- The paper introduces a scalable, open-source ASR framework that leverages a massively multilingual wav2vec 2.0 Transformer to process over 1,600 languages.
- It utilizes the largest labeled and unlabeled speech corpus to date, achieving under 6% CER on benchmark datasets and outperforming existing models like Whisper.
- The study demonstrates effective zero-shot transcription through context examples and emphasizes community-driven data collection for ethical, equitable language inclusion.
Omnilingual ASR: Scaling Automatic Speech Recognition to 1600+ Languages
Motivation and Socio-Technical Barriers
This work addresses the entrenched imbalance in ASR technology, which has historically served only a limited set of high-resource languages. The authors identify both practical and ethical constraints hindering progress on long-tail (low-resource) languages: the high cost of expert-led data collection, architectural rigidity in established ASR models, and risks related to language sovereignty and community disengagement. Omnilingual ASR reframes these problems by designing for both massive scalability and extensibility, foregrounding open, compensated data collection in partnership with local communities.
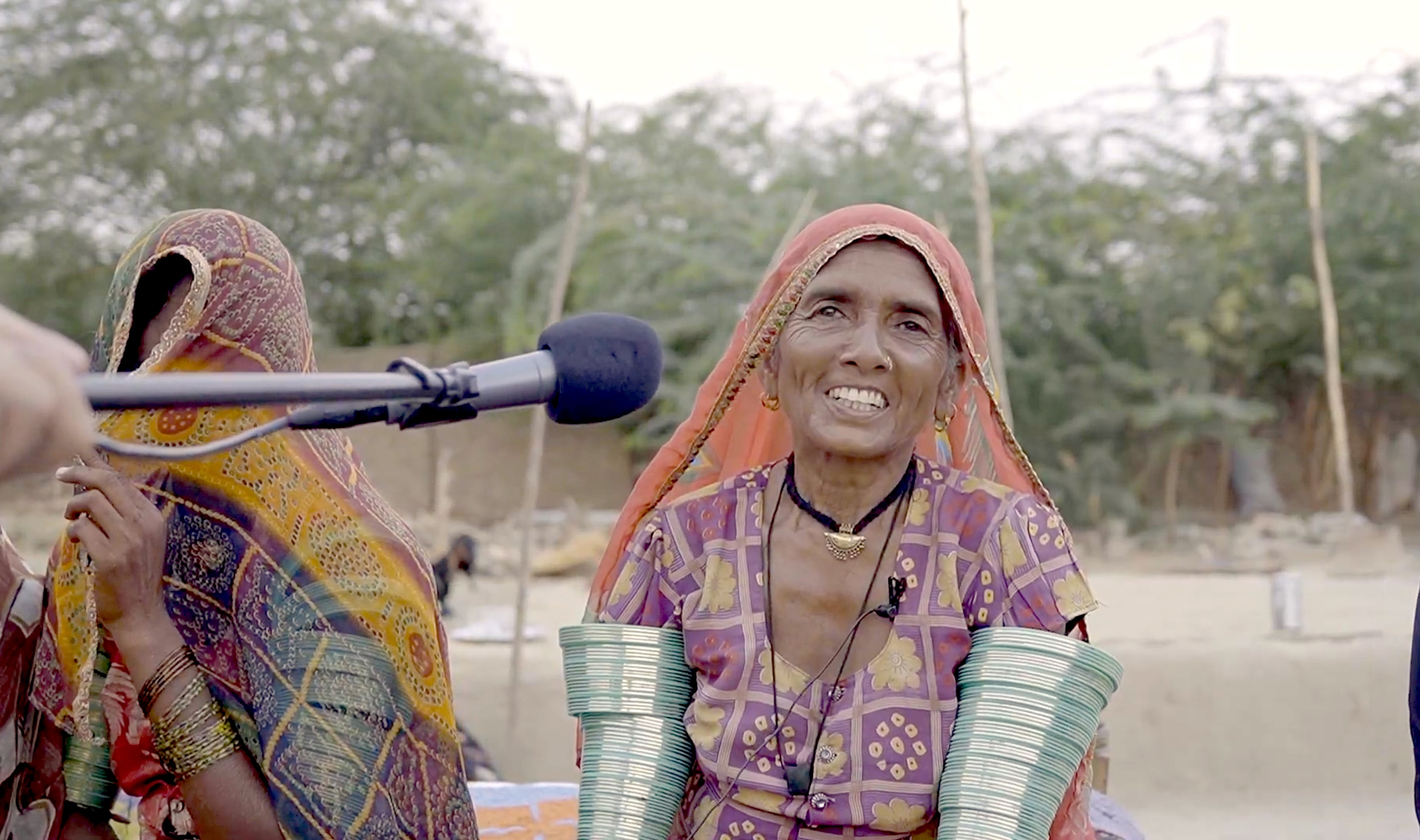


Figure 1: Local participants contributing to corpus creation efforts in Pakistan.
