- The paper introduces a dual-agent framework that assigns dedicated Researcher and Developer roles to optimize idea generation and code implementation.
- It employs multi-trace exploration and fusion techniques to diversify strategies and integrate promising partial solutions, improving overall performance.
- Experimental results on the MLE-Bench benchmark demonstrate significant performance gains over existing baselines in machine learning model design and training.
R&D-Agent: Automating Data-Driven AI Solution Building
The paper "R&D-Agent: Automating Data-Driven AI Solution Building Through LLM-Powered Automated Research, Development, and Evolution" (2505.14738) introduces R{content}D-Agent, a dual-agent framework designed to automate and enhance the process of building AI solutions. By employing a Researcher agent for idea generation and a Developer agent for code refinement, the framework facilitates iterative exploration and parallel development, ultimately aiming to bridge the gap between automated systems and expert-level data science. The paper highlights the system's architecture, key components, and experimental results on the MLE-Bench benchmark.
Dedicated R&D Roles
The core innovation of R{content}D-Agent lies in its dual-agent architecture, comprising a Researcher and a Developer agent. This design mirrors the division of labor in human R&D teams, leveraging the strengths of different LLMs for specific tasks. The Researcher agent is responsible for generating ideas and hypotheses based on performance feedback, while the Developer agent focuses on implementing and refining code based on execution logs and error information. This specialization allows for more efficient exploration and development, as each agent is optimized for its respective role. For example, the paper notes that models like o3 excel at reasoning and creative ideation, while models like GPT-4.1 are better at instruction following and solution implementation. By assigning these models to their respective roles, R{content}D-Agent can achieve better results.
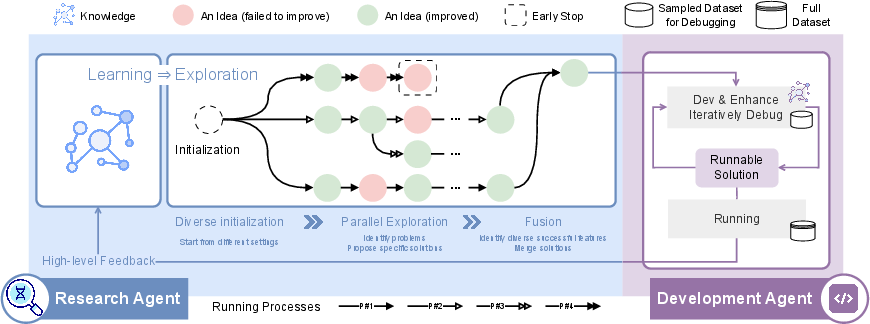
Figure 1: The R{content}D-Agent framework, comprising a Researcher agent that proposes ideas and a Developer agent that implements and tests these ideas.
The Researcher agent utilizes past and external experience, organized into a knowledge base, to refine ideas and generate new ones. The Developer agent focuses on the engineering aspects of the proposed idea, addressing considerations such as resource constraints and ensuring a complete and practical solution. To improve development efficiency, the Developer agent iterates on a smaller, sampled dataset before running the solution on the full dataset.
Multi-Trace Idea Exploration
To overcome the limitations of single exploration paths, R{content}D-Agent introduces a multi-trace exploration mechanism that enables parallel, diverse, and collaborative exploration of the solution space. This approach mitigates the risk of converging on suboptimal solutions due to the constraints of a single configuration. Each trace operates as an independent research agent, configured with heterogeneous parameters such as prompt strategies, model backends, domain-specific tools, and knowledge scopes. This diversity increases the likelihood of uncovering valuable insights from different perspectives and avoids narrow search trajectories imposed by uniform assumptions.
The multi-trace system enables both logical and physical parallelism, with each trace executing asynchronously across compute nodes, containers, or threads. This allows the system to scale horizontally across distributed environments, maximizing resource utilization and reducing time-to-solution. Cross-trace collaboration protocols govern how traces interact, evaluate progress, and make adaptive decisions. Traces maintain performance profiles based on metrics such as solution quality, novelty, resource cost, and error resilience. A centralized module tracks these profiles and makes dynamic decisions, such as terminating unproductive traces, spawning new ones with modified configurations, or initiating trace fusion. Traces can also share intermediate results, creating a collective learning process where one trace's success informs others.
Multi-Trace Fusion
A key outcome of multi-trace exploration is the ability to combine the strengths of multiple traces into a single, high-performing solution through a process called Multi-Trace Merge. Rather than selecting the best trace in isolation, R{content}D-Agent provides a mechanism for compositional integration of partial results from several promising traces. The fusion process operates at multiple granularities within the data science workflow, combining feature generation techniques, model architectures, and post-processing heuristics from different traces. Each trace's components are evaluated and scored based on utility, novelty, compatibility, and performance impact. A configurable fusion strategy is then used to assemble the final solution.
Users can define domain-specific control and fusion rules at each stage of the process, including specifying constraints for early stopping and spawning new traces, determining which intermediate outputs are shared across traces, and customizing component compatibility rules and aggregation functions. This flexibility ensures that R{content}D-Agent can adapt to a wide range of application domains and engineering preferences.
Experimental Results
The paper evaluates R{content}D-Agent on the MLE-Bench benchmark, which assesses the agent's ability to solve Kaggle challenges involving the design, building, and training of machine learning models in GPUs. The experiments were conducted in a virtual environment with a GPU, the dataset, and the competition instructions. The results demonstrate that R{content}D-Agent achieves significantly better performance than the AIDE baseline when using the same LLM backend, particularly in the Low (Lite) and High complexity categories. This highlights the effectiveness of the system design in aligning more closely with the approach to solving machine learning engineering problems.
The paper also explores a hybrid strategy using backend LLMs, combining o3 and GPT-4.1, with o3 assigned as the Researcher agent and GPT-4.1 as the Developer agent. This approach not only meets real-world requirements but also produces results that match or exceed the strongest baseline, demonstrating the value of assigning dedicated research and development roles.
Conclusion
The R{content}D-Agent framework represents a significant step towards automating the process of building data-driven AI solutions. By employing a dual-agent architecture, multi-trace exploration, and multi-trace fusion, the framework facilitates efficient and robust R&D, bridging the gap between automated systems and expert-level data science. The experimental results on the MLE-Bench benchmark demonstrate the effectiveness of the approach, highlighting its potential for accelerating innovation and improving precision across diverse data science applications. Future work will focus on providing more technical details, presenting more comprehensive experimental results, and exploring the application of R{content}D-Agent in other scenarios.