- The paper introduces a mean–variance criterion for Bayesian OED that penalizes utility variance to control risks in experimental outcomes.
- It leverages Monte Carlo estimators with common random numbers and sample reuse to efficiently estimate both the expected utility and its variance.
- Numerical validations demonstrate that the risk-aware designs mitigate extreme outcomes while retaining high expected information gain in complex models.
Mean–Variance Risk-Aware Bayesian Optimal Experimental Design for Nonlinear Models
Introduction and Motivation
The conventional paradigm in Bayesian optimal experimental design (OED) formulates the design problem as maximization of an expected-utility functional, commonly the expected information gain (EIG) quantified via the Lindley information measure. This risk-neutral formulation is agnostic to the variability in realized utilities encountered across distinct experimental outcomes, which is increasingly problematic in high-stakes or resource-limited application domains. The paper addresses this deficiency by proposing a mean–variance Bayesian OED criterion that introduces explicit penalization of utility variance, thus allowing a robust trade-off between maximizing average utility and controlling the risk of potentially adverse (low-utility) experimental outcomes (2604.04315).
Given design variable d∈Rd, parameter θ∈Rp, and observation Y∈Rn with their corresponding prior and data model, the expected utility U(d) is expressed as
U(d)=Eθ,Y∣d[u(d,Y,θ)]
where u is typically instantiated as the Kullback–Leibler (KL) divergence between posterior and prior. Realized utility, however, remains a random variable under the prior predictive measure. The proposed framework introduces utility variance,
V(d)=Eθ,Y∣d[(u(d,Y,θ)−U(d))2]
yielding the mean–variance criterion:
Jλ(d)=U(d)−λV(d)
where λ≥0 modulates the risk aversion of the design. The case λ=0 recovers the standard risk-neutral EIG maximization, θ∈Rp0 translates to risk-averse design, and θ∈Rp1 to risk-seeking.
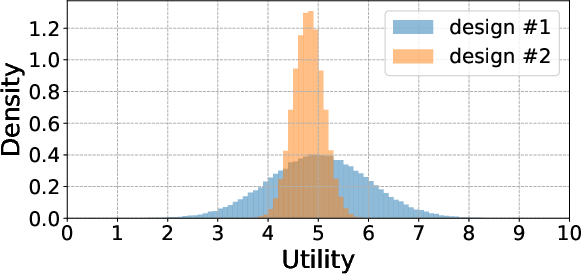
Figure 1: Utility distributions at two example designs, illustrating that higher expected utility can coincide with substantially increased variance.
Monte Carlo Estimation and Algorithmic Framework
Evaluation of θ∈Rp2 necessitates estimation of both mean and variance of the (nested) utility. For the canonical information gain case, the paper devises Monte Carlo (MC) procedures for unbiased (or asymptotically unbiased) estimation of θ∈Rp3, the second moment θ∈Rp4, and thence θ∈Rp5. These estimators rely solely on prior predictive sampling, which avoids the intractability intrinsic to explicit posterior sampling required for general nonlinear models.
The estimators incorporate common random numbers (CRS) techniques—using identical random seeds/samples across designs to eliminate extraneous MC noise in the objective difference across designs—and sample reuse strategies for computational efficiency. Analytical derivations detail leading-order bias and variance behavior of these estimators.
