- The paper introduces the IRMA framework that reformulates inputs with structured memory, domain constraints, and tool suggestions to significantly improve tool usage accuracy.
- It employs the FACT prompting strategy to actively gather follow-up questions, minimizing errors like hallucinations and policy violations in LLM agents.
- Experimental results show up to 22.4% accuracy improvements and an 8.3-turn reduction in task completion, underscoring improved efficiency and robustness.
Introduction
This paper investigates the limitations of LLM-based tool-using agents in complex, multi-turn environments, specifically within the τ-bench benchmark, which simulates realistic airline and retail customer-service scenarios. The authors identify persistent failure modes in agentic reasoning and planning, including user instruction hallucination, agent hallucination, domain policy violations, and contextual misinterpretation. To address these, the paper introduces the Input-Reformulation Multi-Agent (IRMA) framework, which augments agent input with structured memory, domain constraints, and tool suggestions, and leverages a novel prompting strategy—Follow-up Question ACTing (FACT)—to improve tool usage accuracy, reliability, and efficiency.
The manual analysis of τ-bench conversation trajectories reveals four primary error classes:
- User Instruction Hallucination: The user simulator deviates from the original task, often due to context drift and long-horizon interactions.
- Agent Hallucination: The assistant agent generates incomplete or incorrect responses, typically due to memory limitations and context degradation.
- Domain Policy Violation: The agent fails to adhere to explicit domain constraints, often by executing actions that are invalid under the current state.
- Contextual Misinterpretation: The agent misinterprets user intent, leading to inappropriate tool selection or parameterization.
These errors are causally linked to the inability of LLMs to retain and reason over long contexts, maintain instruction fidelity, and consistently apply domain-specific rules.
The FACT Prompting Strategy
To mitigate premature or erroneous tool calls, the FACT agent is designed to prioritize information gathering through targeted follow-up questions before invoking any tool. This approach reduces the frequency of tool-call errors and improves the agent's ability to handle ambiguous or hallucinated user inputs.

Figure 2: Part 1 of the FACT system prompt, illustrating the initial structure for follow-up question generation.

Figure 4: Part 2 of the FACT system prompt, detailing the continuation and completion of the information-gathering process.
FACT demonstrates improved efficiency and robustness compared to ReAct and Function Calling, but its effectiveness is limited by system prompt length and the agent's ability to retain domain rules over extended interactions.
The IRMA Framework: Architecture and Implementation
IRMA automates the input reformulation process, consolidating three modules:
- Memorization: Maintains a persistent record of user queries throughout the interaction, ensuring instruction retention.
- Constraints: Extracts and presents a checklist of relevant domain rules based on the current user query, reducing policy violations.
- Tool Suggestion: Provides a curated list of relevant tools with brief explanations, aiding in disambiguation and correct tool selection.
This structured input is injected into the agent's prompt, enabling more context-aware and policy-compliant decision-making. Unlike verification-based or self-reflective approaches, IRMA operates in a loop-free manner, focusing on preemptive input enhancement rather than post-hoc correction.

