- The paper introduces a stage-wise evaluation framework that decomposes modeling tasks into seven stages, enabling detailed comparison between LLMs and experts.
- The study finds that LLMs approach expert performance in early stages like problem identification but falter significantly in model solving, code implementation, and result analysis.
- The methodology demonstrates high reliability with an intraclass correlation coefficient above 0.67, highlighting robust discriminative power compared to conventional rubrics.
Systematic Evaluation of LLMs Versus Human Experts in Mathematical Modeling
Introduction and Motivation
Recent advancements in LLMs have demonstrated strong performance on isolated reasoning, programming, and formal problem-solving benchmarks. However, whether LLMs can perform expert-level, end-to-end scientific modeling—integrating comprehension, formulation, derivation, implementation, and validation—remains unresolved. This paper, "How Far Are We? Systematic Evaluation of LLMs vs. Human Experts in Mathematical Contest in Modeling" (2604.04791), establishes a comprehensive, problem-aware, stage-wise evaluation framework and applies it to a large set of expert-level mathematical modeling tasks from the China PMCM, performing a rigorous comparison of LLM and expert performance across the modeling pipeline.
Problem-Oriented, Stage-Wise Evaluation Framework
The proposed framework decomposes each modeling problem into modular subtasks, with each subtask mapped to seven canonical modeling stages: Problem Identification, Problem Formulation, Assumption Development, Model Construction, Model Solving, Code Implementation, and Result Analysis. For each subtask–stage pair, domain experts and LLMs co-design granular, problem-specific scoring criteria, enforcing semantic fidelity and technical depth while suppressing superficial, report-level inflation. This framework allows for interpretable score profiles across subtasks and stages, ensuring comparability of solutions independent of narrative style or surface presentation.
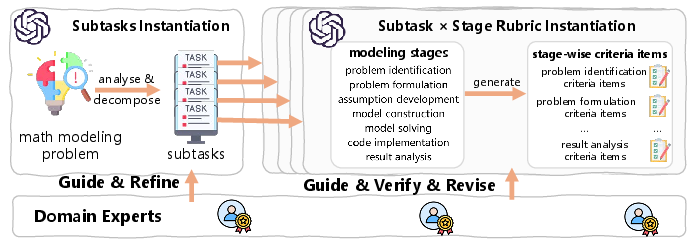
Figure 1: Schematic of the multi-phase, subtask–stage rubric generation and scoring process aligning domain expertise with LLM capabilities for nuanced, problem-aware evaluation.
Reliability and Discriminative Power
The framework’s reliability is substantiated by an extensive inter-rater analysis using the intraclass correlation coefficient (ICC(2,1)): ICC against independent expert judgment exceeds 0.67—far higher than previous problem-agnostic rubrics, which exhibit negligible alignment. This elevated correlation holds robustly across all stages, including technically demanding ones such as model construction, solving, and code realization.
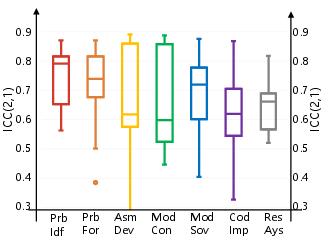
Figure 2: Stage-wise alignment between automatic scoring and expert evaluation, demonstrating high consistency in all major modeling phases.
Furthermore, score distributions generated with the framework are more dispersed and diagnostic of solution quality; unlike traditional coarse rubrics, which cluster model reports within a narrow range (6.5–8.5), the proposed rubric surfaces clear penalties when models fail execution-centric criteria.
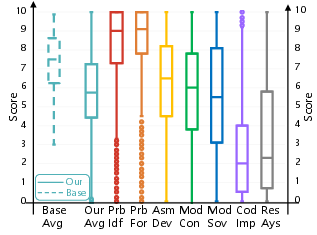
Figure 3: Comparisons of scoring concentration and dispersion under the baseline and stage-wise evaluation, illustrating heightened discriminative power.
Stage-Wise Evaluation: The Comprehension–Execution Divide
Analyzing LLM performance over 97 PMCM tasks, a pronounced monotonic decline emerges from initial to final modeling stages across all tested LLMs (including Qwen and DeepSeek variants). Scores are consistently high in Problem Identification and Formulation (approaching expert performance), drop to intermediate values in Assumption and Model Construction, and fall markedly below 5.0 in Model Solving, Code Implementation, and Result Analysis. These execution-oriented stages remain a bottleneck unaddressed by increased scaling.
