- The paper introduces a training-free method that repurposes SAM3’s promptable segmentation by unifying support and query images for implicit spatial reasoning.
- It achieves state-of-the-art performance on benchmarks like PASCAL-5i and COCO-20i, with significant gains using textual prompts and optimized spatial layouts.
- The study reveals that negative prompts drastically degrade segmentation performance, highlighting challenges in balancing conflicting semantic cues.
Training-Free Few-Shot Semantic Segmentation with SAM3: A Spatial Reasoning Perspective
Introduction
This work addresses Few-Shot Semantic Segmentation (FSS) using vision foundation models, departing from the computationally intensive, episodic training paradigm traditionally used for learning transferable representations. The study leverages Segment Anything Model 3 (SAM3) in a fully frozen state, repurposing its Promptable Concept Segmentation (PCS) capability for FSS without architectural modifications or fine-tuning. The method reframes FSS as a spatial reasoning task: support and query images are geometrically concatenated into a unified spatial canvas, enabling implicit cross-image correspondence within a single forward pass through SAM3’s attention mechanism.
This study achieves strong numerical results on PASCAL-5i and COCO-20i, attaining or exceeding the performance of more elaborate, training-dependent approaches. Additionally, the analysis exposes a significant failure mode: negative prompts, while designed to suppress distractors, degrade performance by weakening target representations and causing prediction collapse. The findings highlight the power and limitations of prompt-centric foundation models in FSS and call attention to unresolved challenges in multimodal prompt interaction.
Methodology: Unified Spatial Canvas for Implicit Cross-Image Reasoning
The core methodological innovation is the reframing of FSS as a single-image segmentation problem via spatial composition. By embedding both the annotated support and the query image within a single canvas, all tokens—regardless of origin—are processed jointly in the self-attention layers of the frozen SAM3. This unifies the support-query interaction into a single forward pass without explicit feature matching or additional architectures.
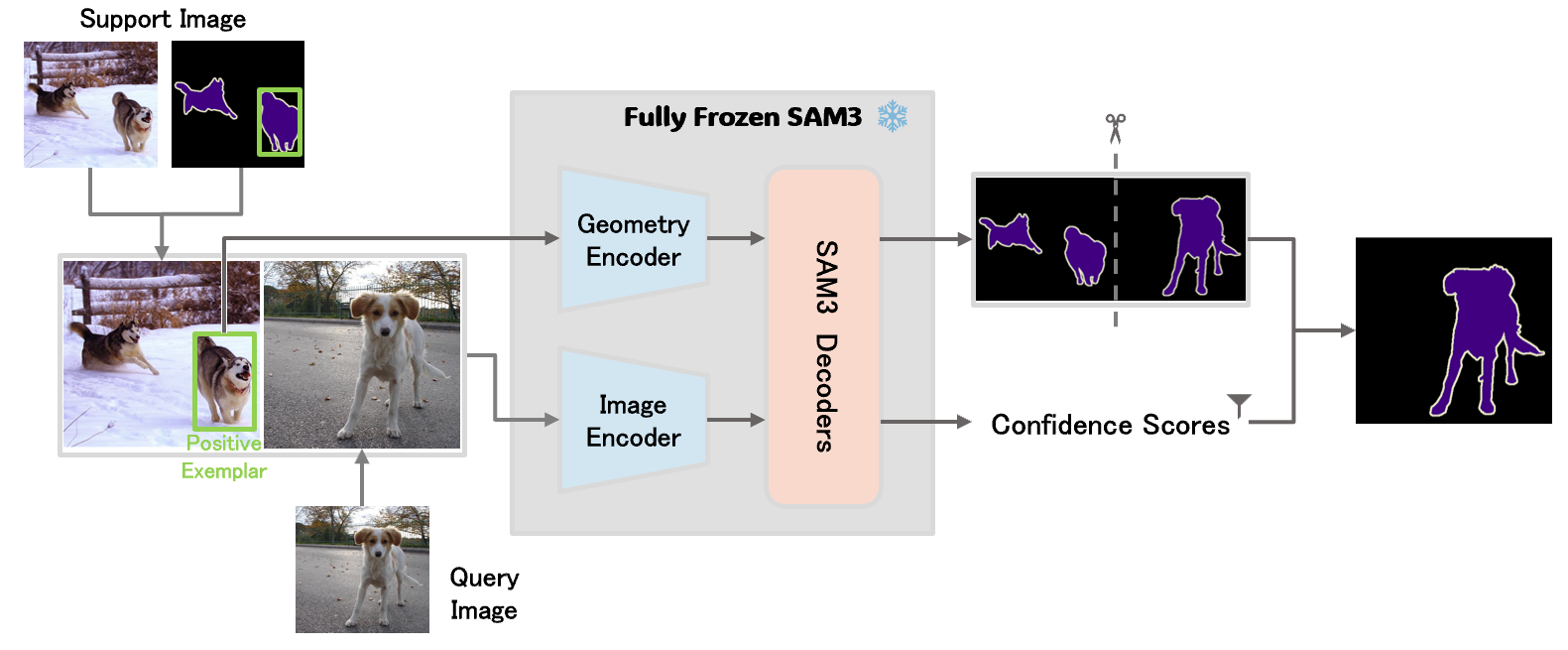
Figure 1: The FSS pipeline built upon SAM3, where instance-aware positive prompts and unified spatial composition enable implicit support-query matching in a forward pass without model modification.
