- The paper presents a comprehensive AI framework integrating Whisper ASR (mean latency 1.2 s, >85% accuracy), NLLB translation, and real-time 3D ISL avatar rendering.
- It employs a modular architecture with scalable AI modules deployed on Meta Quest 3, sustaining up to 1,000 users and handling 10,000 concurrent requests in stress tests.
- User evaluations reported a 92% satisfaction rate and high technical performance, demonstrating effective and inclusive communication for diverse settings.
INTERACT: An AI-Driven Extended Reality Framework for Accessible Communication Featuring Real-Time Sign Language Interpretation and Emotion Recognition
Introduction and Motivation
The paper "INTERACT: An AI-Driven Extended Reality Framework for Accessible Communication Featuring Real-Time Sign Language Interpretation and Emotion Recognition" (2604.05605) systematically addresses accessibility deficits persisting in contemporary video conferencing platforms, particularly for deaf, hard-of-hearing, and multilingual users. Conventional solutions rely heavily on costly human interpreters and offer only piecemeal technological support, frequently lacking cohesive, real-time integration of speech-to-text, sign language, translation, and affective cues within a unified environment.
INTERACT is introduced as an end-to-end, AI-driven XR architecture, designed to collapse these silos and deliver comprehensive accessibility. By integrating modules for ASR (Whisper), multilingual NMT (NLLB), ISL avatar rendering, and emotion analysis (DistilRoBERTa), deployed on hardware such as Meta Quest 3 headsets, the platform aims to set a technical and practical benchmark for immersive, inclusive communication systems.
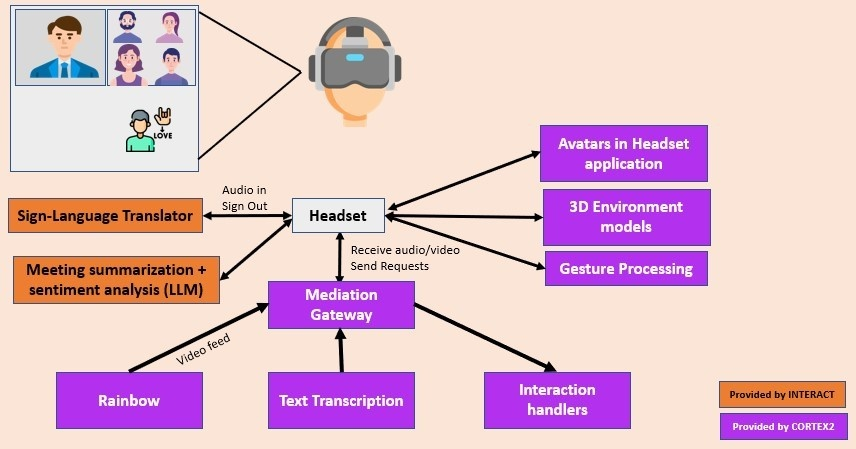
Figure 1: INTERACT system architecture showing modular integration across CORTEX2 and AI service components from audio input to XR output.
System Architecture and Technical Realization
The INTERACT system is architected within the CORTEX2 framework, utilizing modular, independently scalable AI services for each core accessibility channel. The pipeline comprises:
- Speech-to-Text Conversion: Chunked real-time ASR utilizing Whisper Large-v2, implemented with streaming via WebSockets and optimized overlap-window chunking for transcript latency and resilience (mean latency 1.2 s, accuracy >85%).

Figure 2: Speech-to-Text processing pipeline using chunking, Whisper inference, and text assembly to yield live transcriptions.
- Multilingual Translation: The NLLB distilled model (600M parameters) performs language detection and translation, achieving mean BLEU-aligned quality with an 0.8 s mean latency for English–French, engineered for extensibility to further TMs.
