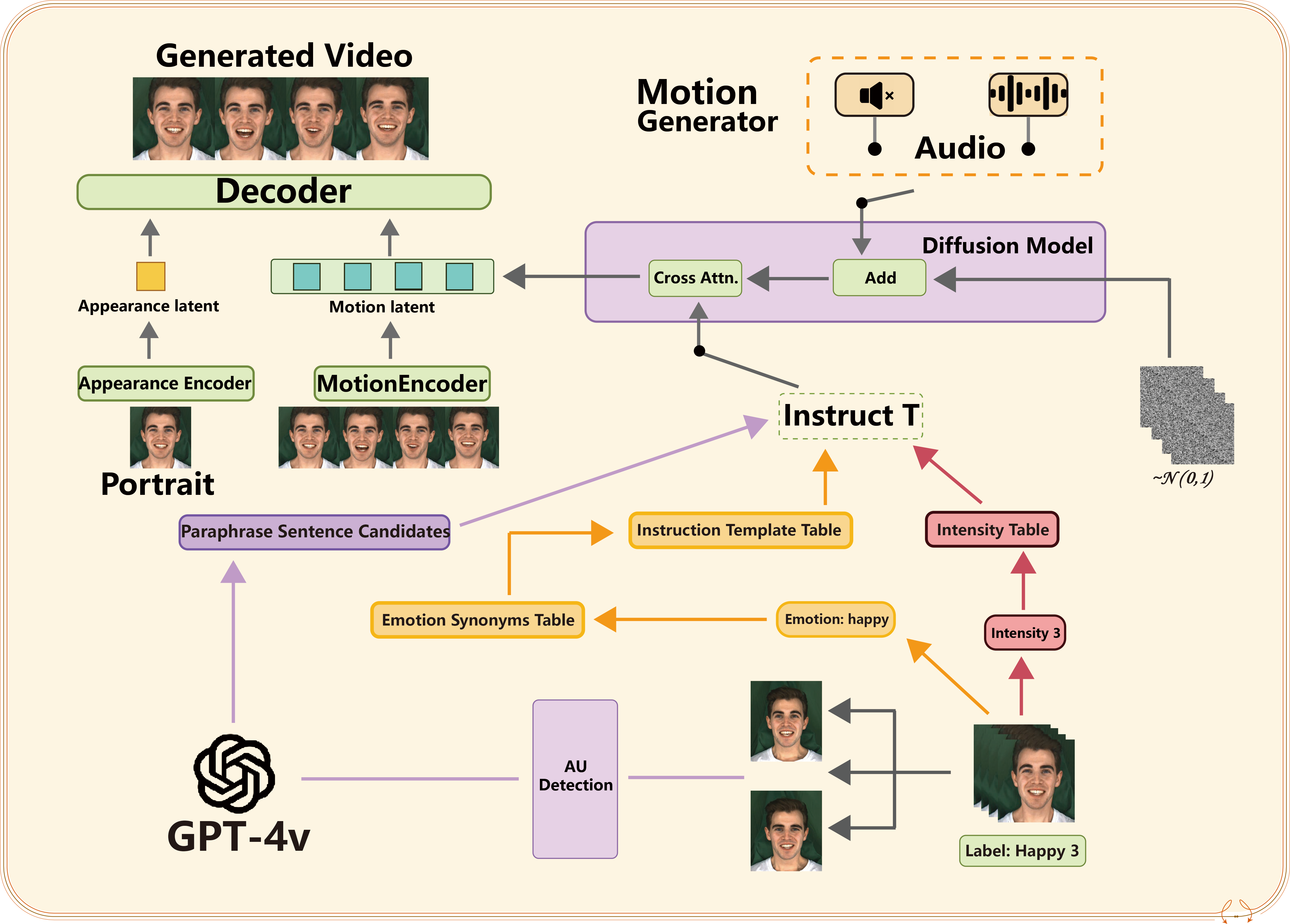
Figure 6: Overview of InstructAvatar, which employs GPT-4 and diffusion models for video generation, producing expressive and dynamic videos that are synchronized with audio input.
Motion Video Generation: Diffusion Model Architectures
The survey provides a granular taxonomy of diffusion-based video generation frameworks:
- Pure Noise Input: Main diffusion branch starts from noise; reference images are encoded via ReferenceNet or feature encoders. ControlNet is often used for conditioning.
- Reference Image Input: Noise is added to the reference image; guided conditions are encoded separately.
- Guided Condition Input: Noise is added to the guided condition; reference images are encoded for appearance.
