- The paper identifies that data leakage arises from improper dataset splitting and metadata handling, leading to inflated performance metrics.
- It demonstrates that embedding similarity analysis and rule-based splits are effective in detecting and mitigating leakage in ML pipelines.
- The study highlights role-differentiated perspectives, emphasizing the need for coordinated technical and organizational safeguards.
Data Leakage in Automotive Perception: Practitioners' Insights
Context and Motivation
The integrity of ML pipelines in automotive perception is critical given their role in safety-relevant functionalities. Data leakage—where training and evaluation sets are contaminated by overlapping or highly similar samples—remains a subtle yet consequential hazard that can undermine model reliability and produce optimistic metrics without real-world generalization. Despite ample research on technical aspects, knowledge about real-world organizational perceptions and mitigation strategies is limited. This study addresses this gap by qualitatively analyzing interview responses from ten practitioners across design, implementation, and verification roles within an automotive OEM.

Figure 1: Graphical overview depicting research design and participant distribution across roles in the automotive perception pipeline.
Role-Differentiated Knowledge and Conceptualization
Findings reveal that conceptualization of data leakage is fragmented across job responsibilities, with ML engineers and data scientists framing the risk in technical terms—data splitting, validation protocols, and similarity metrics. In contrast, system designers and verification engineers interpret leakage through the lens of data subject representativeness and scenario coverage, often omitting technical details of contamination but emphasizing downstream effects. Notable is the unanimous recognition that even highly similar, rather than strictly identical, samples across training and evaluation can constitute leakage, challenging naive notions of contamination. The contextual variability in definitions signals a lack of standardized operational criteria across SDLC stages, complicating cross-role communication and undermining systematic safeguards.
Practitioner Experiences and Impact Analysis
Practitioners in implementation roles report regular encounters with data leakage primarily during pilot or academic projects, with no severe consequences due to pre-production phase detection. The root causes consistently trace to initial dataset splitting, lacking sequence- or scene-level isolation, and inadequate metadata-driven disambiguation. Cases include inadvertent inclusion of near-duplicate driving sequences or contextually similar (e.g., same weather/location) images in both train and validation sets. Resultant impacts are universally described as overestimated performance metrics—validation KPIs exceeding plausible operational domain expectations—thus masking generalization failures until late-stage validation. Verification and design practitioners generally report indirect knowledge, rarely encountering leakage first-hand.
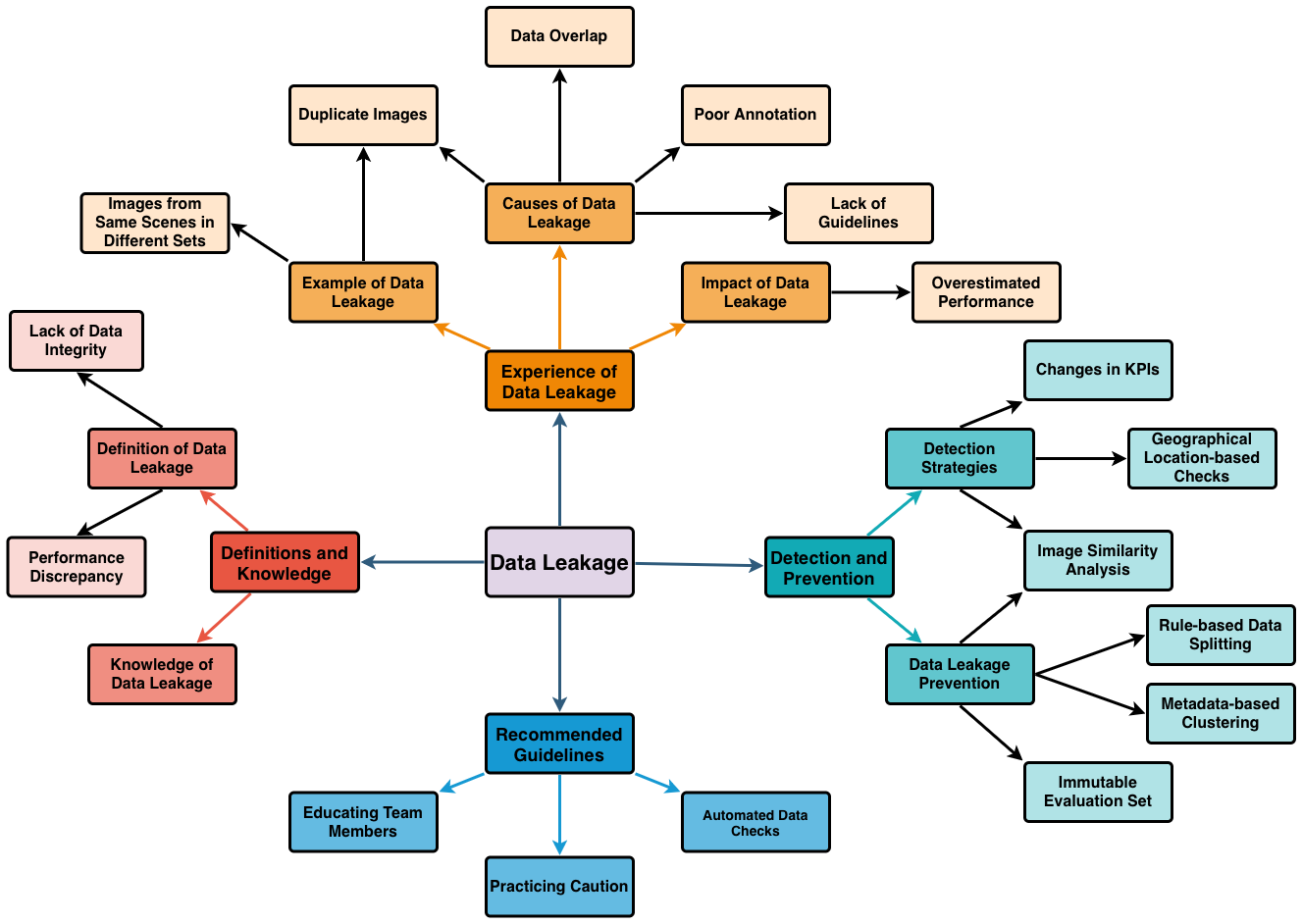
Figure 2: Mindmap visualizing main and sub-themes; frequent codes include duplicate images and image similarity analysis as both causes and detection/prevention techniques.
Detection and Prevention Mechanisms