Data Collection and Resource Assembly
A key contribution is the construction and public release of the largest labeled and unlabeled speech corpus yet assembled for ASR. This corpus spans over 1,600 ISO 639-3/Glottolog coded languages, integrating both public resources and a novel dataset commissioned from community partners, with particular emphasis on languages with previously minimal or non-existent digital presence. The data creation process is characterized by local compensation and community involvement, meticulously documented transcription standards for both spoken disfluency and orthographic diversity, and a multi-stage quality assurance pipeline.
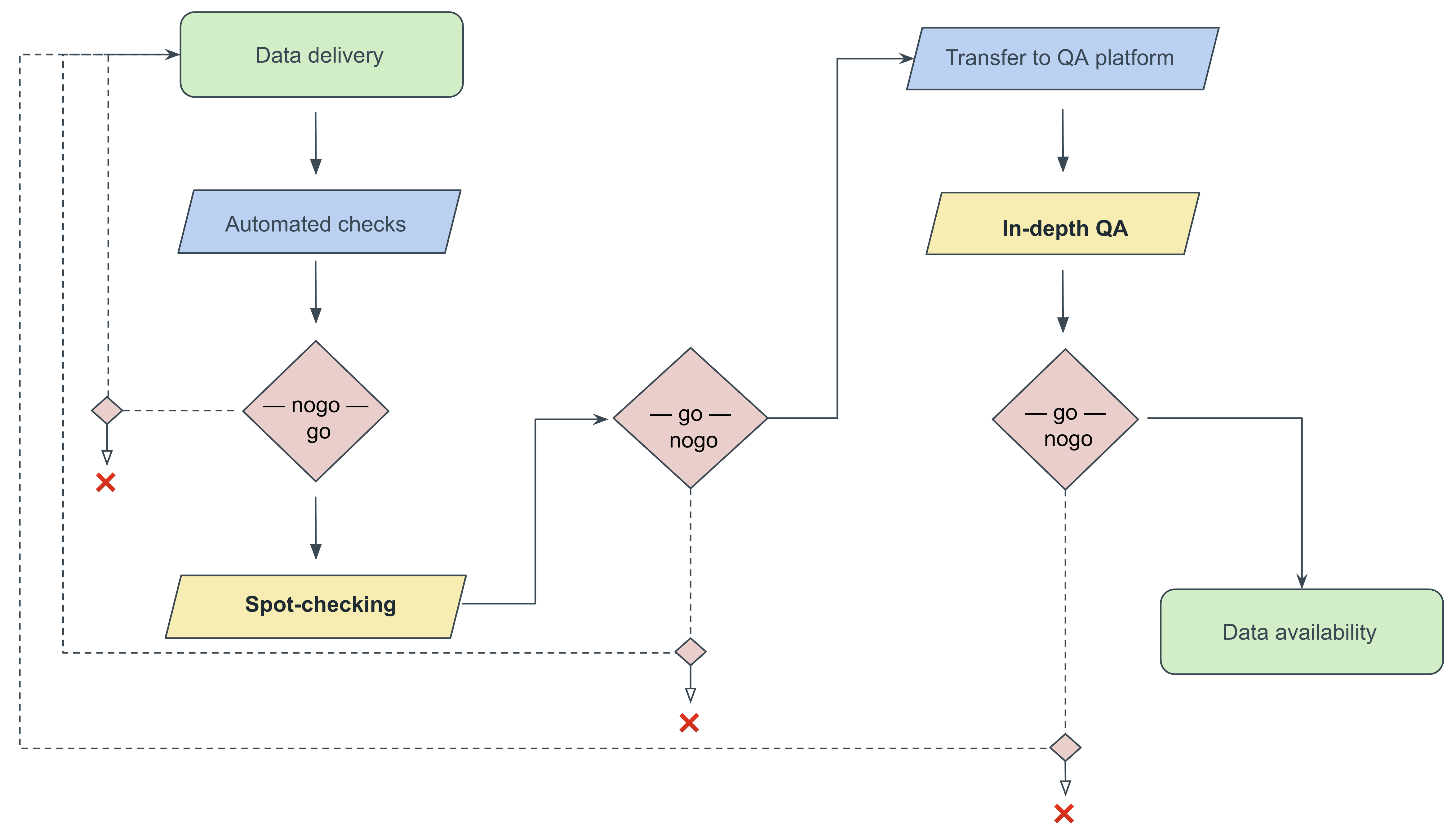
Figure 2: Commissioned data quality-assurance workflow.
The labeled training corpus (AllASR) and the unlabeled pre-training data are both orders of magnitude larger than those used by prior benchmarks. The statistics reveal an average of 10 hours of transcribed speech per language and extensive domain, speaker, and noise diversity.
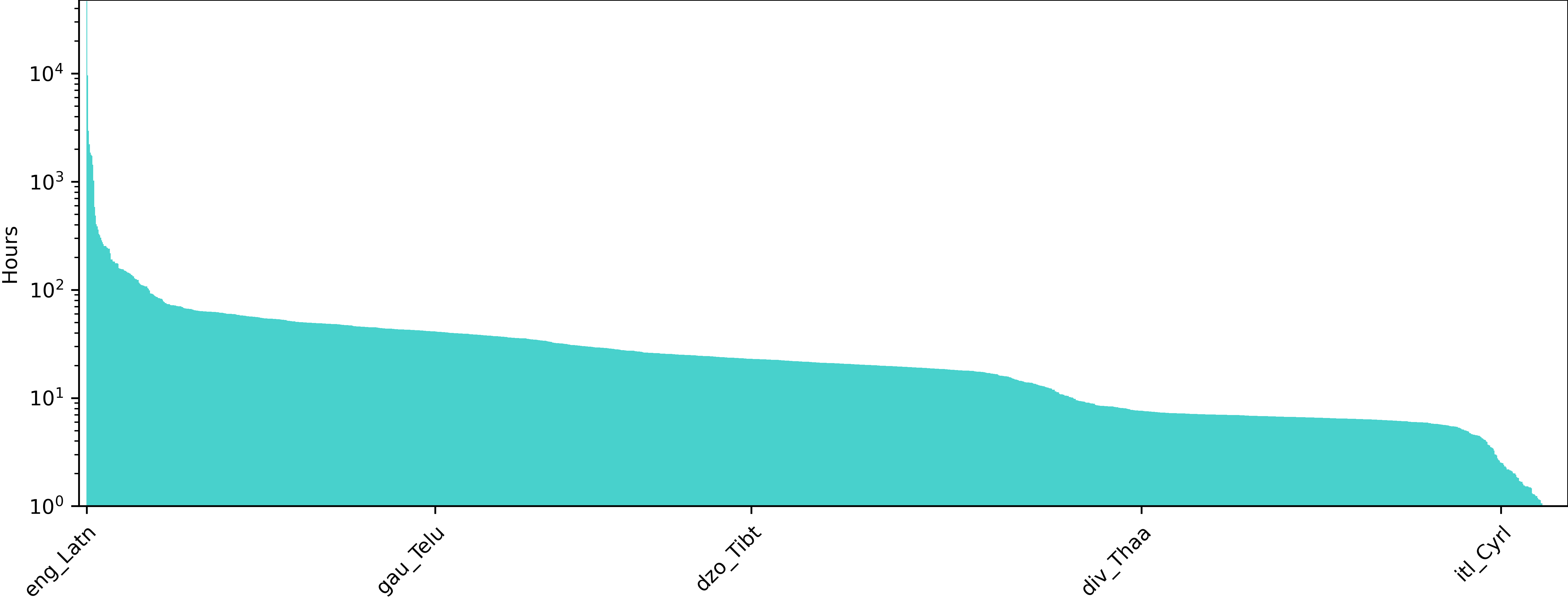
Figure 3: Statistics of the AllASR labeled data (hours of speech recordings paired with transcription) used to pre-train Omnilingual ASR.