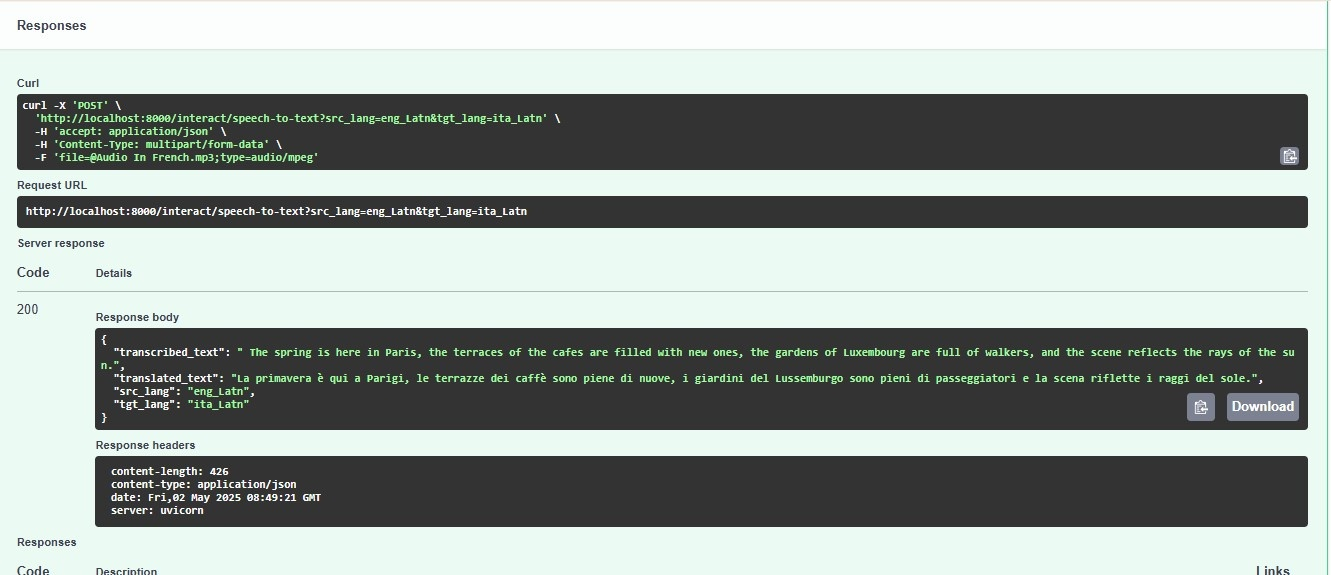
Figure 3: Multilingual translation workflow from source recognition to NLLB inference and distribution of translated sequence to downstream modules.
- ISL Gesture Extraction and 3D Avatar Animation: ISL video corpora are processed via MediaPipe Holistic for pose estimation, extracting 3D skeletal trajectories, which are then mapped to Unity avatar rigs for signing synthesis (vocabulary coverage: 750 signs). Avatar behavior is evaluated in terms of spatial fidelity and communicative efficiency.
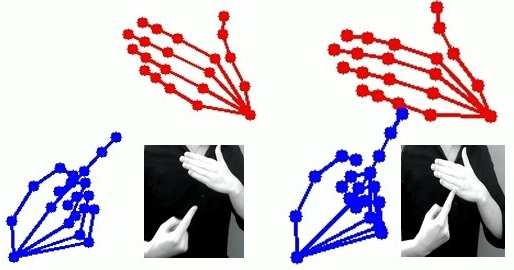
Figure 4: ISL gesture extraction pipeline showing the transformation from source video frames to 3D trajectory for avatar animation.
- Real-Time Avatar Rendering: 3D ISL avatars are visualized within the XR meeting environment, tracked from multiple perspectives to ensure sign intelligibility and alignment with the communicative scene.