Detection is primarily pragmatic: performance anomalies ('too good to be true' results) trigger retroactive checks. Technical responses include embedding-driven image similarity analysis (using pre-trained models such as CLIP), Euclidean or cosine distance clustering, and metadata-driven approaches (GPS, weather, temporal data). These methods require domain knowledge regarding operational design domain (ODD) and task-specific context. Data leakage is attributed most frequently to insufficient splitting logic—random splits without consideration of correlated metadata or continuous stream origins. Preventive strategies advocate rule-based splits (temporal, geographical, sequence-aware), immutable evaluation sets isolated from training data, and hierarchical metadata-driven coverage analysis. Emphasized also is embedding similarity checks prior to dataset augmentation. Prevention success is role-dependent, with technical implementation roles demonstrating higher engagement in proactive controls.
Practitioners endorse hands-on knowledge sharing—demonstrating leakage instances and maintaining red-flag reports. Dataset versioning, traceability, embedded similarity checks, and standardized splitting protocols are highlighted as rigorous defenses, though their application remains inconsistent across roles. Recommendations stress the importance of uniform metadata policies and task-specific requirements, cautioning against universal solutions. Education regarding leakage is viewed as continuous, requiring practical examples and contextual nuance rather than abstract rule dissemination. Cross-role communication, traceable data management, and integrated reporting are favored as means to institutionalize leakage awareness.
Practical and Theoretical Implications
The findings underscore data leakage as a socio-technical coordination challenge distributed throughout the ML pipeline. Technical solutions (embedding-based checks, metadata splits, immutable sets) are necessary but not sufficient; operational safeguards must incorporate cross-role communication and shared documentation. The absence of standardized, context-sensitive definitions and detection protocols increases vulnerability to undetected contamination, especially as team boundaries and development stages shift responsibilities. The study suggests integrating leakage prevention into ML safety culture via formal requirements, onboarding routines, and quality checklists alongside established standards (ISO 26262, SOTIF). Theoretically, the role-differentiated perceptions demand extension of reliability frameworks to account for organizational and human factors, beyond technical fixes.
Limitations and Threats to Validity
A single-case study with ten participants constrains generalizability but offers analytic depth, revealing transferable job-category patterns likely relevant across automotive and adjacent ML domains. Observer bias is mitigated through triangulation, dual-coding, and reflexive note-taking. Construct validity is strengthened by open-ended prompts, allowing roles to self-define leakage. External validity depends on the assumption that automotive ML pipelines share cross-role fragmentation in other environments. Reliability is supported by transparent coding procedures, though qualitative confidentiality limits transcript sharing.
Conclusion
Data leakage in automotive perception manifests variably across roles, as both statistical contamination and representativeness deficiency. Implementation roles provide technical operationalization, while design and verification highlight scenario-based abstraction. Effective mitigation requires integration of technical, organizational, and educational processes—rule-based splits, similarity checks, traceability, and continuous cross-role discourse. Future work should pursue multi-institutional ethnographic studies, longitudinal evolution of leakage awareness, and harmonization of technical safeguards with organizational routines. Embedding leakage prevention in systemic reliability engineering will advance robustness of ML-enabled automotive systems.