- The paper demonstrates that GR models bypass the dense retrieval vector bottleneck using autoregressive docid generation, achieving near-perfect recall on LIMIT.
- The introduction of hard negatives exposes a critical vulnerability where non-unique identifiers lead to severe recall drops in GR systems.
- The study underscores the need for unique, discriminative identifier generation and improved decoding strategies to enhance retrieval robustness.
Generative Retrieval: Overcoming the Vector Bottleneck but Failing with Identifier Ambiguity
Introduction
This paper systematically evaluates the capacity of generative retrieval (GR) models to circumvent the representational bottlenecks that impede dense retrieval (DR) methods. The authors use the LIMIT synthetic benchmark, constructed to isolate the "vector bottleneck" in DR, and extend it with new variants (LIMIT-H and LIMIT-HS) introducing hard negative samples to test fine-grained semantic discrimination. The main findings demonstrate that GR models, exemplified by SEAL and MINDER, indeed bypass the geometric limitations affecting DR and outperform sparse methods like BM25 on this task. However, the introduction of lexically ambiguous but semantically irrelevant documents exposes a critical vulnerability in GR: their reliance on ambiguous identifiers results in severe degradation of semantic robustness.
Background: From Dense Retrieval to Generative Retrieval
DR models encode queries and documents into a shared vector space, enabling efficient similarity-based retrieval. Despite their success, theoretical work demonstrates that this design enforces a combinatorial upper bound on the rank of the query-document relevance matrix that can be faithfully encoded—a "vector bottleneck" which causes rapid performance collapse as task complexity increases (Weller et al., 28 Aug 2025). Traditional sparse methods such as BM25, though lacking in semantic modeling, avoid this collapse due to their inherently high-dimensional symbolic representation.
Generative retrieval models shift away from vector-space matching, employing autoregressive LLMs to generate symbolic document identifiers (docids) conditioned on the input query [seal; minder]. These identifiers are either substrings (ngrams) of the document or pseudo-queries generated from the document's content, which are indexed for lookup via a text index structure (e.g., FM-index).
Experimental Design and Datasets
The authors use pre-trained, non-fine-tuned SEAL and MINDER models as representatives of state-of-the-art GR methods with proven zero-shot transfer capabilities. The primary evaluation employs the LIMIT dataset: each document lists 50 items liked by a unique individual, and each query asks for all documents involving a specific item. Each query has exactly two relevant documents.
The benchmark is extended with LIMIT-H, where for each relevant document, a "hard negative" is generated—syntactically similar, lexically overlapping, but semantically irrelevant sentences, resulting in identifier ambiguity that specifically challenges the unique-mapping assumption underlying GR docid generation. LIMIT-HS further increases the difficulty by duplicating each negative, crafting even denser semantic "collision clusters".
Results on LIMIT: GR's Structural Advantages
On the original LIMIT dataset, all DR models exhibit near-random recall (R@2 < 0.03). BM25, which uses exact term matching, achieves 0.86 R@2. Zero-shot GR models, without any corpus-specific training, obtain up to 0.99 R@2 (MINDER), thus conclusively demonstrating that the parametric and sequence-generative approach in GR overcomes the limitations imposed by the low-rank vector space of DR.
The impact of decoding and scoring strategy is pronounced. Modifying SEAL's beam search and candidate pruning yields much higher precision at rank.
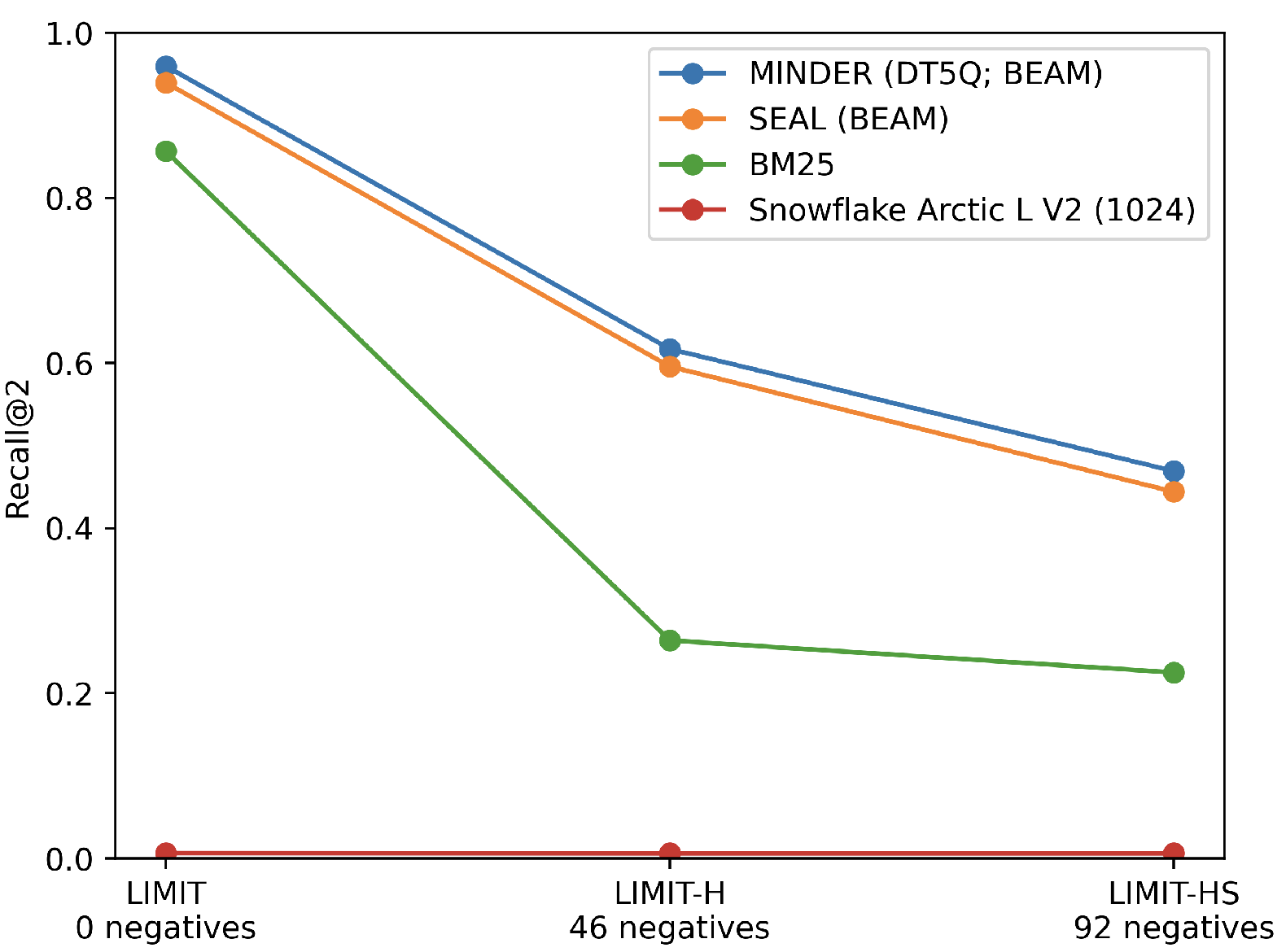
Figure 1: Recall@2 across LIMIT, LIMIT-H, and LIMIT-HS datasets, illustrating the impact of semantic ambiguity on robustness of dense, sparse, and generative retrieval models.