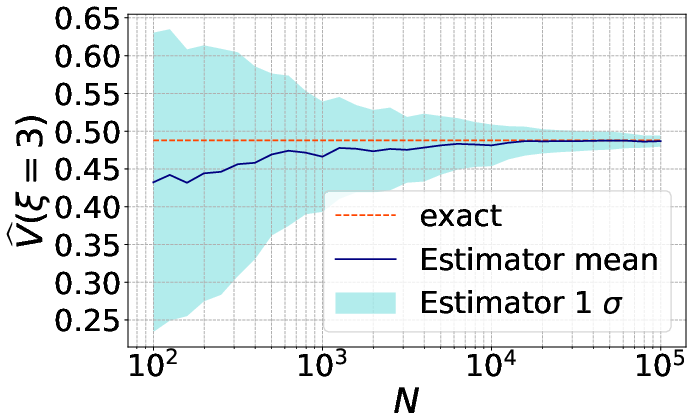
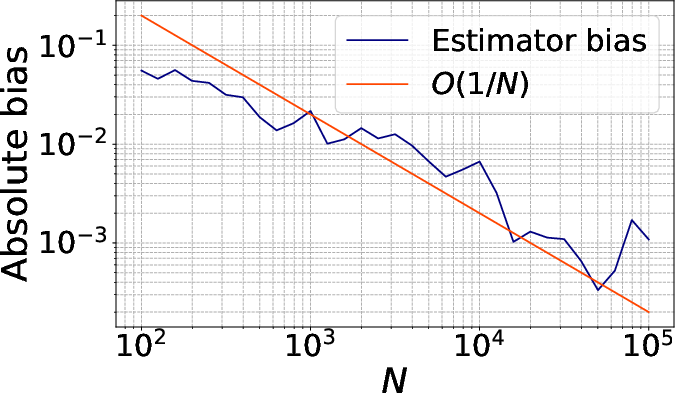
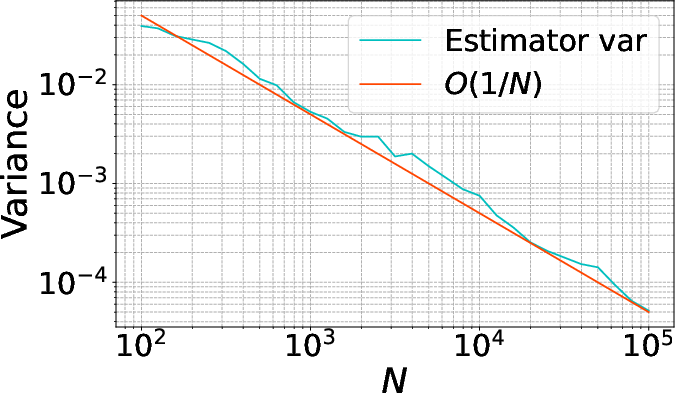
Figure 2: Convergence of the MC estimator θ∈Rp6 at a fixed design, empirically verifying the predicted θ∈Rp7 rate.
Optimization of the noisy, expensive objective is performed by Bayesian optimization (BO) over the design space, using GP surrogates and acquisition strategies designed to maximize sample efficiency.
Numerical Validation: Benchmarks and Realistic Scenarios
Linear-Gaussian Benchmark
A single-parameter, single-design-variable Gaussian model is used to validate the MC estimators against the closed-form analytic result for utility variance.
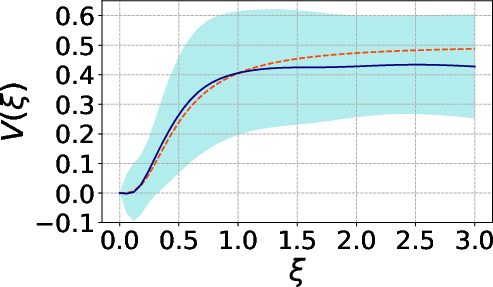
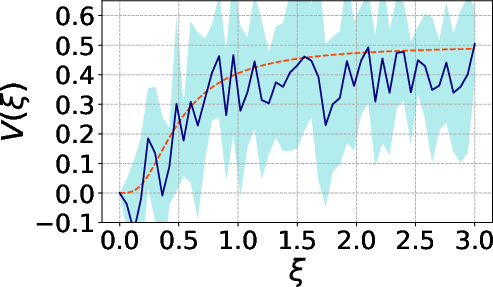
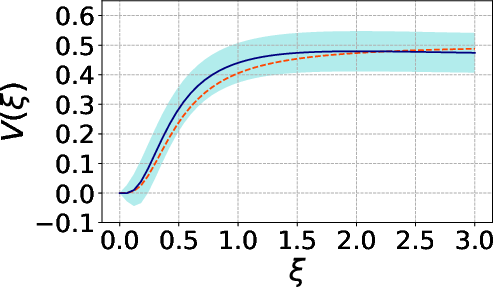
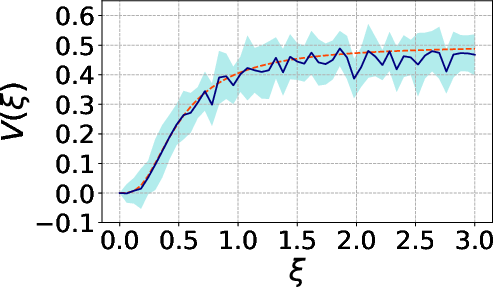
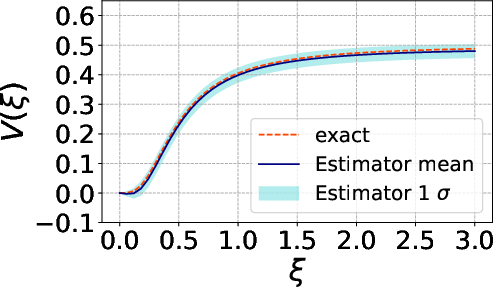
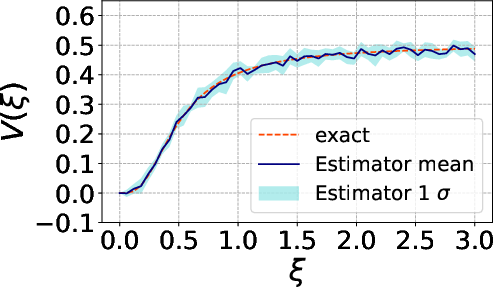
Figure 3: Behavior of the estimator with θ∈Rp8 MC samples.
