Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Abstract: Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.

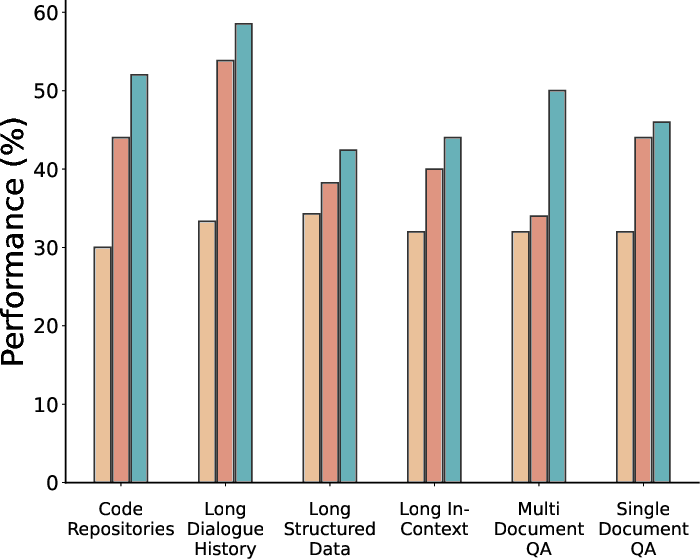
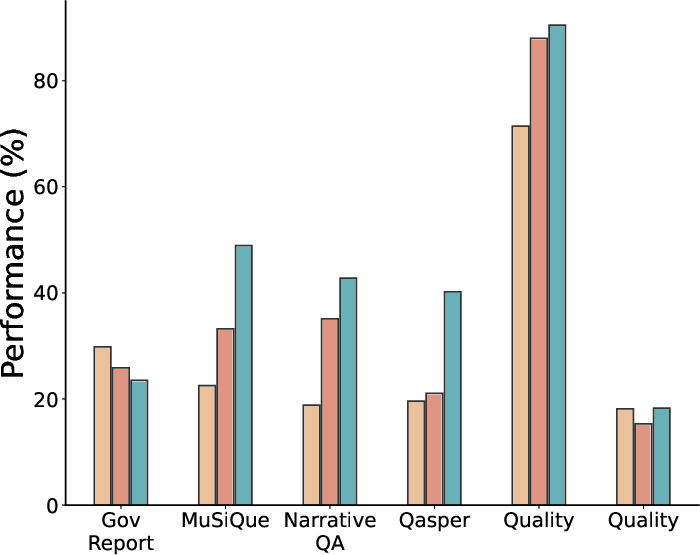
 just put things in Context: Test-Time Training for Long-Context LLMs")
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a problem with LLMs when they read very long inputs—like big codebases, long chats, or multi-document articles. Even if the important information is “in context,” the model often fails to find and use it. The authors show why common tricks, like making the model “think out loud” by generating extra reasoning tokens, don’t fix this at long lengths. Then they introduce a simple, faster way to help the model on the fly: a tiny bit of training during inference called query-only test-time training (qTTT). It changes how the model looks for evidence in the given long input so it can spot the right information more reliably.
Key Questions
- Why do LLMs struggle when the input is very long, even if the answer is somewhere in the text?
- Do “thinking tokens” (extra generated reasoning) help with long inputs?
- Can we use our compute better at inference by briefly adapting the model to the current input, instead of just generating more text?
- If so, what’s a simple, fast way to do that?
How Did They Test Their Ideas?
The problem in simple terms
- Think of the model’s attention like a spotlight trying to find a “needle” (the important bit) in a giant “haystack” (lots of other text).
- As the haystack grows, there are more distractors. Even if the correct spot is slightly brighter, the spotlight gets spread thin across many almost-bright spots. The model’s focus on the needle fades.
The authors call this “score dilution.” The model uses a math function (softmax) to spread attention weights across all tokens. If many tokens look similarly relevant, the correct token’s share gets tiny. They prove that as the input length T grows, the correct token needs to stand out by a gap that grows roughly like log(T) to keep enough attention on it. That’s hard to guarantee with fixed model weights.
Why “thinking tokens” don’t solve long-context problems
- “Thinking tokens” are extra steps where the model writes out reasoning before answering.
