- The paper introduces STEP-HRL, a framework that replaces full history conditioning with step-level progress summarization to enhance scalability for LLM agents.
- It achieves significant improvements in success rates and sample efficiency on benchmarks like ALFWorld and ScienceWorld through offline RL techniques.
- The framework leverages a shared LLM backbone with distinct policy heads, reducing computational costs and facilitating robust decision-making across tasks.
Hierarchical Reinforcement Learning with Augmented Step-Level Transitions for LLM Agents
Introduction and Motivation
Recent advances in LLM-based agents have fueled significant progress in interactive decision making for text-based and embodied environments. However, the prevalent paradigm in RL for LLM agents remains history-conditioned: both high-level and low-level decision policies are typically defined on ever-growing sequences of observations, subtasks, and actions. This mode of policy conditioning inherits essential limitations from Transformer-based sequence modeling, resulting in quadratic computational scaling, accretion of irrelevant contextual information, and degradation in both sample efficiency and reasoning accuracy for long-horizon tasks.
"Hierarchical Reinforcement Learning with Augmented Step-Level Transitions for LLM Agents" (2604.05808) introduces STEP-HRL, a framework that discards the necessity of full interaction history conditioning. Instead, it establishes a step-level abstraction mechanism via local progress summarization within subtasks, thereby enabling efficient and scalable RL for LLM agents while preserving strong performance and generalization.
STEP-HRL Framework
STEP-HRL establishes a hierarchical agent architecture leveraging three primary modules: high-level policy, low-level policy, and local progress policy. All policies share parameters, facilitating value propagation across abstraction levels, with each policy maintaining an independent value function for offline RL.
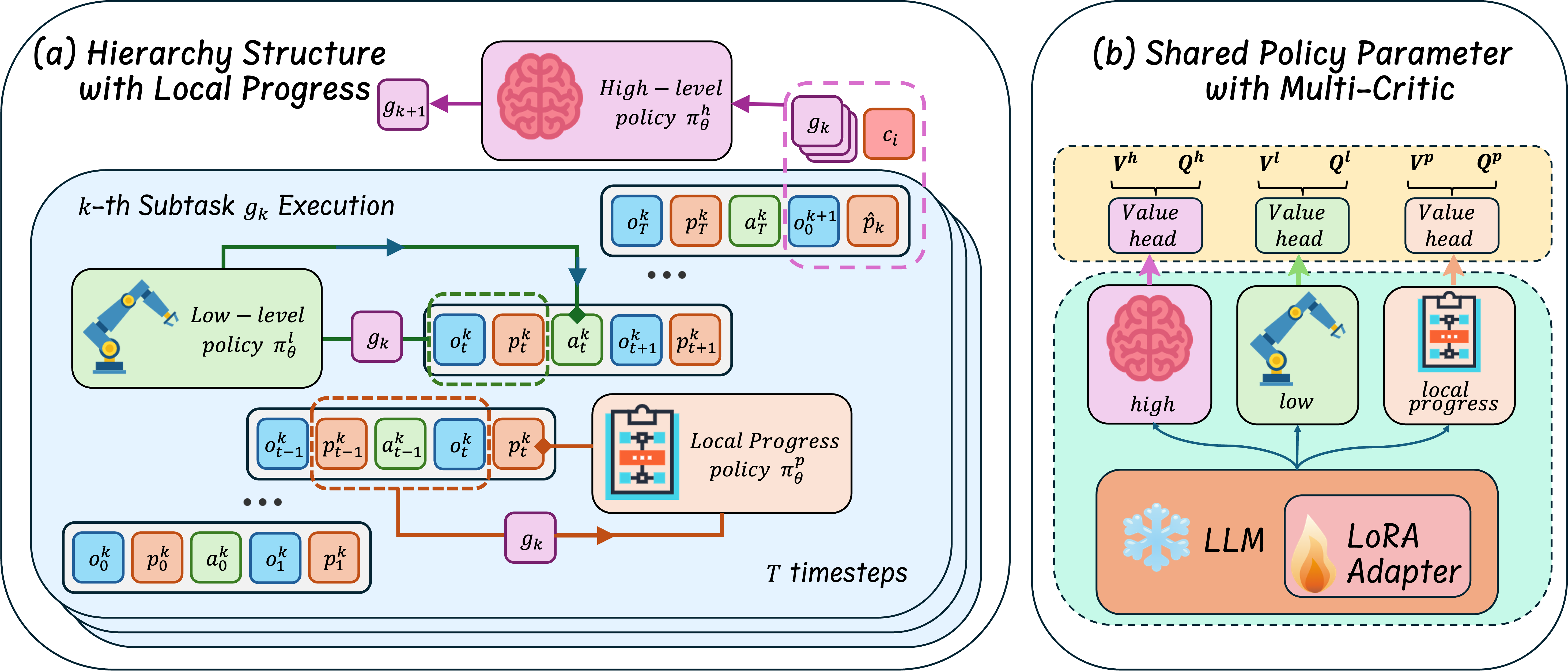
Figure 1: The architecture of STEP-HRL: hierarchical policy decomposition and local progress summarization enable step-level transitions while maintaining information flow between planning layers.