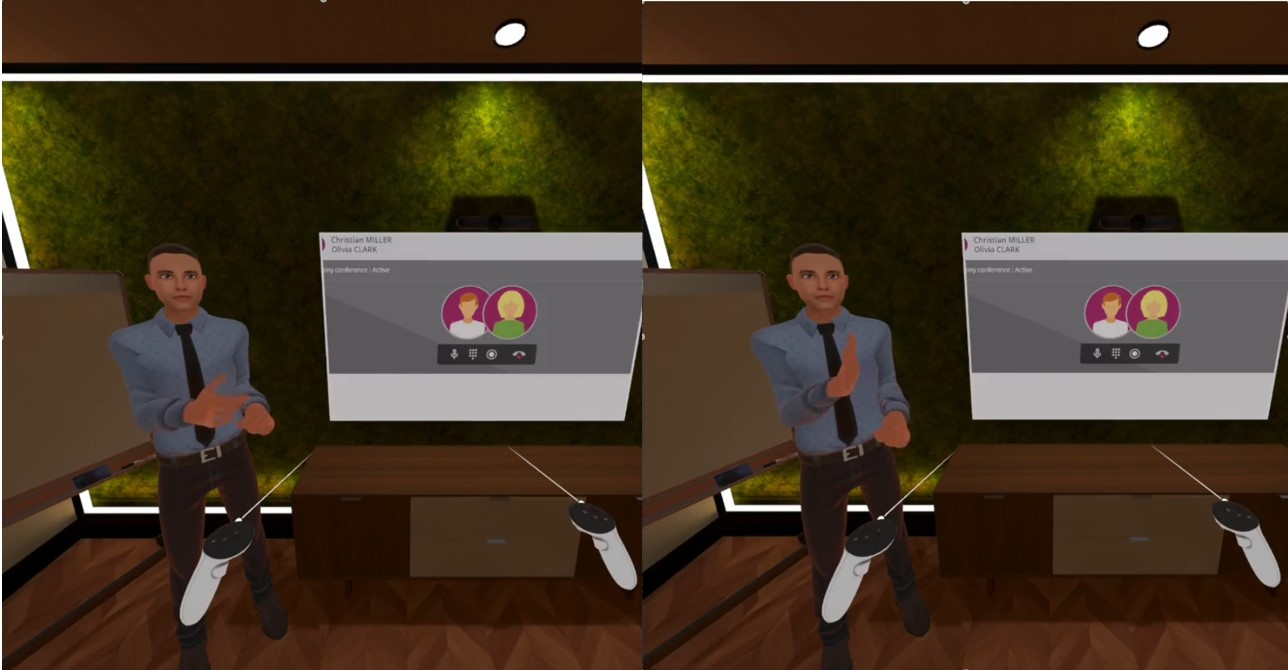
Figure 5: 3D avatar performing ISL signs from multiple angles within the XR environment, demonstrating practical deployment for sign language dissemination.
- Emotion Analysis: The emotion pipeline applies DistilRoBERTa to transcribed text, classifying utterances into six emotional states, with outputs affecting avatar facial rigs and optional emoji overlays, realized under 200 ms latency with >90% precision.
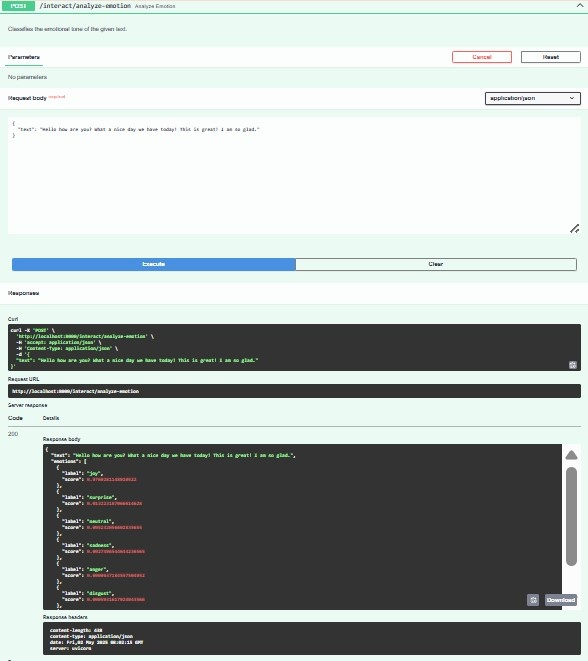
Figure 6: Emotion detection integration where textual transcriptions are annotated for affect and reflected in avatar facial modulation.
- Summarisation: Accumulated transcripts are processed with a fine-tuned BART-Large on the SAMSum dataset, producing structured meeting records (decisions, action items) accessible asynchronously or for post-event review.
