- The paper introduces domain-specific prototype construction combined with dual alignment to disentangle class and domain semantics in federated learning.
- It achieves significant accuracy gains over FedAvg with improvements of +5.61% on DomainNet, +15.06% on Office-10, and +7.56% on PACS.
- The method ensures rapid convergence and robust generalization in non-IID, domain-shifted settings for real-world applications.
Domain-Aware Prototype Learning for Federated Learning under Domain Shift
Introduction and Motivation
Federated Learning (FL) is essential for enabling decentralized training across clients without explicit data sharing but is fundamentally challenged by non-IID and, crucially, domain-shifted data. Cross-domain heterogeneity in client data, prevalent across real-world applications such as edge devices with diverse sensing modalities, significantly undermines the representational alignment and generalization of global models. Traditional prototype-based FL approaches create a single global prototype per class, ignoring domain-specific variations and enforcing a uniform feature alignment that neglects domain semantic disparity.
The "FedDAP: Domain-Aware Prototype Learning for Federated Learning under Domain Shift" framework addresses these limitations by introducing domain-specific prototype construction and a dual alignment strategy. This design explicitly models domain-conditioned semantic structure, promoting better intra-domain consistency and cross-domain generalization by leveraging the structural disentanglement of class and domain in representation space (Figure 1).
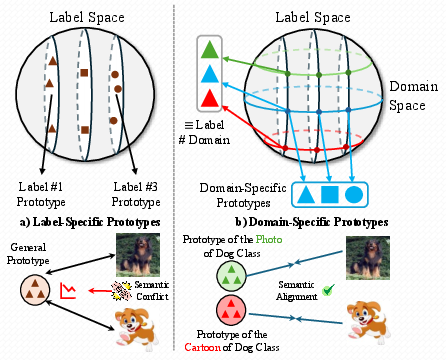
Figure 1: Conceptual depiction illustrating how single label-specific prototypes conflate domain-specific features (left), whereas FedDAP’s domain-specific prototypes disentangle class and domain semantics (right).
Methodology
FedDAP consists of two primary technical innovations for federated learning under domain shift: domain-specific global prototypes, and a dual prototype alignment strategy that combines intra-domain alignment with cross-domain contrastive learning.
Domain-Specific Prototype Construction
Each client computes local class prototypes using its domain-annotated data. These local prototypes are communicated to the server along with the associated domain identifier. For each class-domain pair, the central server aggregates the local prototypes from all clients within the same domain using a cosine similarity-weighted fusion mechanism, rather than naive averaging, in order to emphasize semantically coherent prototypes and suppress outlier effects.
This produces, for every class c and domain d, a prototype vector P(c,d), resulting in a tensor of structure RD×C×I. This explicit modeling of the domain axis prevents semantic dilution and preserves intra-domain semantics.
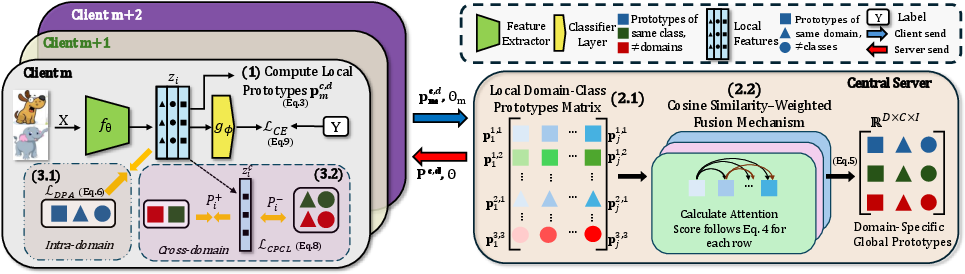
Figure 2: Overview of the FedDAP system, depicting local prototype computation, server-side similarity-weighted aggregation, and client reception of domain-specific global prototypes for local alignment.
Dual Prototype Alignment Strategy
During local training, the dual alignment approach enforces two types of objectives:
- Domain-Consistent Prototype Alignment (LDPA): Each client aligns its local features with intra-domain prototypes (P(c,dm)) using cosine similarity, fostering semantic consistency and reducing within-domain divergence.