Figure 6: Part 1 of the Retail Domain Rules, exemplifying the explicit constraints provided to the agent.
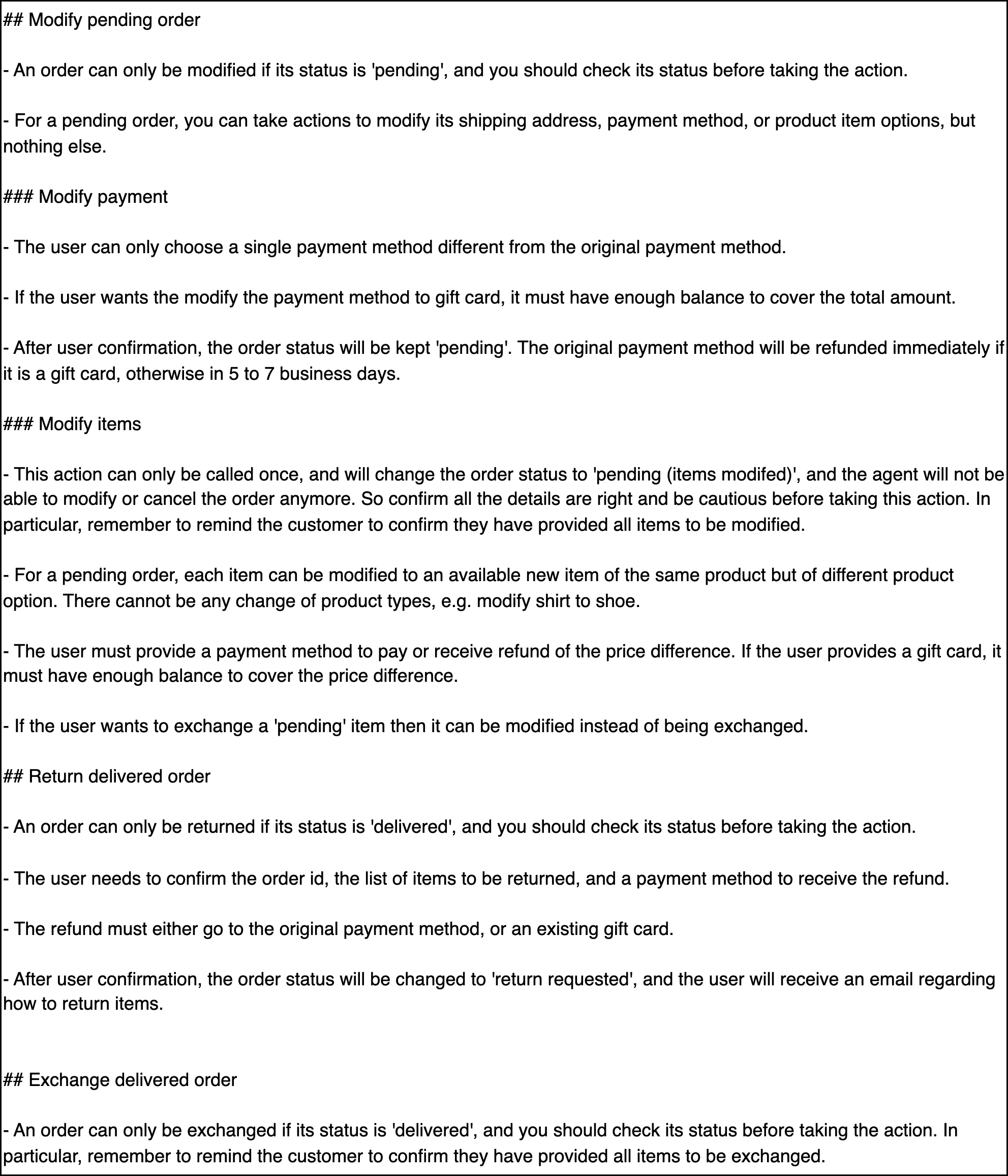
Figure 8: Domain Policies of the Retail Domain, further detailing the operational constraints for tool usage.

Figure 10: Part 1 of the Airline Domain Rules, showing the structured rules for airline-related tasks.

Figure 12: Part 2 of the Airline Domain Rules, completing the set of constraints for the airline domain.
Experimental Results and Comparative Analysis
IRMA is evaluated against ReAct, Function Calling, and Self-Reflection across multiple open-source and closed-source LLMs on τ-bench. Key findings include:
- Accuracy: IRMA outperforms ReAct, Function Calling, and Self-Reflection by 6.1%, 3.9%, and 0.4% respectively in overall pass@1 score. In the airline domain, IRMA achieves 20% and 22.4% higher accuracy than Gemini 1.5 Pro-FC and Claude 3.5 Haiku-FC.
- Reliability and Consistency: On pass5, IRMA exceeds ReAct and Function Calling by 16.1% and 12.6%, respectively, indicating superior reliability across multiple trials.
- Robustness: After removing tasks with ground-truth and user instruction errors, IRMA's performance gap over baselines widens, demonstrating resilience to noisy supervision and ambiguous instructions.
- Efficiency: IRMA completes tasks in fewer turns than competing methods, with reductions of up to 8.3 turns in airline tasks compared to Self-Reflection.
These results are consistent across both retail and airline domains, and ablation studies confirm the complementarity of IRMA's modules, with the full configuration (memory + constraints + tool suggestion) yielding the best performance.
Implementation Considerations
IRMA's architecture is modular and can be instantiated with any function-calling LLM backbone. The memorization module is model-agnostic, while constraint extraction and tool suggestion require domain-specific rule sets and tool catalogs. The FACT prompting strategy is critical for maximizing the benefits of input reformulation, as demonstrated by controlled ablation experiments. IRMA's loop-free design offers latency and cost advantages over verification-based approaches, making it suitable for real-world deployment in customer-service and enterprise automation scenarios.
Implications and Future Directions
The results suggest that context engineering—specifically, structured input reformulation—can substantially improve the reliability and efficiency of tool-using LLM agents in dynamic environments. The approach is robust to hallucination and instruction drift, and generalizes across domains and model sizes. However, the observed ceiling in pass5 scores (~43%) indicates persistent challenges in long-horizon reasoning and policy adherence. Further research is needed to extend IRMA to more diverse environments, refine domain rule extraction, and address limitations in reward modeling and user simulation fidelity.
Conclusion
This study provides a comprehensive analysis of failure modes in tool-using LLM agents and demonstrates that input reformulation via the IRMA framework yields significant improvements in accuracy, reliability, and efficiency on τ-bench. The integration of memory, constraints, and tool suggestions, combined with targeted follow-up questioning, enables more robust agentic behavior in complex, multi-turn settings. The findings underscore the importance of context engineering for agentic LLMs and lay the groundwork for future advances in reliable, policy-compliant tool usage in real-world dynamic environments.

