On Strengths and Limitations of Single-Vector Embeddings
Abstract: Recent work (Weller et al., 2025) introduced a naturalistic dataset called LIMIT and showed empirically that a wide range of popular single-vector embedding models suffer substantial drops in retrieval quality, raising concerns about the reliability of single-vector embeddings for retrieval. Although (Weller et al., 2025) proposed limited dimensionality as the main factor contributing to this, we show that dimensionality alone cannot explain the observed failures. We observe from results in (Alon et al., 2016) that $2k+1$-dimensional vector embeddings suffice for top-$k$ retrieval. This result points to other drivers of poor performance. Controlling for tokenization artifacts and linguistic similarity between attributes yields only modest gains. In contrast, we find that domain shift and misalignment between embedding similarities and the task's underlying notion of relevance are major contributors; finetuning mitigates these effects and can improve recall substantially. Even with finetuning, however, single-vector models remain markedly weaker than multi-vector representations, pointing to fundamental limitations. Moreover, finetuning single-vector models on LIMIT-like datasets leads to catastrophic forgetting (performance on MSMARCO drops by more than 40%), whereas forgetting for multi-vector models is minimal. To better understand the gap between performance of single-vector and multi-vector models, we study the drowning in documents paradox (Reimers & Gurevych, 2021; Jacob et al., 2025): as the corpus grows, relevant documents are increasingly "drowned out" because embedding similarities behave, in part, like noisy statistical proxies for relevance. Through experiments and mathematical calculations on toy mathematical models, we illustrate why single-vector models are more susceptible to drowning effects compared to multi-vector models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how computers find the right documents for a question using “embeddings.” An embedding is like a compact “fingerprint” of a sentence: a list of numbers that tries to capture its meaning. The paper asks: when is it enough to represent a whole sentence with just one fingerprint (a single vector), and when do we need richer representations (many vectors per sentence, called multi-vector models)?
To study this, the authors focus on a simple but tricky test called LIMIT, where each document is a person’s profile listing items they like, and each question asks “Who likes X?” Surprisingly, many popular single-vector systems do badly on this—even though they work well elsewhere. The paper explores why that happens and what can help.
What questions does the paper ask?
- Is the poor performance on LIMIT caused simply by embeddings being too low-dimensional (i.e., the fingerprints don’t have enough numbers)?
- If not, what else is going wrong? Could it be:
- how words are chopped into pieces (“tokenization”),
- how similar some words are to each other,
- a “domain shift” (the test looks very different from what the model saw during training),
- or a deeper problem with using a single vector per text?
- How do single-vector and multi-vector methods compare, especially as the number of documents grows (the “drowning in documents” problem)?
- Can fine-tuning (retraining on the new task) fix these issues, and if so, what are the side effects?
How did the researchers study it?
The LIMIT dataset
- Each document is a sentence like “Olivia Garcia likes chess, apples, hiking, …” (48 liked items per person).
- Each query is a simple question like “Who likes chess?”
- A document is relevant to a query if it includes the item the question asks about.
This setup turns language into a set-matching task: does the item in the question appear in the document’s list?
Their approach (in everyday terms)
- Theory check on dimensions: The authors used math to ask, “How many numbers do we really need in each embedding to get the top answers right?” For LIMIT, there are only two correct documents per query (top-2). The math shows that, in theory, only 2×2+1 = 5 numbers per embedding could be enough to rank the top 2 right. So “not enough dimensions” is probably not the main reason models fail here.
- Controlling for words and tokens: They built a version of LIMIT using single-token nouns and avoided pairs like “iced tea” vs. “black tea” that can confuse models. This isolates issues caused by the way models split words and by word similarity.
- Fine-tuning: They retrained models on LIMIT-like data to see if performance improves and whether models “forget” how to work on old tasks (like MS MARCO, a common web search benchmark).
- Single-vector vs. multi-vector: They compared one-vector-per-text systems to multi-vector systems (which keep several small embeddings per text and match them more precisely).
- Drowning in documents: They studied why retrieval quality often gets worse as you add many more documents, even if most are irrelevant. They ran experiments and simple math models to see which approach drowns more easily.