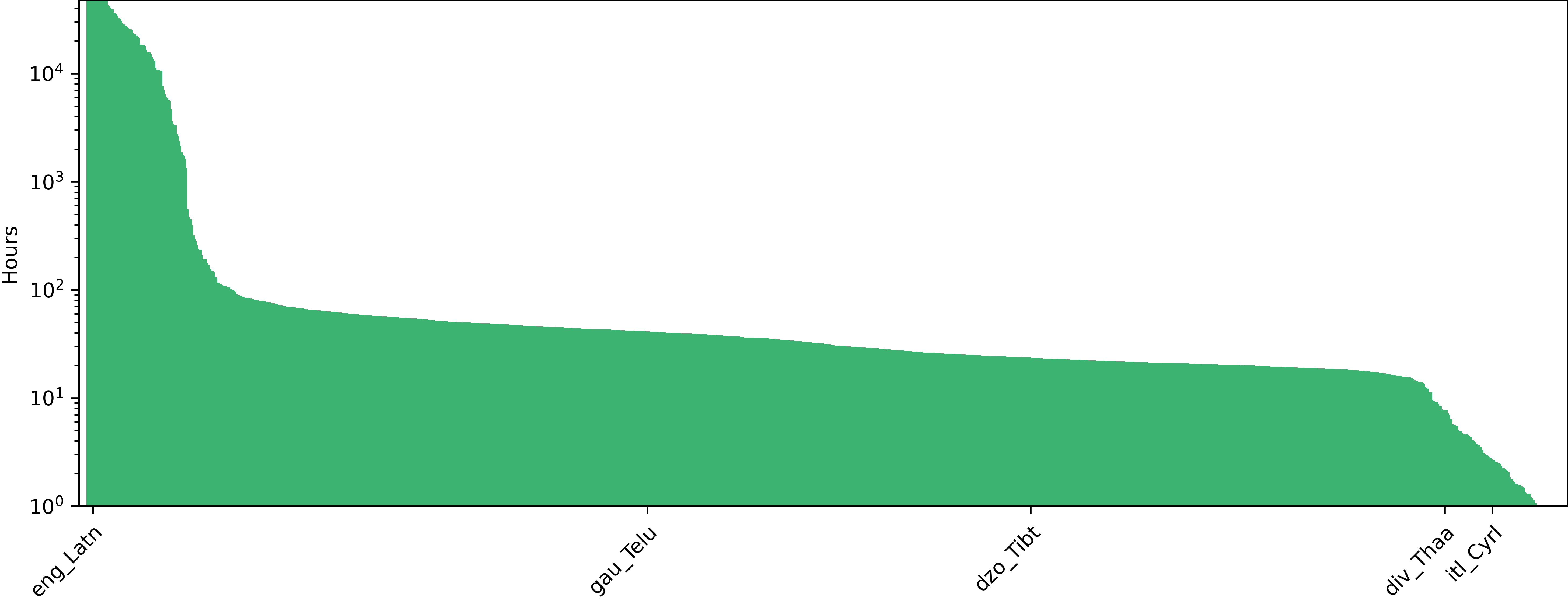
Figure 4: Statistics of the unlabeled data (hours of speech recordings) used to fine-tune Omnilingual ASR for the ASR task.