The MC estimators for both θ∈Rp9 and Y∈Rn0 exhibit rapid convergence and decay of both bias and variance with increasing sample size, underpinning their operational viability for practical model settings.
Nonlinear Analytic Test Problem
A cubic-exponential nonlinear regression model with a flat prior and low-noise regime is examined in both 1D and 2D experimental design. For this archetype, the designs maximizing EIG and those minimizing risk under mean–variance differ substantially, with high-EIG locations exhibiting large utility variance and hence significant downside risk. As Y∈Rn1 increases, the mean–variance optimum shifts away from these risky designs toward more robust, lower-variance alternates.
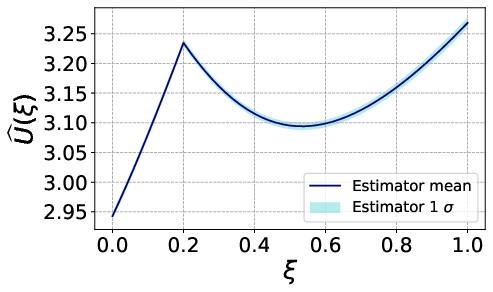
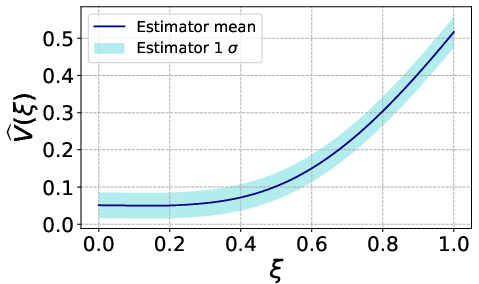
Figure 4: Utility variance Y∈Rn2 showing multiple regions of local maxima, associated with high expected utility but large dispersion.
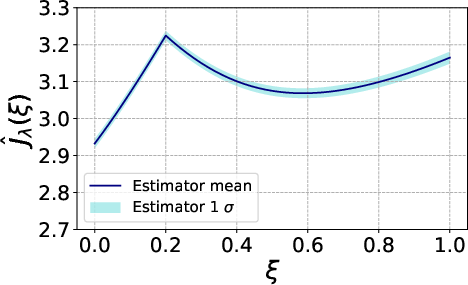
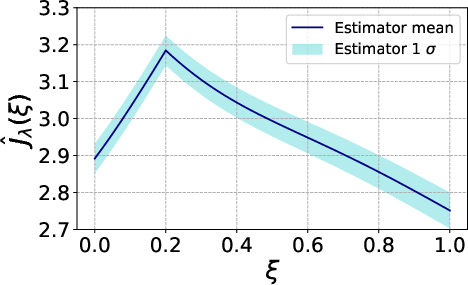
Figure 5: Estimated mean–variance objective for Y∈Rn3 demonstrating a shift in the optimum due to risk penalization.
Designs selected by the mean–variance criterion are empirically shown to possess tighter distributions of realized KL-divergence utility (Figure 6), validating the criterion’s effectiveness in constraining tail risk.
PDE-Governed Inverse Problems: Contaminant Source Inversion
A high-fidelity case study considers sensor placement for source inversion in a 2D diffusion PDE, both with and without structural obstacles. To make the design optimization tractable, the forward PDE is emulated via a deep neural network surrogate.
For both one- and two-sensor cases, the highest-EIG designs tend to extremal boundary or corner placements, but those designs have heavy tails in their utility distributions—i.e., a nontrivial probability of highly uninformative outcomes due to unfavorable source-sensor arrangements. Mean–variance designs shift away from the corners, favoring interior or symmetric placements that yield reduced variance with only minor loss in mean utility.