What did they find?
- Dimensionality isn’t the main culprit:
- For LIMIT-like tasks where only the top k results matter, theory says $2k+1$ dimensions can suffice to get the top k right.
- Since LIMIT needs top-2, about 5 dimensions could be enough in theory. Real models already use hundreds or thousands, so “too few dimensions” doesn’t explain the failure.
- Tokenization and word similarity matter a bit—but not enough:
- Making attributes single tokens and less similar to each other gave only small improvements for single-vector models (e.g., Recall@10 rose from about 1% to ~3%).
- Multi-vector models improved a lot under the same clean setup (Recall@2 jumped from ~27% to ~96% even without fine-tuning).
- Domain shift and misaligned scoring are major problems:
- LIMIT documents are long lists of unrelated items, which is unusual compared to what models usually see in training. That mismatch hurts.
- Fine-tuning helps single-vector models a lot on LIMIT (e.g., Recall@10 rising from ~1% to ~40%) and helps multi-vector models even more (e.g., from ~40% to ~98%).
- Catastrophic forgetting hits single-vector models hard:
- After fine-tuning on LIMIT-like data, single-vector models did much worse on MS MARCO (more than a 40% drop in Recall@100).
- Multi-vector models barely forgot (about a 1% drop).
- Multi-vector models separate relevant from irrelevant better:
- In both math and experiments, multi-vector models keep scores for relevant and irrelevant documents more distinct.
- This makes them much less likely to “drown” as the document pool grows. Single-vector models are more easily swamped by many irrelevant but similar-looking documents.
Why is this important?
- Practical takeaway: If your search task looks like “find documents that contain a specific item from a list” (a set-matching problem), single-vector embeddings may often struggle—even if you use large dimensions. Multi-vector methods tend to work much better and stay reliable as your collection grows.
- Fine-tuning helps but has trade-offs: You can adapt a model to new, unusual data (like LIMIT), but single-vector models may forget what they previously knew. Multi-vector models are more robust and keep their broader skills.
- Design guidance: Don’t assume that “bigger embeddings” solve everything. The match between how similarity is measured and what “relevance” really means for your task is crucial. For set-structured tasks, scoring methods that compare multiple parts (multi-vector with late interaction) are a better fit.
Key terms explained simply
- Embedding: A list of numbers that represents the meaning of a sentence or document—like a fingerprint for text.
- Single-vector vs. multi-vector:
- Single-vector: one fingerprint per text.
- Multi-vector: many small fingerprints per text (often one per important token), then compare sets of fingerprints.
- Tokenization: How a model splits text into pieces it understands. “Iced tea” might become “iced” + “tea.” Different splits can cause confusion.
- Domain shift: When the new task looks very different from what the model was trained on (e.g., long lists of items instead of normal sentences).
- Fine-tuning: Retraining a model on new examples so it adapts to a new task.
- Catastrophic forgetting: When fine-tuning on a new task makes a model perform poorly on tasks it used to do well.
- “Drowning in documents”: As your library of documents gets huge, the few relevant ones can get “lost in the crowd” if the scoring isn’t sharp enough.
In short: The paper shows that for LIMIT-like problems, the weakness of single-vector embeddings isn’t mainly about having too few numbers—it's about using the wrong kind of representation for set-style matching. Multi-vector models align better with the task, perform much better, handle growth more gracefully, and retain their broader abilities after fine-tuning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete follow-up work.
Theoretical scope and generality
- Constructive learnability of the 2k+1 bound: The paper shows that, for a fixed known relevance matrix with at most k relevant documents per query, single-vector embeddings of dimension ≤2k+1 suffice to realize top‑k rankings. It does not provide a constructive training procedure (or sample complexity guarantees) that can learn such embeddings from text for unseen queries/documents, nor demonstrate that current neural encoders can realize this low‑dimensional solution in practice.
- Stability under noise and near-ties: The 2k+1 result assumes exact consistency with a fixed relevance matrix. It remains unclear how robust this bound is to label noise, approximate relevance (e.g., near‑ties), or adversarially close negatives, and how much dimension must increase to maintain stable top‑k under such perturbations.