Model Architecture and Training Regime
Central to Omnilingual ASR is a massively multilingual, scaled-up wav2vec 2.0 Transformer encoder, ranging from 300M to 7B parameters. Self-supervised learning (SSL) is performed on 4.3M hours of untranscribed speech, enforcing balance between high- and low-resource languages through a carefully tuned two-stage sampling regime. The ASR head is either a CTC output layer or an LLM-inspired autoregressive Transformer decoder. The latter ("LLM-ASR") introduces a next-token prediction objective and supports explicit language/script code conditioning for script-ambiguous languages.
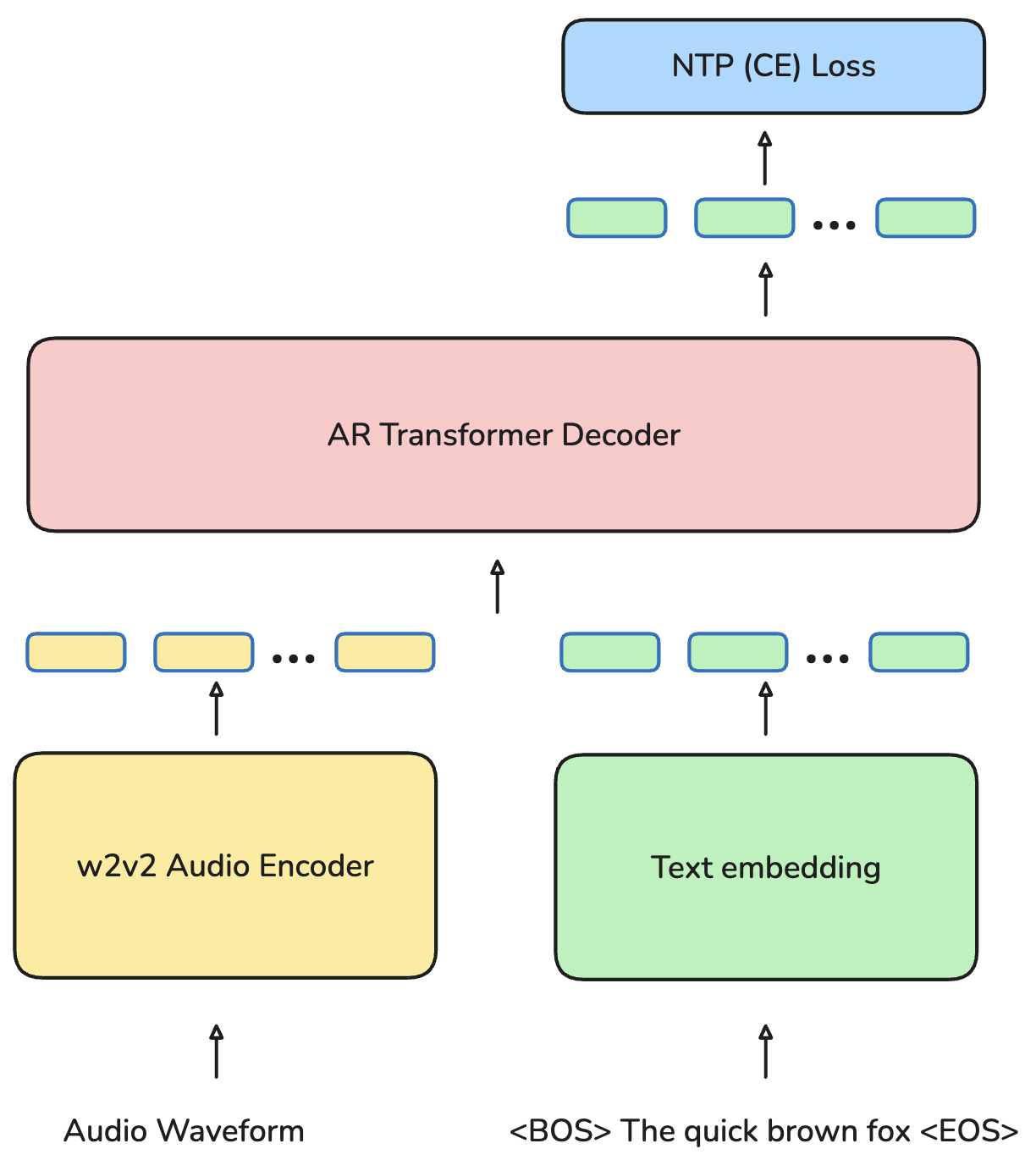
Figure 5: The LLM-ASR model architecture. A wav2vec~2.0 speech encoder and a text embedding matrix embed the speech and text modalities. An autoregressive Transformer decoder emits text tokens, and the system is trained with a next-token prediction objective.