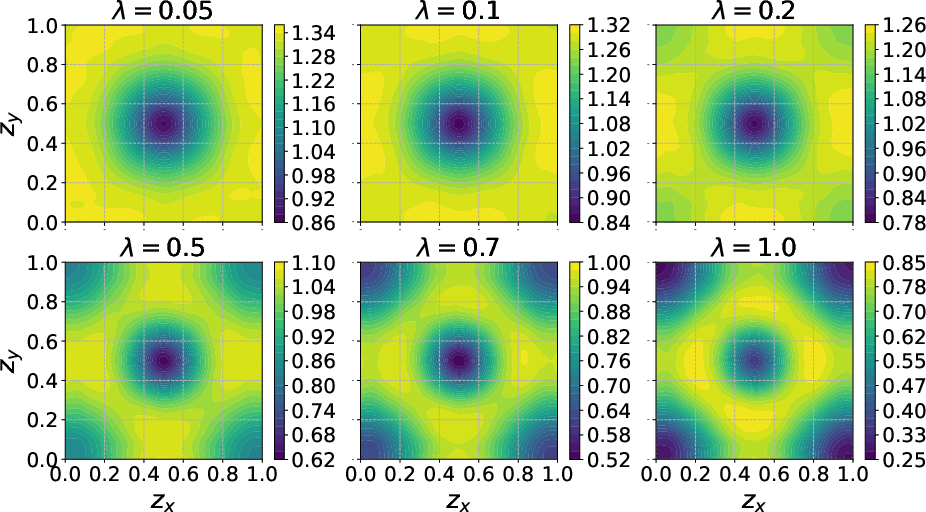
Figure 7: Estimated mean–variance objective for varying Y∈Rn4 in the one-sensor inversion instance.
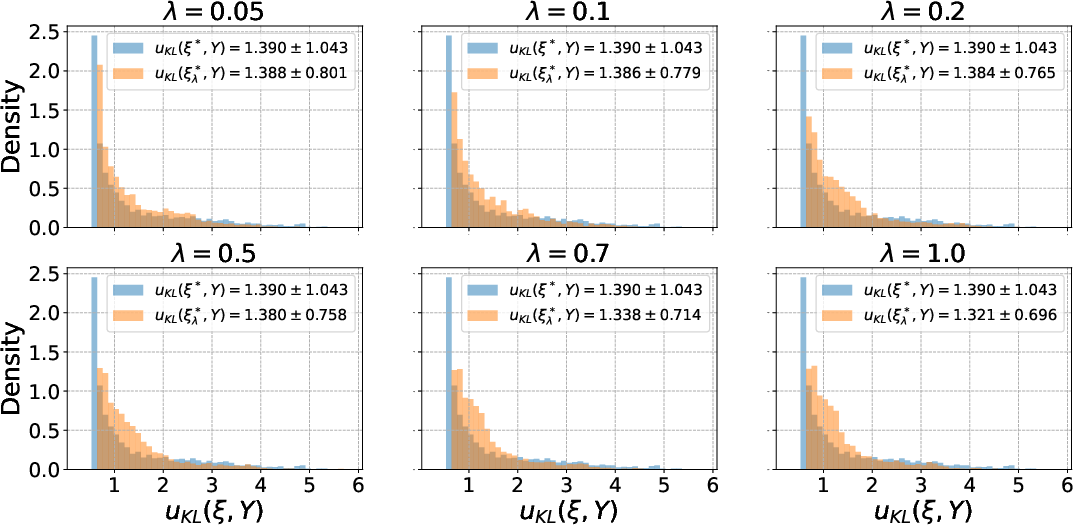
Figure 6: Histogram distributions of utility Y∈Rn5, contrasting mean-optimal and risk-aware designs and highlighting the suppressed variance at the mean–variance optimum.