- But those tokens are generated using the same attention mechanism and the same weights. If the model never focused on the right evidence in the first place, these extra steps can’t magically pull in what it missed. They found thinking tokens help a bit for shorter inputs but show diminishing returns as the input gets very long.
A different approach: query-only test-time training (qTTT)
- Instead of generating more text, do a few tiny training steps during inference that adapt the model to this specific input.
- LLM attention uses three pieces: keys (K), values (V), and queries (Q). You can think of:
- Keys/values as the “library shelves” and “books” created from the input.
- Queries as the “search questions” the model uses to find relevant books on those shelves.
- qTTT:
- Runs the long input once to build and cache the keys and values (the shelves and books).
- Keeps those shelves/books fixed.
- Makes a few small updates only to the query matrices (the search questions), using short spans from the input and a standard “predict the next token” loss.
This is fast because you don’t re-encode the whole input each time. You reuse the cached keys/values and only adjust how you ask the model to look for information.
Everyday analogy
- If you’re in a huge library and you keep asking vague questions, you’ll get lost.
- qTTT is like quickly tuning your question style to match how the library is organized, so your queries point to the right shelf more strongly. You don’t move the shelves (keys/values); you just change how you ask (queries).
Main Findings
Here are the main results explained in accessible terms:
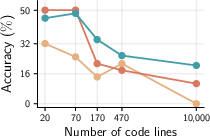
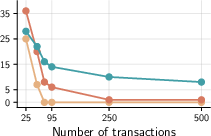
- On controlled tasks like:
- Finding a bug hidden in a large code repository.
- Spotting a single error in long transaction logs.
- as the input length grows, normal in-context performance drops sharply. Thinking tokens help only for shorter inputs and then plateau.
- They prove why: with fixed attention, the correct spot needs to stand out more and more (roughly like log of the input length). Otherwise, attention gets spread too thin over many near-distractors (score dilution).
- qTTT directly boosts the separation between the correct spot and distractors by adjusting queries to match the cached keys/values for this specific input. This increases the model’s focus on the right evidence.
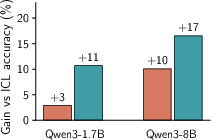
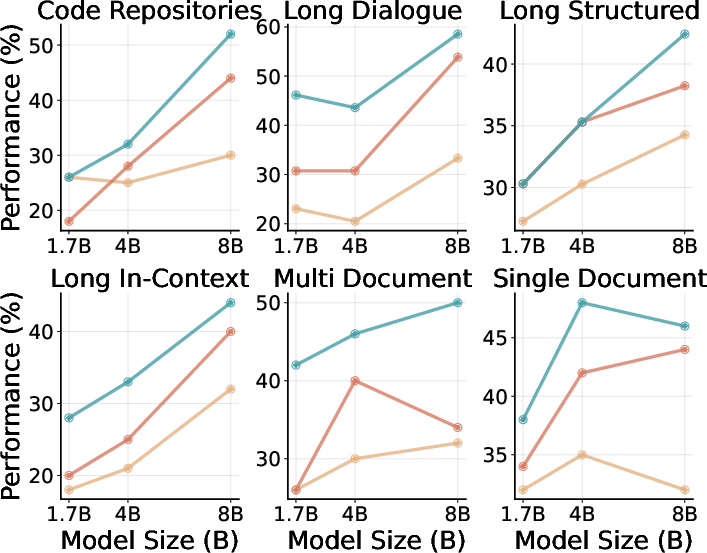
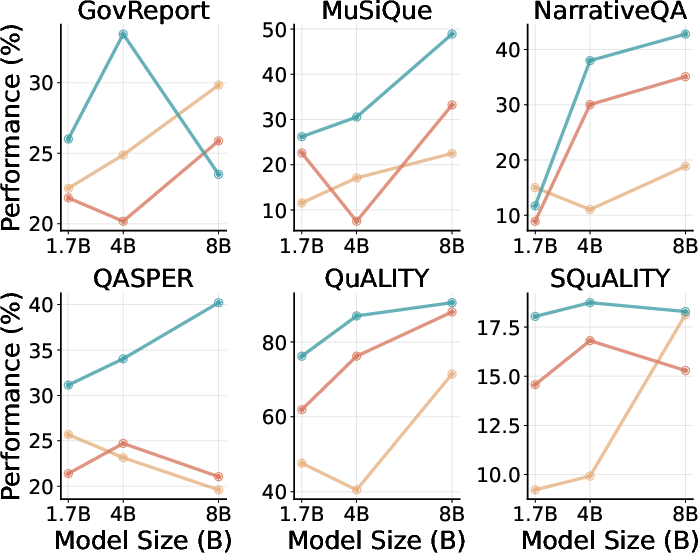
- Across 15+ real-world long-context datasets (LongBench-v2 and ZeroScrolls) and Qwen3 models sized 1.7B to 8B:
- qTTT consistently improves scores versus normal decoding and versus thinking tokens when both spend the same compute budget.
