- The paper introduces DAGAF, a framework that jointly learns causal structures and synthesizes high-fidelity tabular data using multiple FCMs.
- It leverages adversarial, reconstruction, KLD, and MMD losses to align synthetic data with real distributions while ensuring the DAG acyclicity.
- Empirical results demonstrate lower Structural Hamming Distance and robust sample fidelity across synthetic and real-world datasets.
Directed Acyclic Generative Adversarial Framework for Joint Structure Learning and Tabular Data Synthesis
Introduction and Motivation
DAGAF introduces a unified approach for joint causal structure learning and high-fidelity tabular data synthesis by leveraging directed acyclic graph (DAG) representations and adversarial objectives. Standard approaches to causal discovery generally make rigid assumptions—focusing solely on a single identifiable functional causal model (FCM) such as LiNGAM, ANM, or, more rarely, PNL. This limitation introduces a significant risk of misidentifying the true underlying causal structure when the assumed FCM is misspecified, potentially leading to spurious data analyses and poor generalization in downstream applications. Moreover, the majority of existing generative models for synthetic tabular data do not preserve or exploit discovered causal structure, which severely limits their utility in settings where interventions, counterfactuals, or distributional robustness are important considerations.
DAGAF addresses these limitations by constructing a dual-step framework that first jointly learns the underlying DAG and parameterizes diverse FCMs (LiNGAM, ANM, PNL), then performs causally-faithful data synthesis by explicitly simulating the learned generative process. By integrating adversarial loss, reconstruction losses, Kullback-Leibler divergence, and maximum mean discrepancy into a multi-objective formulation, the model is robust to a range of dataset characteristics and mitigates the risk of identifiability breakdowns.
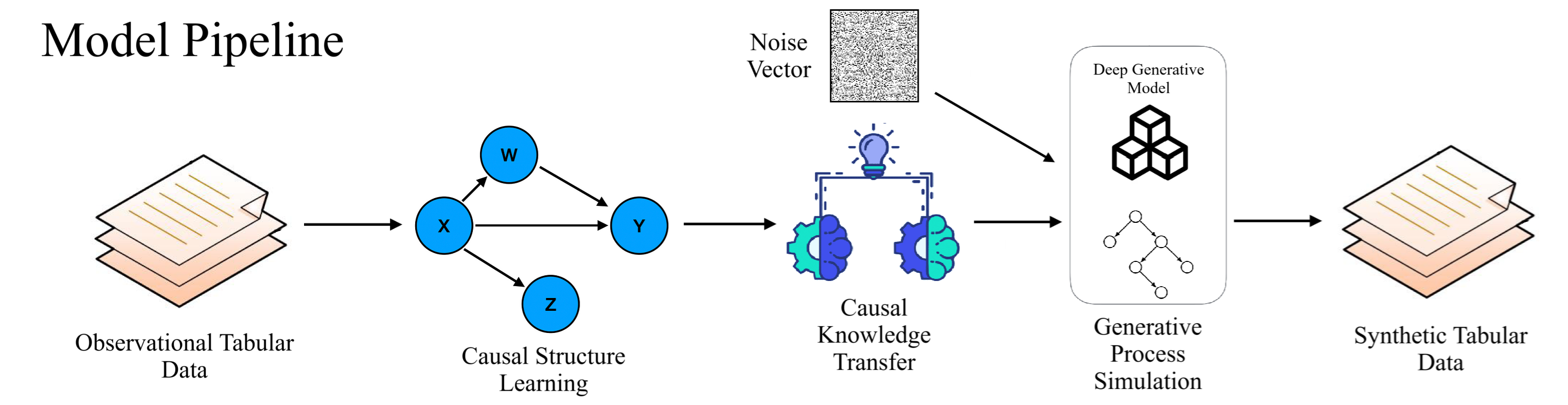
Figure 1: Pipeline of the DAGAF algorithm.
Framework and Theoretical Foundations
The DAGAF framework consists of (1) a causal discovery and structure learning phase and (2) an adversarial tabular data generation phase. Input data X is used to estimate a minimal DAG GA with parameterized edge weights and FCMs for each node. Unlike prior models that restrict attention to a single class of generating mechanisms, DAGAF flexibly supports LiNGAM (linear non-Gaussianity), ANM (additive nonlinear Gaussian), and the more general PNL (post-nonlinear models), treating these as special cases of a broader FCM class and dynamically selecting among them based on empirical fit.
