Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
Abstract: Recent advances in prompt learning allow LLM agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Combee, a new way to help AI language agents learn faster and better from their past experiences without retraining their internal weights. It focuses on “prompt learning,” which means the AI builds and updates a shared guide (like a playbook or set of rules) from what it sees while working, so it can do future tasks more accurately.
What questions did the researchers ask?
The researchers asked:
- How can AI agents learn from many past runs at the same time (in parallel) without the quality of their learning getting worse?
- Why do existing methods break down when we try to learn from lots of experiences at once?
- Can we design a system that speeds up learning (by using many agents in parallel) while keeping or improving accuracy?
How did they do it?
First, here’s the problem in simple terms.
The problem: “Context overload”
Imagine a teacher trying to read and summarize 100 student journals in one sitting. Even if the teacher can fit all the journals on the desk, there’s just too much to process at once. The summary ends up being very general (“study more,” “check your work”) and misses the specific, useful tips (“for problem type X, do Y”). That’s what happens to current AI prompt-learning methods when we scale up: the AI that gathers lessons from many agents at once tends to squash them into generic advice, and accuracy drops.
The solution: Combee
Combee is named after a bee colony because it lets many workers cooperate smoothly. It uses a “Map–Shuffle–Reduce” approach—think of it as organizing lots of notes so you don’t overwhelm the summarizer.
- Map: Many agents work in parallel. Each agent completes tasks and writes short “reflections” (notes about what worked, what didn’t, and helpful strategies).
- Shuffle: To avoid losing important notes, Combee duplicates each reflection a small number of times and shuffles them. This gives each useful tip multiple chances to be included in the final guide.
- Reduce (with parallel scan): Instead of dumping everything into one big summary, Combee combines notes in stages. Small groups summarize their notes first. Then those group summaries get combined into a final guide. This layered approach prevents overload and preserves specific, high-value tips.
Combee also includes:
- A dynamic batch size controller: This automatically chooses how many parallel runs to include at once. It’s like finding the best line size at a theme park—large enough to be fast, but not so large that the ride slows down. This helps balance speed and quality without manual tuning.
What did they find, and why is it important?
The team tested Combee on several tasks:
- Agent worlds (AppWorld and Terminal-Bench): these involve multi-step tasks like using tools, APIs, or the command line.
- Finance tasks (FiNER and Formula): these involve finding financial entities and doing accurate numeric reasoning.
Key results:
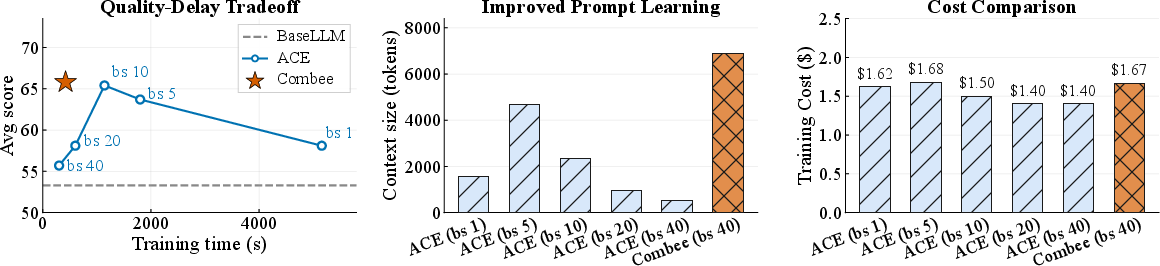
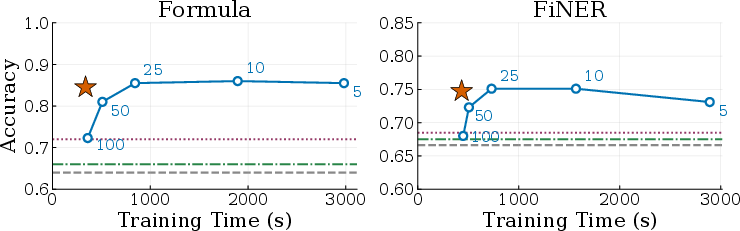
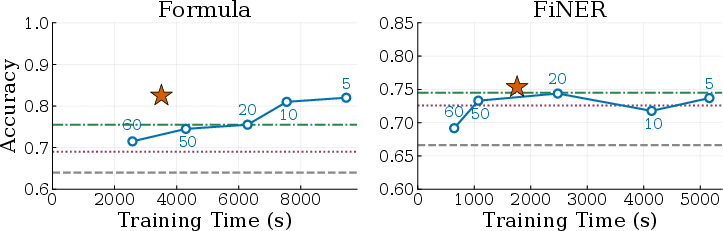
- Combee trained up to 17× faster than previous methods while keeping the same or even better accuracy and cost.
