- The paper presents a causal taxonomy of data leakage, distinguishing estimation, selection, memorization, and boundary effects with quantified AUC shifts.
- The paper reveals that selection leakage, via peeking and seed cherry-picking, is dominant, causing significant performance inflation driven by noise exploitation.
- The study demonstrates that standard cross-validation underestimates leakage risks, prompting recommendations for type-safe, structurally aware evaluation protocols.
Quantitative Analysis of Data Leakage Mechanisms in Machine Learning
Introduction
The study "Which Leakage Types Matter?" (2604.04199) presents a comprehensive empirical analysis of 28 controlled leakage experiments and a temporal boundary experiment across 2,047 tabular classification datasets. With a methodological focus on comparing leaky vs. clean pipelines under strict paired experimental design, the work constructs a four-class taxonomy of data leakage, establishes causal distinctions between them, and directly measures effect sizes using both raw AUC shifts and standardized effect sizes. The results invert common textbook emphases, revealing divergent magnitudes and practical risks across leakage mechanisms.
Experimental Design and Corpus
A corpus was compiled of 2,047 binary classification datasets from OpenML, PMLB, and the ml package, representing significant breadth in both n (sample size; median 1,901, range up to 946,799) and p (features; median 18). Each experiment uses a within-dataset counterfactual design, running paired clean and leaky pipelines under identical fold and seed assignment. Datasets were partitioned a priori into discovery and confirmation splits using deterministic hashing to allow internal validation not contingent on explicit pre-registration.
Each experiment targets a specific leakage mechanism (or combination) via an atomic pipeline perturbation, unambiguously isolating the magnitude and direction of leakage effects on generalization estimates.
A Causal Taxonomy of Leakage Mechanisms
Estimation Leakage (Class I)
Estimation leakage encompasses parameter estimation using holdout/test data—specifically, fitting scalers, imputers, feature encoders, PCA, outlier removal, and calibrators on the entire dataset. Across all conditions, estimation leakage produces negligible effect (absolute ∣ΔAUC∣<0.005).
After controlling for sample size and model, the corresponding bias (order O(p/n)) is well below the numerical noise floor even at low n. This finding sharply contradicts a common pedagogical priority, as the pervasively taught "fit scaler inside fold" rule, while defensible, has minimal practical impact at typical p/n ratios.
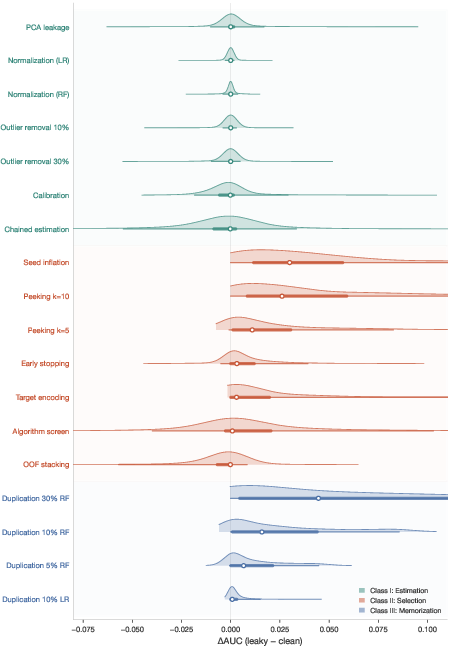
Figure 1: Distribution of ΔAUC grouped by leakage class; Class I (estimation) effects are centered tightly on zero.
Selection Leakage (Class II)
Selection leakage is the dominant, practically significant mechanism. Four subtypes are identified and empirically separated:
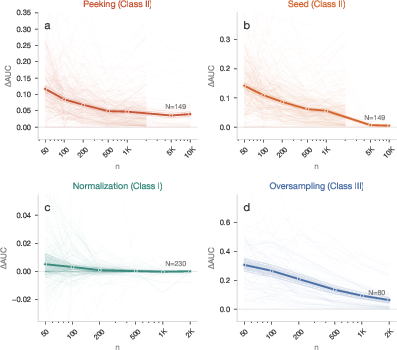
- Peeking (model selection based on test fold performance): At k=10 configurations, mean inflation is +0.040 AUC (dz=0.93, 92% datasets affected).
- Random Seed Cherry-Picking: Reporting the best of p0 seeds yields p1 AUC inflation (92% affected); the effect scales p2 for bagged models.
- Early Stopping (on test data): p3, with positive inflation in 76%.
- Screen Selection (algorithm screening): p4, inflation p5 AUC, independent of p6 due to error correlation structure.
A critical observation is that selection leakage can be decomposed into noise exploitation (p7), which decays with p8, and genuine diversity. At realistic dataset sizes (p9), 90% of measured selection leakage is noise exploitation, compared to a residual at very large ∣ΔAUC∣<0.0050 representing true algorithmic diversity.
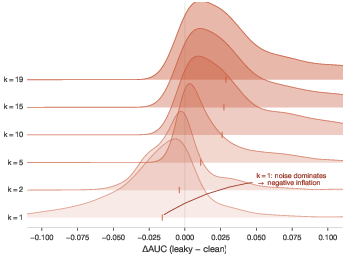
Figure 2: Peeking inflation across datasets at ∣ΔAUC∣<0.0051; the distribution is skewed right, highlighting high prevalence of positive noise exploitation bias.