Causal discovery proceeds by minimizing a multi-term objective comprising:
- Adversarial loss (Wasserstein with gradient penalty): Aligns synthetic and real sample distributions, acting as a robust estimator for the true generative process when the correct DAG is identified.
- Reconstruction loss (MSE): Ensures pointwise sample fidelity, beneficial for optimizing smooth gradients and stabilizing adversarial training.
- Kullback-Leibler divergence: Regularizes against overfitting the noise structure, especially for ANM, and improves model robustness to noisy or limited data.
- Maximum Mean Discrepancy (MMD): Penalizes higher-order distributional mismatches, addressing mode collapse and encouraging variance/shape alignment between synthetic and real distributions.
The acyclicity constraint, enforced through an augmented Lagrangian approach, guarantees that the learned structure is a DAG.
Figure 2: Optimization structure under various FCM assumptions (ANM, LiNGAM, PNL), illustrating reconstruction and adversarial loss flow as well as PNL-specific inverse function modeling.
Theoretical analysis establishes that, under standard identifiability assumptions for each model class, the DAGAF loss landscape possesses a unique minimum corresponding to the true generative graph. The framework formally delineates identifiability breakdown in the presence of discrete variables or non-i.i.d. data, providing explicit characterizations of when and how gradients from adversarial, MSE, KLD, or MMD terms will become biased or unstable under deviation from faithfulness or conditional independence.
Empirical Evaluation
Experimental evaluation encompasses synthetic (simulated) data, real-world tabular datasets (e.g., the Sachs protein signaling network), and benchmark Bayesian network datasets (Child, Alarm, Hailfinder, Pathfinder). Structure learning quality is primarily measured by Structural Hamming Distance (SHD); synthetic sample fidelity is assessed via correlation clustering, PCA, distributional overlap, and downstream regression tasks.
Across all dimensions, DAGAF persistently demonstrates lower SHD (higher structure recovery fidelity) relative to state-of-the-art models (DAG-GNN, GraN-DAG, DAG-WGAN, GAE, DAG-NF, DCRL, VI-DP-DAG), with the performance gap increasing with dimensionality. For instance, in continuous settings with d=100 and post-nonlinear data-generating processes, SHD is reduced by >30% relative to the best alternatives. On the real Sachs dataset, SHD of 8/9 (PNL/ANM) compares to 15–25 for previous methods—a strong claim regarding performance trade-offs between generalized and PNL-specific model classes.
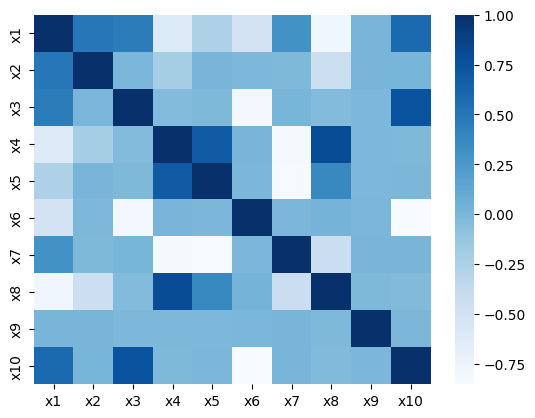
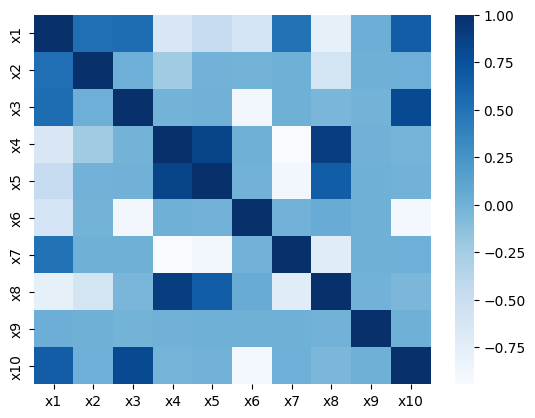
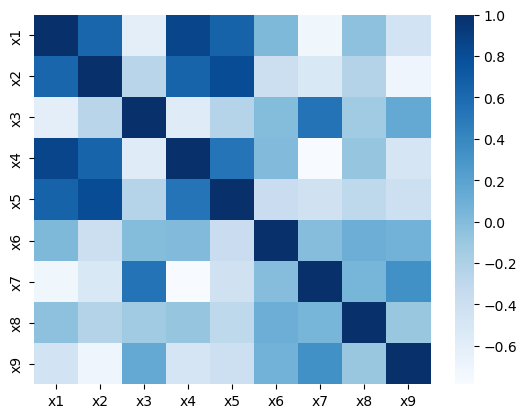
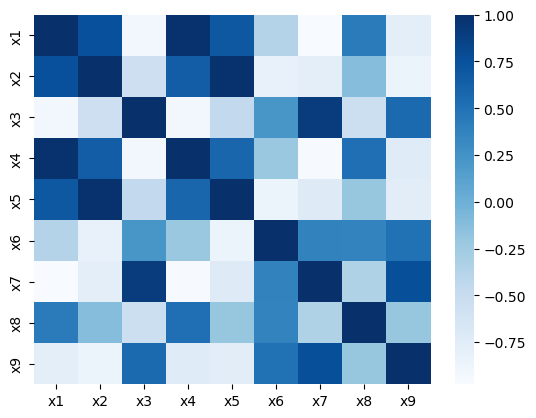
Figure 3: Correlation matrices for real and synthetic features reveal almost identical dependency structures under both ANM and PNL assumptions.
