- The paper demonstrates that LLM-enhanced OSS systems inherit classical CWE vulnerabilities while emerging architectural exposures shape exploitability.
- It employs rigorous manual annotation with high inter-annotator reliability (Cohen’s Kappa 0.76) to classify advisories from 133 unique packages.
- Findings highlight GitHub metadata limitations and the need for enriched, architecture-aware vulnerability disclosure models.
Empirical Analysis of Vulnerabilities in LLM-Associated Open-Source Software
Introduction
The rapid integration of LLMs into open-source software (OSS) ecosystems necessitates a reevaluation of existing vulnerability disclosure frameworks, especially as natural language prompts, probabilistic model outputs, and execution-capable components create emergent interaction pathways that diverge from those of conventional software. The study "LLM-Enabled Open-Source Systems in the Wild: An Empirical Study of Vulnerabilities in GitHub Security Advisories" (2604.04288) provides a systematic investigation into the manifestation and characterization of vulnerabilities in LLM-integrated packages within the GitHub Security Advisory (GHSA) ecosystem from January 2025 to January 2026. The analysis couples both Common Weakness Enumeration (CWE) and the OWASP Top 10 for LLM Applications 2025 to reveal how implementation-level defects and architectural exposures jointly define risk in modern OSS.
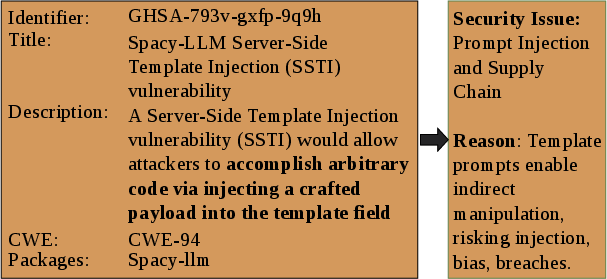
Figure 1: Illustration of model-mediated exposure in an LLM-associated advisory, highlighting how probabilistic LLM outputs mediate pathways to vulnerable components.
Methodology
A dataset of 295 GHSAs referencing LLM-related components forms the empirical basis, gathered via targeted keyword matching against metadata and advisory text. 133 unique packages are manually classified into three groups—LLM-associated, Possible LLM-associated, and Non-LLM-associated—using repository analysis and thematic grouping. A random sample of 100 advisories impacting LLM-associated or Possible LLM-associated packages is annotated according to OWASP LLM risk categories, providing architectural context otherwise absent from GHSA metadata. Inter-annotator agreement (Cohen's Kappa 0.76, Gwet’s AC1 0.95) validates the reliability of the manual annotation process.

Figure 2: Overview of the data collection, filtering, sampling, and annotation pipeline, mapping the study's workflow from advisory selection to architectural risk annotation.
Key Empirical Findings
Implementation-Level Weaknesses
Across both the complete and annotated datasets, vulnerabilities predominantly fall within conventional CWE-defined classes associated with input and code injection (CWE-94, CWE-77, CWE-78, CWE-89, CWE-79), unsafe deserialization (CWE-502), path traversal (CWE-22), and resource exhaustion (CWE-770, CWE-400). Injection-related defects are overwhelmingly prevalent, with no evidence for new, LLM-specific implementation weakness categories. Instead, LLM components inherit and propagate traditional software weaknesses, reflecting the persistent efficacy of established secure development practices for LLM-integrated architectures.
Architectural Exposure Patterns
Manual mapping using the OWASP Top 10 for LLM Applications taxonomy surfaces recurrent architectural risks largely absent from existing advisory schema. In particular, Supply Chain (LLM03, 44%), Excessive Agency (LLM06, 20%), and Prompt Injection (LLM01, 18%) are the most common, with multi-label combinations appearing in 37% of annotated cases. These multi-stage patterns highlight how model-generated outputs traverse through prompt manipulation, output handling, and execution authority mechanisms, frequently culminating in exploitable states that are not directly attributable to model internals but to orchestration and integration logic.