- Cross-Domain Prototype Contrastive Learning (LCPCL): Leveraging cross-domain prototypes as positive and negative samples, local representations are drawn toward same-class prototypes from other domains and pushed away from different-class prototypes, improving domain invariance and separation.
The total training loss is a weighted sum of cross-entropy, intra-domain prototype alignment, and cross-domain contrastive learning objectives:
L=LCE+λ1LDPA+λ2LCPCL
Experimental Evaluation
FedDAP was evaluated on three canonical multi-domain benchmarks: DomainNet, Office-10, and PACS, with clients distributed across domains to simulate real-world domain skew. Baseline methods included FedAvg, FedProx, model-centric contrastive FL (MOON), and various state-of-the-art prototype-based and domain generalization FL techniques such as FedProto, FedPLVM, and FedRDN.
The empirical results indicate:
- FedDAP consistently yields the highest average classification accuracy across all datasets and produces the strongest relative improvement over the FedAvg baseline:
- +5.61% improvement on DomainNet,
- +15.06% on Office-10,
- d0 on PACS.
- Qualitative t-SNE visualizations confirm tighter, well-separated feature clusters for FedDAP compared to FedProto, indicating better class and domain disentanglement.
- FedDAP demonstrates markedly faster convergence than all baselines, expediting communication rounds and enhancing efficiency.
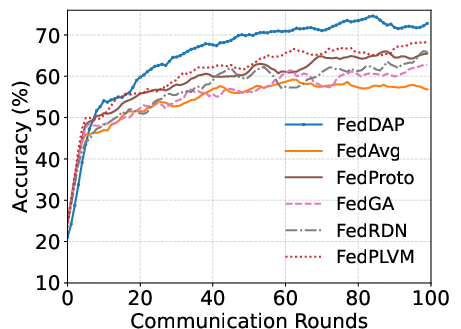
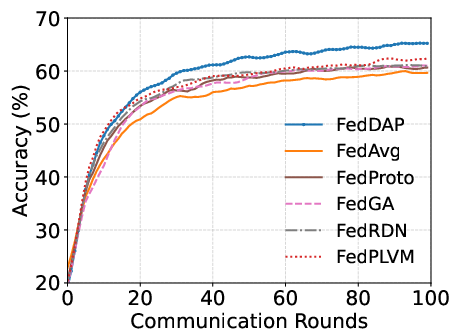
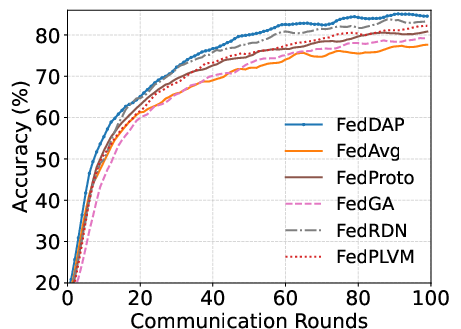
Figure 3: Office-10 test accuracy trajectories illustrate the rapid convergence and higher final performance of FedDAP under domain shift scenarios.
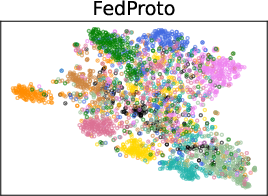
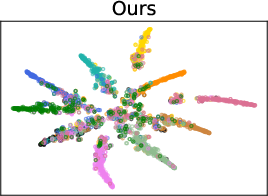
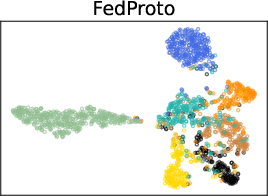
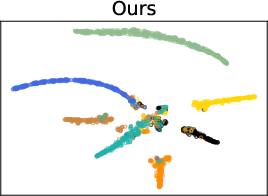
Figure 4: DomainNet evaluation curve further demonstrating consistent improvement in training efficiency and stability.
Additional ablations show that both intra-domain alignment and cross-domain prototype contrastive learning are necessary for peak accuracy, with the combination achieving best results. The cosine similarity-weighted aggregation outperforms plain averaging of domain-specific prototypes by over 1% absolute margin on all datasets.
