- The paper introduces a dynamic framework that models dialogue as a set of discourse trees, improving context utilization in complex conversations.
- It employs semantic clustering and a two-stage branch management process to achieve up to +9.7% relative TCR improvement and an 88.9% absolute TCR on GPT-4.1.
- Experimental results show a 45–52% reduction in context tokens, underscoring enhanced efficiency and reduced redundancy in dialogue processing.
Dynamic Discourse Trees for Non-Linear Dialogue: The Context-Agent Framework
Introduction
"Context-Agent: Dynamic Discourse Trees for Non-Linear Dialogue" (2604.05552) addresses the inefficacy of modeling dialogue history as flat, linear token sequences in LLM-based dialogue systems. The paper posits that the inherent branching and hierarchical structure of human dialogue, such as frequent topic shifts and instruction refinements, is mismatched with the prevailing linear approaches. This misalignment leads to diminished context utilization and a loss of coherence in long, dynamic multi-turn interactions—a challenge unmitigated by simple context window expansion or naive compression strategies.
The proposed solution, Context-Agent, formalizes and implements dialogue history as a dynamic forest of topic trees, explicitly modeling topic branching and discourse-level intent. Alongside, the authors introduce the Non-linear Task Multi-turn Dialogue (NTM) benchmark, designed to stress-test context management paradigms with dialogues featuring multiple topic shifts, complex instruction refinements, and long-horizon task dependencies.
Methodology: Discourse Trees and Dynamic Context Construction
The Context-Agent framework structures dialogue as a set of topic trees, where each node corresponds to a (user, agent) exchange, and branches model distinct dialogue threads under the same or diverging topics. The system continuously updates the state based on queries, utilizing lightweight models for topic/branch decision and semantic clustering for fork-point identification.
Each dialogue turn involves:
- Topic identification (new, switch, or continue), using branch and topic summaries.
- Fork-point detection, leveraging embeddings to discover the closest semantic ancestor.
- Branch management, decided via a two-stage process (heuristic filtering + LM-driven action).
- Selective construction of context: full active-path history plus hierarchical branch/topic summaries.
This structure directly enforces logical separation of threads, minimizing retrieval confounds common in flat history compression and flat RAG, and ensuring efficient path-aware context retrieval.
The NTM Benchmark: Measuring Non-Linear Dialogue Competence
The NTM benchmark comprises 405 dialogues (~6900 turns), with lengths of 10–25 turns each, across daily planning and coding domains. Dialogues are engineered for multiple topic shifts and instruction refinements rather than purely information-centric QA, with each session terminating in an objectively verifiable multi-checkpoint task.
Evaluation focuses on Task Completion Rate (TCR, per-turn checkpoint success) and Average Context Tokens (ACT, per-turn token usage), supporting joint assessment of coherence, task orientation, and computational efficiency.
Experimental Results
Extensive experiments across four distinct LLMs (GPT-4.1, DeepSeek-V3, GLM-4-Plus, Llama 3.1-70B) demonstrate several notable findings:
- Context-Agent consistently improves TCR over both truncation and even Full-History linear baselines, with relative gains up to +9.7% (Llama 3.1-70B) and absolute TCR of 88.9% (GPT-4.1).
- Token efficiency is substantially improved: ACT is reduced by 45–52% compared to Full-History concatenation, indicating more focused, less redundant context presentation.
- For TopiOCQA, Context-Agent increases factual answer accuracy (EM, F1), using only ~57% of baseline context tokens, demonstrating generalization to open-domain QA with topic shifts.
The results decisively indicate that merely increasing the context window size is insufficient for non-linear dialogue management. Even massive-window models like GPT-4.1 and Llama 3.1-70B benefit significantly from the structured context.