- Actual sign‑rank and lower bounds for LIMIT-like tasks: While the paper argues that dimensionality is not the culprit, it does not estimate the empirical sign‑rank of LIMIT or provide lower bounds for LIMIT-like distributions. Quantifying sign‑rank (or proxy measures) would clarify whether practical failures stem from optimization/generalization rather than expressivity.
- JL-style bound is stated but not fully formalized: Proposition “Low dimensional embeddings without sparsity” is asserted with a JL‑based argument, but the formal proposition statement and proof details are missing in the text provided. A precise theorem with explicit constants, conditions, and failure probabilities is needed.
- Drowning theory beyond toy setup: Theoretical drowning results are proved for a restricted toy setting (query length 1; document length n) with stylized score distributions. Extensions to general query lengths, variable document lengths, multiple relevant documents, correlated attribute distributions, and non‑Gaussian/anisotropic score distributions remain open.
- Alternative scoring functions and geometry: Analyses assume cosine (normalized dot‑product). It remains open whether learned bilinear/metric (e.g., Mahalanobis), mixture‑of‑centers, or hyperspherical embeddings can reduce drowning susceptibility or better align with set‑overlap without resorting to multi‑vector models.
- General lower bounds for single‑vector under set‑structured relevance: The paper highlights multi‑vector advantages but does not provide general impossibility results (beyond the toy model) that characterize when single‑vector methods must fail under drowning or combinatorial set overlap.
Empirical design and evaluation
- Limited model diversity on the single-vector side: Experiments primarily use Qwen3‑Embedding‑0.6B; conclusions may not generalize to other strong single‑vector retrievers (e.g., GTR, Contriever, E5, Jina, Snowflake, Voyage, bge-large). A broader sweep across architectures, embedding dimensions, and training regimes is needed.
- Sparse exploration of training objectives: Fine‑tuning uses a specific setup (2 positives, 30 random negatives, 1 epoch). The paper does not examine alternative objectives (e.g., margin/tau tuning, temperature annealing, hard-negative mining, distillation from cross‑encoders, multi‑positive soft labels) that could mitigate misalignment and drowning for single‑vector models.
- Lack of statistical rigor: Reported improvements lack variance estimates, confidence intervals, or significance tests. There is no ablation on random seeds, number of epochs, batch sizes, or negative sampling choices to assess robustness of findings.
- Incomplete ablations for domain shift: While “Two LIMIT,” “Three LIMIT,” “Atomic LIMIT,” etc., are introduced, there is no systematic ablation varying (i) document length, (ii) query length, (iii) attribute overlap, (iv) vocabulary size, and (v) linguistic similarity, to isolate which factor(s) most drive failures or improvements.
- Limited OOD generalization checks: Apart from Atomic LIMIT and a preliminary MS MARCO→SciFact merge, broader OOD tests (e.g., BEIR sub‑tasks with set‑like structure, tagging/label retrieval, multi‑facet queries) are not reported, leaving generality of conclusions uncertain.
- Angle diagnostics are anecdotal: The angle analysis of attribute embeddings is shown for select pairs. A comprehensive analysis across all attributes (distributional changes, hubness, anisotropy metrics) is missing, as is any link between angle changes and retrieval metrics.
- Missing evaluation of ANN indexing effects: The study does not examine how approximate nearest neighbor indexes, quantization, or compression influence drowning and model comparisons—key for real‑world deployments.
Catastrophic forgetting and mitigation
- Single-vector forgetting mitigation is unexplored: The paper documents severe forgetting for single‑vector models but does not evaluate standard remedies (e.g., rehearsal/memory, EWC/LwF regularization, adapters/LoRA with frozen backbones, multi‑task/continual learning curricula, balanced fine‑tuning).
- Breadth of multi-vector robustness: Multi‑vector forgetting is measured only on MS MARCO after LIMIT fine‑tuning. It remains unknown whether this robustness persists under other domain shifts, larger distribution gaps, longer training, or different multi‑vector architectures/scoring functions.