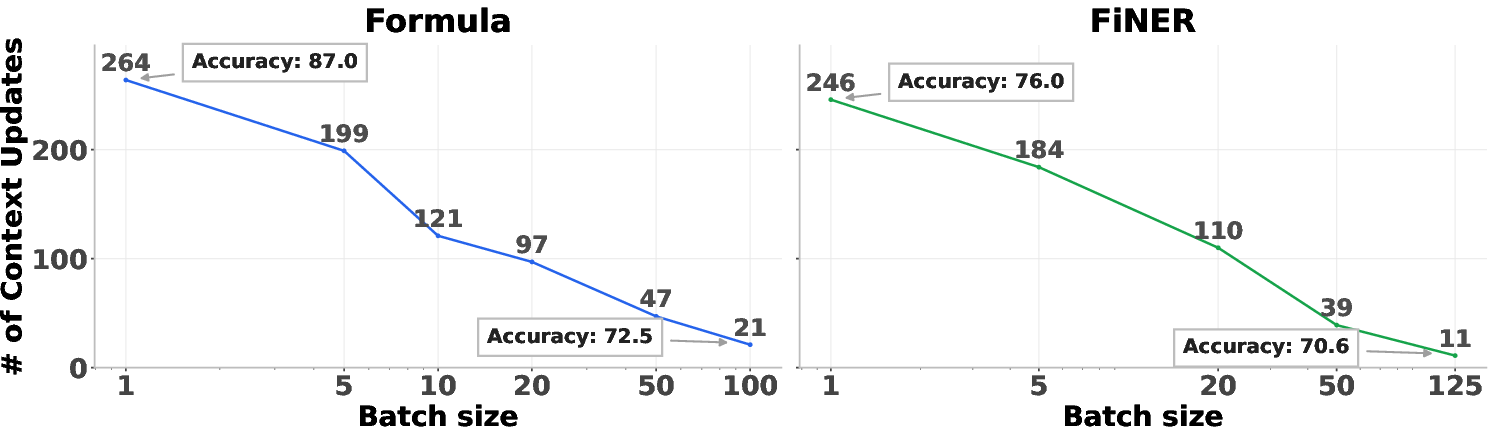
- Naively increasing parallelism (just batching more notes at once) hurt accuracy—agents lost specific, useful strategies. Combee prevented this “context overload.”
- Combee produced larger, more detailed playbooks (the shared guide) than naive batching. Bigger here means richer, not bloated—more specific tips were preserved.
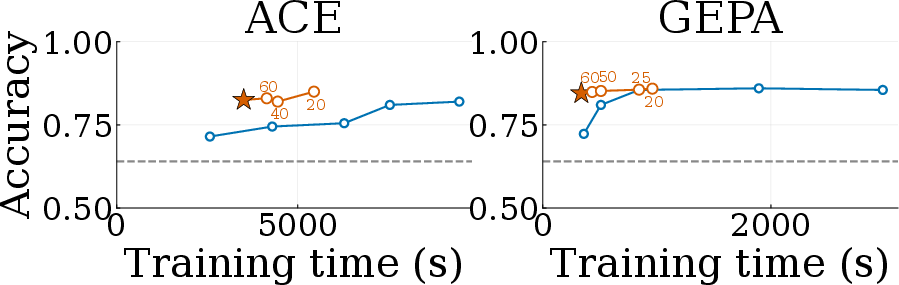
- It worked with different learning styles (ACE and GEPA) and different base models, showing it’s flexible and easy to integrate.
Why this matters:
- AI agents can learn from lots of experiences without becoming vague or generic.
- Teams and companies can run many agents at the same time to adapt faster, without paying extra or losing quality.
- It helps real-world systems (like coding assistants or finance tools) get better on the fly, using what they see while working.
What’s the impact and what could happen next?
Combee shows that prompt learning can scale. Instead of slowing down or getting worse as more agents run, AI systems can:
- Learn faster from many parallel tasks.