- Improvements are especially strong on tasks that need retrieving and combining evidence from long inputs (like multi-document question answering and code comprehension).
- Reported average improvements include roughly +12.6 and +14.1 percentage points for Qwen3-4B on subsets of LongBench-v2 and ZeroScrolls.
In short: With the same compute, briefly adapting the model’s queries is more effective than generating lots of “thinking” text for long-context tasks.
Why It’s Important
- Many real uses of LLMs involve long contexts: big codebases, long chats, multi-file projects, or multiple articles. Models often “lose” relevant info in the middle.
- This paper explains a root cause (score dilution) and shows that the popular fix—produce more reasoning tokens—doesn’t reliably work at very long lengths.
- qTTT gives a practical alternative: spend a small amount of compute to adapt the model to the current input, focusing its attention where it matters, without retraining the whole model or changing its architecture.
- It can be combined with other long-context techniques (like special attention patterns or retrieval augmentation), since qTTT only adjusts queries during inference.
Takeaway and Impact
- For long inputs, don’t just “put everything in context” and hope more thinking tokens will solve it.
- Instead, use a small amount of test-time training on queries (qTTT) to sharpen the model’s focus on the right parts of the input.
- This can make LLMs more reliable for tasks like:
- Debugging across multi-file codebases.
- Answering questions that require reading multiple documents.
- Tracking details across long conversations or logs.
- The approach is compute-efficient, easy to add at inference, and leads to solid gains across benchmarks—making it a practical improvement for long-context LLM applications.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These are framed to guide actionable follow-up research.
- External validity across model families and scales:
- qTTT is only evaluated on Qwen3 (1.7B–8B). Does it generalize to other architectures (e.g., Llama, Mixtral/MoE, Phi, DeepSeek) and to larger (>8B) or sparse/MoE models?
- Interaction with alternative attention architectures and position encodings:
- Effects on sparse/linear attention (Longformer, BigBird, RWKV, Hyena) and on positional schemes (ALiBi, RoPE variants like YaRN/LongRoPE) are untested.
- Ultra-long contexts and memory feasibility:
- Practicality at million-token windows is unclear given KV-cache memory scales with T. What are the VRAM/latency trade-offs for T ≳ 105–106?
- Theory beyond single-layer, single-head abstractions:
- The score-dilution and margin results are analyzed at the level of a single attention layer/head. How do bounds and guarantees change with full transformer stacks, residuals, multi-head interactions, and MLPs?
- Sufficiency of budgeted updates:
- While qTTT locally increases the margin, there is no guarantee it can reach the required Ω(log T) margin within a realistic update budget. What are convergence rates and step-complexity to meet target margins as T grows?
- Typical-case vs worst-case analysis:
- Theoretical results emphasize worst-case near-tie distractors. What are typical-case bounds under realistic distractor distributions (e.g., long-tailed, clustered, topical coherence)?
- Optimal parameter subsets to update:
- Only W_Q is adapted. Could selective updates (head-wise, layer-wise), bias-only, scaling/gating of heads, or low-rank adapters outperform W_Q-only? When (if ever) are K or V updates beneficial despite cache invalidation?
- Span sampling strategy and coverage:
- qTTT uses random contiguous spans. What span selection policies (salience heuristics, gradient-based sampling, retrieval-guided spans) yield better margin gains per FLOP?