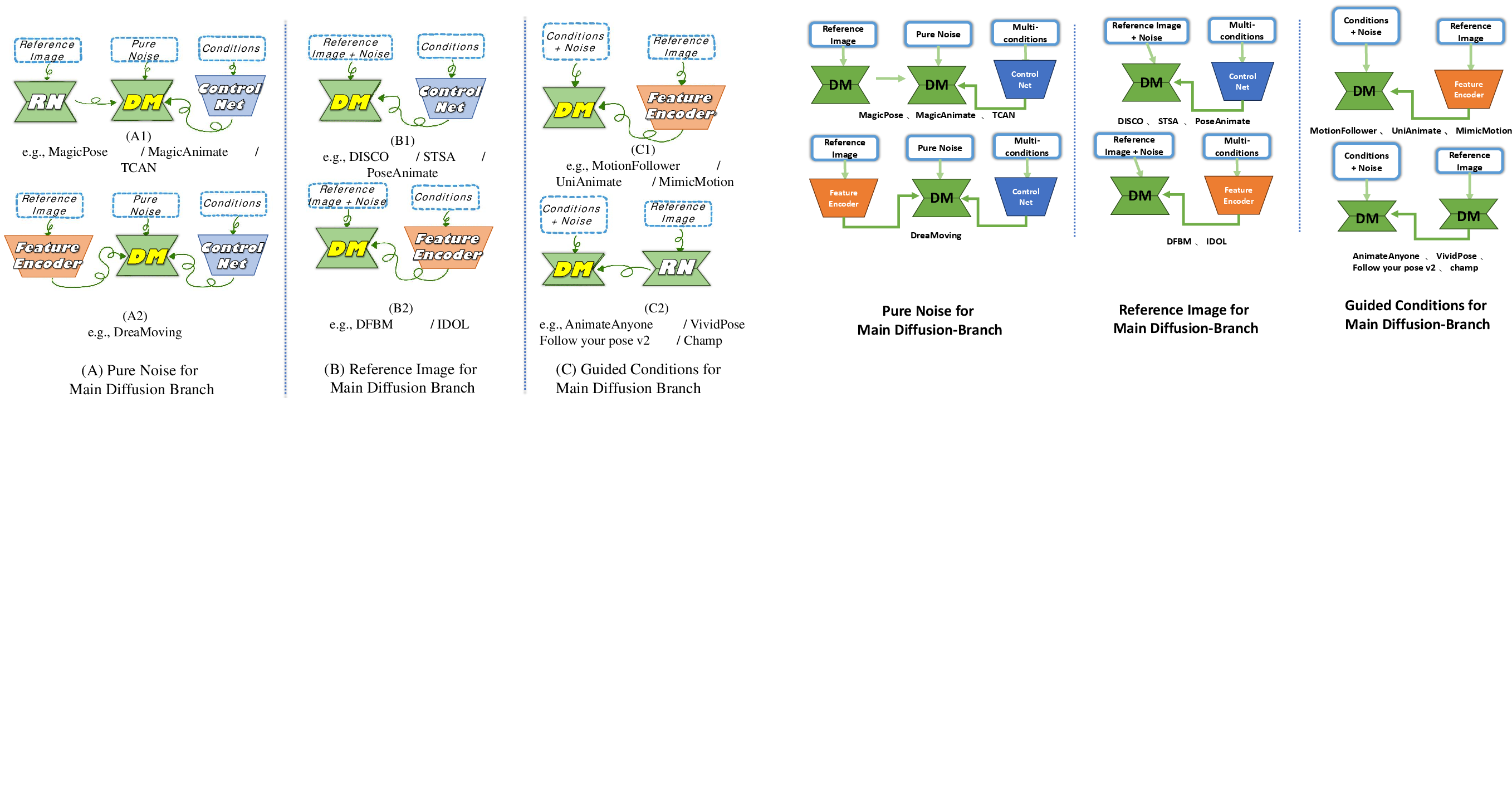
Figure 7: Comparative overview of different generative frameworks based on diffusion models, where pure noise (A), a reference image (B), and guided conditions (C) are for the main diffusion branch.
Attention mechanisms are further classified (e.g., intra-frame, inter-frame, cross-frame), with hierarchical and cross-frame attention improving temporal consistency at the cost of increased computation.