- Keep specific, high-value tips that truly improve performance.
- Plug into existing methods (like ACE and GEPA) with minimal changes.
This could make future AI agents more like smart, organized teams: they share lessons efficiently, update their playbooks as they go, and get better the more they work. That means quicker adaptation in tools for coding, research, customer support, and any job where AI learns from experience—without lengthy retraining.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased concretely to guide future work.
- Lack of theoretical grounding: No formal definition or analysis of “context overload,” nor guarantees (e.g., bounds) that parallel scan aggregation and augmented shuffling preserve high-value information under varying batch sizes or long-context regimes.
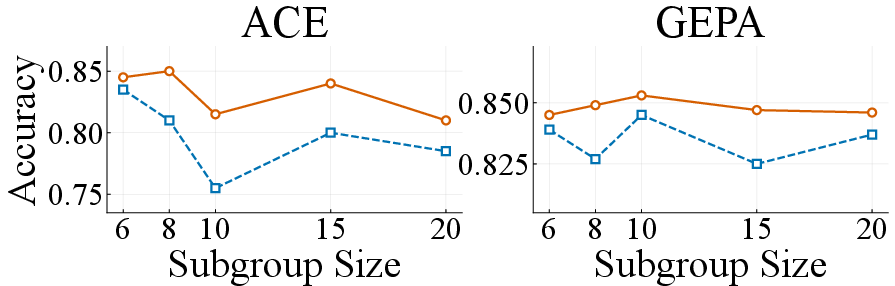
- Heuristic topology choice: The use of two-level aggregation with subgroup size k = ⌊√n⌋ is empirically motivated but unproven; optimal tree depth, branching factor, and topology remain unexplored, especially for n ≫ 100 or multi-level hierarchies.
- Parameter sensitivity of augmented shuffling: The duplication factor p (default p=2) is fixed and not rigorously tuned; its trade-offs (quality gains, token cost, risk of amplifying noise) and adaptive strategies (data- or model-dependent p) are unstudied.
- Conflict resolution in merging: The paper does not specify principled mechanisms for deduplication, contradiction handling, or consolidation of overlapping/competing rules when reflections are aggregated across subgroups; formal merge policies and consistency checks are needed.
- Memory growth and inference-time cost: Combee tends to produce much larger playbooks/prompts; the effects on inference latency, token cost, context-window utilization, and run-time accuracy are not measured, nor are pruning, indexing, or retrieval-based alternatives evaluated.
- Forgetting and drift: There is no policy for decaying, pruning, or updating stale or harmful entries over time (catastrophic prompt bloat, concept drift, or domain shifts), nor empirical studies on long-run maintenance strategies (e.g., scheduled garbage collection).
- Robustness to noisy/adversarial traces: The impact of low-quality, misleading, or poisoned reflections on aggregated prompts is not analyzed, and safeguards (verification, filtering, weighting, provenance checks) are absent.
- Generality across LLM families and context windows: Results are limited to DeepSeek-V3.1 and one GPT-OSS model; how Combee behaves with smaller context windows, different long-context behaviors, or models subject to “lost-in-the-middle” effects remains open.
- Aggregator model choice and specialization: Using the same or different LLM for acting vs. curation is not systematically compared; whether a specialized curator (or mixture-of-experts) improves retention of high-value entries is untested.
- Dynamic batch controller assumptions: The controller assumes a power-law delay curve and uses a fixed threshold (τ = 1.6% peak slope) based on single-iteration profiling; robustness to stragglers, heterogeneous clusters, non-stationary workloads, and cross-epoch variability is unexamined.
- Scaling beyond hundreds of workers: Practical limits (network overhead, synchronization, scheduler bottlenecks, tree depth, and memory pressure) and algorithmic adaptations for thousands of concurrent agents are not addressed.
- Task coverage and reflection length: Benchmarks focus on four datasets with relatively short reflections; applicability to tasks with long, noisy, multi-modal traces (e.g., large code diffs, lengthy logs, multi-document toolchains) is unknown.
- Retrieval vs. monolithic prompts: Combee primarily injects aggregated artifacts into system prompts; a hybrid approach (hierarchical indexing, retrieval gating, per-task selection) could mitigate prompt bloat—yet is not designed or evaluated.