Tokenization and linguistic factors
- Systematic tokenization study is missing: While Atomic LIMIT suggests tokenization/semantic similarity effects, there is no controlled sweep over token granularity (BPE merge levels), morphological variants, synonyms/paraphrases, or different tokenizers across languages to quantify impact curves on single‑ vs multi‑vector performance.
- Bridging text to set‑embeddings: The JL‑style construction presumes explicit sets of attributes; the study does not investigate training procedures that make text encoders recover such set‑like representations (e.g., objectives aligning cosine with Jaccard/overlap).
Practical trade-offs and systems aspects
- Efficiency–effectiveness trade-offs are unquantified: The paper affirms multi‑vector superiority but does not measure memory, latency, and indexing costs vs single‑vector baselines on the same hardware and at scale, nor evaluate recent accelerations (PLAID, MUVERA) in the context of LIMIT‑like tasks.
- Hybrid pipelines are not examined: Real systems often use single‑vector retrieval followed by multi‑vector or cross‑encoder reranking. Whether such hybrids mitigate drowning or forgetting while preserving efficiency remains an open empirical question.
Reproducibility and transparency
- Missing details and artifacts: Some referenced sections/proofs (e.g., formal statement of the JL bound) are absent in the provided text. Precise dataset generation procedures for all LIMIT variants, code, and hyperparameters are not detailed or linked, hindering replication.
- Evaluation breadth and metrics: Apart from recall (and some MS MARCO metrics), broader ranking measures (e.g., R‑precision, AP, Recall@k over varying k) and calibration/ROC analyses of score separability (μ+, μ−, σ−) are limited; standardized reporting would aid comparability.
Additional open directions
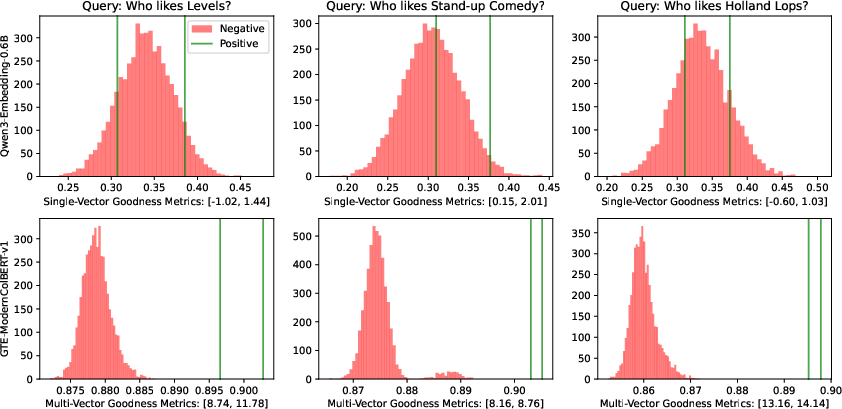
- Quantify and optimize “goodness” (G): The paper introduces a goodness metric G = (μ+ − μ−)/σ− but does not systematically estimate it across datasets/models or train to directly maximize it; exploring loss functions or regularizers that increase G could address drowning.
- Alternative single-vector designs: Investigate whether multi‑prototype per document (e.g., vector mixtures), subspace embeddings, or sparse high‑dimensional encodings within a “single‑vector” budget can close the gap without full late interaction.
- Task realism: Validate claims on real set‑structured retrieval tasks (e.g., tag‑based search, shopping lists, entity‑attribute queries) with human relevance judgments to ensure LIMIT‑style findings transfer beyond synthetic/naturalistic proxies.
Practical Applications
Practical Applications of “On Strengths and Limitations of Single-Vector Embeddings”
This paper clarifies when and why single-vector embeddings underperform in retrieval, and demonstrates that multi-vector (late-interaction) models are more effective and robust—especially under domain shift and corpus growth (“drowning in documents”). It also provides constructive insights (e.g., 2k+1 dimensionality for top‑k recovery, JL-based low-dim embeddings for set-structured tasks) and empirical fine-tuning recipes. Below are actionable applications organized by deployment timeline.