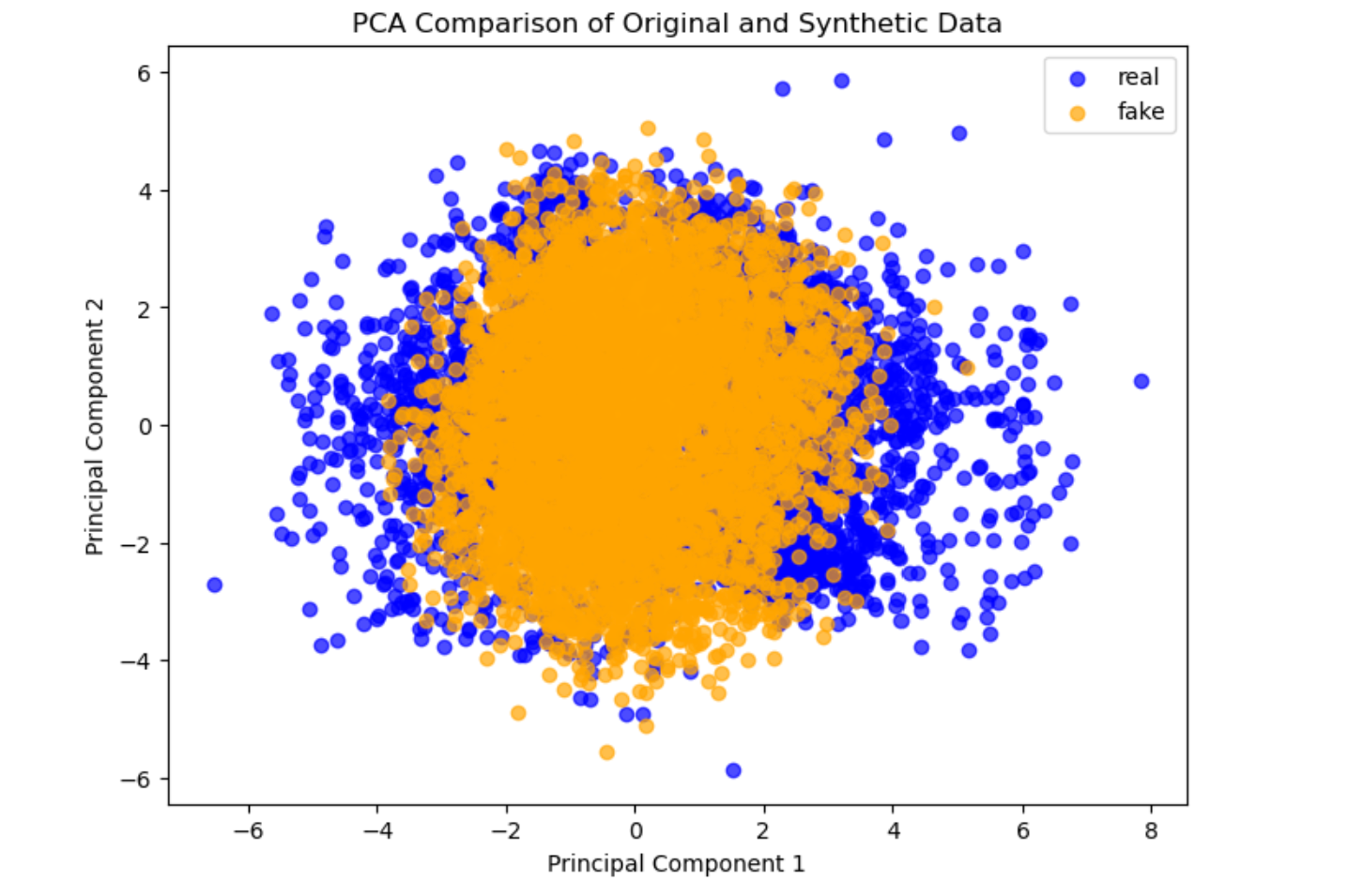
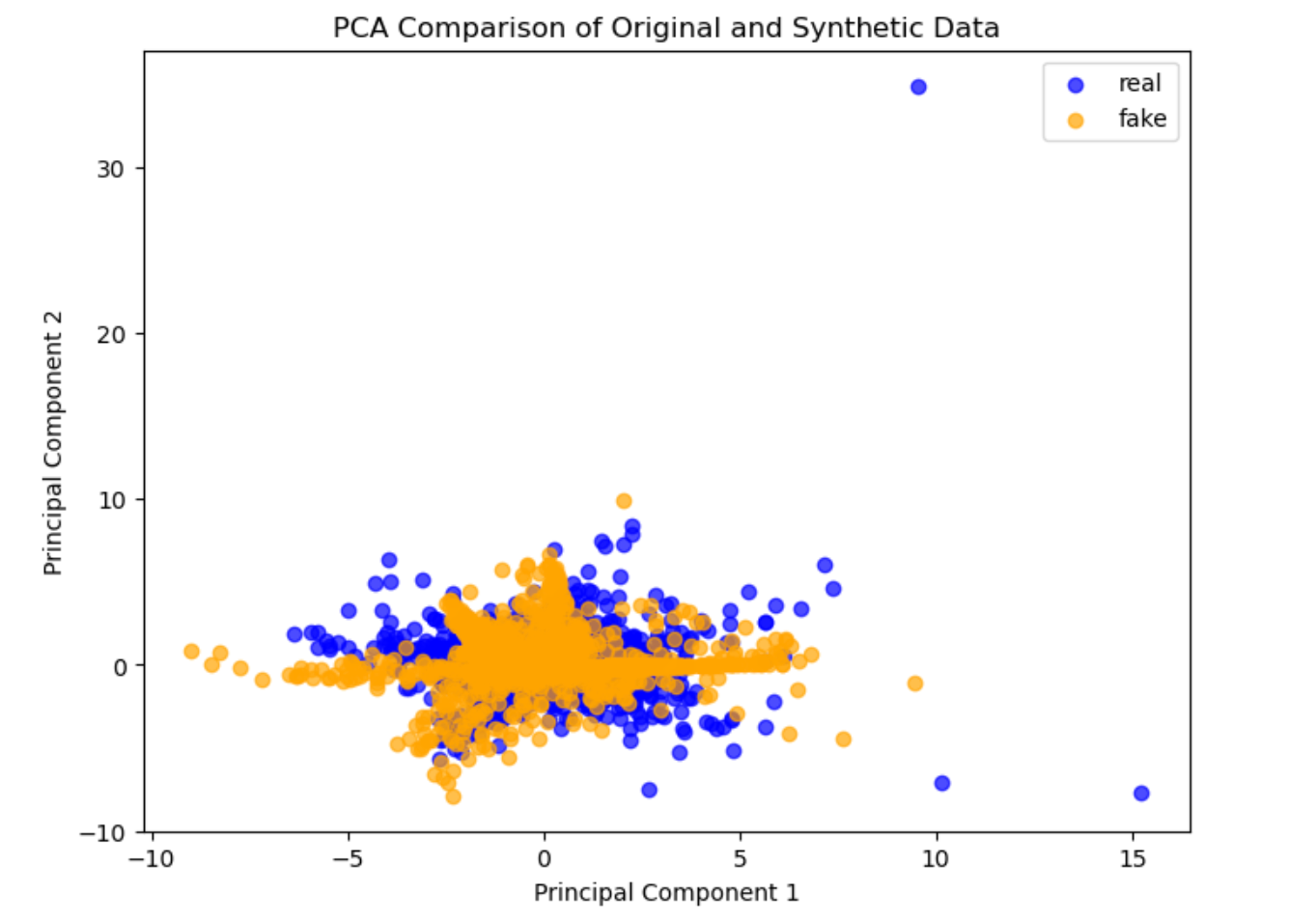
Figure 4: Principal Component Analysis (PCA) for original versus synthetic samples; synthetic data exhibits similar clustering and outlier patterns, indicating robust distributional replication.