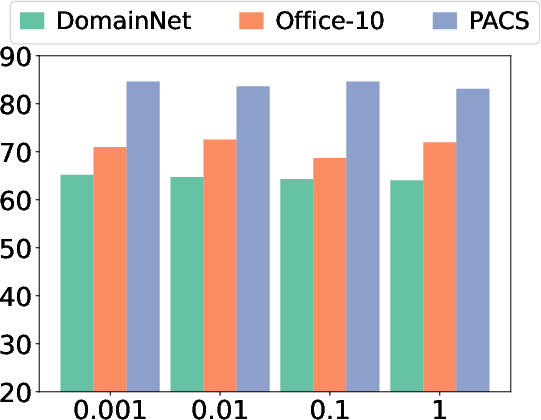
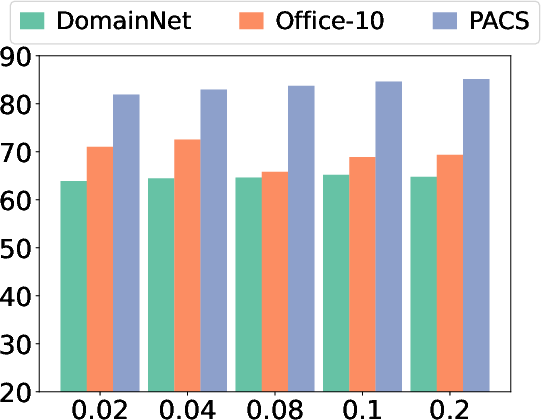
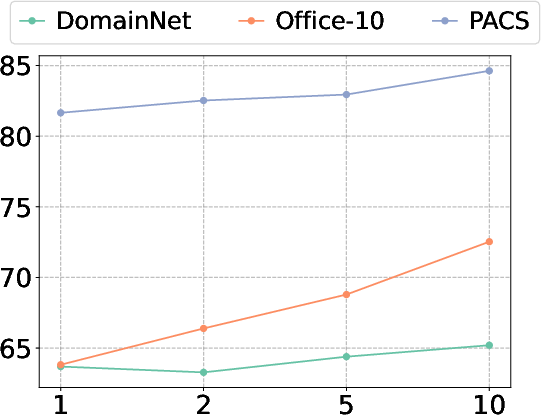
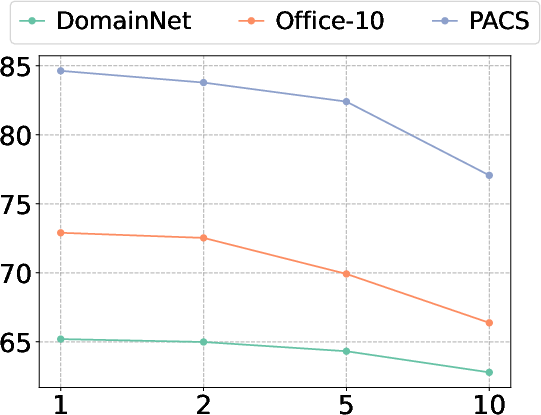
Figure 5: Sensitivity analysis of aggregation temperature d1, which modulates the sharpness of similarity weighting in prototype fusion.
Implications and Future Directions
The key theoretical contribution is the explicit exploitation of domain structure in prototype-based FL. This decouples class and domain semantics, allowing global models to preserve domain-specific representational fidelity while promoting cross-domain robustness. In practical deployment of FL for perception or sensor fusion where domain shift is pervasive, this approach advances both model accuracy and generalization without compromising privacy or inducing prohibitive communication overhead.
Looking forward, several research directions emerge. First, integrating automated domain discovery or clustering could eliminate the need for explicit domain annotations, enhancing scalability. Second, exploring task-conditioned prototypes and extension to other modalities (e.g., speech, medical time series) could further broaden applicability. Finally, incorporating privacy-preserving prototype perturbation, as partially evaluated, can enable trustable FL under regulatory compliance.
Conclusion
FedDAP establishes that incorporating domain-aware, class-conditional prototype learning with dual alignment objectives yields robust, generalizable federated models under domain shift. By formalizing and leveraging domain structure within prototype aggregation and local supervision, FedDAP overcomes the representational collapse and semantic conflict intrinsic to naive prototype-based FL. The strong performance, efficient learning dynamics, and flexibility of the approach position it as a preferred method for FL settings subject to substantial domain heterogeneity (2604.06795).