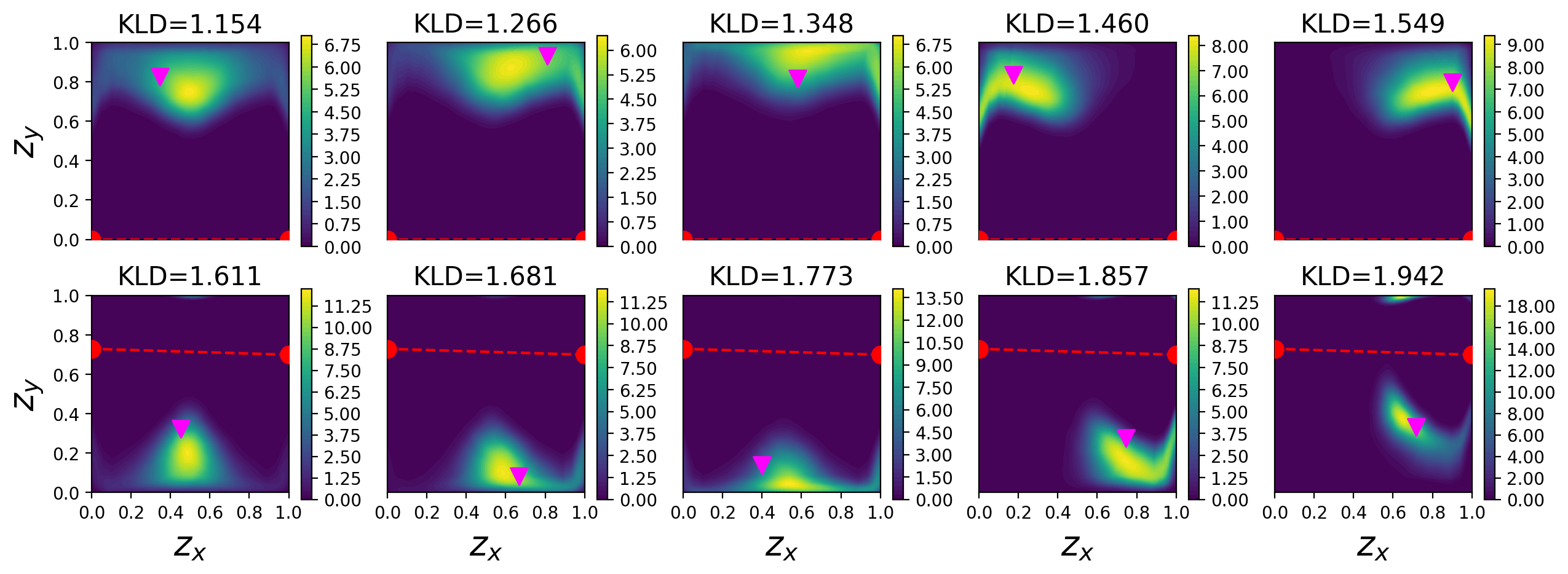
Figure 8: Posterior distributions associated with lowest-utility realizations, demonstrating substantially reduced ambiguity under mean–variance-optimal designs.
The same effect persists in geometrically constrained (obstacle) cases and with increased experimental dimensionality (multi-sensor scenarios)—risk-aware OED maintains competitive EIG while robustly avoiding extreme posterior uncertainty.
Implications and Future Directions
The mean–variance framework exposes and quantifies the critical trade-off between expected utility and stability of experimental outcomes in nonlinear Bayesian OED. The practical implication is that the classical EIG maximization approach can yield designs highly susceptible to rare, disastrous outcomes; variance-penalization provides rigorous, user-tunable mitigation for these risks, with immediate relevance for high-consequence engineering, physical, and scientific experiments.
On the computational side, the MC estimators developed generalize readily to any differentiable utility, and the combination with sample reuse and CRS techniques provides efficiency gains vital for large-scale or forward-model-intensive OED.
Theoretically, the adoption of mean–variance penalization is motivated by its analytical tractability. However, it is neither a coherent nor convex risk measure in the sense of modern risk theory. Future work should address risk functionals with stronger theoretical guarantees (e.g., CVaR, entropic risk, or worst-case analysis) and focus on advanced estimators (importance-sampling, Laplace, or multifidelity) to further reduce computational cost and bias. The selection and calibration of the risk-penalty parameter Y∈Rn6 remain critical open problems, ideally informed by utility-theoretic considerations and operational requirements.
Conclusion
The paper presents a comprehensive framework for variance-aware Bayesian OED in nonlinear and computationally intensive settings, rigorously addressing a prominent gap in the standard paradigm. Numerical results demonstrate that explicitly incorporating utility variance into the design objective yields experimental plans with robust performance, maintaining near-optimal EIG while substantially mitigating the probability of rare, information-poor outcomes. The methodology and estimators developed are directly applicable to a spectrum of modern OED instances, setting the foundation for further risk-aware advancements in statistical experimental design.