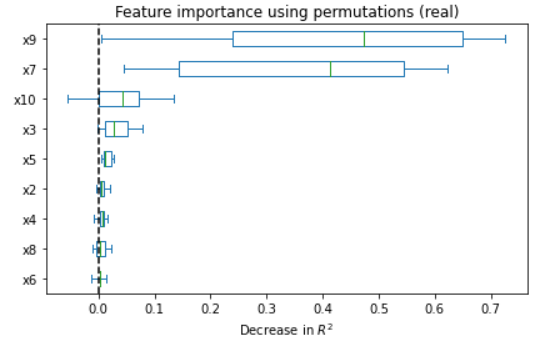
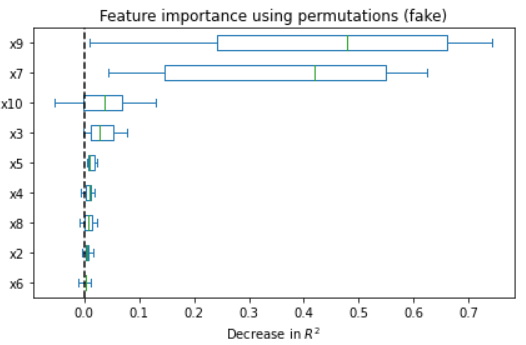
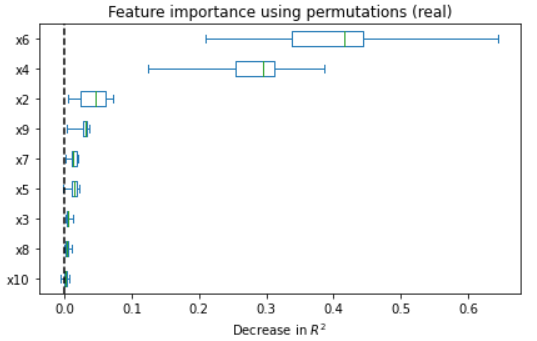
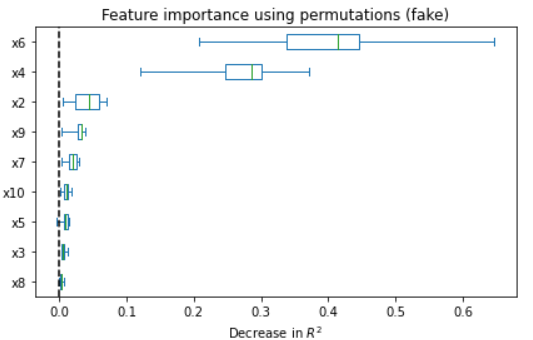
Figure 5: Feature importance comparison between original and synthetic data in ANM and PNL cases; synthetic regressors recapitulate real feature importance rankings.
Quality analyses of synthetic samples indicate that not only are the marginal and joint dependencies well-captured, but that real and synthetic data are statistically indistinguishable under a battery of tests (correlation, PCA, regression). Wasserstein distance convergence tightly tracks structure recovery (low SHD epochs correspond to minimal distributional divergence).
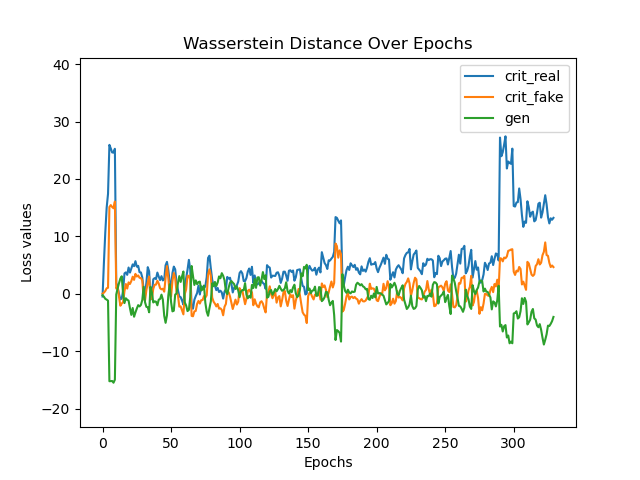
Figure 6: Training trajectory of Wasserstein distance—convergence is associated with low SHD epochs, confirming theoretical predictions that structure learning and distribution alignment are mutually reinforcing.