Instance-level prompting is crucial: prompts are derived from tightly localized support object instances rather than global class masks. This enhances spatial precision and reduces ambiguity. Additional experiments incorporate textual category names via SAM3’s text encoder, further boosting semantic alignment. Prompt information (positive prompts and, in ablation, negative prompts) is geometrically aligned with the global canvas coordinates before being input to the decoder.
Benchmark Results
On PASCAL-5i, the method attains 81.6 mIoU in the 1-shot setting and 81.3 mIoU in the 5-shot configuration when text prompts are incorporated. These results are at parity with or surpass state-of-the-art foundation-model approaches and clearly outperform classical, training-dependent FSS baselines.
On COCO-20i, the method delivers 66.1 mIoU (vision-only prompts) and 75.4 mIoU (with textual prompts) in 1-shot, demonstrating a substantial margin (+13.1 over the next-best) over prior FSS methods. The benefit from textual guidance is particularly salient under conditions of larger category diversity and complex visual variation.
Qualitative visualizations substantiate the efficacy of the unified spatial canvas, revealing competitive mask localization for both 1-shot and 5-shot queries across diverse object categories.
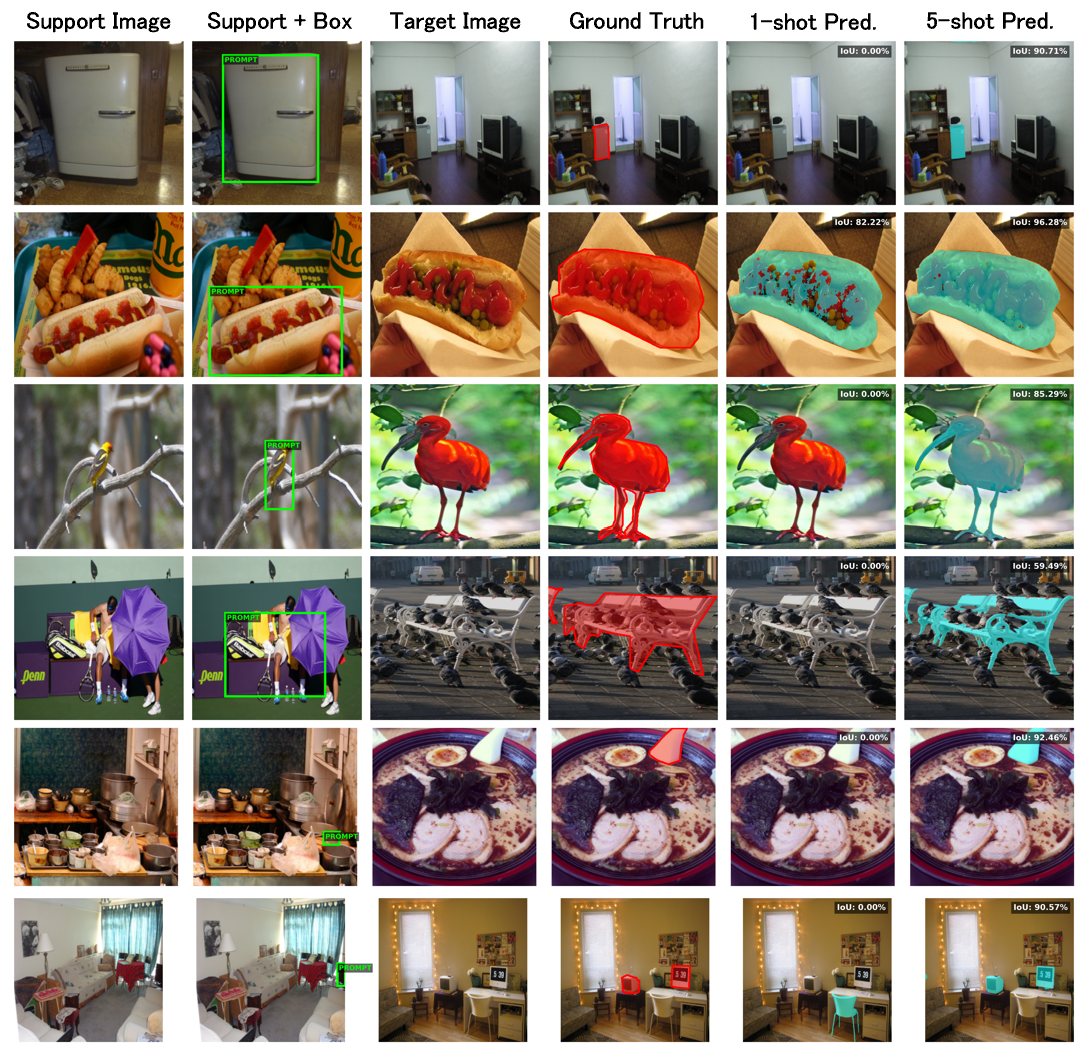
Figure 2: Visual examples of 1-shot and 5-shot predictions on PASCAL-5i demonstrating precise segmentation from sparse annotations.
