- The paper demonstrates a novel architecture integrating six modular AI microservices to support real-time, multimodal language education for hearing and deaf users.
- It achieves high performance with EuroLLM Instruct translation scoring a BLEU of 84.34 and sign language rendering under 300 ms using Whisper and AWS Polly.
- The platform’s scalable, service-oriented design in a Unity XR environment on Meta Quest 3 paves the way for future innovations in accessible education.
AI-Driven Modular Multilingual Education in XR: Integrative Accessible Services for Hearing and Deaf Learners
System Overview and Architectural Innovations
The paper "AI-Driven Modular Services for Accessible Multilingual Education in Immersive Extended Reality Settings: Integrating Speech Processing, Translation, and Sign Language Rendering" (2604.05591) presents an extensible, service-oriented architecture composed of six modular AI microservices deployed in a Unity-based XR environment. The platform targets critical accessibility gaps in language education, particularly for deaf and hard-of-hearing users, via bidirectional language interaction among speech, text, and sign modalities.
The architecture leverages AWS infrastructure for scalable, robust deployment, supporting real-time, low-latency interaction for both hearing and deaf participants. Independent implementation of each AI service—automatic speech recognition (ASR), multilingual text translation, text-to-speech (TTS), sentiment analysis, dialogue summarisation, and International Sign (IS) gesture rendering—promotes maintainability, modular upgrade paths, and independent scaling.
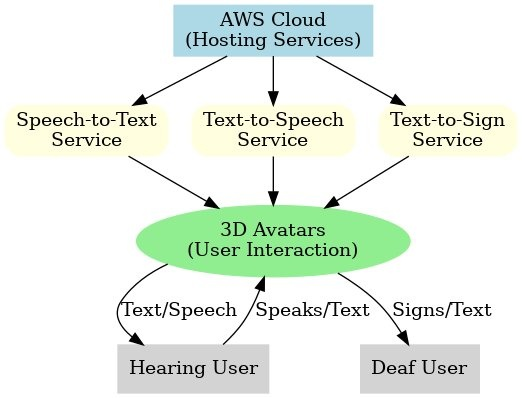
Figure 1: High-level overview of the XR platform architecture, depicting AI microservices accessed by 3D avatars and supporting text, speech, and sign communication.
The pipeline from speech input to avatar output integrates Whisper ASR for transcription, Meta NLLB or EuroLLM for translation, AWS Polly for TTS synthesis, a RoBERTa-based sentiment classifier, Flan-T5 for dialogue summarisation, and a MediaPipe/Unity-based IS animation stack. RESTful APIs serve as the primary interface across all modules.
Speech and Translation Modules: Evaluation and Findings
Speech-to-text transcription is powered by Whisper, delivering robust multilingual ASR with real-time throughput. Benchmarking demonstrates high transcription accuracy even in Greek (Figure 2), affirming Whisper's capacity to generalize to diverse phonetic domains in XR contexts.

Figure 2: Whisper ASR demonstrates high-fidelity speech-to-text conversion, illustrated with Greek input.
For text translation, Meta NLLB-200 and EuroLLM 1.7B (Instruct) were comparatively evaluated. The EuroLLM Instruct variant produced a BLEU score of 84.34—outperforming NLLB's 79.25—with faster inference and acceptable resource profiles on consumer GPUs. The base EuroLLM yielded a BLEU of 27.58, demonstrating the necessity of instruction-tuning for high-recall sentence-level tasks.
Figure 3: NLLB-based translation workflow is demonstrated; the EuroLLM Instruct variant offers superior BLEU and inference speed.
AWS Polly was chosen for TTS production, exhibiting sub-100 ms latency at a competitive cost, with superior mean opinion scores (3.5–3.8) and robust service features for multilingual settings.
Sign Language Rendering, Sentiment, and Summarisation in XR
A distinctive contribution is scalable IS rendering on 3D avatars. The authors curated a dataset of 750 IS gesture videos, extracting 21-point 3D hand landmarks via MediaPipe, normalizing per-wrist, and mapping gesture sequences onto Unity-based avatars with sub-300 ms end-to-end latency. This enables dynamic, real-time IS communication integrated with spoken or textual content.
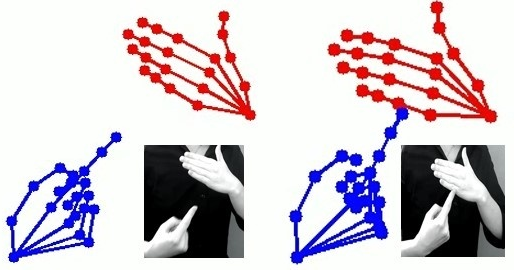
Figure 4: The IS gesture pipeline visualised, including MediaPipe-based landmark extraction and translation to avatar animation.
To enhance avatar social presence, sentiment analysis is mapped to emoticon displays (Figure 5), driven by a RoBERTa-based classifier returning multi-class confidence. The Flan-T5-based summarisation service delivers abstractive dialogue condensation to support session review and assists both hearing and deaf users.

Figure 5: Emoticon-based feedback linked to RoBERTa sentiment analysis enhances XR avatar expressiveness.
XR Learning Environment: User Experience Synthesis
The immersive classroom is implemented with Unity and deployed on Meta Quest 3, supporting multimodal interaction. Avatars blend lip-sync (for TTS) with IS gesture sequences (for sign output) and emotive cues, creating a unified communicative interface. The system supports bidirectional language and sign exchange: speech and text inputs are transcribed, translated, and delivered as both spoken and signed outputs (Figure 6).

Figure 7: Immersive classroom in XR, visualizing a 3D avatar delivering cross-modal content.

Figure 6: MVP demonstration of multilingual, multimodal avatar interaction, with signed, spoken, and text translations plus sentiment feedback.
Key reported metrics include:
- AWS Polly TTS: Consistent first-byte latency of 50–100 ms; MOS up to 3.8.
- Translation BLEU: EuroLLM Instruct variant at 84.34 vs. NLLB at 79.25.
- IS Animation Latency: <300 ms per sign, enabling natural conversational pacing.
- Scalability: 1,000 concurrent simulated users yielded average API response times under 800 ms with no critical service failures.
These findings establish that the platform achieves the stringent latency and throughput demands of real-time XR applications.
Theoretical Implications and Future Directions
The integration of multimodal (text, speech, sign) AI microservices within a single scalable XR architecture directly addresses the persistent lack of accessibility for deaf and hard-of-hearing users in language learning systems. Use of International Sign enables cross-border, cross-linguistic communication, aligning with European policy mandates on digital inclusion and accessibility.
The demonstration that instruction-tuned generalist LLMs (EuroLLM Instruct) can surpass purpose-built translation models (NLLB) on both quality and inference speed for European language pairs motivates further exploration of LLM transfer and fusion for low-resource multimodal translation. The architectural modularity enables rapid updating as stronger models emerge.
The current limitation remains the scope of the IS vocabulary (750 gestures), absence of non-manual marker synthesis, and lack of published user studies or formal usability evaluation. Future work should expand the IS corpus, develop avatar facial/action units for nuanced sign, and evaluate learning outcomes with standardised instruments. Multi-user interaction and formal educational pilots represent critical next steps.
Conclusion
This research provides a compelling case for service-oriented, modular AI integration of speech, translation, and sign language in immersive XR environments, validated by strong latency benchmarks and translation quality. The platform substantially advances the technical and practical feasibility of accessible, multilingual education for both hearing and deaf users via real-time, cross-modal avatars. Anticipated future work includes expansion of gesture corpora, richer avatar expressivity, formal efficacy assessment, and deployment across diverse learning and business contexts.