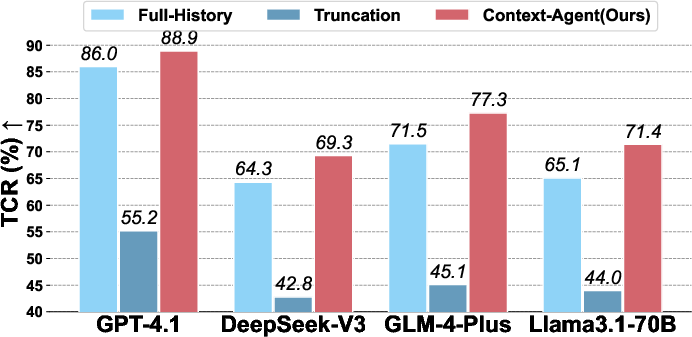
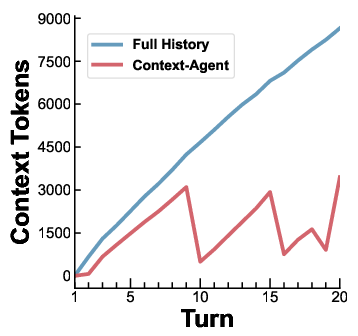
Figure 2: (a) TCR comparison across context management methods and models. (b) Example trajectory of context token usage in a 20-turn dialogue, highlighting greater efficiency with Context-Agent.
Analysis shows that token consumption with Context-Agent grows sub-linearly with dialogue length, while task accuracy remains robust or even improves—a strong endorsement of the value in explicit discourse modeling.
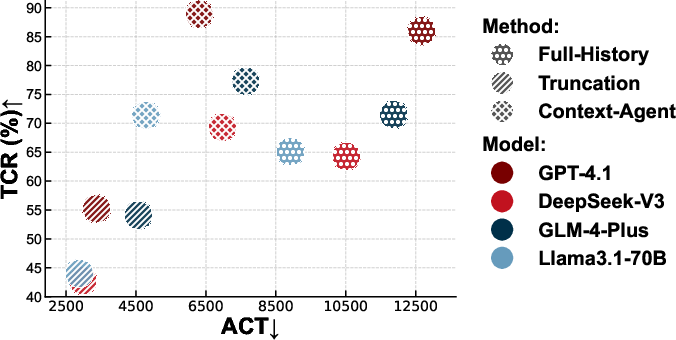
Figure 4: The trade-off between TCR and ACT, with optimal methods in the top-left quadrant (high accuracy, low token usage); Context-Agent dominates the efficiency frontier.
Ablation studies further underscore the necessity of both tree structure and semantic RAG: removing either yields sharp declines in TCR (-29.5% to -35.5% absolute).
Discussion, Implications, and Future Directions
The Context-Agent methodology reifies the intuition from Attentional State theory: human dialogue management is inherently hierarchical and path-sensitive, not simply a function of linear context accumulation. By dynamically representing conversational state as a set of discourse trees and reconciling multiple dialogue threads, LLM-driven agents can sharply reduce token and reasoning redundancy endemic to concatenation/truncation schemes.
Practical implications are significant:
- For LLM agents, Context-Agent allows precise focus amid extended, multi-party, or multi-topic sessions—a necessity for agentic workflows in enterprise and collaborative settings.
- The reduction in ACT unlocks longer interactions before encountering prompt-token limits, or lowers inference cost for otherwise equivalent task accuracy.
- The NTM benchmark fills a clear gap in evaluating discourse-structured, task-oriented dialogue modeling, providing a rigorous standard as LLM applications grow in complexity.
Theoretically, this work points toward integration of explicit, dynamically learned discourse graphs within LLM memory and context modeling architectures, potentially extending to graph-induced attention mechanisms within the model itself. Further, optimizing or end-to-end learning of the decision policies (rather than heuristic/LMM mediation) may yield even stronger gains.
Conclusion
Context-Agent brings explicit branching discourse modeling to the forefront of non-linear dialogue management for LLMs, yielding substantial improvements in both accuracy and context efficiency on challenging, long-horizon conversational tasks. The approach shows robustness across both open- and closed-source LLMs of varying context capacities. These findings strongly support advancing towards explicitly structured, path-aware context management as a foundational component in the development of next-generation conversational agents.