Zero-Shot ASR via In-Context Examples
A novel aspect is the explicit support for zero-shot ASR: unseen languages can be transcribed by providing a handful of paired audio-text utterances (context examples) at inference time, without any further fine-tuning. The LLM-ASR architecture is extended to accept sequences of context examples prepended to the input, and the decoder directly learns to transcribe new utterances conditioned on these in-context pairs. During training, multi-context episode objectives are instilled to facilitate generalization.
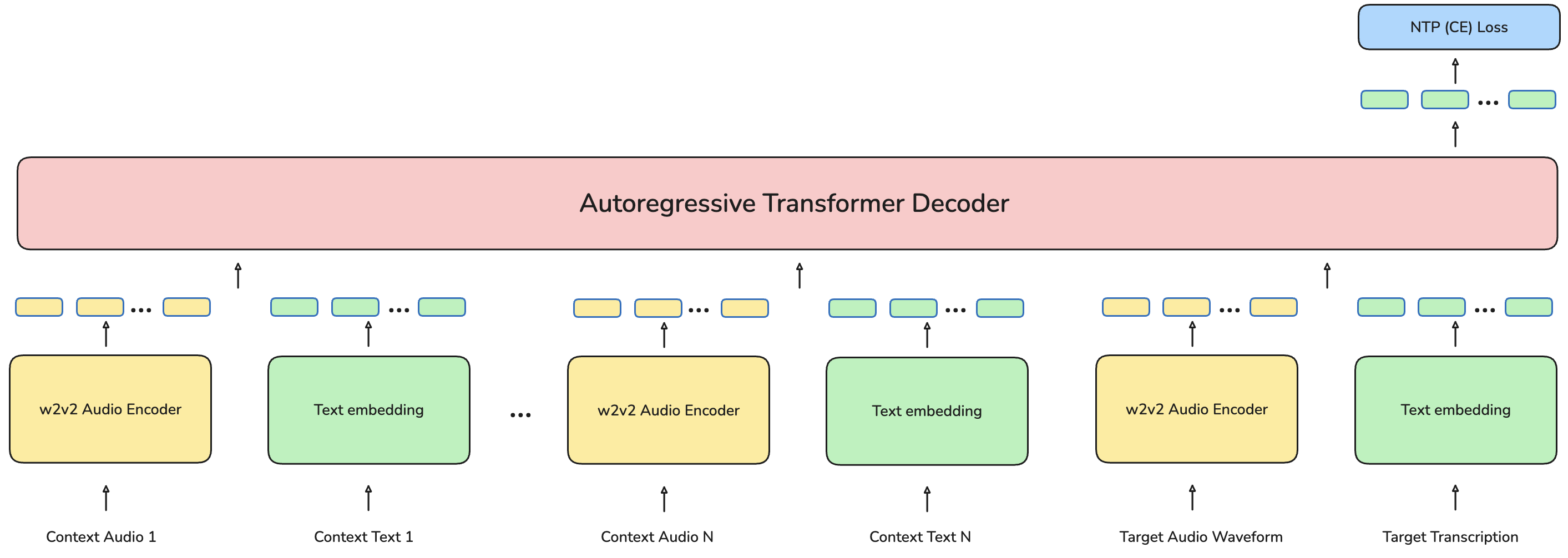
Figure 6: The LLM-ASR model architecture with context examples. Special tokens are omitted for simplicity.
