- The paper introduces TRU, a targeted reverse update protocol that unlearns user data by coordinating interventions at graph, modality, and parameter levels.
- It employs ranking fusion gating, modality branch scaling, and capacity-aware layer isolation to address privacy risks in heterogeneous multimodal architectures.
- TRU achieves near-retraining performance in both data utility and privacy metrics with faster convergence compared to existing unlearning methods.
Targeted Reverse Update for Multimodal Recommendation Unlearning: An Expert Analysis
Introduction
The proliferation of multimodal recommender systems (MRS) that utilize collaborative user-item interactions alongside item-centric modalities (such as images and text) has created increasingly acute privacy challenges. The deep entanglement of user behaviors and rich content signals renders traditional data deletion—necessitated by regulations like GDPR, CCPA, and PIPL—extremely nontrivial. Approximate machine unlearning has emerged as an alternative to costly full retraining, but most methods assume the influences of deleted data propagate uniformly across the model—a premise that fails in heterogeneous modern MRS architectures, leading to persistent privacy risk and degraded utility.
"TRU: Targeted Reverse Update for Efficient Multimodal Recommendation Unlearning" (2604.02183) introduces a targeted intervention protocol, TRU, which counters the non-uniform influence of deletions by coordinating the unlearning process at the levels of collaborative graph ranking, modality decoupling, and parameter sensitivity. This essay provides a comprehensive technical summary of TRU, situating its contributions within the context of MRS unlearning, analyzing its algorithmic mechanisms, empirical findings, and implications for future AI systems.
Multimodal recommendation architectures—typified by approaches such as MGCN and MIG-GT—fuse interaction graphs with image, text, and ID branches using specialized convolutions and global attention, creating deeply decoupled but highly expressive representations. These systems offer excellent accuracy but exacerbate the difficulty of guaranteeing thorough and efficient data erasure when privacy requests arise.
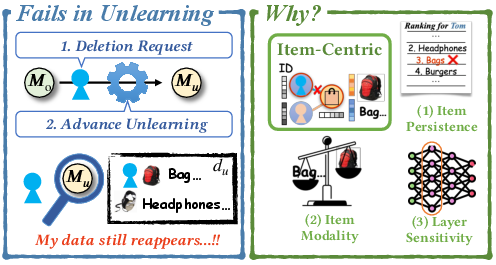
Figure 1: A conceptual overview highlighting unlearning attempts in MRS—deletion requests trigger unlearning, yet verification procedures can fail due to persistent item-centric influences.
Existing approximate unlearning frameworks, notably MMRecUn, pursue computational efficiency by reversing gradients attributed to deleted data and performing subsequent repairs on retained data. However, this global uniformity assumption is empirically invalid in MRS. Deleted data influence is concentrated:
- On target items in collaborative graphs, which retain exposure through remaining user edges.
- In specific item modalities, where imbalances emerge due to non-uniform learning and fusion.
- Across sensitive network layers, particularly at early embedding modules, where excessive shift or insufficient localization impairs representational stability.
Diagnosis of Unlearning Failure Modes
Target-Item Persistence in Collaborative Graphs
Empirical results indicate that even exact retraining on the retained set cannot fully eliminate target-item exposure from top recommendations, especially when forgotten interactions make up a small proportion of item popularity.
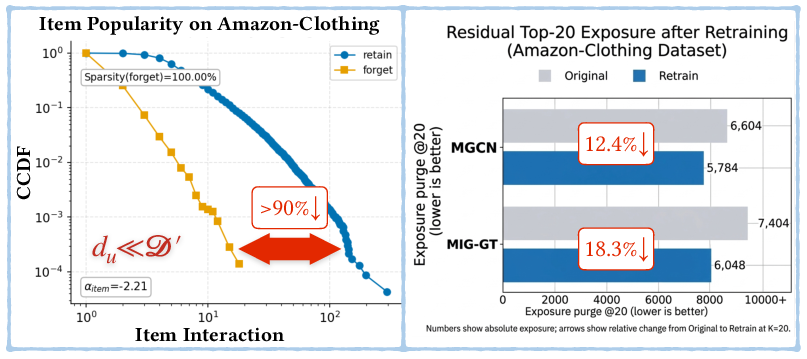
Figure 2: Item persistence in Amazon-Clothing—target (forget) set items are much less popular than the retain set, and retraining cannot fully suppress their Top-20 recommendation exposure.