Immediate Applications
Below are near-term, deployable uses across industry, academia, policy, and daily life that can be built directly from the paper’s findings and methods.
- Multi-vector adoption for set-structured or list-like retrieval (Industry: search, e-commerce, enterprise; Education; Healthcare)
- Description: For queries and documents that behave like sets (e.g., “find items with attributes A and B”), replace or augment single-vector retrievers with multi-vector/late-interaction models (e.g., ColBERT/ColBERTv2, Chamfer/MaxSim scoring). The paper shows large recall gains and far less catastrophic forgetting than single-vector models.
- Tools/workflows: GTE-ModernColBERT-v1; PLAID for efficient execution; MUVERA for ANN-compatible multi-vector search; hybrid pipelines (multi-vector recall + cross-encoder reranking).
- Assumptions/dependencies: Increased storage and compute overhead; availability of late-interaction support in the vector database or retrieval engine.
- Query router to pick the right retriever (Industry: web search, support, RAG systems)
- Description: Introduce a query classifier to detect set-like or multi-intent queries (presence of conjunctions, enumerations, filters) and route them to multi-vector retrievers; route simpler semantic queries to single-vector to save cost.
- Tools/workflows: Lightweight classifier; rules+ML hybrid; confidence thresholds and fallbacks.
- Assumptions/dependencies: Accurate detection for routing; latency budgets that allow model switching.
- “Drowning watchdog” monitoring (Industry: platform/ops; Academia: evaluation)
- Description: Monitor the drowning risk as corpora grow using the paper’s goodness metric G = (μ+ − μ−)/σ− and track changes in Recall@k. Alert when G degrades past thresholds indicating rising false positives from negatives.
- Tools/workflows: Offline analysis of positive/negative score distributions; A/B tests with corpus snapshots; dashboards.
- Assumptions/dependencies: Availability of labeled positives, or trusted heuristics to estimate μ+, μ−, σ−.
- Fine-tune multi-vector retrievers to handle domain shift with minimal forgetting (Industry; Academia)
- Description: The paper shows substantial gains on LIMIT-like tasks with multi-vector fine-tuning and minimal loss on MS MARCO (≈1% drop). Adopt multi-vector fine-tuning when moving to domains where documents are lists or attribute sets.
- Tools/workflows: Contrastive fine-tuning with positives+hard negatives; rehearsal data from original domain; early stopping.
- Assumptions/dependencies: Access to in-domain labeled data or synthetic positives; storage for rehearsal datasets.
- Avoid catastrophic forgetting in single-vector models by using adapters/rehearsal (Industry; Academia)
- Description: If single-vector retrievers must be used, mitigate forgetting seen in the paper by: (a) adapter-based fine-tuning or LoRA; (b) joint training with rehearsal on original corpora; (c) domain-specific heads.
- Tools/workflows: Adapter/LoRA stacks; multi-task schedules; balanced batching.
- Assumptions/dependencies: Additional engineering complexity and training budget; possibly smaller gains than multi-vector.
- Tokenization-aware attribute engineering (Industry: catalogs, ads, HRIS; Daily life: personal search)
- Description: For attribute-centric search, prefer “atomic” (single-token) attributes and avoid linguistically similar collisions (e.g., “black tea” vs. “iced tea”) to reduce single-vector misretrieval.
- Tools/workflows: “Atomic attribute generator” that maps catalog attributes to stable tokens; synonym curation; tokenizer audits.
- Assumptions/dependencies: Control over attribute naming; tokenizer-specific constraints.
- Lightweight indexing strategy for top‑k retrieval tasks (Industry: recommender candidate gen; Finance, Ads)
- Description: Use the 2k+1 dimensionality insight to design low-dim re-rankers when only top‑k correctness is required. Apply this as a low-cost final-stage ranker over a small candidate set.
- Tools/workflows: Train a low-dim head on top of encoder outputs for final top‑k ordering.
- Assumptions/dependencies: Works best when k is small and candidates are pre-filtered; result mainly holds over a known query/document set.