- Evaluation metrics and statistical rigor: Beyond accuracy and “helpful hits,” richer metrics (specificity, coverage, redundancy, contradiction rate), statistical significance over multiple seeds, and error analyses are lacking.
- Cost accounting completeness: Training-cost comparisons ignore potential increases in inference-time cost due to larger prompts; end-to-end cost curves (training + inference) and accounting for duplication overhead are not reported.
- Position bias and ordering effects: Whether augmented shuffling or scan aggregation mitigates “lost in the middle” or other positional biases in long contexts is not experimentally isolated or quantified.
- Hyperparameter auto-tuning: Systematic guidance or automated methods to tune subgroup size, tree depth, p, curator prompt templates, and aggregation prompts are missing; only limited ablations are provided.
- Hybrid baselines: Stronger baselines (e.g., hierarchical summarization/RAG, learned indexing, rule-weighting, or per-leaf distillation with verified merging) are not included, limiting the scope of comparative conclusions.
- Safety and compliance: The Map–Shuffle–Reduce flow can duplicate and broadcast sensitive reflections; privacy-preserving aggregation, policy-aware filtering, and governance for regulated domains remain unaddressed.
- Provenance and weighting: Reflections from different tasks or agents likely vary in reliability; methods to track provenance and weight entries during aggregation (e.g., by utility, confidence, recency) are not developed.
- Lifetime management under deployment: How Combee updates, rolls back, or version-controls prompts in production settings (A/B testing, rollback on quality regressions, continual integration) is unspecified.
- Multi-epoch and continual learning behavior: The dynamics across many epochs (e.g., stability, oscillations, compounding effects of aggregation) are not studied; current results focus on single-epoch or short runs.
- Applicability beyond ACE/GEPA: While claimed framework-agnostic, Combee is only prototyped on ACE/GEPA; generalization to other generate–reflect–update systems (e.g., DC, Reflexion variants, memory graphs) needs empirical validation.
Practical Applications
Practical Applications of “Combee: Scaling Prompt Learning for Self-Improving LLM Agents”
Combee introduces a Map–Shuffle–Reduce framework (parallel scan aggregation, augmented shuffling, dynamic batch-size control) that lets many agents learn from large volumes of traces in parallel without quality loss. Below are concrete, real-world applications derived from the paper’s findings, with sectors, actionable workflows, and feasibility notes.
Immediate Applications
- Boldly faster self-improving coding assistants in IDEs (software)
- What it enables: Continuous, parallel prompt/playbook updates from coding sessions and tool traces, improving repair, refactor, and navigation skills without model fine-tuning.
- Tools/workflows: Integrate Combee with ACE/GEPA in IDEs (e.g., Cursor-/Claude Code–style agents); batch-size autotuning; playbook-size and “helpful/harmful” hit dashboards.
- Assumptions/dependencies: Access to developer traces; long-context LLMs; safe filtering to prevent harmful rules; org consent/privacy controls.
- Rapid prompt learning from terminal/CLI sessions for DevOps and SRE (software, operations)
- What it enables: Faster adaptation of CLI agents to local environments (as in Terminal-Bench), turning successful command sequences and error recoveries into rules.
- Tools/workflows: Map phase over shell transcripts; scan aggregation to build environment-specific playbooks; deployment via agent sidecar.
- Assumptions/dependencies: High-quality reflections; secure capture of shell logs; model reliability on technical text.
- Finance document processing pipelines that learn from run logs (finance)
- What it enables: Improved XBRL entity tagging (FiNER) and numerical reasoning (Formula) by consolidating recurring extraction and calculation patterns into prompts.
- Tools/workflows: Batch ingestion of filings and prior runs; GEPA/ACE + Combee orchestrator; continuous validation against ground-truth tags/calculations.
- Assumptions/dependencies: Availability of labeled or feedback-rich traces; adherence to regulatory data handling; long-context inference budget.
- Customer support chatbots that evolve their system prompts from tickets (software, customer service)
- What it enables: Aggregating high-signal reflection snippets from resolved chats/emails into concise rules (edge-case handling, tone, escalation criteria).
- Tools/workflows: Augmented shuffling over support reflections; hierarchical aggregation to prevent context overload; release gating with A/B evals.
- Assumptions/dependencies: PII handling and anonymization; human oversight on policy-altering rules; stable routing and tool APIs.