TRU's first insight is that node-level deletion does not propagate strongly enough in collaborative graphs, necessitating direct suppression of fusion output to neutralize popularity inertia.
Modality Imbalance in Feature Branches
Modern backbones separate feature propagation by modality. Applying the same reverse penalty across all branches creates pronounced imbalance, over-correcting fragile modalities (e.g., image, text) and under-correcting dominant ones.
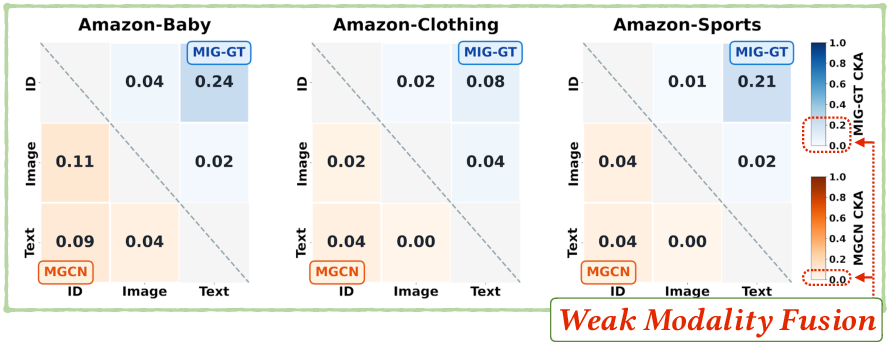
Figure 3: Imbalance in MGCN and MIG-GT—branch representations show weak cross-modal alignment, reinforcing that uniform updates distort multimodal learning.
TRU introduces per-modality scaling of the reverse gradient, using dynamic statistics to modulate erasure force according to each branch's structural sensitivity.
Layer-wise Sensitivity in Parameter Space
Parameter updates from deletion events disproportionately disrupt embedding and early fusion layers, driving their parameters far from the retraining profile and causing utility loss.
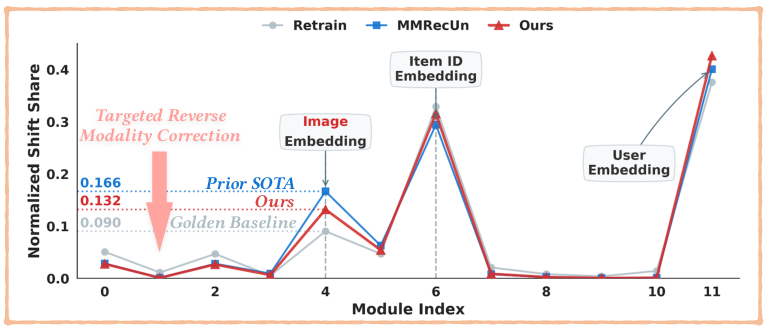
Figure 4: Layer sensitivity—MMRecUn over-shifts early embedding modules, whereas TRU stably localizes corrections, replicating retraining shift profiles more accurately.
TRU restricts reverse updates to capacity-aware, highly sensitive layers via adaptive masking, sifting out less impacted modules from aggressive interventions.
The TRU Framework: Targeted Reverse Update
TRU unifies the three targeting mechanisms—ranking fusion gating, modality branch scaling, and capacity-aware layer isolation—into an adaptive protocol operating as a plug-in atop existing MRS models.