- Specialized low-dim embeddings for controlled attribute spaces (Industry: catalogs; Ads; Robotics logs; Energy ops)
- Description: For known, finite attribute universes, construct per-attribute near-orthogonal vectors and embed documents/queries as normalized sums as suggested by the JL-based construction, reducing memory footprint while preserving set-overlap ordering.
- Tools/workflows: Codebook of near-orthogonal vectors; deterministic or random JL-based constructions; normalized vector summation.
- Assumptions/dependencies: Most effective when queries/documents are true sets; less suitable for free-form text.
- Evaluation upgrades: LIMIT-like tests and “Atomic LIMIT” suites (Industry QA; Academia benchmarks; Policy procurement)
- Description: Add synthetic LIMIT-like and “Atomic LIMIT” evaluations to internal test batteries to capture failures tied to set-structured relevance and tokenization. Report “drowning stress tests” by adding irrelevant corpus chunks.
- Tools/workflows: Synthetic dataset generator; automated reports on Recall@k, goodness metric G, and forgetting across benchmark suites.
- Assumptions/dependencies: Requires test harness and data generation; alignment with business KPIs.
- Risk-aware routing and fallback for LLM-RAG pipelines (Industry; Daily life apps)
- Description: In retrieval-augmented generation, detect attribute-heavy prompts and route to multi-vector recall; fallback to lexical/symbolic filters when signals diverge from set overlap (e.g., “must include X and Y”).
- Tools/workflows: Router; BM25 filters; combining sparse and multi-vector scores; guardrails for specific operators (“AND”, “OR”, “NOT”).
- Assumptions/dependencies: Integration with RAG orchestrators; balancing latency vs. accuracy.
- Sector-specific deployments
- Healthcare: Multi-vector retrieval for EHR searches combining multiple symptoms/medications; monitor drowning as record systems grow.
- Finance/Compliance: Multi-criteria policy or regulation search; set-aware retrieval for clause+entity combinations.
- Education: Question bank retrieval with topic+skill filters; multi-intent student queries.
- Energy/Operations: Log/event searches with multi-tag filters; late-interaction improves retrieval of rare tag combinations.
- Assumptions/dependencies: Domain data availability; privacy/regulatory approval for indexing.
Long-Term Applications
The following require additional research, scaling, or infrastructure development before broad deployment.
- Set-aware training objectives and scoring (Industry; Academia)
- Description: Design loss functions and scorers that explicitly align with set-theoretic relevance (e.g., Jaccard, overlap), extending beyond cosine similarity. Combine token-level late-interaction with overlap-aware regularizers.
- Dependencies: New training pipelines; theoretical analysis for generalization beyond fixed corpora.
- Continual-learning retrievers that resist catastrophic forgetting (Industry; Academia)
- Description: Develop embedding retrievers with regularization, elastic weights, or memory modules to maintain performance across domains without large rehearsal sets.
- Dependencies: Research on stability–plasticity for dense/multi-vector models; benchmarking suites.
- Standardized “Drowning Stress Tests” and procurement guidelines (Policy; Industry)
- Description: Establish sector-wide evaluation protocols to measure drowning susceptibility (e.g., goodness G-based metrics) and require vendors to report robustness under corpus growth and domain shift.
- Dependencies: Consensus on metrics; inclusion in standards bodies and RFIs/RFPs.
- Hardware and systems support for multi-vector at scale (Industry; Vendors)
- Description: Specialized kernels and indexes for late-interaction retrieval (e.g., PLAID-style execution, compressed token vectors, ANN-friendly reductions like MUVERA) to match single-vector latencies and costs.
- Dependencies: Systems engineering and hardware acceleration; ecosystem support within vector databases and search engines.
- Automated domain-shift detectors and self-adaptive retrieval (Industry; Academia)
- Description: Online monitors to detect distribution shift (e.g., unusual list-like inputs) and trigger model adaptation, routing, or fine-tuning—balancing accuracy and forgetting.
- Dependencies: Robust shift-detection algorithms; safe online learning methods.
