- The paper introduces FeDPM, a framework that replaces parameter sharing with discrete prototypical memory transfer to address semantic misalignment in federated time series models.
- It employs local codebook learning and cross-domain memory aggregation, significantly reducing parameters (over 97%) and improving forecasting accuracy.
- FeDPM demonstrates robustness in low-resource and privacy-preserving settings, highlighting its adaptability across diverse time series domains.
Discrete Prototypical Memories for Federated Time Series Foundation Models
Problem Motivation and Background
Training time series foundation models (TSFMs) under federated learning (FL) introduces unique representation mismatches that impair knowledge transfer and semantic alignment. Existing approaches frequently adapt LLMs using parameter sharing to federate TSFMs, but empirical evidence demonstrates that text-centric embeddings induce semantic misalignment when applied to heterogeneous time series domains. Figure 1 shows that replacing frozen LLM backbones with lightweight trainable alternatives yields improved MSE and significant parameter reduction, exposing the representational inadequacy of direct LLM adaptation for FL-TSFM deployment.
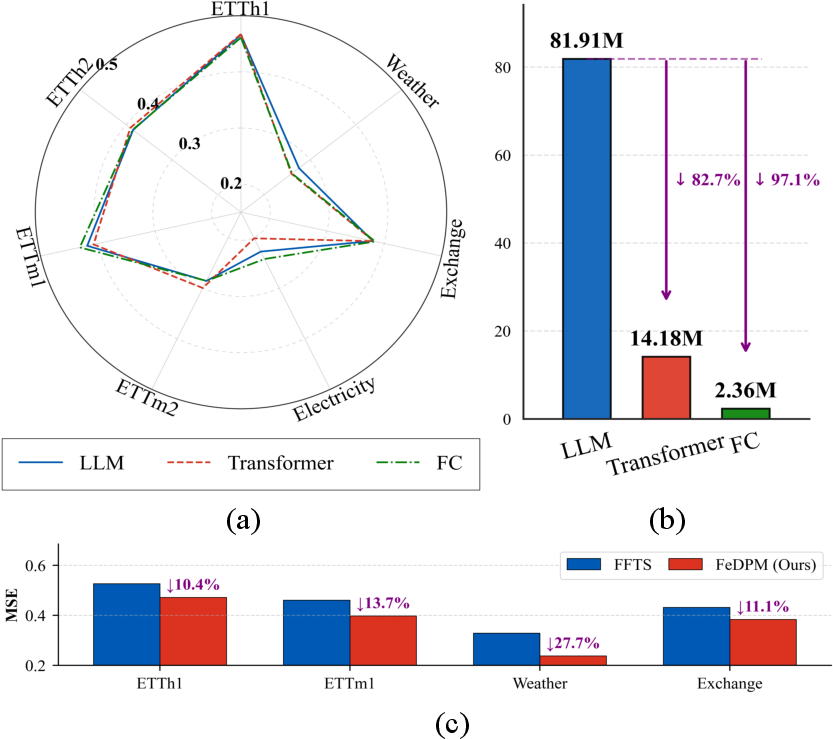
Figure 1: Ablation shows that lightweight models outperform LLMs on forecasting MSE with far fewer parameters, indicating a representational mismatch.
Many current FL methods force time series from diverse domains into a unified continuous latent space, ignoring the discrete, recurring dynamics often found in temporal regimes. This continual, index-based aggregation induces negative transfer and entanglement for nonstationary, domain-specific behaviors. There is a critical gap for communication-efficient, privacy-preserving federated TSFMs capable of robust cross-domain transfer without semantic distortion.
The FeDPM Framework
The proposed FeDPM architecture replaces parameter-centric FL with discrete prototypical memory transfer, achieving explicit semantic separation and drastically improved communication efficiency. Each client independently learns a domain-native prototype codebook (memory) capturing characteristic local patterns. These memories are the sole objects exchanged with the server, decoupling architectural choices and eliminating direct parameter sharing.
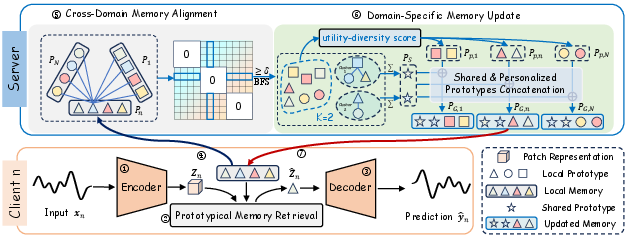
Figure 2: Overall FeDPM architecture with local encoding, prototypical memory retrieval, and cross-domain memory aggregation for federated forecasting.
Local encoding proceeds via channel-independent patch segmentation, linear projection to token embeddings, and passing through a domain-specific encoder. Latent representations are assigned via an argmin retrieval to the nearest codebook prototype, producing quantized patch-level vectors. Decoder modules reconstruct the original horizon from these quantized codes.
Prototypical memory vectors from all clients are uploaded to the server, where cross-domain memory alignment is conducted. Alignment uses the cross-prototype cosine similarity graph to cluster semantically similar prototypes and aggregate centroids using mean pooling. A fixed global ratio controls the inclusion of shared versus domain-personalized prototypes, ensuring efficient transfer of consensus patterns and retention of client-specific nuances.
Utility-diversity scoring within unclustered prototypes selects the most informative, non-redundant personal patterns based on local usage statistics and inter-domain redundancy penalties. The server then returns the concatenated memory for the next training round, with no raw data nor model parameters exchanged.
Experimental Results and Model Analysis
FeDPM is benchmarked on seven canonical time series datasets (ETTh1/2, ETTm1/2, Electricity, Weather, Exchange) against FL baselines (Time-FFM, FFTS, FL-iTransformer, FL-PatchTST), centralized FMs (TOTEM, UniTime, Cen-PatchTST), and dataset-specific centralized expert models (TimesNet, FEDformer, etc.).