High-Level Policy: The high-level module sequentially generates subtasks conditional on the task instruction, the sequence of previously completed subtasks, the final local progress summarization from the prior subtask, and the initial observation for the new subtask. Crucially, global progress is captured compactly as the sequence of completed subtasks rather than the entire task trajectory.
Low-Level Policy: The low-level module operates within the scope of an assigned subtask. It utilizes the current observation, the subtask identifier, and an iteratively updated local progress vector, output by the local progress policy, to select the next primitive action.
Local Progress Policy: At each step within a subtask, this module ingests the previous local progress encoding, the subtask description, the last action, and resultant observation, and then outputs an updated local progress summary. This mechanism distills relevant context for decision making, circumventing the redundancy and inefficiency of long historical rollouts.
Parameter Sharing: All three policies are realized by a shared LLM backbone, with only the critic/value function heads separated per policy, ensuring efficient transfer and compactness in function approximation.
Step-Level Offline Reinforcement Learning
STEP-HRL modifies the conventional RL pipeline by implementing both behavior cloning (BC) and offline RL at the level of single-step, locally and globally summarized transitions. The policies and critics are trained on expert-constructed datasets and policy rollouts, leveraging an advantage-weighted regression objective for the actor and expectile regression for the value function, following the implicit value learning paradigm.
The critical innovation is that both the state and action inputs for offline RL consist exclusively of compact, progress-augmented step-level representations. This eliminates the computational and modeling burden of full trajectory conditioning, supporting efficient scaling to long-horizon domains.
Empirical Evaluation
STEP-HRL is evaluated on two established benchmarks: ScienceWorld (high-variance, procedurally generated science tasks requiring non-trivial reasoning and experimentation) and ALFWorld (long-horizon sequence manipulation and planning).
Main Results
The framework demonstrates substantial improvements in both average success rate and sample efficiency, with seen and unseen splits, compared to both non-hierarchical and hierarchical RL baselines, including ReAct, Reflexion, SwiftSage, ETO, WKM, and GLIDER. Across all model sizes (Mistral-7B, Gemma-7B, Llama3-8B), STEP-HRL exhibits robust, near-saturated performance on ALFWorld (>96%) and strong improvements on ScienceWorld (e.g., Llama3-8B: 81.6% seen, 77.8% unseen). The framework also narrows the gap in backbone dependency, underlining improved scalability.
Component Analysis
Ablation experiments reveal that removal of the local progress module, the hierarchical structure, or the RL stage consistently degrades performance across all settings. The local progress model is the main driver, as it provides critical subtask-level information compression that decouples RL from the bottleneck of full-history sequence inference.
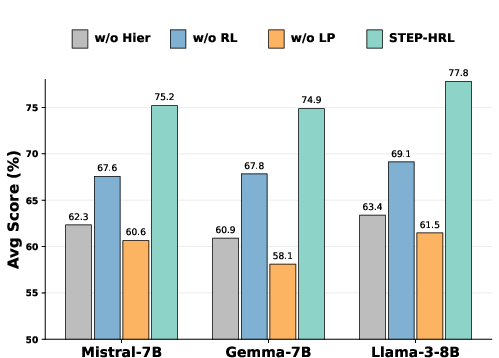
Figure 2: Ablation shows that hierarchical decomposition, local progress summarization, and offline RL each contribute strongly to final performance on ScienceWorld unseen tasks.
Token and Inference Efficiency
STEP-HRL ensures constant per-step token usage, in contrast to the unbounded context growth in standard RL or HRL baselines. The fixed-size, progress-augmented decision space dramatically reduces both inference latency and resource variance.