- Hybrid single+multi-vector architectures (Industry; Academia)
- Description: Architectures that fuse global single-vector semantics with token-level multi-vector matchers, with dynamic weighting based on query structure.
- Dependencies: Research on fusion operators; training strategies to optimize cost–quality tradeoffs.
- Cross-modal set-structured retrieval (Ads, Images, Multimodal assistants)
- Description: Extend late-interaction and set-aware methods to image/ads retrieval where items have attribute tags or concepts. Improve robustness to large catalog growth.
- Dependencies: Multimodal encoders; token-level late-interaction in non-text modalities.
- Synthetic dataset toolkits for attribute-centric retrieval (Academia; Industry QA)
- Description: Multi-language LIMIT-like dataset generators for evaluating set-overlap retrieval, tokenization effects, and drowning phenomena.
- Dependencies: Open-source tooling; community benchmarks.
- Theoretical guidance for dimensionality and generalization (Academia)
- Description: Move from fixed-corpus sign-rank bounds (e.g., 2k+1 for top‑k) to generalization guarantees for unseen queries/documents; characterize when low-dim embeddings suffice in practice.
- Dependencies: New theory linking sign-rank, distributional assumptions, and training dynamics.
- Privacy- and compliance-aware multi-vector indexing (Policy; Industry)
- Description: Governance patterns and technical controls for storing token-level vectors (e.g., hashing, secure enclaves, differential privacy) in regulated environments.
- Dependencies: Legal review and standardized controls; impact studies on accuracy vs. privacy.
- Personalized assistants with set-based preference retrieval (Daily life; Consumer apps)
- Description: User profiles represented as sets of preferences/tags; multi-vector retrieval of content matching multiple preferences without drowning as content libraries grow.
- Dependencies: On-device or low-latency multi-vector support; preference modeling.
Key Assumptions and Dependencies (cross-cutting)
- The 2k+1 dimensionality and JL-based constructions primarily guarantee correct ordering over known query–document sets or top‑k targets; extending to unseen distributions requires additional training and evaluation.
- Drowning analysis assumes approximate Gaussian behavior of negative score distributions; real-world deviations must be monitored with the proposed goodness metric G.
- Multi-vector retrieval offers robust gains but increases indexing and query-time costs; systems like PLAID/MUVERA or compression are needed for large-scale, latency-sensitive use.
- Catastrophic forgetting observations were demonstrated on specific models/datasets (e.g., Qwen3-Embedding-0.6B, MS MARCO); while trends are likely general, verify per deployment.
- Tokenization-sensitive improvements require control over attribute naming or tokenizer selection; when attributes are not controllable, prefer multi-vector approaches.
These applications provide a roadmap to deploy more reliable retrieval today (via multi-vector adoption, routing, monitoring, and fine-tuning) and to guide research and product investments toward robust, set-aware, and scalable retrieval systems.
Glossary
- Anisotropy: A geometry-related imbalance in vector spaces that can distort similarity measures and limit expressiveness. Example: "geometric/representational pathologies (e.g., anisotropy and related degeneracies) that constrain what cosine similarity can express"
- Approximate Nearest Neighbor (ANN): Algorithms or primitives for fast, approximate nearest-neighbor search in high-dimensional spaces. Example: "ANN-mined hard negatives"
- Bi-encoder: A retrieval architecture that encodes queries and documents separately into single vectors scored by a similarity function. Example: "dense retrieval models based on bi-encoders that map queries and documents to single-vector embeddings"
- Catastrophic forgetting: Loss of performance on previously learned tasks when a model is fine-tuned on a new domain. Example: "finetuning single-vector models on LIMIT-like datasets leads to catastrophic forgetting (performance on MSMARCO drops by more than 40\%)"
- Chamfer distance: A set-to-set similarity/distance used in late-interaction retrieval to compare query and document token vectors. Example: "Multi-vector embeddings, together with the associated Chamfer distance \cite{khattab2020colbert, santhanam2022colbertv2}, provide richer representations"
- Chamfer-style scoring: A late-interaction scoring approach using Chamfer-like set matching to compare token-level representations. Example: "Chamfer-style scoring naturally encode the set-structured similarity underlying LIMIT-like tasks better than single-vector models."