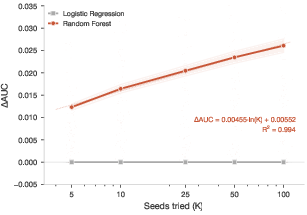
Figure 3: Seed cherry-picking leads to monotonically increasing inflation with ∣ΔAUC∣<0.0052 seeds for stochastic models; LR is deterministic.
A notable effect is non-monotonicity at ∣ΔAUC∣<0.0053: at a single configuration, peeking can appear conservative due to test set noise. For ∣ΔAUC∣<0.0054, order-statistics dominate and inflation becomes substantial and monotonic.
Memorization Leakage (Class III)
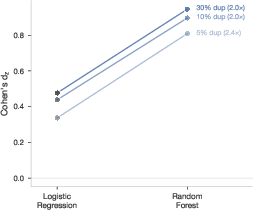
Memorization leakage arises when duplicated (or nearly-duplicated) evaluation instances are included in the training set. The inflation is monotonic in both duplication rate and model capacity, exhibiting:
Empirically, memorization leakage is accentuated by high-capacity models (decision trees, KNN), and diminishes both with increased O(p/n)2 and for regularized or low-capacity models.
Boundary Leakage (Class IV)
Boundary leakage is a structural phenomenon: when the cross-validation partitioning does not respect non-iid structure (temporal, group, spatial), random CV distributes correlated samples across train/test, hiding leakage. A temporal boundary experiment (walk-forward vs. random CV) on 129 datasets shows domain-dependence:
- On datasets with genuine temporal structure, mean pure temporal effect is O(p/n)3 AUC.
- On null controls (FOREX), effect is near zero.
Thus, random CV censors structural contamination; on standard iid benchmarks, the effect is negligible, but for nonstationary or grouped data, the risk is substantial and invisible under standard evaluation.
N-Scaling and Mechanistic Isolation
The O(p/n)4-scaling experiment (subsampling O(p/n)5 to O(p/n)6) documents three critical patterns:
Cross-Validation Confidence Intervals: Coverage Failures
Experiment AO empirically calibrates 95% CV confidence intervals, finding only 55% actual coverage (z-based), 70% (t-based), strongest using a conservative method (87%). Bootstrap is pathological for high-variance models, reaffirming theoretical limitations identified in previous literature.
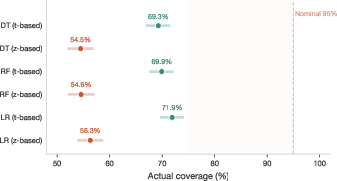
Figure 6: Actual coverage of various 95% CV CI constructions; dashed line denotes nominal level, all methods are anti-conservative.
A Bayesian hierarchical meta-regression confirms that leakage mechanism explains an order of magnitude more variance than n4, n5, or imbalance, with all dataset feature moderators rendered null after conditioning on experiment class. There is no "safe" n6 or n7 zone—mechanism dominates all effect size heterogeneity.
Additional Findings
- Feature selection leakage is negligible at low n8 but nontrivial at n9 (p/n0 mean, up to p/n1 AUC).
- Metric selection (reporting most favorable score) flips winner rankings in 31% of datasets.
- Tooling implication: APIs enforcing type-safe, structurally prevented selection and memorization leakage would eliminate almost all impactful leakage under iid conditions.
Implications and Future Directions
Practical Recommendations
- Audit and structurally prevent selection leakage (the dominant effect class).
- For high-dimensional (p/n2) or non-iid (temporal, grouped) data, employ evaluation protocols respecting the data-generating process (e.g., walk-forward, group, spatial CV); standard random CV is insufficient and censors contamination.
- Memorization leakage risks are accentuated for high-capacity models or duplication practices; practitioners should monitor and report any instance re-use protocols.
- Estimation leakage, while still an error, should be deprioritized relative to selection and boundary effects when auditing and teaching, as its practical impact is negligible at typical p/n3.
- Confidence intervals produced via standard CV variances are anti-conservative by p/n41.7p/n5; proper calibration is non-trivial and method-dependent.
Theoretical and Methodological Insights
- The study confirms that observed selection leakage at practical p/n6 is dominated by noise exploitation but that a diversity term persists at scale.
- The explicit causal taxonomy predicts new empirical tests (e.g., neural nets in Class III), bridging mechanistic and statistical reasoning.
- The results demonstrate that the dominant textbook warning ("always normalize inside the fold") is correct but orders of magnitude less important than warnings about adaptive test set usage.
Future Research
- Extension to neural networks, multiclass regimes, real-world applications with grouped/longitudinal data, or non-tabular domains (images, text, graphs).
- Automating detection and type-safe prevention of Class II/III leakage in modular workflow frameworks.
- Systematic exploration of metric selection (as a form of selection bias) and its integration into tooling.
Conclusion
Class I estimation leakage—often the focus of introductory ML pedagogy—has negligible effect at practical p/n7 in tabular binary classification. In contrast, selection leakage mechanisms (particularly peeking and random seed cherry-picking) result in the largest, most persistent performance inflations, primarily through statistical noise exploitation. Memorization leakage is monotonic in both duplication and model capacity, demanding additional caution when using high-capacity models. Boundary leakage remains invisible under standard random CV, with possible significant domain-specific contamination.
Structural, type-safe workflow frameworks targeting selection and memorization leakage have the potential to eliminate most impactful errors in ML reproducibility for iid tabular settings. The evidence provided should recalibrate both empirical practice and educational priorities for ML researchers and practitioners.