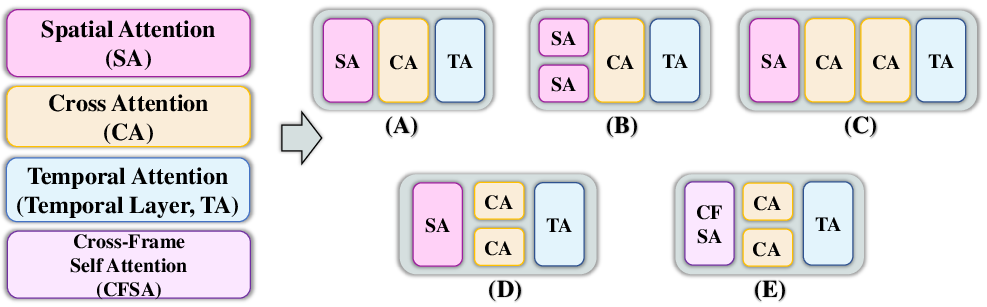
Figure 8: Different attention fusion methods of diffusion-based vision-driven human motion video generation.
Subtasks and Technical Challenges
Vision-Driven
- Portrait Animation: Focuses on facial expression control, with challenges in gaze, teeth, and multi-person driving.
- Dance Video Generation: Pose-driven and video-driven methods face challenges in pose extraction accuracy, temporal consistency, and few-shot learning.
- Try-On and Pose2Video: Require robust appearance and motion disentanglement.
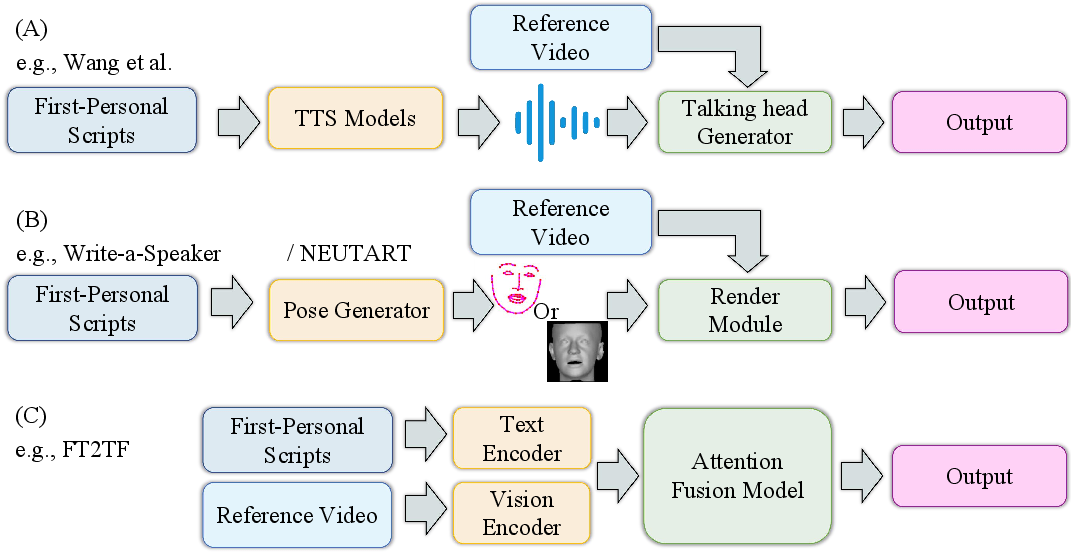
Text-Driven
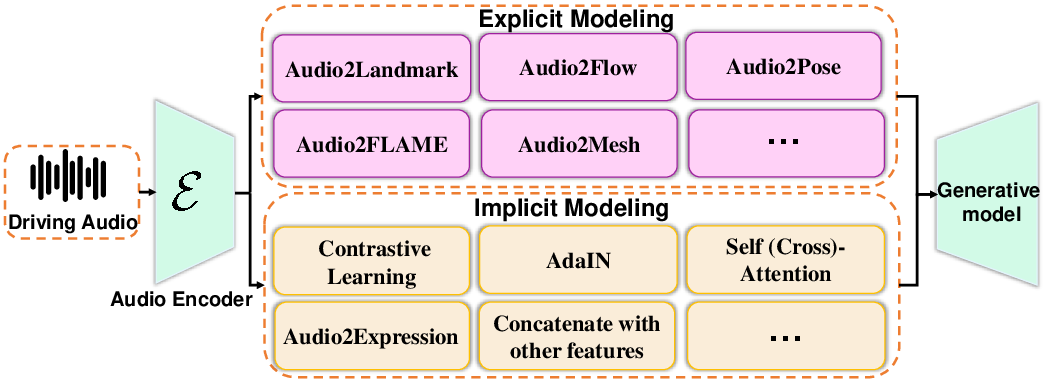
Audio-Driven
Refinement and Output
Refinement is divided into part-specific (e.g., hand, mouth, eye) and general (super-resolution, denoising) strategies. Real-time generation remains challenging, especially for diffusion models, with ongoing research in model distillation and stream-based inference.