Ablations and Prompt Modality Analysis
The ablation study reveals that forced resizing and specific spatial layouts (e.g., vertically stacking images with a 6:4 support:query ratio in 1-shot, inverse L-shaped layouts in 5-shot) yield optimal results, maximizing relevant token density. Hybrid prompting (visual and textual) consistently yields superior generalization compared to single-modality prompts, as the two provide complementary signals: visual exemplars enhance instance discrimination, while text aids in category-level robustness.
Analysis of Negative Prompting
A systematic and quantitative investigation into negative prompting exposes a significant and counterintuitive limitation. Contrary to the intent of negative prompts (to suppress distractors), their inclusion results in marked performance drops: up to 21.9 mIoU lost as the number of negative exemplars increases on COCO-20i. Qualitative results show prediction collapse with backgrounds dominating the output, especially as more negatives are introduced.




Figure 3: Comparative results with and without negative prompts. The addition of negatives leads to prediction collapse and loss of target segmentation.
Robustness analyses on MSCOCO further confirm that the presence of negative prompts—whether derived from non-target objects, backgrounds, or multiple regions—uniformly degrades performance, often catastrophically in low-shot regimes. This suggests that the SAM3 prompt processing pipeline is not robust to conflicting semantic cues and lacks a mechanism for stable positive-negative prompt balancing.
Practical and Theoretical Implications
The proposed approach demonstrates that strong FSS performance can be achieved by leveraging pretrained foundation models with minimal architectural engineering—specifically, by spatial formulation that enables implicit cross-image reasoning via self-attention. This significantly reduces the engineering and computational cost for FSS deployment, making it feasible to segment novel classes in real-world applications (e.g., medical imaging, industrial defect detection) where large-scale annotation and retraining are impractical.
Theoretically, the findings challenge the prevailing hypothesis that negative prompting universally enhances segmentation by filtering distractors. Instead, they reveal a clear inconsistency in how current promptable foundation models resolve conflicting or multilayer semantic guidance. The results also suggest that simple spatial juxtaposition is sufficient for strong support-query alignment when leveraging high-capacity attention mechanisms, shifting focus from elaborate feature-matching architectures toward prompt and task formulation.
Limitations
Three primary limitations are exposed:
- Negative prompt instability: Rather than enhancing performance, negative prompts cause over-suppression and prediction collapse, especially in few-shot regimes.
- Lack of encoder-level multimodal alignment: Although both textual and visual prompts are supported, they are not aligned at the encoder level; semantic integration occurs only in the decoder.
- Limited applicability of temporal memory: Treating FSS as video-like memory propagation fails since the model is optimized for temporal, not semantic, consistency.
Future Directions
Enhancing negative prompt handling is a priority. Potential strategies include prompt re-weighting, decoupling positive/negative attention, and model adaptation to avoid unintended global suppression. Strengthening encoder-level multimodal alignment through contrastive or cross-modal objectives could unlock richer semantic reasoning across support modalities. Furthermore, explicit architectural mechanisms to promote cross-image semantic, rather than merely temporal, correspondence in memory-augmented models represent a compelling research direction, with broad implications for open-world and long-tailed segmentation tasks.
Conclusion
This work demonstrates that simple training-free spatial formulations, when combined with foundation models like SAM3, can deliver strong few-shot segmentation with minimal engineering overhead. The results reveal surprising strengths in support-query correspondence via spatial reasoning, but also highlight nontrivial failures in handling negative prompts and prompt modality alignment. The findings motivate both practical adoption and foundational advances in the theory and practice of promptable vision models for FSS.
Reference: "Few-Shot Semantic Segmentation Meets SAM3" (2604.05433)