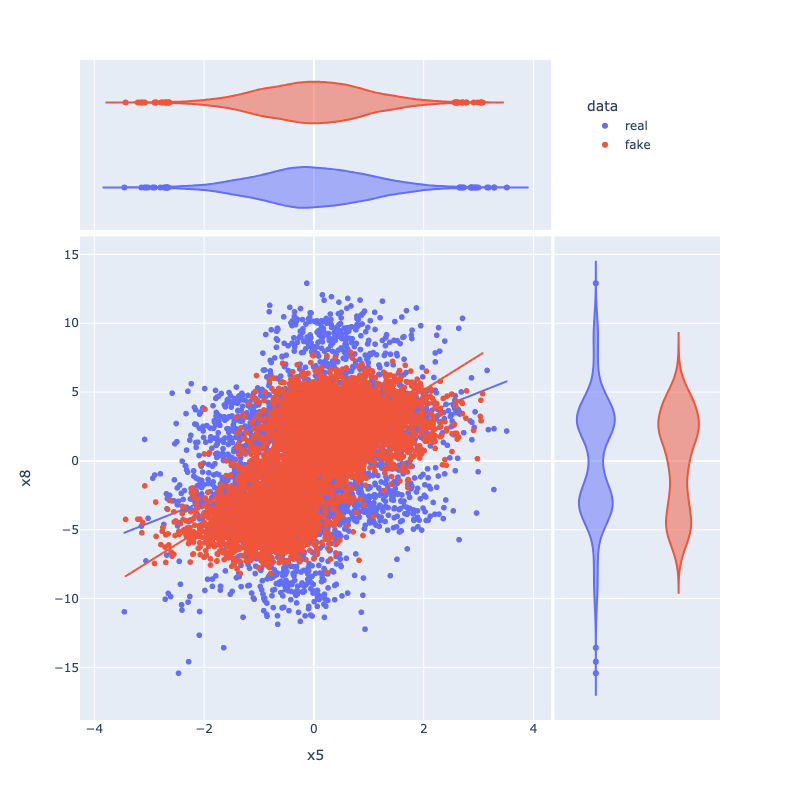
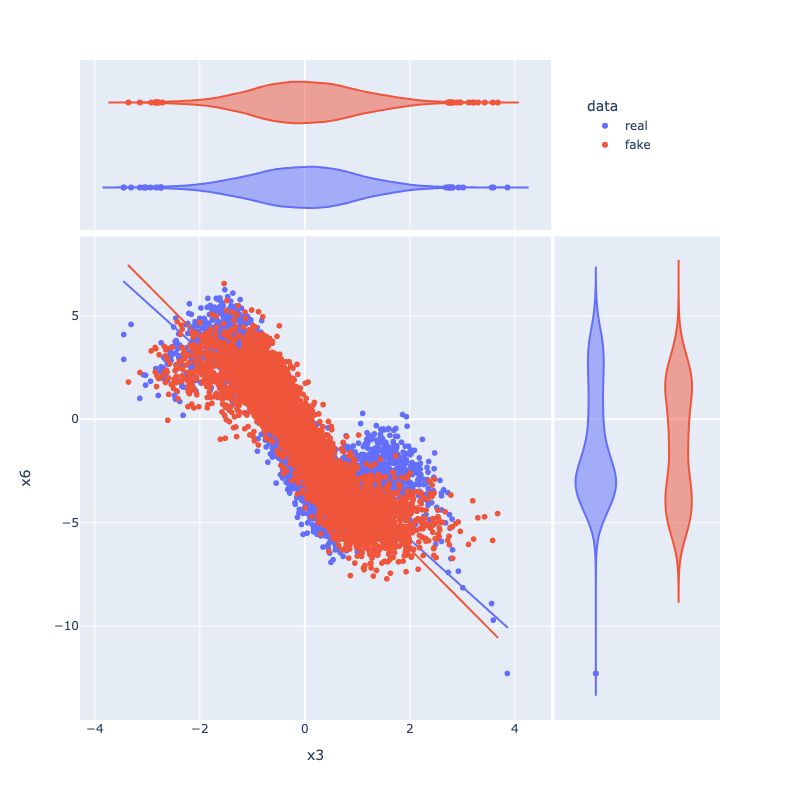
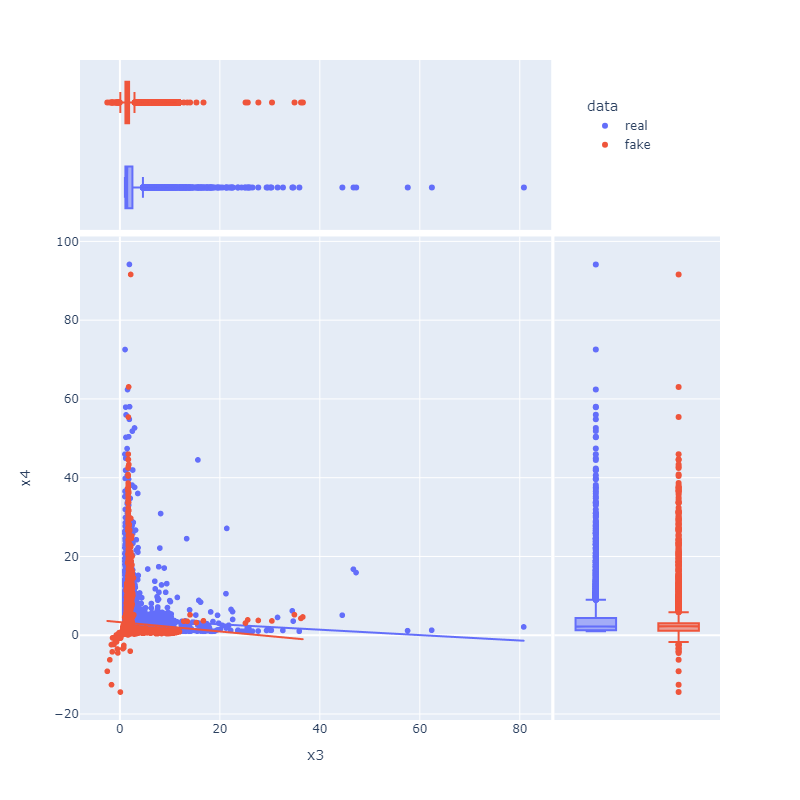
Figure 7: Distributional comparisons for feature pairs (e.g., x5 vs x8) show accurate modeling of joint and marginal densities in both real and synthetic ANM/PNL samples.
Implications and Discussion
The integration of joint structure learning within the generative model enables broader application of synthetic tabular data in domains requiring interventionally robust or causally explainable generative models. By resolving the non-uniqueness of Markov-equivalent structures with flexible poly-assumptive FCM choices and adversarial structure alignment, DAGAF strengthens the foundation for high-stakes downstream tasks (e.g., digital twin simulation, fairness auditing, robust causal inference).
Furthermore, the modularity of the framework—supporting new FCMs or neural architectures (e.g., attention, graph neural layers)—invites immediate extension to time-series, mixed-type, or incomplete data domains. The detailed failure mode analysis (missingness, discrete data, non-i.i.d. structure) provides principled guidance on applicability and avenues for extension, particularly for robust imputation and attention modules that could leverage partial domain knowledge or soft interventions.
Limitations and Future Directions
Despite strong empirical and theoretical performance, DAGAF exhibits cubic complexity in d due to the augmented Lagrangian and multi-term neural optimization—a challenge for ultra-high-dimensional or latency-sensitive applications. Robustness to substantial missingness or heterogeneity remains limited (as with all observational causal discovery approaches). The experiments focus on a specific set of FCMs; adapting the adversarial-discovery architecture to other easily-identifiable models (e.g. generalized additive models, index models, flexible autoregressive families) is explicitly targeted for future work.
There is also clear potential for integrating attention-based architectures (e.g., transformers) into DAGAF, exploiting the natural connection between attention weights and parent-set selection in learned DAGs—an opportunity for principled digital twin construction in industrial and clinical settings.
Conclusion
DAGAF presents a robust, theoretically-justified, and experimentally validated framework for simultaneous causal DAG discovery and high-fidelity tabular data synthesis. The model's poly-FCM approach, adversarial multi-term loss, and explicit acyclicity enforcement collectively achieve superior DAG recovery and data generation fidelity compared to existing baselines. DAGAF's extensibility and empirical performance position it as a reference architecture for next-generation causal generative modeling in both research and applied domains.