- The paper presents a circuit-aware unlearning strategy that disentangles forget-specific, retain-specific, and shared modules to reduce conflicting gradients by up to 76%.
- It employs a two-stage process—circuit discovery using activation interventions and selective module updating via gradient projection—to target unlearning effectively.
- The approach achieves an 18% boost in unlearning efficiency and 3.5× faster performance, ensuring robust compliance and maintained recommendation quality.
CURE: Circuit-Aware Unlearning for LLM-based Recommendation
The incorporation of LLMs into Recommender Systems (LLMRec) allows for nuanced semantic user modeling and sophisticated recommendation through prompt-based paradigms. However, the integration of user data into these large-scale architectures introduces nontrivial privacy risks and regulatory concerns, necessitating robust unlearning capabilities that can reliably remove traces of sensitive or user-specified data while retaining overall system performance. Existing unlearning approaches for LLMRec, primarily based on globally mixing forgetting and retaining losses via static weighting, are shown to be limited by entangled gradient flows, often resulting in either insufficient data removal or unacceptable utility loss.
Circuit-Aware Perspective and CURE's Architecture
CURE (Circuit-aware Unlearning for Recommendation) directly attributes these limitations to the entanglement of computational circuits within LLMs. It posits that defining unlearning as a global parameter update ignores the functional specialization within model subgraphs ("circuits") responsible