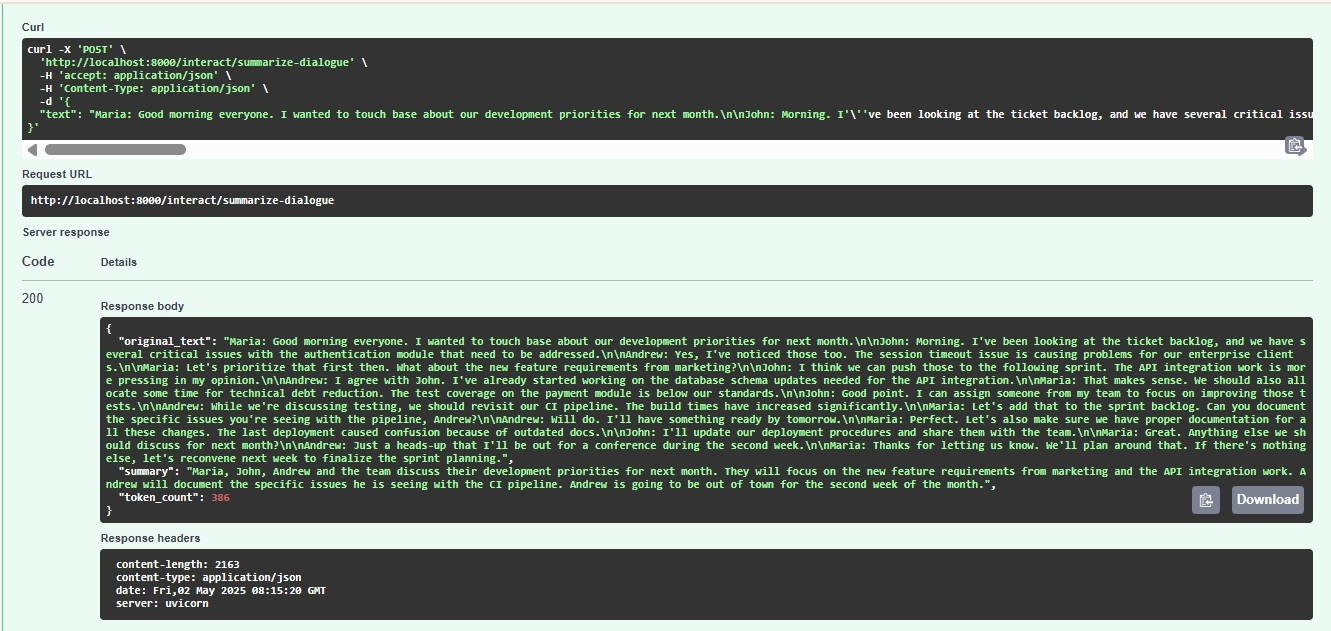
Figure 7: Meeting summarisation: BART-driven process yielding concise highlights and key points for archival and accessibility purposes.
- XR Environment and Conferencing Integration: The Unity/Meta XR stack supports ergonomic placement of avatars and content overlays, integrated with the Rainbow SDK for audio and participant management.
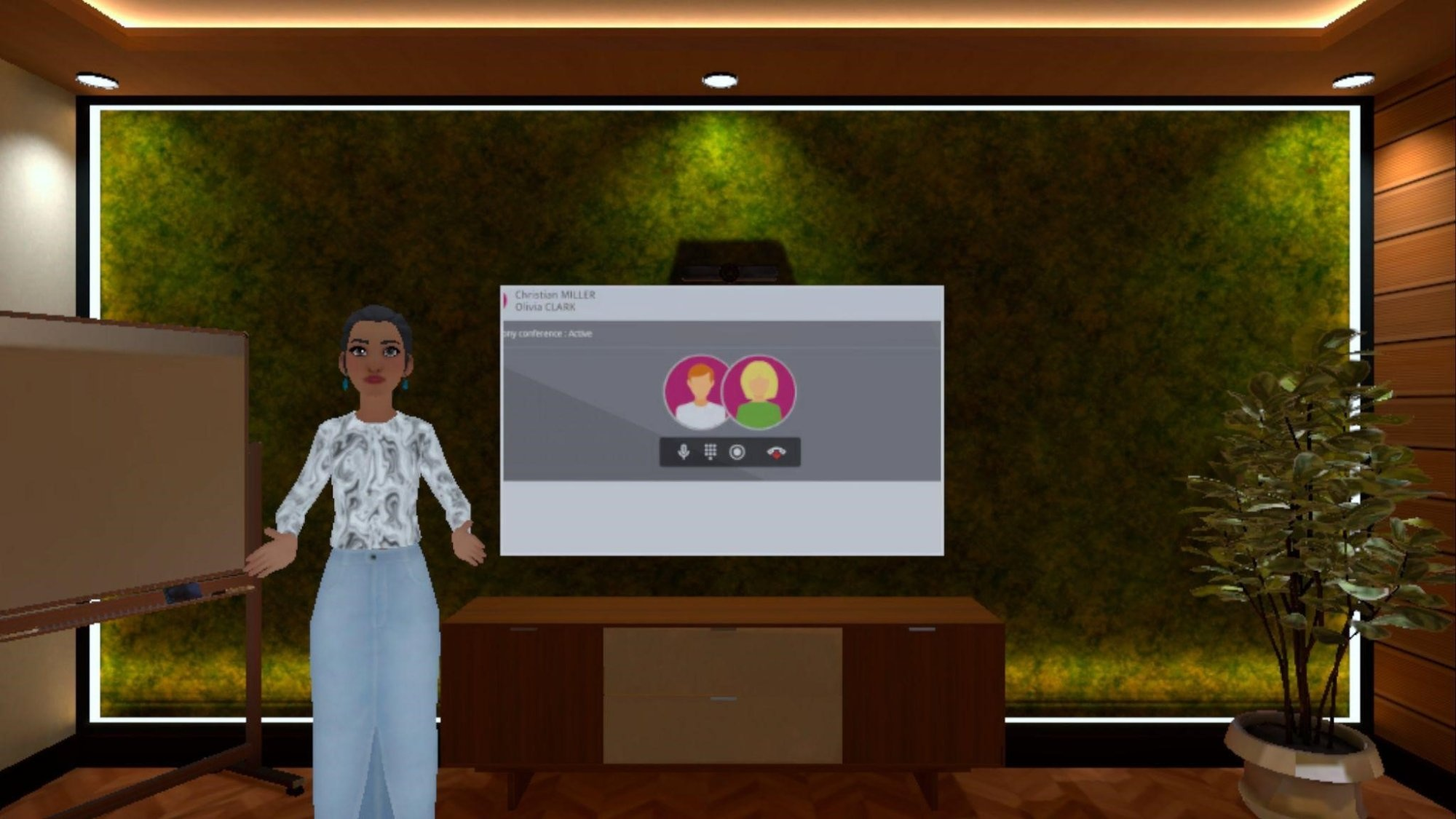
Figure 8: Full virtual office setting illustrating participant spatialization and signing avatar integration for maximal accessibility.
Figure 9: SDK and AI module integration within Unity, visualizing data flow among conferencing, AI, and rendering subsystems.
- End-to-End Communication: Real-time ISL avatar animation, synchronized with emotion detection, is rendered as participants communicate, leveraging the streaming and modular architecture.
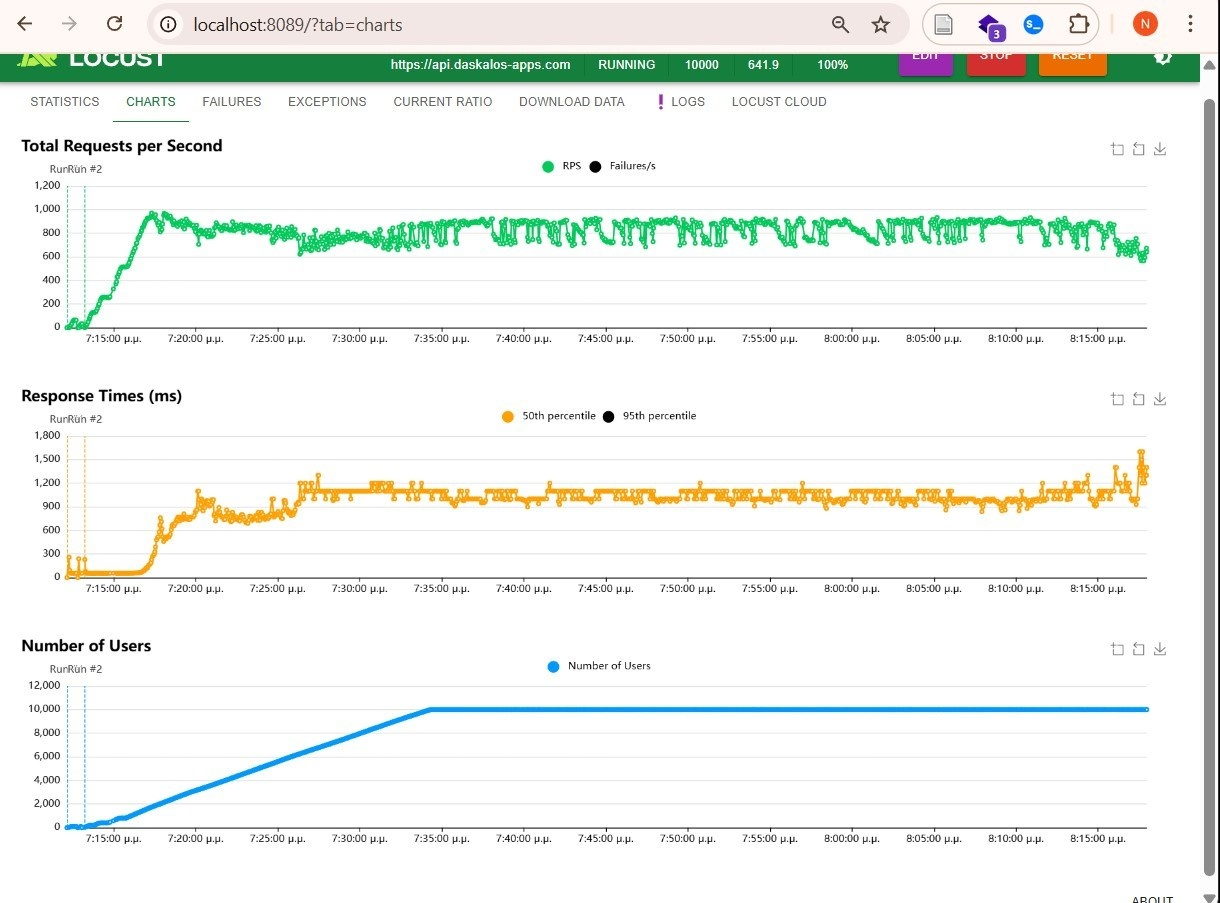
Figure 10: VR scene demonstrating ISL avatar animation and emotion feedback in response to live spoken interactions.
Evaluation and Empirical Results
A two-stage pilot evaluation protocol was adopted: technical experts assessed system reliability and modifiability; deaf community members evaluated linguistic accuracy, avatar expressiveness, and accessibility value. Notably:
Participant feedback strongly emphasized the requirement for further enhancement of avatar facial expression for authentic ISL grammatical and affective communication, as well as expedited expansion of language pairs and vocabulary customizability.
Limitations
Primary limitations concern ISL vocabulary coverage (currently 750 items) and insufficient facial expression integration in avatar signing. The pipeline’s fallback on fingerspelling for out-of-vocabulary terms and limited support for languages outside English–French reduce the system’s universality. Evaluations, while methodologically rigorous, were based on modest sample sizes, warranting expanded future studies.
Implications and Prospective Developments
The INTERACT framework establishes a practical pathway toward genuinely accessible XR communication for sensory and linguistic minorities in professional and educational domains. Practically, the platform enables scalable deployment across a spectrum of collaborative contexts, contingent on further extension of sign language corpora (including advanced facial/grin markers), incremental addition of TM directions, and broader integration with conferencing platforms.
Theoretical implications underscore the benefit of modular, interface-driven AI pipeline architectures for accessibility: each component can be replaced or extended as new SOTA models emerge (e.g., neural sign generation supplanting dictionary- or template-based methods). End-user involvement is demonstrated to be central for evaluating not only performance but authenticity and communicative success.
Development trajectories will likely include adoption of S2S neural models tailored for ISL sequence generation, dynamic adaptation of signing pace to context/user preference, incorporation of lip-sync and ISL grammatical features, and multimodal input/output channels. The architecture offers a testbed for real-world evaluation of affective computing and ASR/NMT paradigms in multi-agent, immersive settings.
Conclusion
INTERACT provides a rigorously validated, modular, and scalable blueprint for XR-based, AI-driven accessible communication platforms, substantiated by high user satisfaction and technical performance metrics. Its open-source design, strong empirical validation with diverse stakeholders, and extensible architecture position it as a reference for future applied research and large-scale deployment in accessible XR communication systems (2604.05605).