- The paper introduces a two-stage pipeline that uses sparse autoencoders to identify and steer latent reasoning features in LLMs.
- It contrasts chain-of-thought and direct prompting, demonstrating that targeted latent interventions yield comparable reasoning performance with significantly reduced token overhead.
- Experimental results reveal that early latent feature interventions activate concise reasoning, challenging conventional chain-of-thought paradigms.
Analyzing Latent Computational Modes in LLMs
Introduction
The paper "Reasoning Beyond Chain-of-Thought: A Latent Computational Mode in LLMs" (2601.08058) investigates the mechanisms underlying reasoning capabilities in LLMs. It specifically challenges the prevailing understanding that Chain-of-Thought (CoT) prompting is the sole technique for triggering reasoning processes in such models. By exploring sparse autoencoders (SAEs) to analyze and intervene in LLMs' internal representations, the authors present an alternative framework where latent reasoning features can be directly modulated.
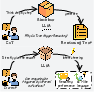
Figure 1: Multiple triggers for latent reasoning in LLMs. Top: CoT prompting produces explicit reasoning text, while the internal mechanism responsible for its effectiveness remains unclear. Bottom: We view reasoning as a latent internal mechanism that can be activated through different triggers, including latent steering.
Methodology
The authors propose a two-stage pipeline, encompassing feature discovery and causal validation, to identify and intervene on reasoning-related latent features in LLMs (Figure 2). Feature discovery contrasts CoT and direct prompting to extract activation patterns and project them into sparse latent spaces. This process employs pretrained SAEs to isolate prompt-sensitive features. Causal validation involves targeted interventions via latent steering, assessing the impact of these features on reasoning performance without explicit CoT prompting.
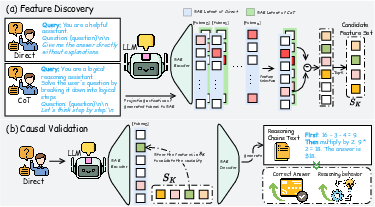
Figure 2: Overview of the proposed two-stage pipeline. (a) Feature Discovery. We contrast direct and chain-of-thought prompting to extract token-level activations, project them into sparse latent features using a pretrained sparse autoencoder (SAE), and identify prompt-sensitive candidate features via differential analysis. (b) Causal Validation. We apply targeted latent steering to selected features and inject the resulting residual into the model to assess their intervention sensitivity, evaluating the effect on model behavior and answer correctness.
Experimental Results
The experimental evaluation covers six model families, demonstrating that steering a single latent feature can achieve reasoning performance comparable to CoT prompting with reduced token overhead. In particular, latent steering activates reasoning-related states earlier in the generation sequence, leading to efficient and concise solutions. An intervention at the initial decoding step is crucial, as later interventions appear less effective (Figure 3).

Figure 4: Behaviors induced by steering. (a) Steering can override prompt-level instructions that suppress reasoning (e.g., \textbackslash no_think). (b) For questions requiring multi-step computation, steering can yield shorter explicit reasoning traces compared to standard chain-of-thought prompting. (c) On retrieval-heavy questions, latent steering leads the model to explicitly note that step-by-step reasoning is unnecessary. These examples are illustrative and not intended to be exhaustive.
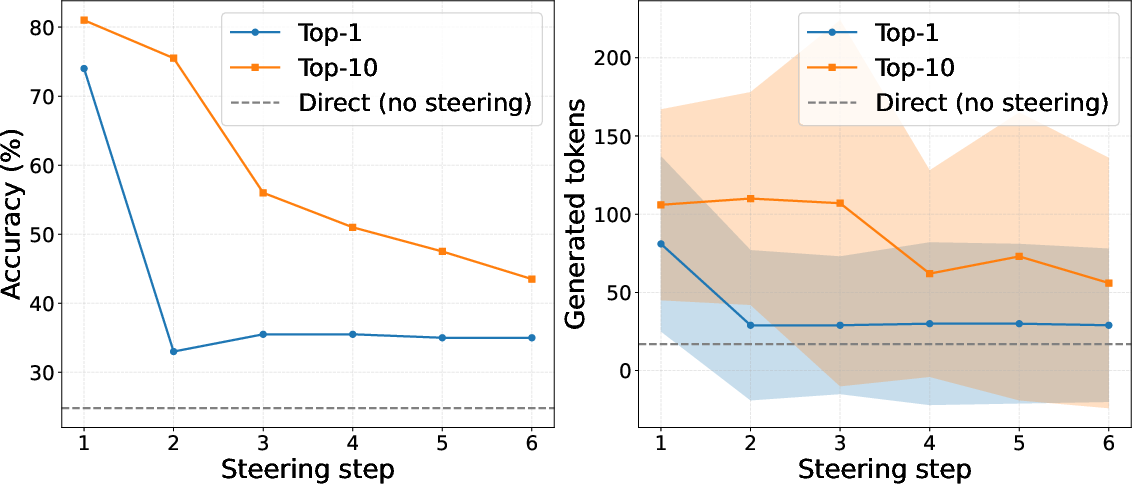
Figure 3: Effect of intervention timing when steering reasoning-related latent features on GSM8K with LLaMA-3.1-8B-Instruct. The figure reports accuracy (left) and generated token length (right) as a function of the decoding step at which the intervention is applied.
Implications and Future Directions
This research posits that reasoning in LLMs involves latent computational modes that can be externally triggered. CoT prompting, therefore, emerges as one of multiple potential triggers rather than a unique cause of reasoning. Practically, the findings suggest that optimization of reasoning strategies might benefit from focusing on latent state interventions, enhancing efficiency and interpretability in LLMs.
The study opens avenues for further exploration into fine-grained interventions on LLM activations. Future investigations could explore fully disentangled reasoning mechanisms and the transferability of latent features across diverse reasoning tasks. Additionally, examining the interplay between latent features and task-specific architectures could unlock more adaptable AI systems.
Conclusion
Overall, the paper challenges prior assumptions about reasoning in LLMs by demonstrating that latent computational modes underpin reasoning capabilities. Through careful identification and manipulation of reasoning-related features, the study highlights the versatility of latent steering as a tool for understanding and enhancing reasoning abilities in LLMs. These insights contribute significantly to the broader discourse on the interpretability and control of neural computation in advanced AI systems.