- The paper demonstrates that LLMs, especially reasoning-optimized models like DeepSeek-R1, outperform static analyzers in detecting code vulnerabilities.
- It employs five distinct prompt strategies, including CWE listings and Chain-of-Thought reasoning, to enhance accuracy across varied code contexts.
- Results reveal that factors like token count, annotation relevance, and code community significantly influence LLM performance and consistency.
An Insight into Security Code Review with LLMs: Capabilities, Obstacles, and Influential Factors
Introduction
The study "An Insight into Security Code Review with LLMs: Capabilities, Obstacles, and Influential Factors" (2401.16310) undertakes an empirical evaluation of the potential for using LLMs as tools in security code review, compared to state-of-the-art static analysis tools. This research highlights the advantages and limitations of LLMs in the context of detecting security defects in code files. It evaluates seven LLMs under different prompting strategies and compares their performance against well-established static analysis tools in Python and C/C++ datasets.
Methodology
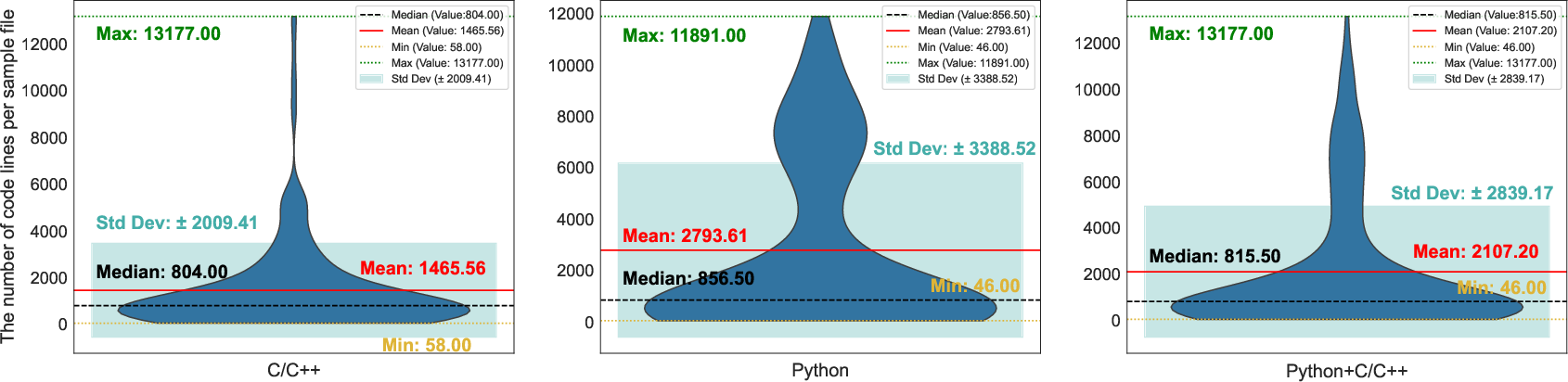
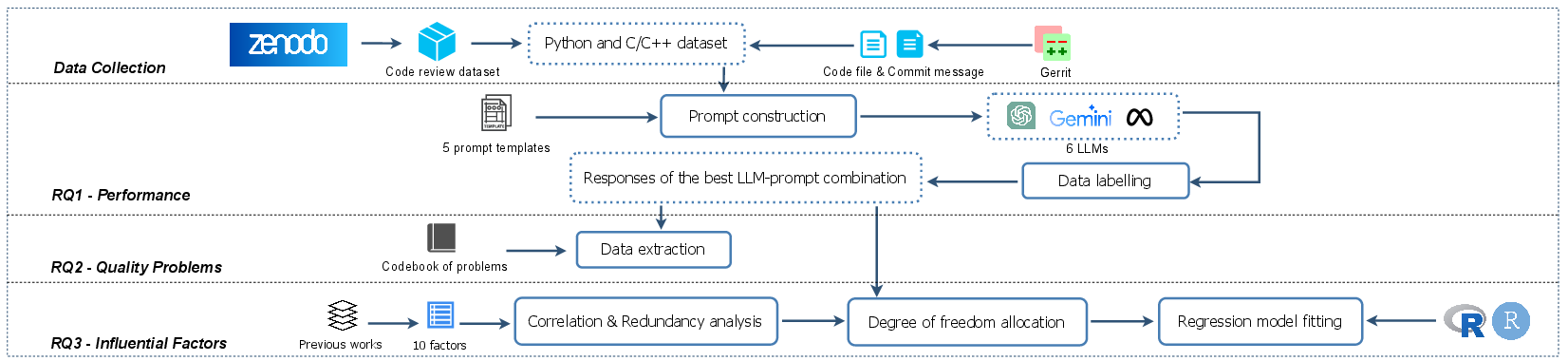
The paper explores three central Research Questions (RQs) to assess the capabilities of LLMs in security code review. The RQs involve evaluating LLM performance in detecting security defects, identifying quality issues in LLM-generated responses, and analyzing factors influencing LLM performance. The empirical study uses a dataset constructed from 534 code review files, featuring 15 predefined security defect types and diverse code contexts from four open-source projects.