Retrieval and construction of optimal context examples are further explored using dense acoustic/semantic representation approaches (e.g., SONAR encoder retrieval), showing that context example similarity to the test utterance improves zero-shot accuracy substantially.
Empirical Evaluation and Benchmarks
The evaluation covers both supervised and zero-shot regimes:
- Supervised ASR (CTC and LLM-ASR models):
- Outperforms Whisper-v3 and Google's USM on all multilingual test sets evaluated, including FLEURS and Common Voice, achieving average CER below 6% on FLEURS-102 with the 7B-LLM-ASR variant.
- Covers over 500 languages not previously supported by any ASR system; achieves CER ≤ 10% for 78% of 1570 languages assessed.
- Demonstrates that 300M-parameter variants approach the performance of Whisper large models, with the 7B models consistently dominating all prior work even for the most spoken languages.
- In extreme low-resource settings (<10 hours of training per language), Omnilingual ASR achieves mean CER of 18% and under, outperforming all baselines.
- Zero-Shot ASR:
- Noise and Domain Robustness:
- Performance degrades gracefully in the presence of severe background interference, remaining robust across resource-level, speaker, and SI-SDR quantiles.
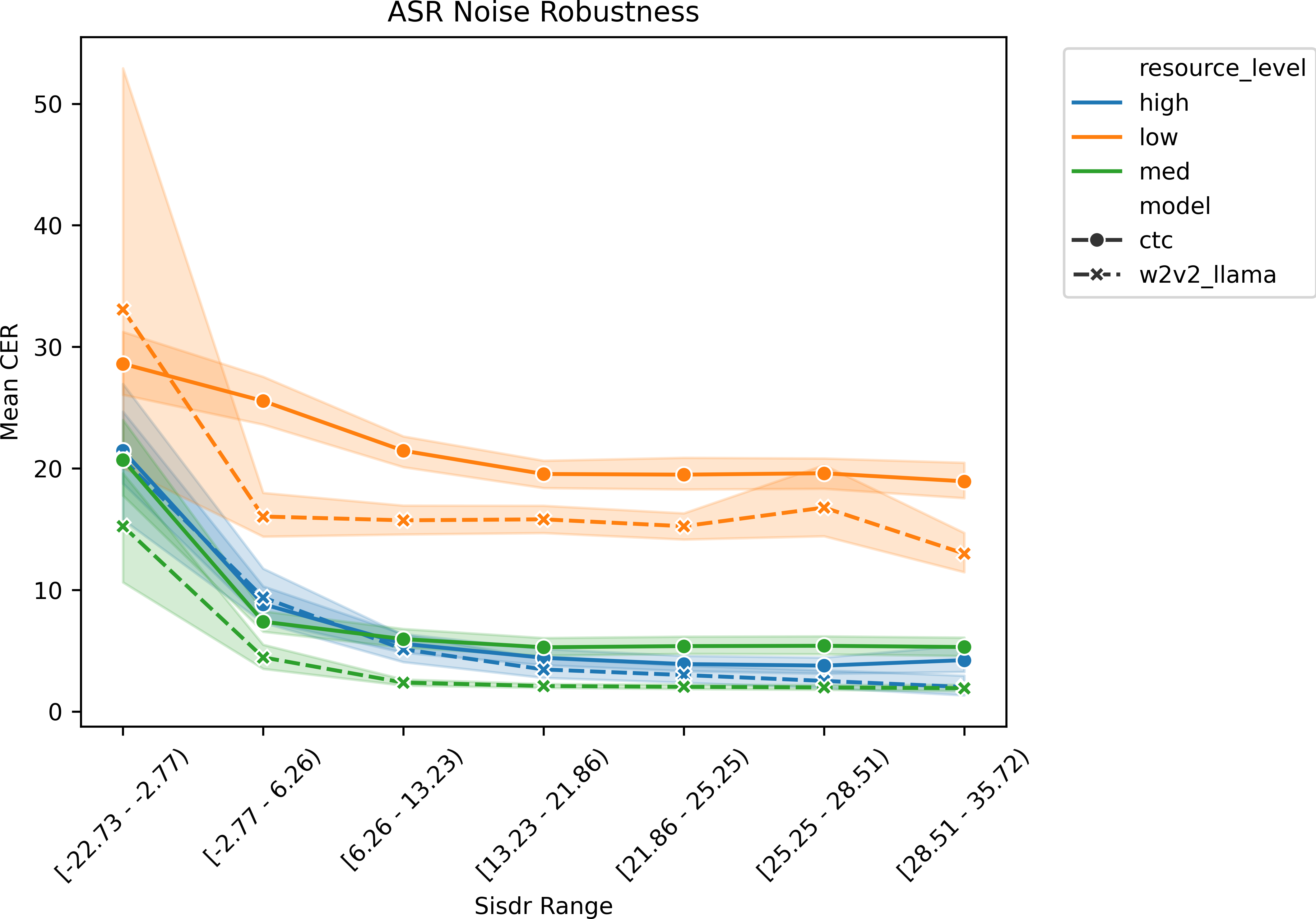
Figure 8: ASR noise robustness across All_ASR dev sets. Utterances were binned into SI-SDR ranges that showcase the outliers with low SI-SDR values, up through the rest of the distribution. Mean CER values, averaged across languages (y-axis), are plotted against SI-SDR range (x-axis) of the associated audio.
Ablation and Fine-Tuning Insights
Ablations highlight several key findings:
- Upsampling strategies balancing data source and language prevalence are essential. Uniform sampling maximizes coverage but at a slight cost to very high-resource language accuracy; moderate upsampling is adopted in the final training mix.
- Language/script code conditioning in the LLM-ASR model eliminates script confusions without sacrificing unsupervised language detection.