Main Results: FeDPM achieves the highest count of best-in-class scores among FL-FMs, with MSE and MAE improvements (4.92%) over the strongest prior federated baseline FFTS. Communication overhead is reduced by over 97.03%: transmitting only 0.016M parameters versus millions in baseline FL frameworks.
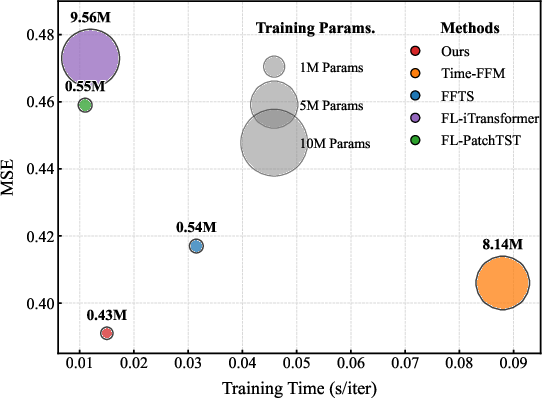
Figure 3: FeDPM requires the lowest MSE, training time, and parameter count among federated and centralized methods, highlighting its efficiency.
Few-shot experiments with 5% and 10% training data confirm FeDPM’s strong transfer ability and robustness, outperforming all FL-FM baselines in low-resource settings. Ablations further show that breaking semantic alignment (naïve averaging) or disabling memory aggregation significantly degrades performance, validating the necessity of the cross-domain prototypical transfer. Encoder ablation reveals consistent superiority of the Transformer-configured FeDPM, but the framework is robust to CNN, FC, or RNN backbones.
Visualization of codebook assignments using t-SNE illustrates clear separation of prototype clusters, demonstrating that the learned discrete latent space avoids entanglement and promotes interpretable semantic aggregation.
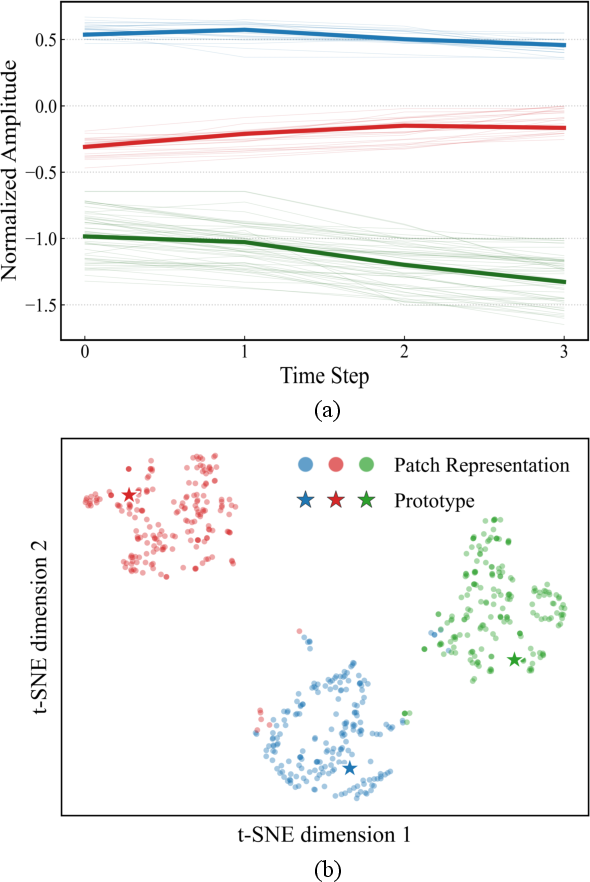
Figure 4: Visualization of Weather dataset patch assignments reveals distinctive cluster structures in both time domain and latent space post-encoding.
FeDPM demonstrates strong resilience to standard privacy-preserving noise mechanisms (Laplace, Gaussian, Exponential) on memory vectors: even with noise, losses remain competitive with the best unperturbed baseline scores, supporting its suitability for deployment in privacy-critical real-world scenarios.
Architectural and Theoretical Implications
FeDPM’s separation of semantic aggregation (via codebook clustering) from parameter transfer directly addresses the bottlenecks of cross-domain negative transfer and domain homogeneity assumptions in traditional FL. By treating local memory codebooks as permutation invariant and leveraging graph clustering for aggregation, FeDPM aligns with the discrete structure of time series regimes more naturally than continuous latent projection.
This enables a practical trade-off between global knowledge sharing and domain personalization—critical for forecasting where non-IID client data and abrupt local patterns dominate. The reduction in communication (prototypes only) and parameter counts (no stacking) yields improved scalability for large-scale FL time series systems.
Limitations and Future Directions
Computational complexity on the server side remains non-trivial due to cross-domain memory alignment (similarity graph and BFS clustering), and current hyperparameter selection is manual. Future work should address adaptive clustering thresholds, sparse prototype transmission, and dynamic control of shared/personalized capacity. Extensions to hierarchical or graph-based prototype organization could further enhance semantic resolution and efficiency.
Conclusion
Discrete prototypical memory transfer via FeDPM provides a highly communication- and parameter-efficient framework for federated time series foundation model training, resolving core issues with representation mismatch and negative transfer. Experimental results highlight robust, state-of-the-art performance across tasks and federated regimes, with validated privacy robustness. These findings lay theoretical and practical groundwork for the future development of cross-domain, privacy-preserving, and semantically disentangled FL time series models.
Reference: "Discrete Prototypical Memories for Federated Time Series Foundation Models" (2604.04475)