- Budget scheduling and hyperparameter sensitivity:
- The paper fixes (k, N_TTT) at a single operating point. How should span length, number of steps, learning rate, and per-layer update budgets be scheduled adaptively across inputs and lengths?
- When to invoke qTTT:
- No decision rule is provided to detect “retrieval-limited” inputs. Can we predict ex ante whether to spend compute on qTTT vs thinking tokens vs neither?
- Robustness and adversarial settings:
- Behavior under adversarial or highly structured distractors is untested. Can gradient steps overfit to spurious distractors or amplify misleading signals?
- Side effects on generation quality and calibration:
- Limited gains on summarization tasks hint at generation bottlenecks. Does qTTT harm fluency, factuality, or calibration on tasks not primarily retrieval-limited?
- Serving-time safety, isolation, and privacy:
- Per-request gradient updates on user contexts pose risks (weight contamination across sessions, gradient leakage, privacy). How to sandbox updates (e.g., ephemeral adapters) and quantify privacy leakage?
- System-level performance beyond FLOPs:
- FLOP parity omits memory bandwidth, activation checkpointing, and kernel efficiency. What are realistic latency/QPS trade-offs on commodity GPUs for prefill+qTTT vs decoding-heavy baselines?
- KV-cache staleness and decoding dynamics:
- Updating W_Q leaves K/V fixed; during decoding, queries change per token while keys/values are frozen. How does this affect stability, cache reuse, and error accumulation over long generations?
- Compatibility with RAG and tool use:
- The paper claims composability with RAG but provides no experiments. Does qTTT improve retrieval quality, re-ranking, or fusion-in-decoder settings, and how should it be integrated with retrievers?
- Comparison to stronger inference-time baselines:
- Compute-matched comparisons to self-consistency, best-of-n with re-ranking, or speculative decoding are limited or deferred to the appendix. A comprehensive, rigorously compute-matched suite remains open.
- Cross-lingual, multimodal, and domain robustness:
- Evaluations are primarily English and text-only. How does qTTT fare in multilingual, code-switched, or multimodal (vision/text) long-context settings?
- Realistic, large-scale code and enterprise logs:
- Synthetic “bug localization” and “transaction logs” approximate tasks but may not capture real repository structures, logging noise, or heterogeneity. Can gains replicate on SWE-bench, LiveCodeBench, or real ops logs?
- Detecting and monitoring margin improvements:
- There is no online metric to confirm that qTTT increased effective margins on relevant needles. Can we design proxy diagnostics (e.g., attention coherence, retrieval attribution) to guide or early-stop qTTT?
- Regularization and stability of updates:
- What regularizers (weight decay on W_Q, proximal/elastic updates, trust-region, orthogonality or low-rank constraints) best prevent overfitting or drift?
- Persistence and reuse of adaptations:
- Are per-input W_Q updates reusable across similar documents/sessions? How to cache and index per-context adapters safely and efficiently?
- Energy and carbon impacts:
- The energy footprint of prefill+qTTT vs extensive “thinking token” decoding is not measured. What are energy-optimal allocations of inference-time compute for long-context workloads?
- Reproducibility and release:
- Full code, hyperparameters, and the synthetic dataset generators are not made available in the paper body. Open-sourcing these assets would enable fair replication and extension.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams that control their inference stack (weights access, KV caching, gradient updates). They leverage qTTT’s ability to reallocate inference-time compute toward query-only updates that increase target–distractor margins in long contexts.
- Code intelligence in large repositories
- Sectors: software, developer tools
- Use cases: bug localization across multi-file repos; cross-file code comprehension; API/definition finding; automated code review with precise evidence citation.
- Tools/workflows: IDE assistants or CI bots that (1) prefill a long repo snapshot, (2) run a small number of qTTT steps on sampled code spans, (3) answer dev prompts; repo QA endpoints in code search platforms; SWE-bench-style evaluation harnesses with qTTT toggles.
- Assumptions/dependencies: long-context model + KV cache; ability to run gradients and update W_Q only; ephemeral reset of adapted weights per query; GPU memory sufficient for the prefill; open-weights or on-prem serving.
- Log analysis and incident response
- Sectors: SRE/DevOps, cybersecurity, finance (payments), enterprise IT
- Use cases: anomaly detection in transaction or event logs; tracing causality across long traces; RCA with evidence highlighting.