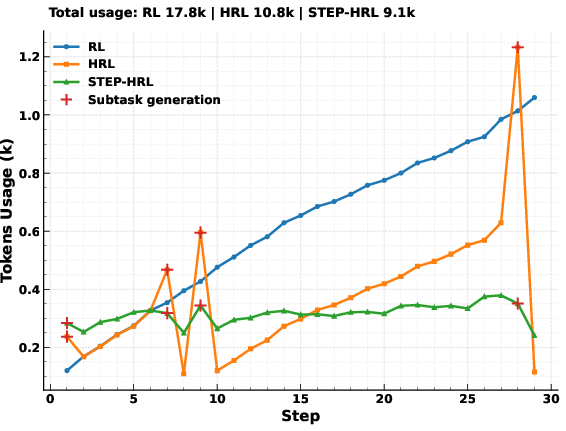
Figure 3: STEP-HRL retains a stable per-step token budget, avoiding the increasing or bursty costs in standard RL and prior HRL baselines.
Offline RL Stability
Sensitivity studies on advantage temperature (β), expectile parameter (τ), data mixture ratios, and dataset sizes demonstrate predictable and stable offline RL performance, with mixed expert and BC-collected data providing optimal results and higher expectile values yielding greater policy improvement.
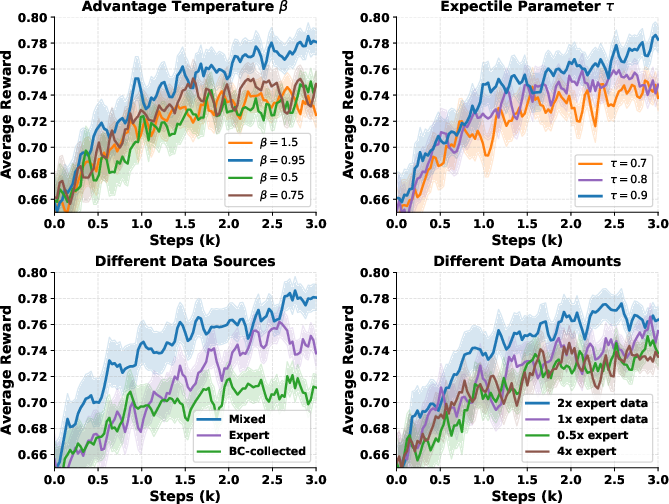
Figure 4: Offline RL performance is most stable with β=0.95 and τ=0.9; combining expert and exploration trajectories outperforms each alone.
Implications, Limitations, and Future Directions
Theoretical and Practical Implications
By reducing the dependency of LLM agents' policy optimization from lengthy full histories to constant-sized, subtask-focused progress representations, STEP-HRL breaks the conventional bottleneck induced by Transformer-based trajectory modeling. This abstraction substantially improves tractability for long-horizon tasks, increases the sample efficiency of offline RL, and establishes a pathway to multi-level hierarchical agents without exponential cost in memory or computation. Importantly, it demonstrates that high performance and generalization are not strictly tied to full-context conditioning in RL for LLM-based agents.
STEP-HRL's modular, progress-driven state summarization is compatible with a broad class of text-based or hybrid task environments, suggesting straightforward extensions to multimodal and embodied agent domains.
Limitations
The method depends critically on expert demonstrations for subtask and local progress modeling. The design and curation of fine-grained step-level progress signals are nontrivial for domains with ambiguous abstraction boundaries or ill-defined subtask progress measures. Errors in subtask termination, due to its joint prediction with primitive actions, can introduce policy-critic misalignment.
Directions for Future Research
- Automated Subtask and Progress Segmentation: Advances in unsupervised or weakly supervised segmentation may relieve the need for expert curation.
- Robustness to Suboptimal Progress Signals: Integrating probabilistic uncertainty modeling for progress extraction could make this approach resilient to environment ambiguity.
- Scalable Multi-Agent and Multi-Modal Integration: The constant step-level abstraction paradigm naturally promotes hierarchical coordination in distributed, collaborative, or sensor-rich environments.
- Online RL and Self-Improvement: Extending the framework to online RL scenarios and automated curriculum generation would further enhance generalization and autonomy.
Conclusion
STEP-HRL presents a parameter-efficient hierarchical RL framework that augments LLM agents with subtask-local progress modeling and constant-sized step-level transitions. The architecture achieves superior performance, generalization, and computational efficiency—most notably, it demonstrates that long-horizon reasoning and planning in LLM agents do not inherently require full-history conditioning. This direction provides a foundation for future architectures that exploit modularity and local summarization, paving the way for robustly scalable LLM-based agents in open-ended interactive domains.