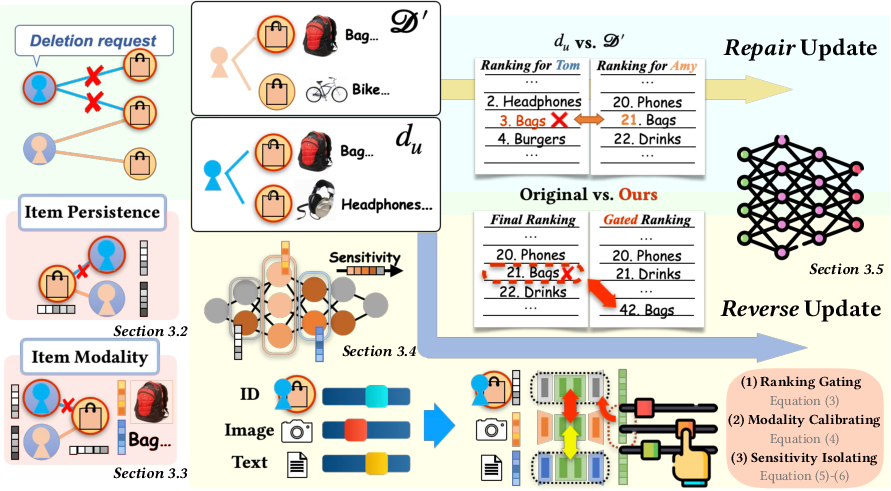
Figure 5: Overview of TRU’s three-level intervention: ranking gate, branch-wise gradient scaling, and adaptive layer mask, precisely localizing reverse unlearning.
Key steps:
- Ranking Fusion Gate: Augments the reverse loss with sparsity-promoting penalties centered on fusion parameters, directly decoupling target item exposure from collaborative context.
- Modality Branch Scaling: Computes branch-specific scale factors from gradient energies on retain and forget objectives, dampening reverse updates in over-corrected modalities and allowing aggressive forgetting where required.
- Capacity-Aware Layer Isolation: Quantifies per-module sensitivity and constructs a binary mask to restrict reverse updates only to the most deletion-reactive modules, expanding capacity until minimum coverage is satisfied.
Expressed concisely, the per-module update is:
θk←θk+ηαzkγm(k)∇θkL~rank
where zk is the module mask and γm(k) the branch scaling, with L~rank penalizing output fusion.
Empirical Evaluation and Analysis
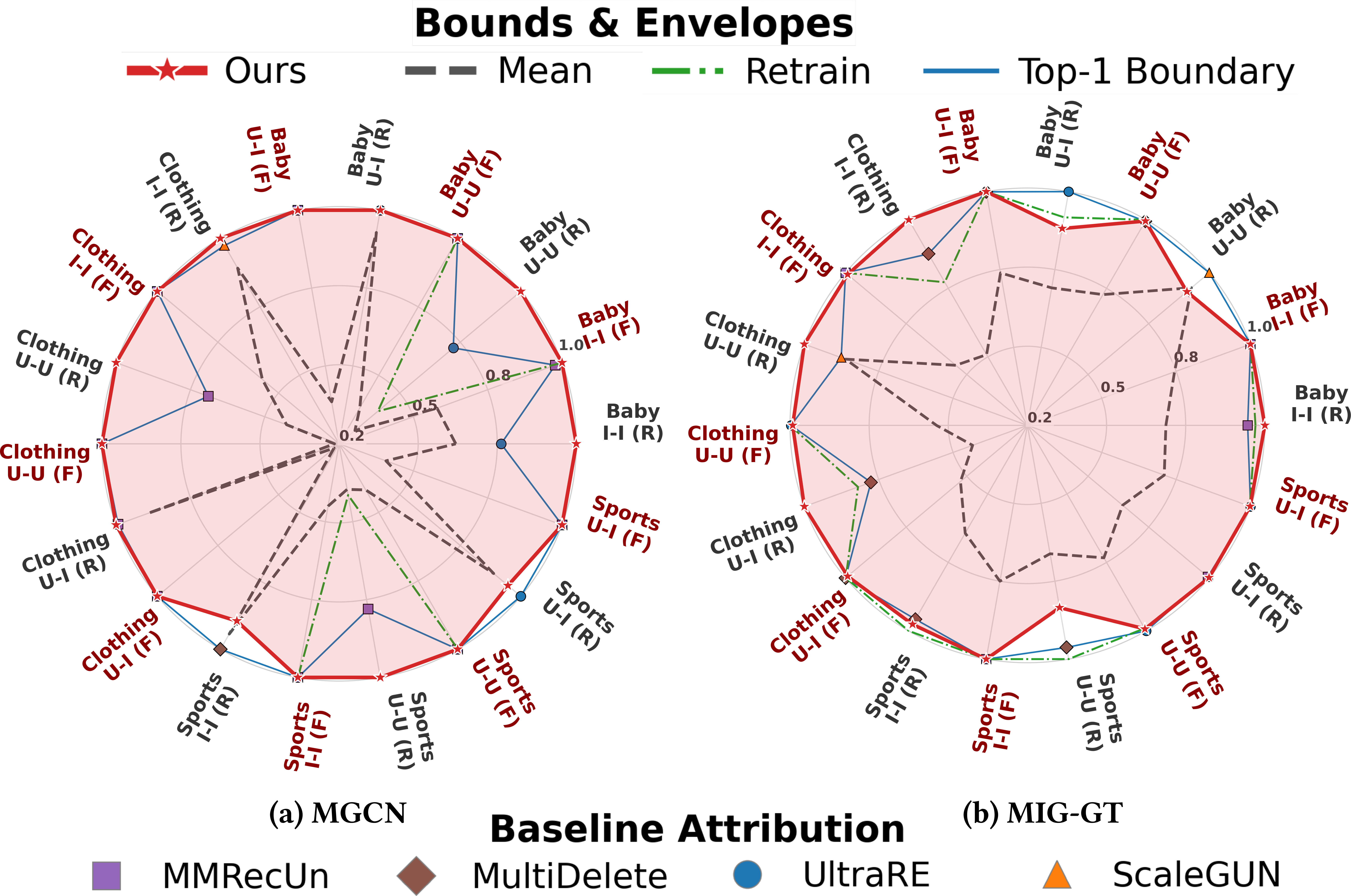
Extensive experiments benchmarked TRU against baseline unlearning methods (MMRecUn, UltraRE, MultiDelete, ScaleGUN, and full retraining) across MGCN/MIG-GT (two representative multimodal graph backbones) on Amazon Baby, Sports, and Clothing datasets, evaluating user-level, item-level, and interaction-level forget regimes.
Evaluation strictly considers:
Key Findings:
Ablation confirms that removing any TRU subcomponent leads to rapid collapse of either utility, completeness, or privacy, highlighting the necessity of all targeting modules.
Implications and Future Directions
TRU’s results have direct implications for privacy-compliant deployment of MRS in realistic settings:
- Targeted unlearning closes the gap between computationally cheap approximate protocols and ideal retraining, without sacrificing accuracy or scalability.
- Component analysis reveals that interventions must respect the architectural inhomogeneity of MRS—uniform recipes are systematically defective for graph-modality fusion systems.
- Security auditing underlines the importance of multi-perspective metrics; attacking only surface metrics leads to erroneous conclusions about privacy.
For future research, several directions emerge:
- Extending targeted reverse update concepts to ever-evolving data streams (continual unlearning, online deployment).
- Support for richer, higher-dimensional modalities and agents in next-generation foundation and agentic models.
- Establishing formal privacy/utility/robustness guarantees and real-time unlearning audit tools for regulatory compliance.
Conclusion
The study conclusively demonstrates that approximate unlearning for multimodal recommendation must break with global uniformity assumptions and instead pursue targeted, architecture-aware intervention. TRU operationalizes this insight, combining ranking, modality, and layer targeting to yield a robust, scalable, and privacy-sound solution for data deletion requests in advanced recommender systems. Its approach sets a clear methodological baseline for future responsible unlearning protocols in complex AI systems.