- Tools/workflows: observability platforms add a “qTTT mode” to long-log questions; SOAR/SECOPS playbooks call a qTTT-adapted LLM before answering; financial reconciliation pipelines flag and explain inconsistent entries.
- Assumptions/dependencies: same as above, plus privacy guardrails (ephemeral adaptation, no persistent learning from sensitive logs).
- Multi-document QA and knowledge synthesis
- Sectors: enterprise search, legal, research, media
- Use cases: answering questions over collections (policies, wikis, contracts, briefs); literature synthesis with cited spans; discovery requests.
- Tools/workflows: RAG + qTTT hybrid—retrieve many candidate docs into a large context, then perform qTTT to sharpen cross-doc retrieval before answering; citation-aware prompt templates.
- Assumptions/dependencies: long-context inference already in use; small qTTT budget (e.g., 8–32 steps over k=128–512 spans) under existing compute limits; careful span sampling over the concatenated corpus.
- Long-history conversational agents
- Sectors: customer support, CRM, productivity
- Use cases: agents that must recall details from hundreds of prior turns; summarizing prolonged threads; contextually consistent follow-ups.
- Tools/workflows: conversation state stored as long context; single prefill of chat history; lightweight qTTT before response generation; automatic on/off switch based on a retrieval-difficulty heuristic (e.g., entropy/attention spread).
- Assumptions/dependencies: controllable inference server; latency budget to accommodate prefill + a few qTTT steps.
- Contract and policy analysis
- Sectors: legal, compliance, procurement
- Use cases: clause retrieval across attachments; cross-referencing amendments; policy change impact analysis.
- Tools/workflows: document management systems add a qTTT inference path for complex queries; redlining assistants that reliably surface buried clauses.
- Assumptions/dependencies: on-prem or VPC deployment for confidential documents; ephemeral updates and audit logs; human review.
- Research assistants over large corpora
- Sectors: academia, R&D
- Use cases: systematic reviews; multi-paper comparison; extracting methods/results across long PDFs or notes.
- Tools/workflows: literature copilot that performs one prefill on a user-selected bundle (papers, notes) and runs qTTT before answering; evidence-linked outputs.
- Assumptions/dependencies: PDF-to-text normalization; memory for million-token prefill if very large bundles are used (or chunked with smart concatenation).
- Enterprise summarization with hard retrieval
- Sectors: operations, governance, PMO
- Use cases: summarizing long meeting transcripts with references; executive briefs requiring details scattered across minutes and docs.
- Tools/workflows: QMSum-style pipelines with a qTTT step that improves retrieval before drafting; citation markers linked to source spans.
- Assumptions/dependencies: gains are largest when retrieval is the bottleneck (less so for pure surface-level summarization); tuned (k, N_TTT) schedules.
Long-Term Applications
These applications are promising but require further research, scaling, or ecosystem support (APIs for ephemeral adaptation, million-token serving, governance tooling).
- Ephemeral adaptation as a managed cloud feature
- Sectors: cloud AI platforms, MLOps
- Use cases: API-level “qTTT mode” that updates only query projections per request while keeping base weights hidden; FLOP-metered billing for adaptation vs thinking tokens.
- Tools/workflows: serving stacks (e.g., vLLM-like) that preserve KV across updates; KV-preserving optimizers; autoschedulers that choose between thinking tokens and qTTT by predicting retrieval difficulty.
- Assumptions/dependencies: platform support for secure, per-request ephemeral deltas; isolation and rollback; cost/latency SLAs.
- Million-token enterprise memory with retrieval guarantees
- Sectors: enterprise AI, legal discovery, intelligence analysis
- Use cases: reasoning over corpora at 105–106 tokens with predictable retrieval under distractors; verifiable citation pipelines.
- Tools/workflows: coupling qTTT with sparse/sliding attention, rotary scaling, or memory-augmented architectures; runtime monitors of logit margins and attention concentration; proactive qTTT scheduling at segments with high dilution.
- Assumptions/dependencies: hardware and kernels optimized for extremely long prefills; memory-efficient KV storage; formalized “margin health” telemetry.