Robustness to Identifier Ambiguity: LIMIT-H and LIMIT-HS
Introduction of hard negatives in LIMIT-H causes precipitous drops in recall. All default GR configurations essentially collapse (R@2 < 0.02). Restricting docid generation to the top candidates using classical beam search (BEAM) improves recall—MINDER (with ngram+pseudo-query BEAM) achieves 0.60 R@2 on LIMIT-H. However, no configuration approaches the near-perfect recall seen on LIMIT; the drop in top-rank recall between LIMIT and LIMIT-H approaches 40-50 percentage points for all GR variants.
BM25 serves as a strong baseline on LIMIT, but its recall plummets to 0.21 on LIMIT-H, revealing its lack of semantic disambiguation. Further scaling of negatives in LIMIT-HS impacts GR models disproportionately more severely than BM25.

Figure 2: A LIMIT-H example highlighting docid ambiguity, where the GR model cannot reliably resolve which documents are relevant due to overlapping identifiers.
Error Analysis and Failure Modes
A detailed error analysis reveals that in the presence of hard negatives, SEAL and MINDER are unable to generate identifiers unique to relevant documents (the NqR∖I set is empty), regardless of ngram or pseudo-query strategy. Scoring is dominated by ambiguous identifiers shared among relevant and irrelevant documents, or even by identifiers exclusive to negatives. Identifier ambiguity is thus shown to be a fundamental limitation for sequence-to-sequence GR systems relying on substring/pseudo-query docids.
Pruning strategies partially reduce spurious ngram generation and improve ranking by filtering weak matches, but do not resolve the core issue: insufficiently expressive or non-unique identifiers cannot distinguish among documents with high lexical overlap but different semantics.
Key Claims and Empirical Results
- GR (SEAL, MINDER) can completely overcome the structural vector bottleneck that collapses dense retrievers.
- When forced to distinguish amongst semantically divergent but lexically overlapping document sets, both GR and BM25 sharply degrade, revealing that GR solutions reliant on substring identifiers are not robust to docid ambiguity.
- Pseudo-query expansion does not introduce enough discriminative capacity to overcome this limitation in practice, even with oracle-constructed pseudo-queries, since label assignment and scoring are not robust to early pruning.
- Score differences between top-ranked documents collapse on ambiguous cases, confirming the loss of discriminative signal and that retrieval performance is largely driven by chance amongst equivalently ambiguous candidates.
Implications and Future Work
The results decisively show that while GR architectures with high-dimensional parametric memory can circumvent embedding-based bottlenecks, their reliance on ambiguous or multi-view identifiers makes them vulnerable to semantic collisions in realistic retrieval scenarios with subtle lexical ambiguity. Thus, while parametric generative retrieval is structurally powerful, it is insufficient for robust information retrieval unless docid design (or the retrieval process) is fundamentally improved for uniqueness and semantic disentanglement.
Practically, these findings stress the need to either (1) develop identifier generation processes that guarantee unique, discriminative mappings between queries and relevant documents, or (2) create improved decoding and ranking strategies that can faithfully preserve fine-grained semantic distinctions—even in zero-shot, out-of-distribution contexts.
Future directions likely entail (a) integrating richer semantic representations directly into the docid generation pipeline, (b) leveraging hybrid sparse-generative approaches, and (c) adopting more sophisticated decoding, scoring, and regularization techniques. Techniques for joint learning of identifiers and similarity metrics, as well as more robust document expansion models, may also play a central role. Scaling the analysis from synthetic to real-world, large-scale datasets is a vital next step.
Conclusion
Generative retrieval represents a promising advance beyond dense retrieval’s vectorial limitations, as shown by its performance on structurally complex tasks. However, when challenged with identifier ambiguity, GR’s reliance on non-unique substring-based docids or pseudo-queries leads to catastrophic failure. The work provides a rigorous framework for assessing such failure modes and offers novel benchmarks (LIMIT-H, LIMIT-HS) to drive the development of more robust retrieval architectures. Advances in docid uniqueness, decoding policies, and scoring regularization are necessary to deliver on the latent capacity of current GR systems.
(2604.05764)