- Language-specific fine-tuning of even 300M-1B parameter models on low-resource languages yields strong performance gains with minimal compute, approaching or surpassing the 7B LLM-ASR variant.
- Fine-tuning on challenging domains and real-world audio conditions is critical; holding out field-collected data results in over 2x degradation in CER for new languages, emphasizing the importance of in-domain examples.
Practical and Theoretical Implications
This work contradicts prior assumptions regarding diminishing returns of scaling ASR to thousands of languages and the impracticality of community-origin extensibility. The release of a family of open-source models ranging from 300M to 7B parameters enables both high-accuracy, resource-demanding applications and deployment on low-power devices. The open-source data collection framework and careful governance set a technical precedent for equitable participation and adaptation by non-expert, local actors.
Deployments in community health, civic information, and heritage preservation are cited, but the authors explicitly caution about repurposing risks, such as surveillance. Compensation and governance arrangements are highlighted as ongoing ethical priorities. The methodology sets a new foundation for both ASR and broader multimodal, low-resource language AI, demonstrating that extensive coverage and robust zero-shot generalization are feasible under both practical and socially responsible constraints.
Conclusion
Omnilingual ASR delivers a practical blueprint for scalable, extensible, and equitable multilingual ASR, both pushing state-of-the-art recognition quality and reframing the technical and ethical contours of language technology development. The demonstrated ability to accommodate over 1,600 languages, including hundreds never previously digitized, with robust zero-shot extension and support for open data/participation, has direct implications for digital inclusion and the future of AI-driven language preservation. The modular, open infrastructure will almost certainly inform future work in continual learning, federated adaptation, and collaborative governance for massively multilingual models.