- Safety-critical decision support over EHRs
- Sectors: healthcare
- Use cases: longitudinal patient timeline synthesis; cross-visit medication reconciliation; focused retrieval of rare adverse events.
- Tools/workflows: hospital on-prem LLMs run qTTT on full EHR context before generating clinician-facing notes; strict citation and uncertainty reporting.
- Assumptions/dependencies: rigorous clinical validation; regulatory compliance; robust privacy (no persistent adaptation); bias and safety audits.
- Financial compliance and audit at scale
- Sectors: finance, audit, regtech
- Use cases: scanning years of trades/transactions for anomalies, policy breaches, or control failures with fine-grained evidence.
- Tools/workflows: audit copilots that run qTTT for targeted retrieval across long ledgers and communications; explainable flags with supporting spans.
- Assumptions/dependencies: integration with secure data lakes; chain-of-custody for outputs; regulator-acceptable evaluation protocols.
- Robust long-context agents and tool use
- Sectors: software robotics, automation
- Use cases: agents that plan with long memories (logs, configs, codebases) and reliably fetch the right evidence before acting.
- Tools/workflows: agent frameworks add a “retrieve→qTTT-adapt→act” loop; combine with programmatic retrieval, memory indexing, and guardrails.
- Assumptions/dependencies: better policies for span sampling; dynamic budgets for (k, N_TTT); failure detection and fallback strategies.
- Educational long-course tutors
- Sectors: education, edtech
- Use cases: tutors that reason over months of student interactions, notes, and assignments; personalized feedback referencing prior work.
- Tools/workflows: privacy-preserving, on-device or school-hosted LLMs that adapt ephemerally via qTTT before each session; teacher dashboards showing cited history.
- Assumptions/dependencies: robust privacy controls; explainability; content alignment for minors; compute constraints on school hardware.
- Retrieval-aware model governance
- Sectors: policy, AI assurance
- Use cases: auditing long-context systems for “lost-in-the-middle” failures; certifying retrieval fidelity under distractor load.
- Tools/workflows: margin-based diagnostics; synthetic score-dilution stress tests; standardized benchmarks and reporting for long-context reliability.
- Assumptions/dependencies: community benchmarks and consensus metrics; regulator adoption; interpretability tooling tied to attention/margin analytics.
Cross-cutting assumptions and dependencies
- Technical
- Access to model weights and ability to compute gradients at inference time (not typically available via pure SaaS LLM APIs).
- KV caching over long contexts; sufficient GPU memory/throughput for the initial prefill; inference stack that supports updating W_Q only and resetting deltas per request.
- Span sampling strategy matters (coverage of likely evidence); budgets for (k, N_TTT) must be tuned to latency/cost constraints; watchdogs to prevent overfitting to local noise.
- Safety, privacy, and operations
- Ephemeral adaptations must be discarded after the response; enforce tenant isolation; log adaptation metadata for audit.
- In regulated domains (healthcare/finance), validation and human oversight are required; ensure no persistent learning from sensitive data.
- Monitoring for prompt injection or malicious context artifacts that could steer gradient steps; robust defenses and fallbacks.
- External feasibility
- Results shown on Qwen3 1.7B–8B; behavior may vary for other families or very large models; additional evaluations advisable.
- Gains are largest when retrieval is the bottleneck; for generation-limited tasks (e.g., some summarization), qTTT may offer smaller returns compared to model or decoding improvements.