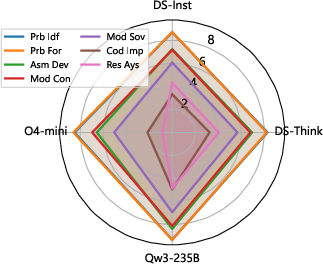
Figure 4: Radar plot of averaged stage-wise performance for leading LLMs, illustrating the systematic decay from comprehension to execution and validation.
Scaling up model parameters within the Qwen series (7B to 235B) yields gains almost exclusively in comprehension-centric stages, while the gap in solving, implementation, and validation persists without substantial improvement.
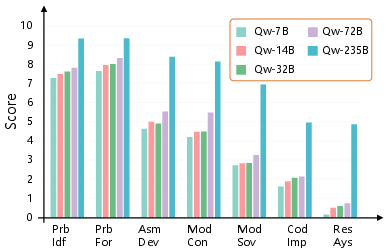
Figure 5: Analysis of within-family scaling for Qwen models, highlighting saturation in execution stages.
Failure Taxonomy: Analysis of Execution Deficiencies
Detailed failure analysis attributes LLM underperformance not to flawed conceptual intent, but rather to procedural or operational breakdowns:
- Assumption Development: High rates of unverified or underspecified assumptions, lack of impact analysis, and hidden idealizations.
- Model Construction: Frequent omission of core structure, ambiguous variable definitions, incomplete derivations, or weak alignment with underlying assumptions.
- Model Solving: Missing or uncheckable computational solutions, absent key algorithmic steps, lack of numerical/stability verification.
- Code Implementation: Non-executable or irreproducible code, incomplete or inconsistent implementation with mathematical logic.
- Result Analysis: Missing empirical validation, superficial or unsupported conclusions, no sensitivity or limit analysis.
Errors emerging in early modeling stages (assumptions, construction) are rarely identified or corrected later in the pipeline. Instead, they propagate, ensuring that downstream stages cannot recover, leading to compounded deficits in implementation and result quality.
Dataset and Coverage
The PMCM test set exhibits broad methodological and domain coverage (engineering, environment, finance, etc.), with task structure closely matching real-world scientific workflows rather than stylized benchmarks.
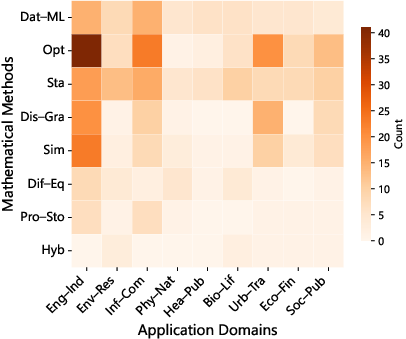
Figure 6: Heatmap of method–domain co-occurrences, underscoring the diversity and interdisciplinarity of the evaluation corpus.
Implications and Future Directions
This analysis decisively demonstrates that LLMs, when confronted with rigorous, real-world-style modeling challenges, are hampered by a persistent comprehension–execution gap. While language-driven comprehension and representation (problem identification, initial formulation) are near parity with human experts—benefiting from increased scale—successful model solving, rigorous coding, and robust validation require procedural, algorithmic, and iterative competencies absent from current architectures.
Several theoretical and practical directions are suggested:
- Process-Aware and Self-Corrective Reasoning: Mechanisms for stateful, revisitable solution artifacts and stage-wise feedback, rather than single-pass generation.
- Verification and Validation Integration: Techniques for explicit solution checking and output grounding, possibly integrating symbolic computation or external verification modules.
- Scalable Evaluation Protocols: Task- and stage-specific, expert-in-the-loop datasets for diverse domains, ensuring that LLM advances are measured against holistic problem-solving rather than isolated capability tests.
- Agentic and Multi-Agent Orchestration: Delegation and coordination over complex pipelines—potentially leveraging heterogeneous agent systems to distribute comprehension, execution, and validation.
Conclusion
The introduced framework offers a highly reliable, fine-grained, and problem-anchored strategy for benchmarking true mathematical modeling competence in LLMs. It reveals strong evidence that, even at the forefront of model scale and capability, LLMs still lack crucial operational and validation skills necessary for scientific-grade, end-to-end problem solving. This deficiency is unlikely to be resolved by scale alone, necessitating focused algorithmic and architectural innovations in process modeling, retrospection, and stage-wise learning.