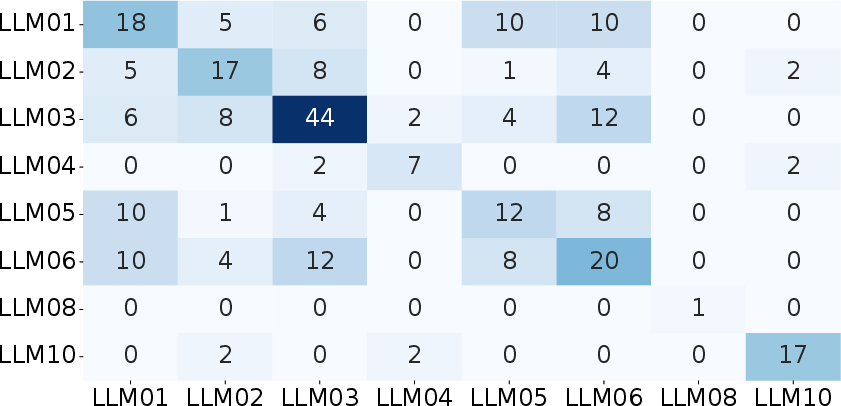
Figure 3: Co-occurrence heatmap of OWASP LLM Risk Categories, emphasizing multi-label clusters such as Supply Chain + Excessive Agency and Prompt Injection + Improper Output Handling.
Mapping between OWASP and CWE shows that architectural risks consistently materialize via classical implementation defects (e.g., LLM03–Supply Chain via CWE-78/77/94/502), indicating that model-enabled exposures are not introducing novel vulnerability classes but altering the composition and traversal of known weaknesses.
GHSA metadata is shown to lack structured indicators for LLM involvement or model-mediated exposure. Neither affected package fields nor CWE assignments communicate whether the vulnerability leverages model inference, agent autonomy, or orchestrated tool invocation. Identification of LLM relevance and architectural risk currently depends on manual categorization and annotation, impeding automated or large-scale risk analytics for LLM-enabled OSS.
Implications for Secure LLM Integration
The study robustly demonstrates that classical code-level vulnerabilities remain central in LLM-associated systems, but that system-level risk cannot be fully articulated via implementation-focused CWE taxonomies alone. Architectural exposure, particularly through model coupling and dynamic prompt handling, shapes how vulnerabilities propagate and are ultimately exploitable. Notably, supply-chain vulnerabilities dominate, exacerbated by the interconnection of specialized LLM toolkits, orchestration libraries, and vector stores, which amplifies transitive exposure.
The findings further indicate that the existing GHSA disclosure model requires extension to explicitly encode LLM involvement, enabling more systematic and automated architectural risk detection. Absent such structural augmentation, vulnerability management for LLM-enabled OSS will remain labor- and expertise-intensive.
Limitations
The study’s scope is intentionally restricted: it only considers advisories surfaced through GHSA within a one-year window, leverages keyword-based filtering (potentially missing latent LLM associations or overincluding generic cases), and applies manual annotation, which is inherently interpretive despite high inter-rater reliability. Only disclosed vulnerabilities are assessed, so the prevalence of yet-undetected LLM-specific exposures is unknown.
Conclusion
The empirical analysis in this study establishes that, at present, LLM-enabled OSS does not introduce novel implementation-level weaknesses outside the CWE schema but does transform the ways conventional defects are exposed and exploited due to model-mediated interaction and supply-chain complexity. CWE and OWASP perspectives are complementary; a comprehensive risk profile for LLM-integrated systems demands both. Immediate requirements are for richer, LLM-aware advisory metadata and for architecture-driven security auditing across OSS supply chains. Future research should pursue automated advisory enrichment, broader disclosure source incorporation, and longitudinal architectural risk modeling to further advance secure LLM adoption.