for task-specific behaviors. CURE leverages mechanistic interpretability to identify three classes of parameters: forget-specific, retain-specific, and function-shared modules. This functional disentanglement allows gradient-targeted updates, substantially mitigating optimization conflicts.
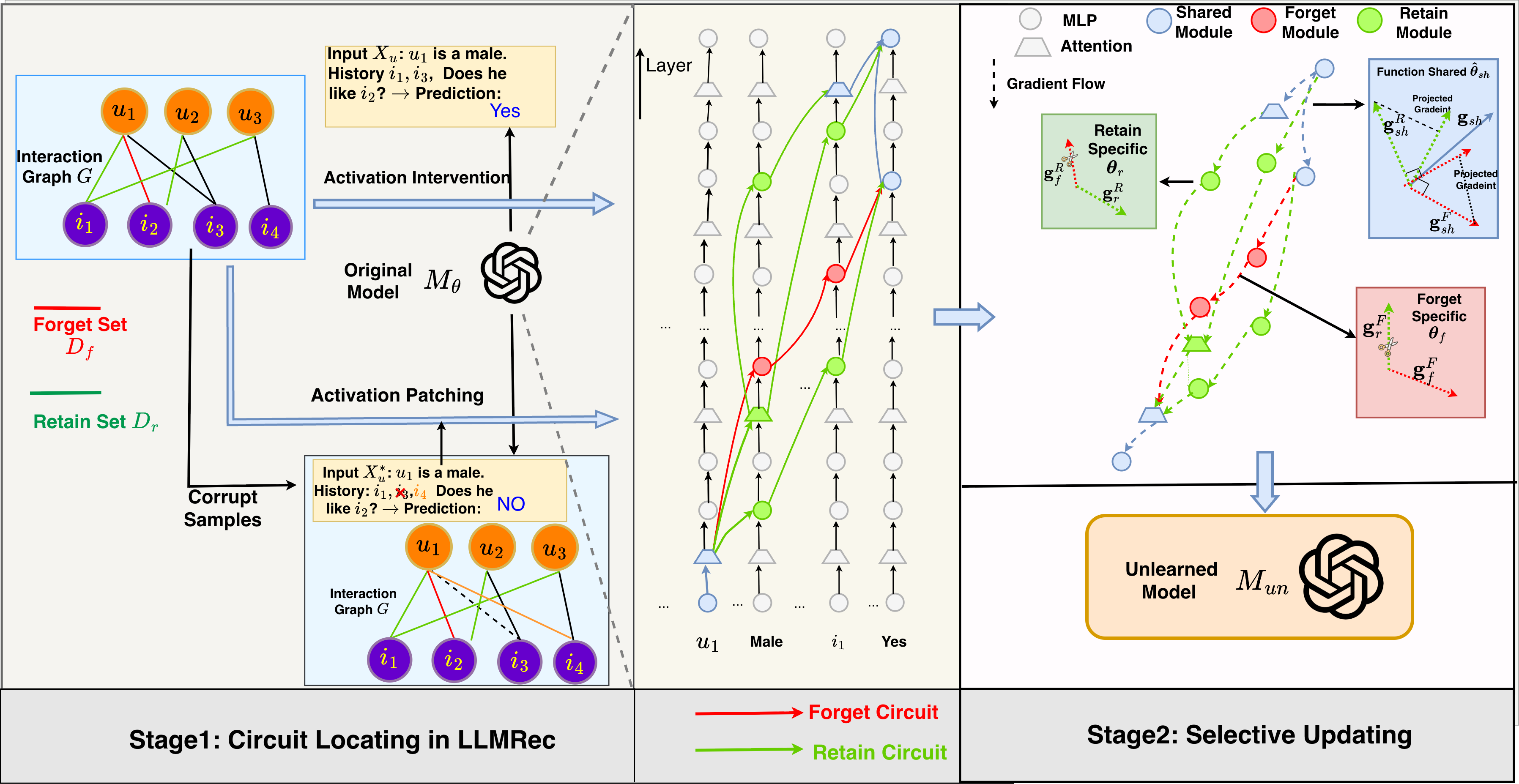
Figure 1: Schematics of CURE, highlighting computational circuit discovery in LLMRec and selective module updating for targeted unlearning.
CURE operates in two stages:
- Circuit Discovery: Using efficient variants of activation intervention and contrastive activation patching, CURE localizes high-influence circuits for both "forget" and "retain" objectives. It exploits the user-item bipartite graph for input selection and employs Personalized PageRank scoring stabilized by gradient-based item importance.
- Selective Module Updating: Detected modules are grouped by functional role. Forget- and retain-specific parameters are updated with respect to their corresponding objectives. Shared modules utilize gradient projection to resolve conflicts, ensuring descent direction does not amplify either objective's loss.
Mitigation of Gradient Conflicts
CURE introduces a rigorous analysis of gradient alignment between the two objectives. Instead of a naive global update, its selective scheme enables granular control, empirically showing more stable and directed convergence.
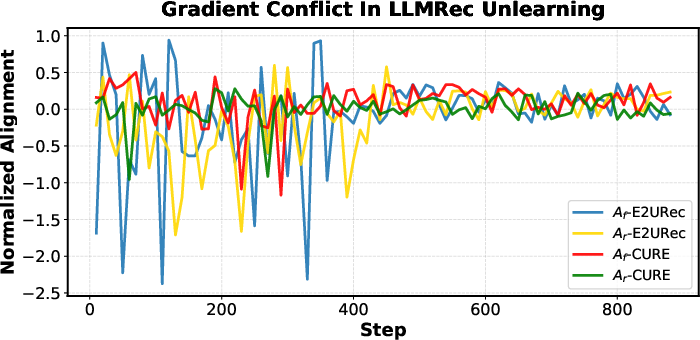
Figure 2: Normalized alignment trajectories demonstrate CURE's ability to suppress frequent oscillations in descent direction induced by naive loss blending.