- Enterprise knowledge assistants with faster organizational playbook curation (enterprise software)
- What it enables: Organization-wide agents that accumulate cross-team “how-to” patterns without model retraining, preserving specificity at scale.
- Tools/workflows: Playbook warehouse; retrieval-augmented use at inference; batch autotuner selecting throughput “sweet spots.”
- Assumptions/dependencies: Access to heterogeneous logs; governance for cross-team sharing; versioning/audit trails of evolving prompts.
- A/B and multi-armed testing of prompt strategies at scale (software product ops)
- What it enables: Parallel exploration of prompt variants with controlled aggregation (scan) to avoid quality collapse; quicker convergence on winning variants.
- Tools/workflows: Experiment orchestration with dynamic batch-size control; metrics on update count, “helpful hits,” and task KPIs.
- Assumptions/dependencies: Reliable feedback signals; careful confound control; cost tracking.
- Data labeling assistants that refine task instructions from reviewer feedback (data operations)
- What it enables: Better, task-specific labeling prompts distilled from annotator corrections and dispute resolutions.
- Tools/workflows: Reflective loops on annotation sessions; structured rules for corner cases; periodic aggregation to minimize overload.
- Assumptions/dependencies: Consistent reviewer signals; label quality gates; privacy if annotator data includes sensitive content.
- Academic pipelines processing large agentic logs (academia)
- What it enables: Faster, lower-cost test-time learning studies that remain reproducible; processing thousands of trajectories with stable quality.
- Tools/workflows: Combee atop ACE/GEPA for benchmarks; open-source orchestration and configuration; evaluation on held-out sets.
- Assumptions/dependencies: Compute for parallel runs; compatibility with chosen LLMs; clear documentation of hyperparameters.
- Personal assistants that adapt from daily interactions without retraining (daily life)
- What it enables: Incremental improvements to email triage, scheduling, or personal workflows by retaining high-value rules from user corrections.
- Tools/workflows: On-account “experience memory” using scan-aggregated updates; opt-in controls; rollback/versioning of rules.
- Assumptions/dependencies: User consent; small-scale parallelism (home or cloud); privacy-preserving storage.
- PromptOps for LLM applications (platform/infra)
- What it enables: A “Prompt Learning Orchestrator” microservice offering Map–Shuffle–Reduce, duplication factor tuning, and batch-size autotuning APIs.
- Tools/workflows: Plug-ins for LangChain, DSPy, or custom agent stacks; observability for context size, update rates, and quality metrics.
- Assumptions/dependencies: Integration effort; telemetry and monitoring; long-context model availability.
Long-Term Applications
- Federated and privacy-preserving prompt learning across departments or devices (healthcare, finance, enterprise)
- What it could enable: Aggregating “experience” via parallel scans over local shards without centralizing raw data; organization- or hospital-wide improvements.
- Tools/products: Federated scan aggregation; differential privacy for reflections; consent and data residency policies.
- Dependencies: Strong privacy frameworks; secure reflection formats; alignment with compliance (e.g., HIPAA, GDPR).
- Safety-governed deployment in regulated domains (healthcare, public sector)
- What it could enable: Auditable evolution of system prompts for clinical documentation, coding, or administrative triage with rollback and approval workflows.
- Tools/products: Rule promotion pipelines with human-in-the-loop governance; safety filters; red-teaming on learned playbooks.
- Dependencies: Domain validation datasets; stringent oversight; model robustness on domain-specific language.
- Organization-wide “experience bus” for multi-agent systems (enterprise platforms)
- What it could enable: A shared, versioned memory service where agents contribute reflections that are aggregated hierarchically and redistributed with provenance.
- Tools/products: Experience registry, playbook marketplaces, dependency tracking; cross-team knowledge discovery.
- Dependencies: Standardized reflection schemas; access control; incentive and quality scoring mechanisms.
- Real-time adaptive agents for robotics and IoT (robotics, manufacturing)
- What it could enable: Agents that adapt textual/planning prompts from parallel task outcomes (e.g., instruction following, exception handling) without firmware changes.
- Tools/products: On-edge or gateway Combee modules; small-model compatibility; latency-aware batch controllers.
- Dependencies: Robustness beyond text domains; alignment with safety envelopes; reliable sensor-to-text abstractions.
- Built-in Map–Shuffle–Reduce prompt learning in LLM platforms (software platforms)
- What it could enable: Cloud providers offering Combee-like orchestration primitives as managed services (parallel scan, augmented shuffling, autotuners).