Glossary
- Adaptive positional encoding: Techniques that modify how position information is represented to improve long-context handling. "adaptive positional encoding"
- Attention kernel: The specific functional form of attention used to compute interactions among tokens in a sequence. "the same attention kernel as in~\cref{eq:attn}"
- Attention logits: The unnormalized similarity scores between queries and keys before softmax in attention. "gives the attention logits "
- Attention weights: The normalized coefficients (via softmax) that determine how much each value contributes to the output. "attention weights "
- Autoregressive setting: A generation setup where each token is predicted based only on past tokens. "In the autoregressive setting, causal masking enforces "
- Beam search: A decoding algorithm that keeps multiple candidate sequences to improve output quality. "best-of-N and beam search"
- Best-of-: An inference-time strategy that samples multiple outputs and selects the best one according to a score. "best-of-"
- Causal masking: A constraint in autoregressive transformers preventing attention to future positions. "causal masking enforces "
- Chain-of-thought: Prompting that elicits step-by-step intermediate reasoning tokens before the final answer. "chain-of-thought “thinking” tokens"
- Decoding (compute scaling): Spending extra inference-time compute by generating more tokens rather than changing model parameters. "primarily scale decoding"
- Distractors: Irrelevant tokens whose logits compete with the true evidence in attention, causing dilution. "All other positions are distractors"
- Finite-precision self-attention: Self-attention operating under finite numerical precision, implicated in long-context failures. "static, finite-precision self-attention"
- FLOP equivalence: A compute-matching relation comparing the cost of thinking tokens and query-only updates. "FLOP equivalence (\autoref{app:flops}) yields the rule of thumb"
- FLOP-matched: Using equal floating-point operation budgets when comparing different inference-time strategies. "Under FLOP-matched inference-time compute budgets"
- Gradient descent: An optimization method used here at inference time to update specific parameters (queries). "perform $N_{\text{TTT}$ steps of gradient descent"
- In-context learning (ICL): The ability of LLMs to adapt to tasks by conditioning on examples in the input without parameter updates. "in-context learning (ICL;"
- Key–value cache (KV cache): Stored keys and values from a prefill pass, reused to avoid recomputing attention over long contexts. "reusing the KV cache"
- Key–value pair: A specific key and value vector at a position that may contain the relevant evidence (“needle”). "key–value pair (the `needle')"
- Logarithmic margin requirement: The needed growth (Ω(log T)) in target–distractor logit gap to maintain non-vanishing attention on the target as context grows. "logarithmic margin requirement---the worst-case targetâdistractor logit gap must scale as "
- Logit margin: The difference between the target logit and the log-sum-exp of distractor logits. "denote the logit margin."
- LongBench-v2: A benchmark suite assessing long-context reasoning across diverse context types. "LongBench-v2 provides a testbed to evaluate long-context abilities across a diverse set of context types."
- “Lost in the middle” effect: A phenomenon where models under-attend to evidence placed in the middle of long contexts. "yielding the ``lost in the middle\" effect"
- Multi-head attention: Parallel attention computations across different subspaces to capture diverse dependencies. "Multi-head attention extends this computation across several subspaces"
- Multi-hop reasoning: Tasks requiring the model to retrieve and combine multiple pieces of evidence. "multi-hop reasoning tasks."
- Needle-in-a-haystack: Evaluations where a small relevant span is buried among many distractors in long sequences. "Needle-in-a-haystackâstyle tests show"
- Prefill: An initial forward pass over the entire input to compute and cache keys/values for later reuse. "Perform a single prefill to cache keys and values"
- Query-only test-time training (qTTT): An inference-time adaptation that updates only query projections while reusing cached keys/values. "Query-only test-time training uses inference-time compute more effectively than \"thinking\" tokens for long contexts."
- Query projection matrices: The learned weights that map hidden states to queries in attention; updated in qTTT. "query projection matrices"
- Retrieval augmented generation (RAG): Methods that incorporate retrieved external documents into generation. "retrieval augmented generation"
- RoPE scaling: Extending context length by scaling rotary positional embeddings. "via RoPE scaling"
- Score dilution: The phenomenon where many near-tie distractors reduce attention mass on the true target. "We attribute these failures to score dilution, a phenomenon inherent to static self-attention."
- Self-consistency: An inference-time strategy that samples multiple reasoning paths and aggregates answers. "self-consistency and best-of-"
- Sliding window attention: An architectural change that restricts attention to a local window to reduce quadratic cost. "sliding window attention"
- Softmax: The normalization function converting logits into attention weights. "normalized via softmax"
- Static attention mechanism: Using the same (unchanged) attention parameters during inference, even when generating extra tokens. "the same static attention mechanism that is already under-allocating mass to the evidence."
- ZeroScrolls: A benchmark suite evaluating long-context tasks such as multi-hop QA, summarization, and comprehension. "ZeroScrolls~\citep{shaham2023zeroscrolls} evaluates a diverse set of tasks"
Collections
Sign up for free to add this paper to one or more collections.