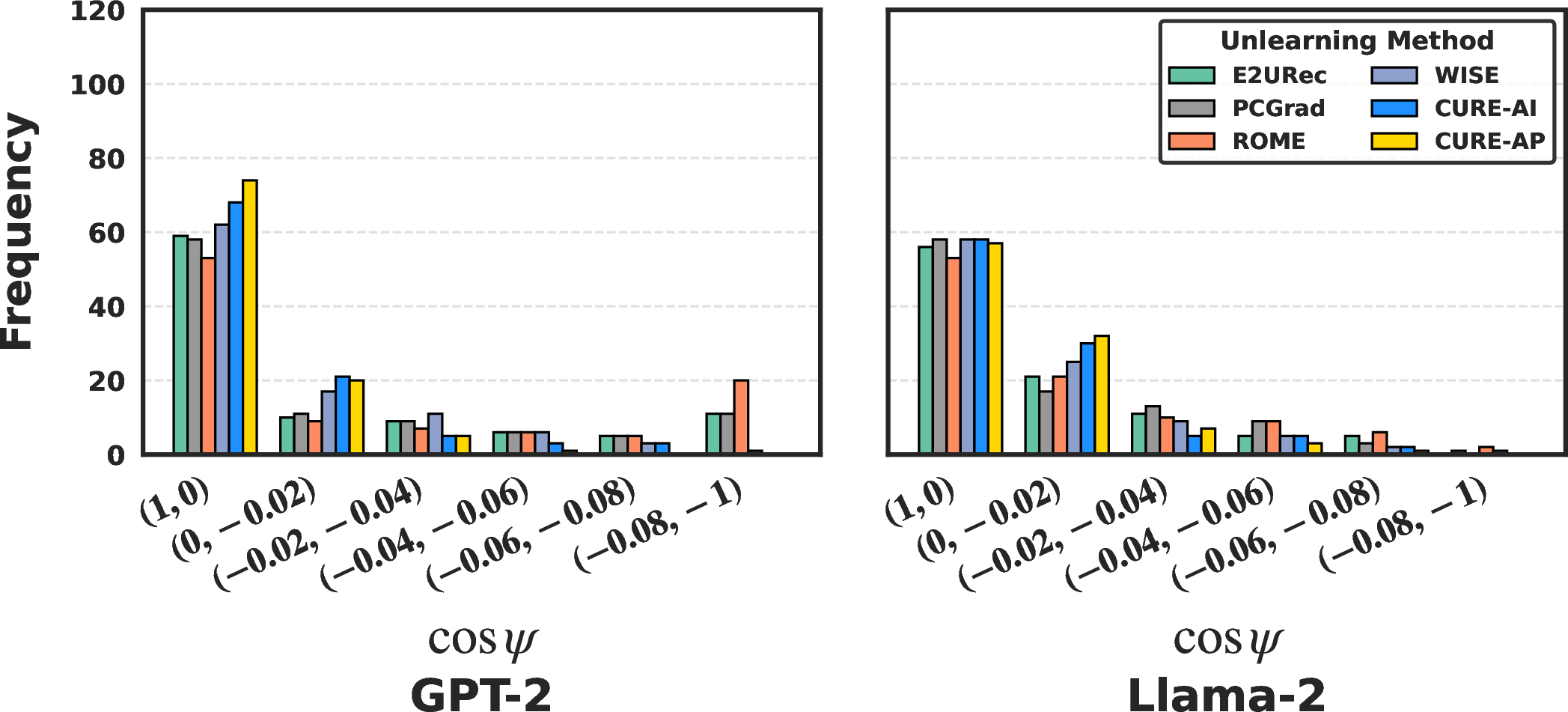
Figure 3: The distribution of conflicting gradients (measured by cosψ) is substantially compressed under CURE, compared to baselines, across two LLM architectures.
Strong quantitative evidence is presented: the proportion of severely conflicting gradients (cosψ<−0.02) is reduced by 55–76% compared to representative LLMRec unlearning methods. PCGrad and generic layer-restriction baselines achieve only marginal improvement.
Empirical Evaluation
Experiments on MovieLens-1M and GoodReads, using both GPT-2 Large and Llama-2-7B as backbones, validate the framework in a comprehensive evaluation pipeline. Metrics include AUC, ACC (utility), Jensen-Shannon Divergence (unlearning quality), and total unlearning time (efficiency).