- Tools/products: “Experience OS” APIs; turnkey connectors to agent runtimes and vector stores.
- Dependencies: Platform adoption; standard metrics for quality-delay trade-offs; cost governance.
- Cross-model transfer and eventual distillation to weights (ML/AI research, model providers)
- What it could enable: Using learned playbooks as scaffolds for fine-tuning or adapters, capturing stable rules into smaller models.
- Tools/products: Prompt-to-weights distillation pipelines; evaluation harnesses to prevent rule regression.
- Dependencies: Reliable mapping from text rules to parameter updates; catastrophic forgetting safeguards.
- Autonomous SRE for agent fleets with adaptive parallelism (software operations)
- What it could enable: Systems that auto-tune batch sizes to meet SLAs while protecting quality, reacting to load and model latency.
- Tools/products: SLA-aware autotuners; telemetry-driven policies; canary updates for learned prompts.
- Dependencies: Accurate delay models; guardrails for quality collapse; integration with deployment stacks.
- Standards and policy for “evolving prompts” auditability (policy, compliance)
- What it could enable: Governance frameworks that require versioning, provenance, and impact analyses for changed prompts in production systems.
- Tools/products: Audit logs, signed artifacts, compliance reporting; diff tools for context changes.
- Dependencies: Industry consensus; regulator engagement; standardized artifacts and metadata.
- On-device/edge prompt learning for resource-constrained models (edge AI)
- What it could enable: Lightweight scan-based aggregation to preserve quality when memory is scarce, enabling incremental improvement on-device.
- Tools/products: Tiny aggregation libraries; batched, low-overhead reflection handling.
- Dependencies: Efficient reflection generation; limited context windows; intermittent connectivity assumptions.
- Knowledge marketplaces of reusable, versioned playbooks (ecosystem)
- What it could enable: Sharing high-value, domain-specific rule sets (e.g., for spreadsheets, CRMs) with quality signals and provenance.
- Tools/products: Registries, licensing, and scoring; integration hooks for retrieval and adaptation.
- Dependencies: IP and licensing models; trust and verification; domain adaptation methods.
Notes on feasibility across applications:
- Core dependencies: long-context capable LLMs, reliable reflection generation (e.g., ACE/GEPA), and orchestration implementing parallel scan aggregation, augmented shuffling (duplication factor p≥2), and dynamic batch-size control.
- Quality risks: harmful or generic rule accretion without oversight; domain shift; junk reflections; context governance required.
- Operational constraints: compute and cost budgets for parallel runs; access to sufficient, representative agentic traces; privacy and compliance where applicable.
Glossary
- Accuracy@1: An evaluation metric that measures whether the top-ranked prediction is correct. "and evaluate average Accuracy@1 across three runs on 29 held-out tasks."
- ACE: A prompt-learning method that consolidates agent experience into structured playbooks to improve performance without weight updates. "ACE~\citep{ace} enables agents to adapt during inference by consolidating experience into structured playbooks"
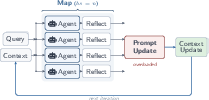
- Aggregator LLM: The LLM component that consolidates multiple reflections into a unified context update. "the aggregator LLM responsible for consolidating many reflections must process increasingly long-horizon reflective context at once, and becomes overwhelmed."
- Agentic traces: Recorded trajectories or interaction logs produced by agents during task execution. "ability to efficiently learn from a large set of collected agentic traces."
- AppWorld: An agent benchmark of multi-step API tasks evaluated by TGC and SGC metrics. "AppWorld~\citep{appworld} evaluates multi-step API tasks via Task Goal Completion (TGC) and Scenario Goal Completion (SGC)."
- Augmented shuffling: A robustness mechanism that duplicates and shuffles reflections to increase their chance of being incorporated during aggregation. "Combee introduces an augmented shuffling mechanism."
- Context artifact: An external, evolving prompt or memory object that stores learned guidance for future use. "updates a shared context artifact for future iterations."
- Context curator: The LLM component that synthesizes and curates updates to the shared context. "without overloading the LLM context curator (Reduce)."
- Context overload: The degradation that occurs when too many reflections are aggregated at once, causing loss of useful details. "We refer to this context overload."