- Contrastive pretraining: Unsupervised training that brings semantically similar texts closer in embedding space and pushes dissimilar ones apart. Example: "unsupervised contrastive pretraining (e.g., Contriever)"
- Cross-encoder distillation: Training a retriever by transferring knowledge from a cross-encoder that jointly scores query–document pairs. Example: "cross-encoder distillation / joint retriever--reranker training"
- Dense retrieval: Neural retrieval paradigm mapping queries and documents into a shared vector space for nearest-neighbor search. Example: "a family of methods known as dense retrieval have become prominent."
- Domain shift: A mismatch between training and test distributions that degrades model performance. Example: "The poor performance of embedding models on LIMIT stems from a domain shift."
- Drowning in documents paradox: The phenomenon where retrieval quality worsens as the corpus grows, even with mostly irrelevant additions. Example: "Drowning in documents paradox \cite{reimers-gurevych-2021-curse, drowning2025}."
- Goodness metric: A separability measure for relevant vs. irrelevant score distributions that predicts drowning probability. Example: "The goodness metric , where is the mean of scores of relevant documents, is mean of scores of irrelevant documents and is standard deviation of scores of irrelavant documents."
- Hard negatives: Challenging non-relevant examples used during training to improve retriever discrimination. Example: "ANN-mined hard negatives"
- Johnson-Lindenstrauss lemma: A result guaranteeing low-distortion embeddings into lower-dimensional Euclidean spaces via random projections. Example: "Johnson-Lindenstrauss lemma \cite{Johnson1984} implies that a random set of vectors has this property (with high probability)"
- Late-interaction retrieval: A paradigm that compares sets of token-level vectors from queries and documents instead of single vectors. Example: "multi-vector or late-interaction retrieval - addresses these expressiveness limits"
- MaxSim: A late-interaction operator that scores by taking maximum similarities between token vectors across sets. Example: "scoring via a set-matching operator such as Chamfer/MaxSim."
- Multi-vector embeddings: Representations that store multiple token-level vectors per text to capture fine-grained matching signals. Example: "Multi-vector embeddings, together with the associated Chamfer distance \cite{khattab2020colbert, santhanam2022colbertv2}, provide richer representations"
- Nearest-neighbor search: Retrieving items whose embeddings are most similar to a query embedding. Example: "enables retrieval by nearest-neighbor search."
- Out-of-distribution generalization: A model’s ability to perform well on inputs drawn from a distribution different from its training data. Example: "The ability of machine learning models to handle such domain shifts is known as {\em out of distribution generalization} ability."
- Row-sparse (matrix): A matrix where each row contains only a small number of nonzero entries (e.g., few relevant documents per query). Example: "is {\em row sparse}, i.e. each row in has at most nonzero entries."
- Set-matching operator: A function that compares two sets of vectors (e.g., token embeddings) to produce a similarity score. Example: "scoring via a set-matching operator such as Chamfer/MaxSim."
- Sign rank: The minimum rank of a real matrix whose entrywise signs match a given sign pattern; bounds embedding dimensionality needed to realize relevance. Example: "an analytic quantity known as the sign-rank of a matrix formed out of the relevance data"
- Single-vector embeddings: Representations that map each text to a single vector, scored by a similarity measure such as cosine. Example: "single-vector embeddings produced by existing state of the art neural models perform strikingly poorly on it."
- Tokenization (in NLP): Splitting text into subword or word tokens as input to LLMs; can introduce overlaps and artifacts. Example: "many attributes are tokenized into multiple tokens rather than a single token"
- Top-k retrieval: The task/objective of ensuring the top k returned documents are relevant, often with relaxed requirements for the rest. Example: "$2k+1$-dimensional vector embeddings suffice for top- retrieval."
- Vector indexing: Data structures and systems for efficient nearest-neighbor search over large collections of embedding vectors. Example: "others (e.g. vector indexing) favor Euclidean distance for its geometric intuition and connections to various algorithmic techniques."
Collections
Sign up for free to add this paper to one or more collections.