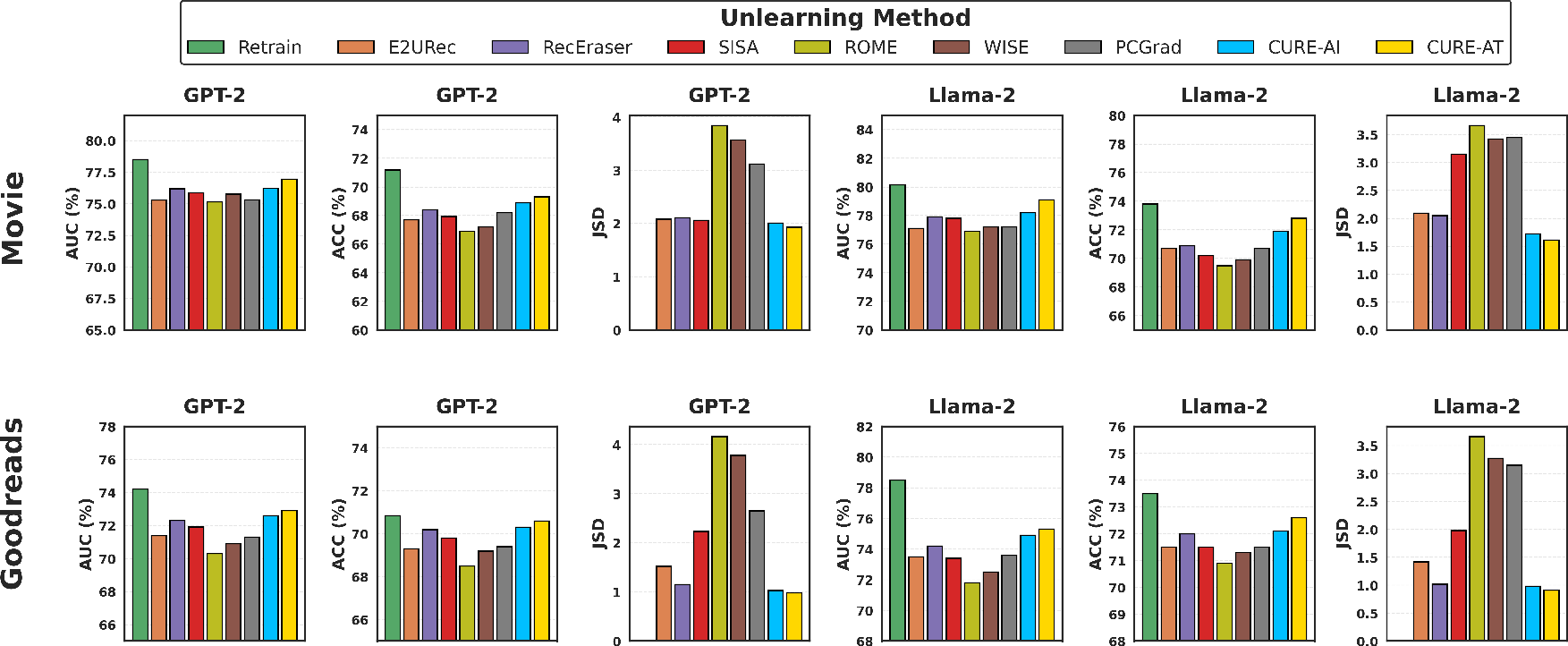
Figure 4: CURE achieves the best trade-off between unlearning completeness (lowest JSD) and recommendation utility (high AUC, ACC) across multiple settings.
CURE outperforms strong baselines (RecEraser, SISA, E2URec, ROME, WISE, PCGrad) in both unlearning and utility metrics. Notably:
- Unlearning efficiency: CURE provides an 18% improvement in effective unlearning and a 6% increase in model utility over the closest baseline.
- Computational performance: CURE attains 3.5× faster unlearning than baseline approaches relying on retraining and model partitioning.
- Divergence to retraining: CURE-AT and CURE-AI maintain the lowest divergence scores (JSD), robustly narrowing proximity to retrained models without incurring their cost.
Circuit-level Interpretability and Targeted Editing
A qualitative study demonstrates that, unlike ROME (which updates isolated early layers) and WISE (which restricts attention to late layers), CURE identifies full computational paths from input tokens through semantically relevant modules to output logits.