- Context window: The maximum sequence length a model can attend to in a single pass. "even when all reflections fit within the model's context window (we use DeepSeek-V3.1 with 128K context)"
- Critical batch size: The largest batch size that yields significant speedups before diminishing returns or quality degradation. "analogous to the critical batch size concept from distributed training~\citep{mccandlish2018empirical}."
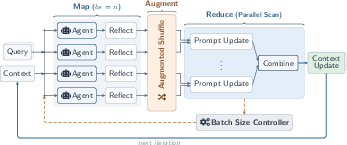
- Dynamic batch size controller: A component that adaptively selects batch size to balance learning quality and delay. "Combee also introduces a dynamic batch size controller to balance quality and delay."
- FiNER: A financial NLP dataset for fine-grained numeric entity recognition in XBRL documents. "FiNER~\citep{loukas2022finer} for fine-grained entity typing in XBRL documents"
- Formula: A dataset for numerical reasoning over structured financial filings. "Formula~\citep{wang2025finlora} for numerical reasoning over structured filings."
- GEPA: A prompt-learning method that optimizes system prompts using performance feedback from contextual examples. "GEPA~\citep{gepa} optimizes prompts based on performance feedback from contextual examples."
- Generate-reflect-update loop: An inference-time learning cycle where agents solve tasks, reflect on trajectories, and update shared context. "methods that follow a generate-reflect-update loop"
- Lossy compression: The phenomenon where the aggregator retains generic patterns and discards specific insights when overloaded. "the aggregator appears to perform lossy compression"
- Map-Shuffle-Reduce paradigm: A processing pattern where work is partitioned (Map), permuted/replicated (Shuffle), and merged (Reduce). "Combee adopts a Map-Shuffle-Reduce paradigm: multiple agents process distinct context shards in parallel (Map), reflections are duplicated and shuffled to prevent information loss (Shuffle), and a hierarchical parallel scan algorithm aggregates local updates into a coherent global context without overloading the LLM context curator (Reduce)."
- MapReduce-style decomposition: Structuring computation into map and reduce stages to handle large inputs efficiently. "This approach also draws inspiration from MapReduce-style decomposition for LLM processing of long documents~\citep{zhou2024llm}."
- No-context-learning baseline: Performance of the agent without any prompt learning or context updates. "approaching the no-context-learning baseline of 53.3"
- Parallel scan algorithm: A parallel aggregation method (akin to prefix sums) used to combine updates without overloading the curator. "Combee employs a multi-level parallel scan algorithm to aggregate learning experience from multiple trajectories"
- Pareto frontier: The set of trade-off optimal points where no method improves speed without losing quality (and vice versa). "Combee consistently reaches the Pareto frontier, matching or exceeding the best fixed-batch accuracy while training significantly faster than quality-matching setups."
- Playbook: A structured collection of reusable strategies or rules stored in the system prompt. "the final system prompt learnt is a playbook with many entries."
- Power-law delay curve: A fitted relationship modeling how epoch time decreases with batch size. "We fit a power-law delay curve through measurements:"
- Prefix sum operations: A classic parallel computing primitive used as an analogy for Combee’s aggregation. "for performing prefix sum operations"
- Scenario Goal Completion (SGC): An AppWorld metric measuring scenario-level task success. "AppWorld~\citep{appworld} evaluates multi-step API tasks via Task Goal Completion (TGC) and Scenario Goal Completion (SGC)."
- Self-consistency: An inference technique that improves reasoning by aggregating multiple sampled solutions. "echoing the principle behind self-consistency~\citep{wang2022self}"
- System prompts: High-level instruction blocks that steer model behavior and can be learned/optimized over time. "can learn system prompts to improve accuracy based on previous agent runs."
- Task Goal Completion (TGC): An AppWorld metric measuring task-level goal success. "AppWorld~\citep{appworld} evaluates multi-step API tasks via Task Goal Completion (TGC) and Scenario Goal Completion (SGC)."
- Terminal-Bench 2.0: A benchmark of command-line tasks assessing software engineering capabilities. "Terminal-Bench 2.0~\citep{merrill2026terminal} contains 89 command-line tasks testing software engineering capabilities."
- Top-K Retrieval: A baseline that selects representative reflections by clustering and taking one per group. "Top-K Retrieval embeds reflections, clusters them into K groups, and feeds one reflection from each group to the curator."
Collections
Sign up for free to add this paper to one or more collections.