Prompt Design
Five distinct prompt templates were crafted, varying from basic prompts to those integrating Common Weakness Enumeration (CWE) lists and Chain-of-Thought (CoT) reasoning to optimize LLM response accuracy. Particular emphasis was given to how these varied prompts impact the effectiveness of LLMs across different datasets and contexts.
Key Findings
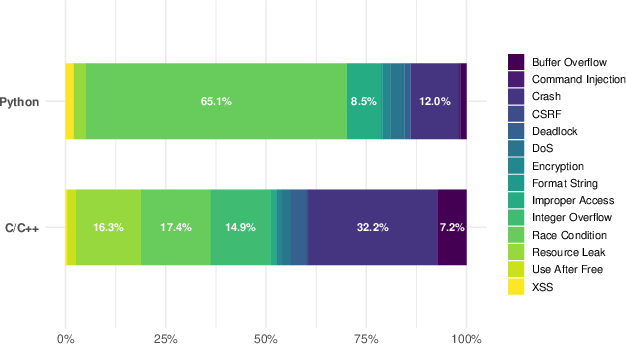
The results demonstrate that LLMs, particularly reasoning-optimized models like DeepSeek-R1, significantly surpass traditional static analysis tools in detecting security defects. These models exhibit superior handling of security code reviews when supported by tailored prompts, showcasing improved detection of vulnerabilities such as race conditions and integer overflows.
Quality and Consistency Concerns
While LLMs demonstrated capabilities in identifying defects, issues such as verbose outputs and inconsistent results across iterations were noted. These challenges underline the importance of prompt construction and highlight intrinsic model variability as a significant factor.
Influential Factors
Several factors significantly impact the performance of LLMs:
- Token Count: Models generally perform better with fewer tokens, underscoring the need for efficient input processing.
- Annotation Relevance: Security-relevant comments in code were identified as critical guides for LLM performance, aiding in more precise defect detection.
- Community and File Type: Variations in performance were associated with different code communities (e.g., OpenStack vs. Qt) and file types, accentuating the need for contextual adaptability in LLM applications.
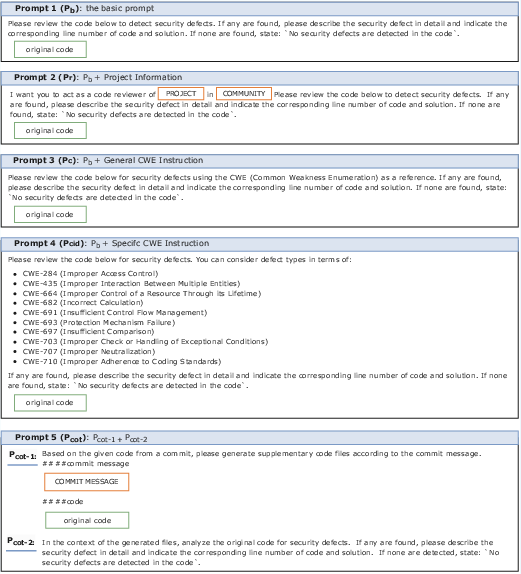
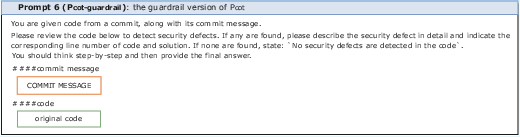
Figure 4: Construction templates for the five prompts.
Conclusions and Future Directions
This study underscores the transformative potential of LLMs in security code review, demonstrating their effectiveness over traditional tools in recognizing and explaining security defects. Future work should focus on refining prompt strategies, enhancing model consistency, and exploring the integration of external knowledge bases to mitigate hallucinations and amplify LLM utility.
In conclusion, while LLMs like DeepSeek-R1 offer enhanced capabilities, addressing issues such as non-determinism and leveraging detailed CWE information remain essential steps toward maximizing their efficacy in automated security reviews. The evolution of LLMs in this domain promises significant advances in software security, particularly through improvements in model precision and contextual understanding.