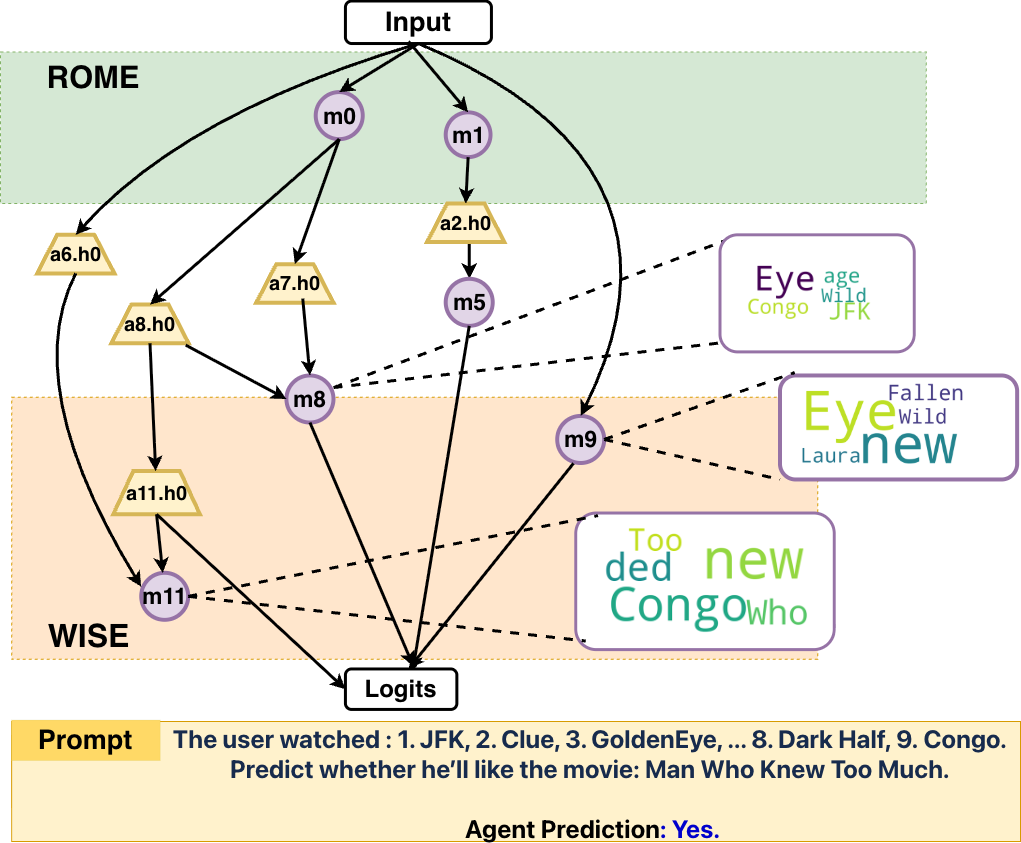
Figure 5: CURE locates and updates interconnected module sequences along the functional path, ensuring both efficacy and interpretability in unlearning.
This granular control prevents the drift of utility associated with blanket parameter modifications, and delivers a transparent account of which modules encode and subsequently forget input-specific information.
Theoretical Guarantees
The authors provide a theoretical result ensuring that for appropriately normalized gradients, the CURE update produces lower joint loss with respect to the composite objective than standard gradient descent. The analysis establishes conditions on gradient angles and magnitude ratios for guaranteed improvement, formally underpinning the empirical success.
Implications and Prospects
CURE marks a shift from black-box, homogeneous parameter updates towards modular, interpretable interventions in LLM-based recommendation engines. This approach aligns unlearning methodology with the latest mechanistic interpretability advances and sets a blueprint for scalable, trustworthy compliance in privacy-sensitive applications. CURE's architecture-agnostic nature makes it adaptable to any transformer-based LLM system.
Theoretically, this work suggests that future LLM editing and unlearning protocols should leverage fine-grained circuit localization, exploiting subgraph-aware parameterization for both efficiency and correctness. Practically, the system offers a path toward regulatory compliance in dynamic data regimes, with verifiable guarantees on data removal and minimal collateral damage to unrelated user experiences.
Conclusion
CURE introduces and validates a circuit-aware unlearning strategy for LLMRec, providing significant gains in both the effectiveness and transparency of the unlearning process. By leveraging computational subgraph analysis for targeted parameter updates, CURE decisively outperforms state-of-the-art baselines in both utility retention and computational efficiency. These findings have implications for the development of robust, interpretable, and regulation-compliant recommendation systems in industries sensitive to privacy and data rights (2604.04982).