Evaluation and Benchmarking
The survey reviews evaluation metrics at the frame, video, and characteristic levels, noting the lack of a unified standard. LLM planner evaluation is nascent, relying on retrieval metrics and CLIP scores.
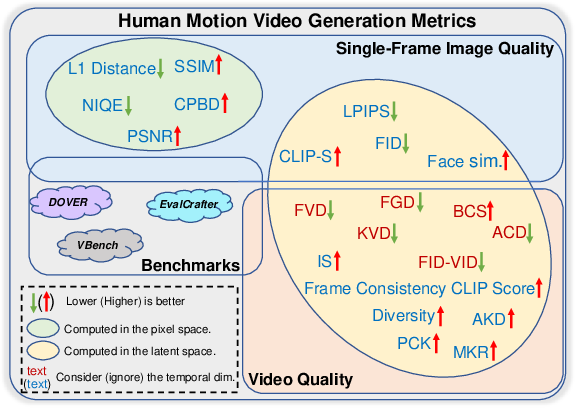
Figure 11: Overview of common metrics in human motion video generation.
A comparative analysis of nine open-source pose-guided dance video generation methods reveals that MagicAnimate achieves the highest SSIM and PSNR, while UniAnimate excels in LPIPS, FID, and FID-VID, indicating trade-offs between structural fidelity and perceptual/temporal quality.
Datasets
A curated list of 64 datasets is provided, spanning head, half-body, and full-body data, with annotations on modality, resolution, and task suitability. Data scarcity, privacy, and diversity remain major bottlenecks.
Open Challenges and Future Directions
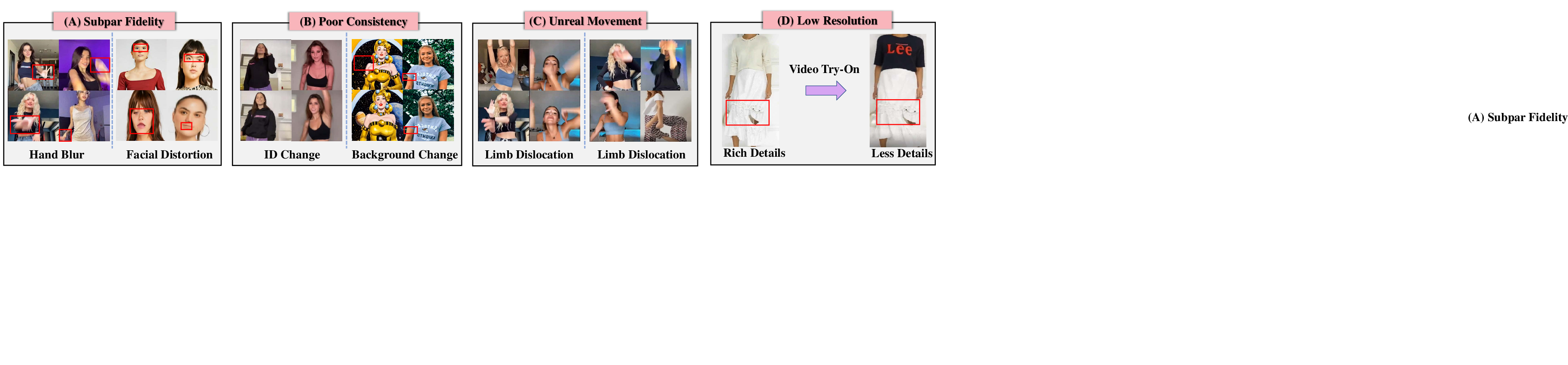
Figure 12: Main challenges in human motion video generation: subpar fidelity with examples like hand blur and facial distortion, poor consistency with identity and background changes, unrealistic movements, and low resolution.
Key challenges include:
- Data Scarcity: Privacy and collection costs limit dataset size and diversity.
- Motion Planning: Current methods lack semantic depth; LLMs offer promise but require better intermediate representations and evaluation.
- Photorealism and Consistency: Fidelity in faces/hands, temporal coherence, and physically plausible motion remain unsolved.
- Duration and Control: Extending video length and achieving fine-grained control over all body parts is an open problem.
- Real-Time and Cost: Diffusion models are computationally intensive; efficient architectures and distillation are needed.
- Ethics: Privacy, consent, and accountability for digital humans require robust frameworks.
Conclusion
This survey establishes a comprehensive taxonomy and technical roadmap for human motion video generation, highlighting the centrality of diffusion models, the emerging role of LLMs in motion planning, and the persistent challenges in data, fidelity, and real-time deployment. The field is poised for further advances in semantic motion planning, efficient generative modeling, and ethical deployment, with significant implications for digital human applications across domains.